一种适合Tegra K1架构的Top-k查询优化算法
2020-02-02李靓琦黄玉龙谢绍国
李靓琦 黄玉龙 谢绍国
(1.吉安职业技术学院机械与电子工程学院 江西省吉安市 343000)
(2.新余学院数学与计算机学院 江西省新余市 338004 3.安庆师范大学计算机与信息学院 安徽省安庆市 246133)
1 引言
在当今移动互联网时代,NVIDIA 推出了拥有192 个CUDA[1]核心的嵌入式GPU — Tegra K1 来提升移动应用性能。禁止随机访问的Top-k 查询为信息检索领域的典型问题,在移动应用中得到了广泛使用。作为禁止随机读的代表性算法--NRA 算法[2]使用分值上下界逐次逼近策略,算法可在未获取所有对象的准确聚合分值前获得最终结果。为了减少计算代价,Guntzer 以及Mamoulis 等分别提出了SC 算法[3]及LARA 算法[4]。为了充分利用台式GPU 的计算性能,黄玉龙等提出了分段Top-k 查询算法[5]。然而,由于嵌入式硬件GPU 与CPU 共享运行内存等特点,这些算法均不能适应在Tegra TK1 上运行。为此,本文提出了一种适合Tegra K1 架构的查询优化算法。
2 共享内存的CUDA模型
在CUDA 编程模型中,通常需将CPU 看作是主机,将GPU看作是设备。为此,可将程序分为两类:一种是运行在CPU 上的宿主代码,另一种为GPU 执行的设备代码。由于CPU 和GPU 在硬件架构上存在差异,这两类代码可访问的资源是不一样的。
与传统架构不同,嵌入式GPGPU 与CPU 共享运行内存,即:基于嵌入式GPGPU 算法的执行时间T= Th+Td。其中,Th表示host端执行时间,而Td为device 端执行时间。
3 查询优化算法
由文献[1]可知:Top-k 查询就是在规模为m 的空间中找出聚合分值最高的k 个对象。其中,每个对象由n 个属性组成且所有对象在属性i 下的得分降序保存到一规模为m 的列表Li。其中,每个存储位的结构为(id,score)。由于CUDA 适合处理线性结构,在此将输入数据数组合并为一个m*n 的一维数组L。为了存储候选结果,算法执行前需分配一个长度为k 的对象集合Ck。集合中每个元素的结构为(oID,w,b,visited)。其中,oID 为标识符,b 和w 分别表示分值上下界,visited 位图则记录对象的访问状况。此外,为记录集合Ck外的已访问对象,还需分配一个变长对象数组Ck。同理,在此将集合Ck与Ck合并为集合C。为了尽可能地利用Tegra K1 的线程资源,我们的算法还采用分段执行策略。即,一次执行有序列表STRIDE个层次。基于以上定义,下面分两个阶段阐述查询优化算法。
3.1 扩展阶段
开始时,数组C 为空,在此仅需将读到的数组L 中的元素简单插入集合C 即可,具体流程为:循环批量读取L 中元素及下标。在此,可将读取到的元素分为两类:一类是从未读取过。对于此类元素,直接将其插入数组C 即可。另一类元素是数组C 保存对象的属性值。对于此类元素,需要更新相关对象的访问状况并且更新其分值下界b,直至数组C 的长度大于等于k 为止。此阶段的具体思想如下:

For each tid∈[0,STRIDE ) parallel do item ←L[tid].id; //tid 为线程编号if(item.id ≠obj.oID)// obj 为数组C 中的对象obj.oID=item.id;obj.w=item.score;将obj 追加到数组C 末尾;else obj.w=obj.w+item.score;//更新对象obj 的分值下界end if更新obj 的visited 位图;End parallel for使用thrust 库[5]中的sort_by_key 原语排序数组C;
此时,在host 端将当前阈值T 与数组C 末尾对象的分值下界进行比较,如大于等于,则算法进入下一阶段。否则,继续批量访问数组L,直至数组C 末尾对象的分值下界大于等于当前阈值为止。
3.2 剪枝阶段
此阶段,数组L 的对象个数将维持不变。访问中,如遇到上阶段从未访问的对象,则不予处理。为了减少比较次数,在此使用类似SC 算法策略,仅维护分值上界即可。为了充分利用GPU 的性能,在此亦采用相似批量处理策略循环执行。同样地,此阶段一次遍历数组L 中STRIDE 个元素且每次遍历的流程如下:
(1)并行获取L 中从第 j 到 j + STRIDE 层所有元素及下标;//j为上阶段访问的层次。
(2)更新数组C 中相关对象的分值下界及访问状况visited 位图;
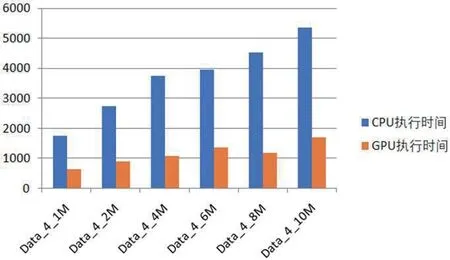
图1:算法执行时间

图2:算法的加速比
(3)如果数组C 存在k 个或以上对象的聚合分值完全确定,则执行步骤4;
(4)并行获取数组C 中已确定聚合分值的对象到临时数组tmp;
(5)并行删除数组C 中相应位置对象;
(6)使用thrust[5]库中的sort_by_key 原语排序tmp 以及C 数组;
(7)如果tmp[k-1]的分值score 大于等于C[0]的分值上界b,则算法结束,tmp 数组前k 个对象即为查询结果;否则,重复执行步骤1~6,直至算法结束。
由此可知,本文提出的算法在综合LARA 及SC 算法的优点基础上,充分利用了Tegra K1 GPU 强大的线程资源,可快速获得查询结果。与此同时,考虑到Tegra K1 与CPU 共享内存的特点,使用位图结构记录对象访问状态,从而可处理更大规模的查询。
4 性能分析
为了验证本文算法的有效性,在嵌入式开发板Jetson-TK1 上进行了实验。开发板硬件配置为:CPU 为 ARM Cortex-A15,主频为1.3GHz;GPU 为拥有192 个CUDA 核心的Tegra K1,每个核心主频为0.825GHz。CPU 与GPU 共享2GB 运行内存;操作系统为Ubuntu14.04,CUDA 工具包为6.5 版本。实验数据集为随机生成的均匀分布数据,其中,每个对象的属性分值都服从(0,1)分布。基于此,随机生成了1M、2M、4M、6M、8M 以及10M 规模的实验数据,每个对象包含了4 个属性。算法返回的对象数量100;分值计算函数为∑ ui(0 ≤i<m),m 为有序列表数量。STRIDE 步长为100。根据上述规定,下面给出了算法的具体执行时间以及算法的加速比,分别如图1 和2所示。
由图1 可知,在一次访问100 个输入元素基础上,我们的算法在10M 规模数据集上执行top-100 查询,可在2 秒内完成,这样的性能非常适合在大规模集合上执行top-k 查询。从图2 中可以得知,与单线程CPU 算法比较,我们的算法可以获得2.7 至3.8 倍的加速比,这主要因为虽然Tegra K1 的计算核心数量众多,但工作频率低且算法中存在多处线程同步,需要消耗大量通信代价。
5 结论
作为信息检索的一个经典问题,Top-k 查询在移动应用中得到了广泛使用。为了提高移动应用的查询性能,NVIDIA 公司推出了一个拥有192 个计算核心的Tegra K1 GPU。为此,本文研究了一种适合Tegra K1 架构的分段查询算法。结合LARA 以及SC 算法的优势,本文的算法在10M 规模对象中查找出100 个最高分值对象的过程可在2 秒钟内完成。与单线程CPU 算法比较,本文的算法有着显著的性能提升。
