基于自学习特征权重网络的模板匹配研究
2020-02-03许志龙施烨俞鑫春郭伟
许志龙 施烨 俞鑫春 郭伟
(1.国网江苏省电力有限公司 江苏省南京市 210024 2.国网江苏省电力有限公司南通供电分公司 江苏省南通市 226006)(3.南通华远科技发展有限公司 江苏省南通市 226007)
1 引言
模板匹配在电力巡检机器人有着重要的应用[1],其可以帮助机器人在复杂环境下定位目标位置。模板匹配算法可由两部分组成:特征工程和定位模块。特征工程可以将模板图和目标图转换到特定的特征空间,定位模块在特征空间计算模板图和目标图不同区域的相似度,从而定位出模板图在目标图上的位置。
特征工程是模板匹配任务的基础环节。传统的模板匹配算法主要依靠人工设计特征模板提取图像特征,如灰度、直方图和角点等特征,其提取效果受环境影响较大。文献[2]对比了三种典型模板匹配算法,在外加不同程度噪声时,算法的效果均出现明显退化。相反,深度学习方法可以通过反向传播机制从大量训练样本中自动学习适用于特定视觉任务的图像特征,具有较强的鲁棒性[3]。
定位模块是将模板图在目标图中定位出来。在特征空间中,使用模板图在目标图上遍历计算相似性可以完成定位。相似性计算是定位模块的核心步骤。在已发表文献中,一般使用逐像素点比较的相似性计算方式[2],但当目标存在遮挡或图像形变较大时性能会大幅下降。为了解决形变问题,BBS(Best-Buddies-Similarity)方法[6]提出了建立在最近邻的相似度度量方法,通过计算模板图中特征点与目标图中特征点的匹配对数实现定位目的。DDIS(Deformable Diversity Similarity)方法[7]在BBS 的基础上优化了计算效率,同时比BBS 方法具有更高的匹配精度。目前,模板匹配领域主要研究较为固定场下的特定目标定位问题,如车牌定位[4]和人脸识别[5]等。然而,电力巡检机器人所处的工作环境较为复杂多变,遮挡和形变等问题会降低模板匹配算法的匹配效果。
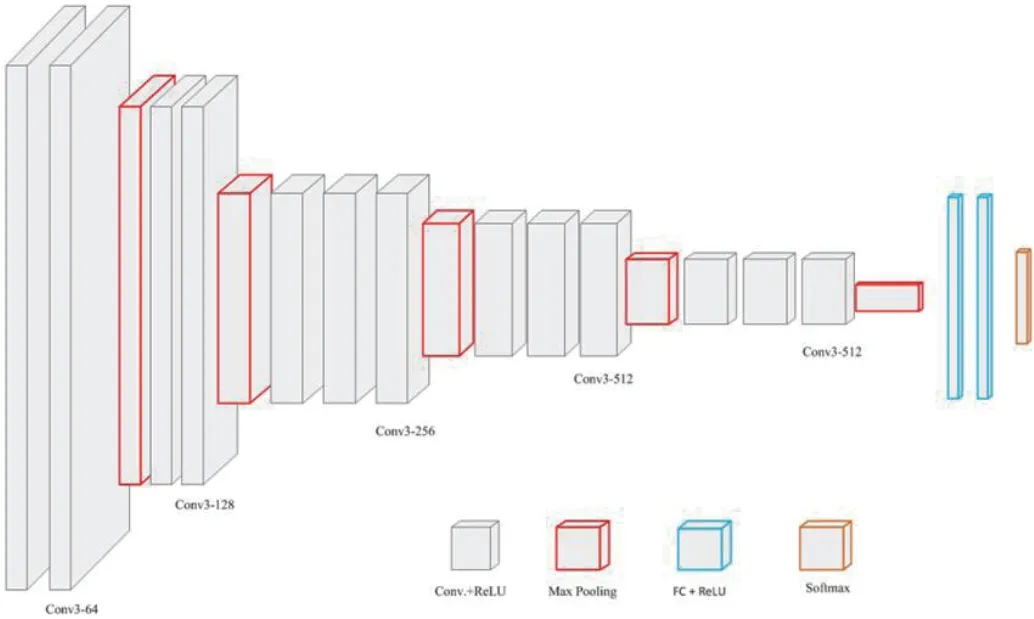
图1:VGG16 网络结构
为了提升复杂电力场景下模板匹配的准确率,本文提出了一种基于自学习特征权重网络(self-learning feature weight network,SFWN)的模板匹配方法。以VGG16[8]为骨干网络,分别提取浅层、中层和深层(第2、7 和11 层)的特征图作为模板匹配特征图。深度卷积网络的浅层卷积层提取低层次特征,包含更多细节信息,如图像边缘和颜色信息。中间卷积层则进一步抽象特征图,得到更加高级的特征。深层特征图最抽象,含有明显的语义信息。多层次的特征图可以完整描述图像的特征,有助于提升目标匹配准确率。但是,直接利用不同层之间的特征图计算相似度会使得时间损耗太大,因此使用VGG16 中的第2、7 和11 层的特征图作为多层次特征图代表,可以减小特征空间维度。另外,为了进一步减少匹配算法耗时,在VGG 基础上引入SE(Squeeze-and-Excitation)模块[9]。SE模块可以自主学习同一层特征图中不同通道特征的重要程度。通过剔除特征图中不重要的通道,降低定位模块的计算复杂度。在定位模块中,本文使用曼哈顿距离[10]作为相似性度量,曼哈顿距离越小,表示模板特征图与目标特征图的相似度越高。
本文主要的贡献可分为如下:
(1)分析卷积神经网络不同深度特征图的特点,提出了使用VGG16 的浅、中和深等不同抽象程度特征图作为模板匹配的特征工程输出,减少了不同深度特征图之间的信息冗余和计算量;
(2)使用SE 结构改进VGG16 网络,实现了特征通道权重的自学习,降低了同一深度特征图不同通道间的信息冗余和算法耗时;
(3)与已发表文献相比,本方法在TMDE 数据集上取得最高的准确率,同时具有较强鲁棒性。
2 方法

图2:VGG 特征层可视化
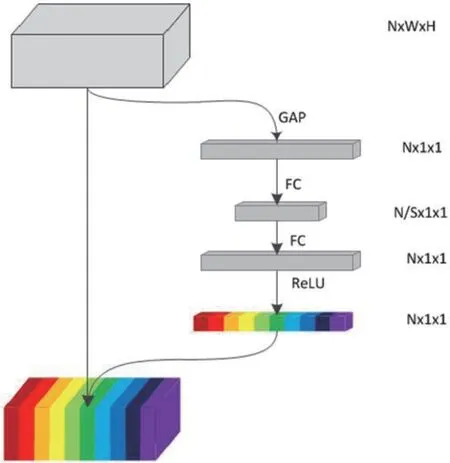
图3:SE 结构

图4:曼哈顿距离热力图
下文主要围绕特征工程和相似性度量函数两部分展开。首先使用SFWN 提取图像重要的特征图作为模板匹配的特征空间,并使用模板特征图遍历目标特征图得到曼哈顿距离。组合目标图上每个像素对应的曼哈顿距离可以得到相距离热力图。最后,按模板图大小遍历曼哈顿距离热力图可以得到模板特征图与匹配特征图区域的曼哈顿距离之和,距离和最小的位置即为模板在目标图上的定位。
2.1 特征工程
特征工程的作用是获取模板图和目标图对应的特征图,用以计算曼哈顿距离。因此,特征提取的质量对模板匹配效果影响极大。少量特征图可以减小定位模块的计算量,但是匹配效果较差。相反,大量特征图有利于提高匹配精度,但是耗费大量计算资源。因此,需要从大量特征图中筛选出重要的特征图,在保证匹配精度的同时减少时间损耗。本文同时使用特征图可视化分析方法和网络自学习特征图权重两种方式,确定最具代表性的特征图。
2.1.1 卷积层特性分析
VGG16 网络结构由13 层卷积层、2 层全连接层构成,激活函数使用的是ReLU[8]。VGG 通道数较多,最多可达512 个通道,其结构如图1 所示。
VGG16 不同卷积层具备不同的特征抽取和表达能力,图2 展示了VGG16 的第2、7 和11 卷积层特征图[11]。
其中,图2(a)是原图。图2(b)是原图对应的网络浅层特征图可视化结果,浅层网络提取的特征与传统算法所做的特征工程比较接近,主要包括颜色、边缘和角点等特征[12]。而随着网络层的加深,低层次的图像特征被进一步抽象形成更高级的特征。图2(c)对应的是网络中层特征图可视化结果,提取的特征图相对于浅层更抽象。图2(d)是网络深层特征图的可视化结果,其带有较明显的语义信息。与浅层细节信息相比,深层语义信息对遮挡和形变等噪声敏感度较低。
VGG16 可获得图像不同抽象程度的特征图,但是不同层的特征图之间存在较大的信息冗余。另外,直接使用全部特征图极大增加匹配算法的计算量。因此,使用VGG16 的浅、中和深三层的特征图分别作为各个层次特征图的代表。其中,浅层和中层特征图主要用于构建目标物体的结构特征,深层特征图用于提供对噪声不敏感的语义信息,增加匹配算法的鲁棒性。
2.1.2 自学习权重
但是,直接使用VGG16 的浅、中和深三层特征图有两个缺点:
(1)特征冗余性:同一层特征图的不同通道之间具有相似性。
(2)计算复杂度:在模板匹配的计算相似性过程中,需要将模板特征图与目标特征图遍历匹配。因此,过多的特征图容易增大计算复杂度;
为了减少同一深度特征图的信息冗余,在网络中引入SE 模块,使网络能自适应学习层内不同通道的重要性。最后,浅、中和深层特征图仅分别选择各自权重值前5 大的通道,用于构建模板匹配任务的特征工程。SE 结构由挤压(Squeeze)和激发(Excitation)组成,实现了通道权值的自主学习,如图3 所示。
Squeeze 操作:对于某一层的输出按通道进行全局平均池化(Global average pooling,GAP)。将N 个W×H 大小的通道输出特征压缩成N 个实数z,每一个实数具体有全局的感受野,具体地全局池化操作如式(1):

表1:与其他算法对比
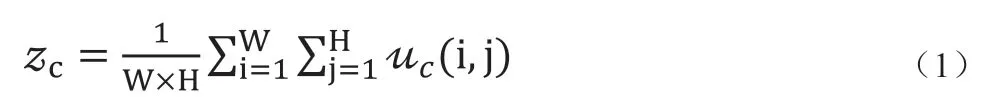
其中,uc和zc分别代表的是前一卷积层第c 通道特征图和对应的全局平均池化值,W、H 分别为uc的宽和高。
Excitation 操作:通过两个全连接层建模通道间的相关性,并输出N 个权重值。使用全连接层可以引入更多的非线性性,更好地描述通道间复杂的相关性。最后通过一个Sigmoid 激活函数将值归一化到0~1 之间,如式(2)所示:

其中,w 表示对应不同通道的权重值,F1表示降维的全连接操作,F2表示升维的全连接操作。ReLU 作用是引入非线性,而Sigmoid 输出值是网络对特征图不同通道重要性的权重值。为了实现通道权重可学习,将N 个权重值通分别与特征图N 个通道对应相乘。因此,网络训练时可以通过反向传播机制自动更新权重值,实现权重值自学习。将w 权值排序,使用较大权值对应的通道用于特征工程,可有效地降低特征空间复杂度。最终,用于构建模板匹配的特征描述如式(3):

其中,I 为输入网络的图像,Oi,j对应的是第i 层卷积层、第j个通道索引的输出特征张量,j 的取值范围是各层的w 中前5 大权值所对应的通道索引号。
2.2 模板匹配的相似性度量函数
记P 和Q 分别为模板图和目标图经过特征描述子F 提取得到的特征图。设模板图的长宽分别为m 和n,待匹配图的大小为a 和b,则将模板特征描述P 在Q 上通过滑动窗口计算的方式计算曼哈顿距离。滑动的范围是:m/2 ≤i ≤r-m/2、n/2 ≤j ≤c-n/2,其中r 和c 分别代表原图像的行数和列数,m 和n 分别代表模板特征图的宽度和高度。曼哈顿距离如式(4)所示:

通过公式(4)计算模板特征图和目标特征图对应位置的曼哈顿距离,可得到如图4 所示的曼哈顿距离热力图分布。其中,蓝色越淡表示距离越小。按(m,n)大小在热力图上遍历求和,曼哈顿距离之和最低的位置即为模板在目标图上的最终位置。
3 实验
本文实验环境为Ubuntu 16.04LTS,CPU 为Intel Xeon@2.10Ghz, GPU 为NVIDIA GeForce GTX 1080Ti,内存为128GB,深度学习框架为pytorch 0.4.1。
3.1 数据集

图5:TMDE 数据集

图6:模板匹配结果
目前没有公开的关于电力场景的模板匹配数据集。为了验证算法在实际工程中的可靠性,提出了一个关于电力环境的模板匹配数据集TMDE,所有数据均来自江苏省南通市供电局的实际作业监控视频。数据图像格式均为1080P,主要通过巡检机器人和移动布控球等设备采集得到。TMDE 的部分样本如图5 所示。
经过数据清洗后,得到TMDE 数据集共85640 张。同时,对需要匹配的目标统一标注。
3.2 实验参数及评价指标
为了普适性,SFWN 网络训练并未使用TMDE 数据集,而是使用VOC2007 的数据[13]。使用VGG16 预训练模型初始化主干网络的权重参数。实际训练时,使用随机梯度下降方法优化损失,其中学习率设为10-4、迭代次数设置为30000。
采用交并比IoU(intersection-over-union)衡量目标匹配的程度,如式(5)所示:

其中,MB(Matching Box)和GT(Ground truth)分别代表匹配结果和真值框。当匹配结果与目标图中的真值框的交并比大于75%认为目标匹配成功。统计测试集的匹配结果可以得到匹配准确率。准确率定为在TMDE 数据集上匹配成功的图像张数除以数据集的图像总张数。
3.3 实验结果分析
在TMDE 数据集上,模板匹配的对象包括仪表、梯子和标识牌等电力场景常规目标。图6 展示的是绝缘梯的匹配结果,图6 从上到下分别为模板图原图、良好场景匹配、严重遮挡匹配和严重形变匹配。其中,蓝色、绿色和红色框分别代表本方法、DDIS 和SSD 匹配结果。实验结果显示,本方法在不同情况下的匹配效果均最佳。其中,SSD 对于缩放和形变几乎均失效,而DDIS 的匹配效果比SSD 稍准确。
SSD、DDIS 以及本方法在TMDE 上的准确率和平均耗时,如表1 所示。
在表1 中,模型1、2 和3 分别为使用全部VGG16 特征图方法、使用VGG16 浅中深特征图代表方法和最后方法(本方法)。表1表明,特征冗余会不仅会降低匹配准确率,而且会极大增加耗时。另外,与已发表文献相比,本方法的匹配准确率最高。与BBS 相比,DDIS 虽然有较明显的提升,但耗时大幅增加。因此,本方法可以在耗时增加不多的情况下,极大提高检测准确率。
4 结束语
为了提高电力场景中模板匹配算法的准确率,提出了一种基于SFWN 的模板匹配方法。使用深度网络自动提取模板图和目标图的特征,减少人力损耗。使用VGG16 中的第2、7 和11 卷积层特征图作为不同深度特征图的代表,可以减少不同层之间的特征信息冗余且和计算损耗。另外,在VGG 的基础上引入SE 结构,可以使网络自主学习到同一层特征图不同通道间的重要性。选择重要特征图通道作为该层的特征图代表,可以进一步减少算法耗时。在自制的模板匹配数据集TMDE 验证不同匹配算法的效果。结果表明,与其他已发表算法相比,本方法能保证耗时增加不大的前提下,极大提高模板匹配准确率,更适合于实际电力巡检应用。
