基于改进K-means的K近邻算法在电影推荐系统中的应用
2020-02-02蔡畅
蔡畅
(辽宁科技大学 辽宁省鞍山市 114051)
推荐系统是通过分析客户的历史行为对用户所感兴趣的内容进行预测[1],它可以帮助用户找到感兴趣的电影,同时可以发现那些不容易被发现的好电影。本文融合改进K-means 算法和K 近邻算法给用户推荐感兴趣的电影,由于K-means 算法对初始聚类中心敏感,选取不当可能会导致不理想的聚类[2-3],文献[4]设计了改进的混合推荐提高算法的收敛速度,采用改进的LeaderRank 方法增强网络的连通性。文献[5]提出了一种改进的K-means 算法,IPSGWO-KMeans 算法可以跳出已经找到的较好的聚类中心,从较好的聚类中心附近找到更优解,有更强的寻优能力。推荐算法和K-means 算法一直被研究,但都没有一个很好的进展。
1 相关基础
传统的K-means 算法使用的是随机采取机制,它的目的是将所有数据点划分为聚类中心,使簇内方差之和最小化。该算法对初始聚类中心的选择也会明显的影响聚类结果。本文用肘部法估算数据的聚类数量K,在开始聚类之前设置一个K 值及每个簇的初始聚类中心,当K-means 算法中没有指定的K 值时,K-means 参数的最优解是以成本函数最小化为目标,成本函数为各个簇畸变程度之和,每个簇的畸变程度为每个变量点到其类别中心的位置距离的平方和,而簇内成员的紧凑性与簇的畸变程度成正比,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
肘部法的核心是SSE(sum of the squared errors,误差平方和),
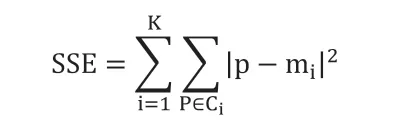
其中,Ci是第i 个簇,p 是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE 是所有样本的聚类误差,代表了聚类效果的好坏。聚类数目K 越多,簇内成员间的紧凑度会随之提高,SSE 值会随之降低。当聚类数目K 达到一个最优值后,在持续增加K 值时,簇内成员间的紧凑度的增加幅度以及SSE 值的下降幅度会趋于平缓。
2 改进的算法
2.1 改进的K-means算法
本文提出用最大最小距离算法对K-means 算法做出改进,采用最大最小距离算法随机选取一个初始聚类中心,剩余的初始聚类中心根据欧式距离准则进行计算获得,用该算法选取初始聚类中心可以降低聚类的迭代次数,同时可避免聚类中心出现邻近的情况。改进后的K-means 算法流程:
(1)使用肘部法选取聚类数目K 值,并设置初始的K 个簇为空值。
(2)从测试数据集X={X1,X2...,Xn}中随机选取一个初始聚类中心Z1。
(3)计算各数据点到Z1的距离,距离Z1最大的数据点作为第二个初始聚类中心Z2。
dij=‖Xi-Zj‖(j=1,2..k;i=1,2...n)
(4)计算其余数据点到Z1,Z2的距离,并求出它们(i ≤ K)中距离的最小值。
di=min[di1,di2](i=1,2,...,n)
W=θ*‖Z1-Z2‖(θ 为选定n 比例系数)
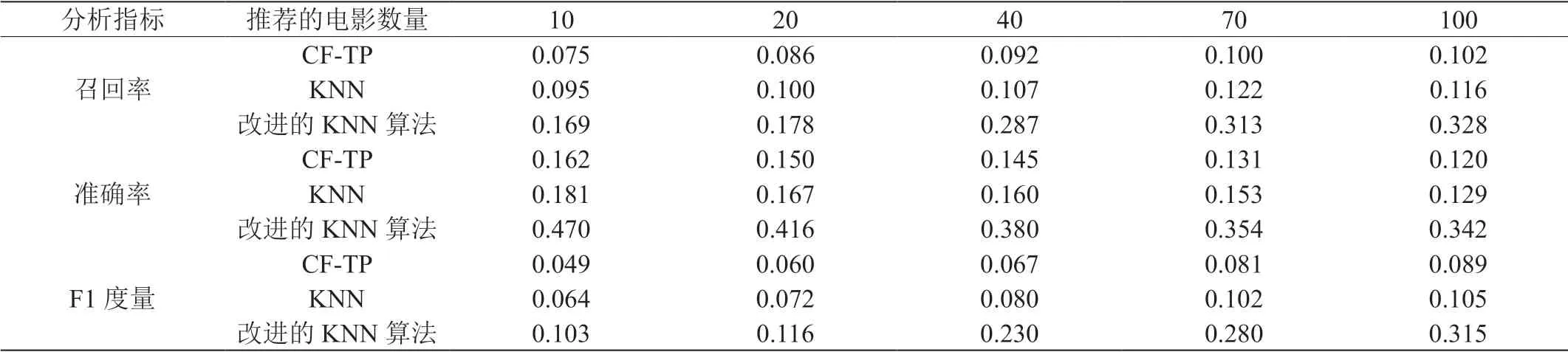
(5)从已知最小距离中计算出最大的距离值,它所对应的数据点作为第i 个(i ≤ K)初始聚类中心。当i>K 或dl dl=max[min[di1,di2,...dik]]>W (6)计算数据点Xi(i=1,2,...,n)到初始聚类中心Zi(i=1,2,...k)的距离,按照最小距离准则,将数据分配给距离它们最近的聚类中心。 (7)将分配后的Xi标记到所属簇zi(i=1,2,...,k)中。计算各簇中所有数据点的平均矢量,更新簇的聚类中心,重复(5)、(6)。 (8)经过多次迭代计算得到最终的聚类结果K 个簇Z={Z1,Z2,...,ZK}和各簇的聚类中心z={z1,z2,...,zk}。 K 近邻算法是数据挖掘和推荐系统中非常流行的算法,本文提出了改进K-means 的K 近邻算法,可以为K 近邻分类减少了计算量,降低时间成本。 改进K-means 算法对训练集聚类后,计算待分类用户与各簇聚类中心的距离,距离最小的聚类中心所属簇中的数据作为待分类用户的训练集,在新训练集中,根据待分类用户与训练数据的距离,找到与待分类用户最近的K 个用户,取用户中类别最多的一类作为待分类用户的类别,再将该类别中电影评分较高的电影推荐给用户。改进算法的具体步骤如下: (1)根据改进K-means 算法得到聚类结果K 个簇Z={Z1,Z2,...,Zk}。 (2)计算各簇的聚类中心与待分类用户u={u1,u2,...,un}的距离,按照最小距离原则,选取距离最小的聚类中心所在的簇。 表1:分析指标表 (3)将簇中数据作为新的训练集Y,查找与待分类用户距离最近的K 个最近邻子集。 (5)根据待分类用户u 的类别归属决策函数确定u 的所属类别: Cu=arg max(Su-Zi) (6)重复操作,直到所有待分类用户完成分类。 在传统推荐系统中,大部分推荐算法是以用户对电影评分作为测试数据,会出现数据稀疏问题。以用户的个人信息作为依据可以缓解这一问题,例如,未成年用户会更喜欢动漫,女生用户会给爱情电影评分更高。本文将用户年龄考虑在内,拼接用户年龄信息与电影评分向量,将用户年龄划分为七个年龄段1-17 岁、18-24 岁、25-34 岁、35-44 岁、45-49 岁、50-55 岁、56+岁,把用户所属年龄段设置为值1,其余的值为0,例如某一用户35 岁,可以表示为[0,0,0,1,0,0,0]。出现用户数据稀疏时,可根据相近的年龄选取相似性用户,同时可以缓解冷启动的问题。 本文系统分为训练、测试两部分。 训练部分:本文改进K-means 算法是基于电影评分相似度的用户聚类算法,首先获取用户对电影的评分数据,从中随机选取用户对看过电影的评分作为第一个初始聚类中心,再根据欧氏距离计算各用户与第一个初始聚类中心用户之间相似度,选取其余用户作为剩余的初始聚类中心,根据训练集中用户与初始聚类中心的最小距离进行分配,形成用户簇。 测试部分:当测试用户进入推荐系统后,根据用户对电影评分作为数据点,计算到簇的聚类中心距离,将用户划分到距离最近的簇中,将簇中用户作为新训练集,在新的电影评分训练集中查找相似度较高的K 个最近邻用户形成最近邻用户集合,根据K 个用户邻居对已看电影的实际评分来预测用户对电影的评分值,按照评分进行排序,向用户推荐电影列表。 本文的算法是通过python 实现的,运行环境:Dual-Core Intel Core i5 CPU,主频2.3GHz,内存8G,Macos64 位操作系统。 为了验证改进算法的性能,实验使用了真实的MovieLens 数据集,将数据集按照2:8 的比例随机划分为测试集和训练集。 实验用三个分析指标衡量电影推荐的结果:准确率、召回率、F1 综合评定准确率和召回率的调和平均数。 表1 将本文提出的改进算法与融合时间因素和用户评分特性的协同过滤算法(CF-TP)、K 近邻算法从上述的三个指标进行对比分析。可直观的看出推荐结果的优化程度,改进的算法与其他两种算法相比,推荐结果的准确率明显提高,同时召回率也有改善,但随着电影推荐数目的增加准确率随之递减。 本文提出了用肘部法确定K 值并且用最大最小距离法优化了K-means 算法,在聚类数据中考虑到用户年龄信息,最后应用到K近邻算法中对用户进行电影推荐。并对本文算法进行实验评估了,结果表明改进后的算法对电影推荐的准确率等性能都有了明显的提高。2.2 改进K-means的K近邻算法
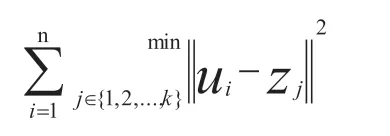
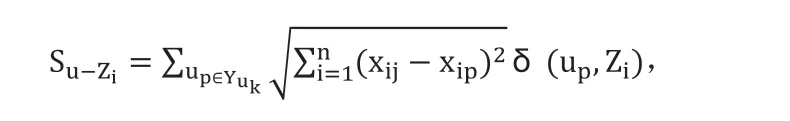
2.3 引入用户个人信息
2.4 改进算法在电影推荐中的应用
3 实验结果与分析
4 结束语
