从“推土机”到Zen后的又一次次重大升级 AMD Zen 3架构锐龙5000系列处理器首发评测
2020-01-25《微型计算机》评测室
《微型计算机》评测室


北京时间2020年10月9日零点,本年度最受期待的一场处理器发布会:“WHERE GAMINIG BEGINIS”(游戏从这里开始)终于召开,AMD公司总裁兼CEO苏姿丰博士正式发布了采用新一代Zen 3架构的AMD锐龙5000系列处理器,并带来了一系列好消息:Zen 3核心架构的每时钟周期指令数(IPC)性能比上一代Zen 2产品提升了多达19%;锐龙5000系列处理器的单线程性能得到大幅提升,锐龙5000系列处理器中的高端产品在游戏性能上已经全面超越现在的游戏处理器旗舰:酷睿i9-10900K。
如果真如AMD所言,这可是一次堪比从“推土机”到Zen之后的又一次重大升级,毕竟尽管Zen、Zen+、Zen 2架构的问世让AMD处理器在总体技术水准上能与竞争对手平分秋色,但在处理器单线程性能、游戏性能上与對手相比一直略有差距,对手也总是拿这两点来打压AMD产品。那么Zen 3真能改变AMD处理器的以上不足,在单线程性能与游戏性能上形成反超吗?AMD又是怎样办到的?AMD Zen 3处理器架构有何神奇之处?
如何实现19%的性能提升?
AMD Zen 3处理器架构技术设计解析
在AMD发布锐龙3000系列处理器也就是Zen 2架构之后,就公布了有关Zen 3架构的相关内容。当时AMD宣称Zen 3相比Zen 2能带来大约15%的IPC提升。考虑到Zen 2架构的锐龙3000系列处理器的频率较低,因此业内普遍估计新的Zen 3架构应该是基于Zen 2架构的小改款,核心架构改变应该不算太多,其性能增加主要来自于缓存设计的改变和频率提升。但是,在Zen 3架构和相关处理器发布后,人们惊讶地发现,Zen 3架构是基于Zen 2架构做出了重大架构更新和全面优化的处理器架构,值得深入研究。
Zen 3架构设计一览
从宏观来看,Zen 3架构采用的仍是基于SMT同步多线程技术的设计,每个核心拥有2个线程。在Zen 3上,AMD首先提到的就是全新的分支预测单元,Zen 3架构大幅度加强了分支预测设计,并宣称其为目前最先进的分支预测单元。缓存方面,Zen 3的一级指令缓存和一级数据缓存都采用了8路设计,容量为32KB,Op缓存部分支持4K个指令排序,二级缓存采用了数据和指令混合的方案、8路设计,容量为512KB。
前端指令解码方面,Zen 3每周期可以执行4个指令解码(依旧是4发射设计)或者从Op缓存中提取8个指令——这里需要注意的是,AMD设计Op缓存的意义就在于,将之前使用过的指令结果直接存储在Op缓存中,如果下次流水线中重新出现这样的指令,那么Zen 3架构将会直接从Op缓存中取出结果进行宏指令执行,每次可以提取并派送8个结果。考虑到Op缓存可以存储高达4K指令,因此有比较大的概率可以实现更宽的指令分派,并允许更多的指令进入后续的执行部分,这是一个非常巧妙的方案,后文我们还有针对这部分和Zen 2架构的对比。另外,对整数或者浮点数据而言,每周期可以分派6个宏指令或者微指令,这里Zen 3依旧采用了协处理器执行模型,且可以分别同时执行整数和浮点计算。
Zen 3的执行部分也经过了加强,现在Zen 3的整数执行单元有4个整数ALU单元、1个带分支预测的ALU单元、3个AGU单元和1个专用分支预测单元。由于有3个AGU单元,在地址计算方面,Zen 3每周期可以进行3个地址计算。浮点计算部分是Zen 3加强的重点之一,Zen 3现在拥有6个浮点计算单元,每周期可以执行2个256bit的FP乘积累加运算单元(FMAC)。FMAC计算是目前最重要的浮点计算基础方法之一,包括常见的卷积运算、点积运算、矩阵运算、数字滤波器运算、多项式的求值运算等都可分解为数个FMAC指令来进行求解。因此高效率、加强的FMAC单元可以有效提高处理器在这些计算中的效率。
最后则是内存单元部分。Zen 3的内存单元现在每周期可以执行3个数据加载或者执行1个数据加载、2个数据存储,这样的混合模式也提高了数据存储效率。从Zen 3的宏观架构来看,AMD试图将Zen 3优化为一个更高效率、更低延迟和更为符合现代计算任务的全新综合体,这一点在和Zen 2架构的对比中更明显。
对比Zen 2:19%的IPC从何而来
在之前的发布会上,AMD宣称Zen 3相比Zen 2带来了大约19%的IPC提升,并且给出了一些详细的数据。这一点在本刊之前的文章中也有一些解释,包括Gache Prefetching(缓存数据预取)贡献了2.7%的力量;Execution Engine(执行引擎)的改进贡献了3.3%;更先进的Branch Predictor(分支预测)贡献了1.3%;Micro-op Cache(微操作缓存)的改进贡献了2.7%;处理器采用了新的Front End前端架构,为性能提升贡献了多达4.6%的力量;在整数运算单元上,Zen 3架构提升了Load/Store(数据载入和存储)带宽,贡献同样高达4.6%,这些数据加起来高达19%。
不过,由于当时AMD没有公布每个部分详细的设计细节,因此这些性能提升如何还有待探寻。现在,AMD给出了整个Zen 3架构设计的简图,并给出了每个部分比较重要的改进以及相对于Zen 2架构的对比,人们终于可以一窥Zen 3内部架构设计的奥秘了。
从Zen 3和Zen 2的架构简图来看的话,前端部分,Zen 3的最大变化在于使用了Op排序单元和分派单元2个单元替换了原有的Micro-Op排序单元。具体来看,通过L1指令缓存、分支预测、解码、Op缓存后,Zen 2可以每周期给出4个指令或融合后的8个指令(此处AMD将其描写为Fused Ins,但应该还是MacroOps),Zen 3则是每周期给出4个指令或8个宏指令(此处AMD直接写为Macro Ops)。这一部分看起来似乎没有变化,但是AMD宣称微操作缓存部分进行了改进,带来了2.7%的性能提升。另外,AMD数据显示,Zen 3相比Zen 2,在缓存数据预取和分支预测部分带来了2.7%和1.3%的IPC提升。这部分内容后文还有详细解释。
值得注意的是,Zen 3相对于Zen 2,在前端架构设计上的重要变化在于Zen 2的指令进入了微指令排序单元(Micro-OpQueue)后,直接输出6个微指令给执行单元的整数或者浮点部分。但是,Zen 3经过指令排序单元(Op Queue)和指令分派单元( Dispatch)后,每周期可以输出6个宏指令给执行单元的整数部分或者6个微指令给浮点单元。
在这里,AMD所定义的“宏指令”可包含多条微指令,比如1条移动到某位置的内存数据,并和另外位置的数据直接相加的指令可以使用宏指令完成,但是实际上在执行时需要进一步解码为多条微指令,包括定位地址、取得数据、移动数据、相加等。因此,Zen 3允许宏指令最多以每周期执行6个的方式发送给整数执行单元,使得前端最终输出给整数执行单元的实际指令吞吐量大大提升(整数执行模块的性能和指令并行度呈现高相关性,因此更多的指令有助于实现高效率的并行)。综合来看,前端部分的改进是Zen 3 IPC提升的最重要部分之_,AMD数据显示高达4.6%。
在执行引擎的整数部分,Zen 2拥有7个整数排序单元,Zen3精简为4个,但是每个单元的性能有所变化。后端执行部分,Zen 2只有4个整数ALU单元和3个AGU单元,Zen 3则同样使用了4个ALU(其中1个有分支预测功能)、3个AGU以及1个额外的分支预测单元。AMD解释为,在执行部分新加入分支预测单元可以提供更多的分支吞吐量,并带来关键延迟的降低。
在执行引擎的浮点部分,Zen 2架构只有1个浮点排序单元,Zen 3架构提升至2个。后端执行部分,Zen 2架构拥有2个MUL和2个ADD单元,总计4个浮点计算单元。Zen 3架构则改为2个ADD单元不变,但是2个MUL单元同时也可以执行FMAC计算,另外还增加了2个F21单元,主要用于将浮点数据转换为整数,其中1个用于地址计算,另1个专用于转换计算,总共6个浮点计算单元。根据AMD公布的数据,综合了整数和浮点部分的性能提升后,新的执行引擎架构设计带来了3.3%的性能增幅。
在数据存储和读取部分,AMD提到Zen 2每周期只能完成2次数据读取和1次数据存储,Zen 3将其提高为每周期3个数据读取和2个数据存储。AMD宣称数据存储和读取部分的改进也带来了高达4.6%的性能提升。上述所有的改进综合起来,实现了前文提到的总计19%的IPC提升,值得一提的是,这个数据并不包含频率或者其他方面的增益,是AMD采用了8核心、4GHz固定频率的Zen 3架构处理器对比相同配置的Zen 2架构处理器,综合了25个测试后得出的结果,其中最低的性能提升在9%,最高的在39%,其算数平均值是19%。AMD也给出了相关的测试对比。其中提升最大的部分依旧是1 1款游戏,包括《CS:GO》、《英雄联盟》《绝地求生》《战地4》《地铁:最后的光芒>等,这些游戏的性能提升最低都高达20%。
从前端到后端:详细解读Zen 3架构进化
在基本了解了Zen 3架構的宏观内容后,AMD还给出了从前端、执行到后端各个部分比较具体的性能提升情况。在整个指令拾取和解码阶段,AMD的设计目标是更快速的指令拾取,尤其是在面对分支预测和占据比较大空间的代码的时候。其中分支预测器依旧是Zen 3设计的重点之一。
之前Zen 2发布时,AMD宣称自己采用了基于神经网络的分支预测器结构,还采用了TAGE分支预测器(Tagged geometriclength predictor标记几何长度分支预测器)的设计。从分支预测器的发展来看,这几乎是AMD能够使用的最先进的分支预测器了。在Zen 3上,AMD继续使用基于TAGE架构的分支预测器,但做出了相当多细节上的改进。比如重新分配BTB(分支目标缓冲器)以获得更好的预测延迟。之前AMD在Zen 2架构上加大了BTB,其LO、L1、L2 BTB分别拥有1 6个、512个和7K个条目(entry)。在Zen 3上,L1 BTB进一步提高至1024条目,L2 BTB反而降低至6.5K条目。另外,Zen 3还使用了更大的ITA(Indirect Target Array,间接目标阵列),容量提升至1.5K,之前Zen 2为1K,更大的ITA有助于降低错误预测率。
除了上述内容外,AMD在Zen 3的分支预测器部分还反复提到更低的分支预测错误延迟和“无气泡”模式。其中前者的改进主要来自通过前端宏指令发射的设计,这带来了流水线级数的降低,从而间接降低了分支预测错误后重新填充流水线的损失。后者提及的“气泡”,是指在现代超标量流水线处理器中,如果不同指令之间出现互相等待结果的情况,并且分支预测器又没有给出分支预测信息的话,那么整个处理器都会停摆来等待相关指令的完成,由于这个等待周期的存在,程序员形象地称之为“气泡”。“气泡”会带来处理器性能的显著降低。现在,AMD采用了新的“无气泡”模式的分支预测器,会在很大程度上避免这种问题的产生——即使这种问题已经非常少见了。
另外,有关L1指令缓存,AMD提高了其拾取指令的速度和利用率。在Op缓存方面,AMD进一步加强了Op缓存拾取的速度,同时还可以在Op缓存和指令缓存之间更快速地切换,这有助于提高指令读取的效率。
执行部分:更宽、更快
AMD在执行部分做出的改进也非常显著,整个执行单元主要是效率的提升,而不是规模的扩张。先来看整数部分。AMD在Zen 3上使用了4个整数排序单元,每个整数排序单元分别拥有24个条目,4个一共96个条目。相比之下,之前Zen 2架构拥有7个整数排序单元共计92个条目。新的Zen 3架构稍微扩大了整数排序单元的条目数量。随后的整数寄存器部分,Zen 3拥有1 92个条目空间,Zen 2则只有180个,也只是小幅度增加。后续执行部分,Zen 3的整数执行部分每周期够执行1 0个操作,之前的Zen 2只能执行7个,增加了大约42%,这是增加最显著的部分。ROB部分,Zen 3也进一步扩大至256个,之前Zen 2只有224个。
从AMD在Zen 3整数部分的设计来看,AMD没有大规模增加计算资源,而是通过微调和对计算单元的合理设置,比如依1日采用4个ALU设计、共享ALU和AGU调度器以跨工作任务平衡负载、没有大幅度增加寄存器端口或者旁路网络输入端口等,但是通过这些优化尤其是执行部分每周期可执行操作数提升了42%,带来了整数部分性能的进一步提升。一般来说,整数部分的性能表现差异主要来自指令级并行是否能够非常好地完成,之前Zen2的表现非常不错,Zen 3自然不会有太大的问题。
在浮点部分,Zen 3的设计目标是通过更低的延迟和更大的结构来实现指令级并行,同时提高执行效能。具体的改进包括增加拾取带宽、单独的F21以及存储单元、更大的排序窗口、更快的4周期FMAC单元等。另外,AMD还提到Zen 3的MUL和ADD单元还可以实现整数文件存储和浮点寄存器文件处理,并且这两者是独立运作的,有助于同时执行不同的操作,来获得更大的数据吞吐量。
最后再来看看读取和存储单元两个部分。这个部分AMD的设计目标是提供更大的结构和更好的预取设计,以支撑更大规模的指令集并行。鉴于此目标,AMD在这部分做出了非常重大的改进。首先是存储排序单元从之前的48条目提升至64条目,L2DTLB则保留了2K个条目的设计,这有助于提高这部分运作的效率。在32KB、8路的L1缓存方面:缓存Ops提升至之前设计的3倍,每周期可以执行3个操作,但是在执行浮点操作时,每周期则只能执行2个,执行存储操作时更是回落至每周期1个操作。另外,AMD为读取和存储单元添加了新的指令,用于高效率复制较短的字符串,还改进了跨页面边界的预抓取操作的速度,以及更好的针对存储、加载转发关系的依赖等。
通过前文的介绍,AMD在Zen 3在前端、执行、读取和存储三大部分最重要的改进总结如下:
前端部分的改进包括:
2倍容量的L1 TBL,现在尺寸是1 024单位。
提高了分支预测单元的带宽
分支预测单元的“无气泡”模式
可以从错误预测中更快速地恢复
Op缓存更快的排序速度
更细粒度的Op缓存管道切换
执行部分
整数部分拥有专用的分支预测和地址选择器
整数部分拥有更大的执行窗口(增加了32个单位)
降低了整数和浮点指令通过Ops选择的延迟
浮点计算部分现在变化为6个单元
浮点部分MAC计算降低了1个周期
读取和存储单元
更高的读取和存储带宽(分别增加了1个单位)
更为灵活的加载和存储操作
改进的内存依赖性检测
LB部分的walker表从2个增加至6个
总的来看,AMD在Zen 3架构上的改进是多方面的,这些细微的改进加起来共同带来了整个Zen 3高达19% IPC的提升。从2017到2020,AMD通过Zen奠定的基础以及Zen 2、Zen 3两代架构的继续努力,终于实现了CPU微架构效能的大提升,值得庆贺。
锐龙5000:全新的SoC架构设计
在AMD的定义中,Zen 3是CPU微架构的代号,CPU微架构要联合其他部分,一起组成整个锐龙5000处理器。和之前的Zen 2-样,AMD将处理器设计为CCX、CCD、Infinity Fabric以及cIOD等多个模块,最终实现的锐龙5000处理器是以SoC的形式存在的。
现在,1个锐龙5000处理器将包含1个或者2个CCD,搭配1个cIOD来实现。CCD中包含了8个CPU核心组成的CCX和一个Infinity Fabric单元。其中前者采用Zen 3架构,8核心16线程,后者则执行总线功能,实现外部数据联通。对cIOD来说,内部同样包含了针对CPU通讯的Infinity Fabric总线,以及内存控制器、IOHub控制器等设备。
以AMD给出的2个CCD搭配一个cIOD的“2+1”的处理器为例,两个CCD都可以通过Infinity Fabric總线以写入16 Bit/周期、读取32Bit/周期的速度和cIOD的Infinity Fabric总线连接,AMD还为cIOD的Infinity Fabric总线定义了fclk频率。接下来,cIOD的Infinity Fabric总线又会以32Bit/周期的速度和UnifiedMemory Controller也就是统一内存控制器进行连接,同时以64Bit/周期的速度和IO Hub控制器连接。其中,统一内存控制器的频率被称为uclk, 10 Hub控制器的频率被称为lclk。
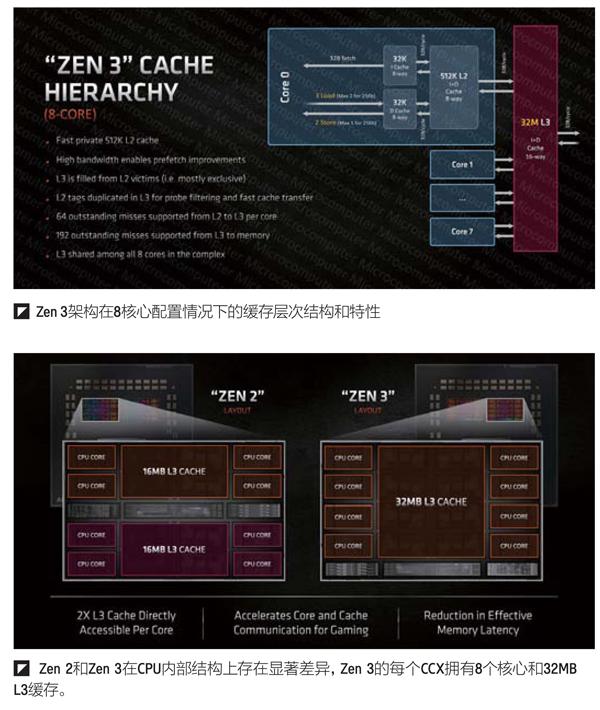
继续深入每一个CCD的话,可以看出,Zen 3相对Zen 2的最大变化在于CCX采用了8核心16线程,32MB L3,之前的Zen2则是每个CCX 4核心16线程,16MB L3。AMD也特别提到,新的设计使每个核心可以访问2倍的L3缓存,这样做可以加速核心和缓存之间的通讯,对游戏应用非常有益,另外还降低了访问内存的次数和延迟等。
更具体一些来看的话,AMD还给出了更详细的Zen 3和CCD的缓存层次结构介绍。首先是缓存体系,Zen 3的每核心私有512KB L2缓存,同时8个核心共享32MB L3缓存。其中,L2缓存通过加强的读取和存储单元实现了带宽的提升(前文已有介绍),这也有助于提高数据预取性能。在缓存模式设计上,Zen 3的L2和L3缓存采用了部分非包含式,L2中只包含了有关L3指针部分的筛选和快速缓存数据的标签信息。换句话说,L2包含了L3部分信息的“标签”,这有助于CPU在未命中L2缓存时通过查询L2的方式快速寻找到L3内的信息,算是一个比较常见的优化做法。在信息处理方面,Zen 3每核心可以处理64个未在L2中命中的信息并转而向L3查询,L3一次可以处理192个未命中信息,并转向内存查询。
在缓存带宽方面,核心每周期可以执行向32KB L1指令缓存的32Bit缓存拾取,针对32KB的数据缓存模式比较复杂,其模式是前文中提到处理器对普通数据每周期可以执行3个操作,执行浮点操作时每周期则只能执行2个,执行存储操作时更是回落至每周期1个操作,每个操作都是256bit。L1數据缓存和L1指令缓存到L2的带宽、L2缓存到L3缓存、L3缓存到Infinity Fabric等外部设施的带宽分别都是每周期32Bit。
另外在Zen 3的CCD中,由于32MB L3要面对8颗核心,因此受制于较大的芯片面积占比,很难使用传统的类crossbar总线。如果基于L3缓存分片区通讯,并采用mesh架构的连接方式又不太符合AMD目前介绍的情况。因此AMD在CPU核心和L3缓存的连接方面采用了常见的环形总线,也就是设计了通讯环来挂接每个CPU核心并连接至L3的各个区块。环形总线的优势在于设计简单、实现方便,在优化得当的情况下能够带来多核心之间数据通信、缓存信息拾取等比较高效的信息传输。
最后再来看看Zen 3和锐龙5000系列处理器在安全性和新指令集方面的内容。安全性方面,由于之前包括英特尔“幽灵”和“熔断”在内的CPU安全漏洞接连出现,因此现在人们也颇为关注处理器的安全设计。AMD在Zen和Zen 2架构设计上引入了SME、IBC、GMET、UMIP等安全特性,并得到了市场的广泛好评后。在Zen 3上,AMD在继承之前的安全特性的基础上,又引入了名为CET(Control-flow Enforcement Techonlogy,控制流执行技术)的新安全方案,主要用于针对ROP攻击。在指令集方面,之前AMD在Zen和Zen 2架构的处理器上,也添加了包括ADX、SMAP、SHA1、CLWB、QOS等指令,现在在Zen 3上,AMD加入了新的VAES/VPCLMULQD,正式宣布了对AV2×指令集的兼容和支持,使得处理器在运行支持AVX2指令的应用时,效能进一步提升。
从16核心到6核心 首发产品有四款
第一批上市的Zen 3处理器有四款,它们是锐龙9 5950X、锐龙9 5900X、锐龙7 5800X、锐龙5 5600X。其中锐龙95950X对应Zen 2旗舰,同样采用16核心、32线程设计的锐龙93950X,L3缓存总容量也是64MB,TDP热设计功耗为105VV,但最高加速频率从锐龙9 3950X的4.7GHz提升到了4.9GHz,处理器在中国区的首发价格为6049元。锐龙9 5900X则是为了取代锐龙9 3900XT、锐龙9 3900X,对标酷睿i9 -10900K的产品,同样采用12核心、24线程设计,L3缓存总容量仍为64MB,最高加速频率达到4.8GHz,分别比锐龙9 3900XT、锐龙93900X高了100MHz、200MHz,其中国区售价为4099元,比酷睿i9-10900K还便宜了1 00元。
至于锐龙7 5800X则是为了替换现在的锐龙7 3800XT、锐龙7 3800X,对标酷睿i7-10700K的产品。单从规格上看,它与锐龙7 3800XT几乎完全相同,最高加速频率同为4.7GHz,L3缓存容量为32MB,TDP均为105W。当然就像我们在前面讲的那样,它们在内部架构上有大的区别,锐龙7 5800X采用单CCX设计,而锐龙7 3800XT需要两个CCX才能实现8核心、32MB三级缓存的规格,目前锐龙7 5800X的中国区售价为3199元。
由于定位高端,以上三款处理器上市时都不会附送散热器,用户可以自行为它们购买高端风冷或水冷散热器。作为面向主流用户的锐龙5 5600X则会向用户附送幽灵潜行(VVraith Stealth)65VV静音版散热器。作为替换锐龙5 3600X、锐龙5 3600的产品,它也采用了6核心、12线程设计。三级缓存总容量同为32MB,但最高加速频率从锐龙5 3600XT的4.5GHz提升到了4.6GHz。其中国区售价为2129元。
最后,为了让用户能方便地使用Zen 3处理器,AMD表示现有500系芯片组主板,如X570、B550、A520等主板只需将BIOS中的AGESA(AMD Generic Encapsulated SoftwareArchitecture,AMD通用封装软件架构)升级到1.0.8.0,就能让Zen 3处理器通过自检、引导。当然如果想获得更好的体验,则需用户将AGESA升级到1.1.0.0或更新的版本。
多核心性能没有对手游戏性能秒掉i 9—1 0900K
16核心旗舰锐龙9 5950X首发测试
锐龙9 5950X+ROG CROSSHAIR ⅧDARK HERO主板展示
接下来,就让我们通过实际测试来看看新一代Zen 3处理器到底具备怎样的实力。我们首先将对本次Zen 3架构处理器中的旗舰:锐龙9 5950×进行测试。本着“好马配好鞍”的原则,为了充分发挥出锐龙9 5950×处理器的最大性能,本次我们特别采用了ROG专为Zen 3处理器研发的X570游戏主板:ROGGROSSHAIRⅦDARK HERO。
在ROG主板中,HERO系列产品的定位偏主流、更凸显性价比一些。不过在HERO前加入DARK即“变身”为黑暗英雄后,这款主板的各个方面相对以往的ROG X570主板都有一定的升级。首先在供电电路上,这款主板采用了与CROSSHAIRⅦHERO主板相同的14+2相供电设计。其中专为处理器核心供电的14相供电是由两颗电感、两颗一体式MOSFET通过两两并联来实现的。虽然在电感部分它依然使用16颗粉末化超合金电感,但CROSSHAIR V_DARK HERO的MOSFET从.CROSSHAIRⅦHERO支持60A电流的IR3555M升级为了支持90A负载的Ti德州仪器CSD95410RRB Power Stages MOSFET,这也就意味着GROSSHAIRⅦDARK HERO的1 6相供电电路在理论上最高可支持高达1440A的电流,能轻松保证锐龙9 5950X处理器的正常工作与超频。
在设计上,CROSSHAIR V_DARK HERO同样有很大的改变。作为“黑暗英雄”,该主板采用了全板隐身黑设计,去掉了CROSSHAIRⅦHERO主板上原有的银色元素,并在主板芯片组的“败家之眼”LOGO与主板I/O部分的“ROG”英文设计了多颗Aura RGB LED灯珠,令主板的外观更加炫酷。同时主板也支持AURA SYNIC神光同步功能,可连接其他支持AURA SYNIG技术的硬件或通过可编程接口、RGB接口,连接各类二代灯带、5050灯带以制造更加壯观的“光污染”。CROSSHAIRⅦDARKHERO还拥有其他×570主板所不具备的静谧性,在以往,由于X570芯片组完全支持PCle 4.0,技术规格提升的同时功耗也增加了,因此主板厂商往往为芯片组配备—具高速风扇进行散热,但风扇的增加却带来了额外的噪音。因此在CROSSHAIRⅦDARKHERO主板上,工程师为其采用了一个超大面积的铝合金散热片,不仅覆盖整个主板芯片组,更将散热片延伸占据了两根PCle 4.0x16显卡插槽中间的空位。这个设计思维很简单,通过扩大散热材料与空气的接触面积来提升散热性能。而根据华硕的官方报告来看,这个设计让他们达到了目的,CROSSHAIR V_DARK HERO主板上X570芯片组的工作温度只比采用主动散热的X570芯片组温度高了2.25%,但噪音却得到了完全消除。
值得一提的是,在网络方面CROSSHAIRⅦDARK HERO主板也采用了非常极致的设计。首先在无线方面,它搭配了支持最新WiFi 6技术(802.11ax)的英特尔AX200无线模块。其不仅支持5GHz/2.4GHz双频和多用户2x2 MIMO(MU-MIMO),峰值传输带宽更达到2.4Gbps,比现有802.11ac标准的速度提升了至少37%。有线网络部分,这款主板采用了双网卡设计,除了传统稳定的英特尔1211-AT干兆网络芯片外,主板还板载了瑞昱RTL8125-GG 2.5G有线网卡,网速是普通干兆网卡的2.5倍,配合ROG最新的GAMEFIRST VI网游优化工具,在开启Gaming First Mode后,可以强制将游戏数据包排列到队列前面而不必检查数据包,从而有效降低网游延迟。
音频方面,这款主板也配备了SUPREMEF×电竞信仰音效系统。其核心是一颗由瑞昱特供,输出信噪比为120dB、输入信噪比为113dB的81220 7.1声道Codec,并搭配一颗可推动600Q高阻抗设备,具有侦测播放设备阻抗,提供合适放大等级的耳放芯片。为了让电竞耳机拥有更好的播放效果,GROSSHAIR ⅧDARK HERO主板的前置音频输出则交由谐波失真仅-94dB的ESS SABRE 9023 Hyperstream DAG芯片负责,可以为玩家带来更精准的定位、更震撼的动态效果。当然像尼吉康音频电容、专为防爆音设计的DE-POP MOSFET,以及镀金音频插孔等多种高品质元件在这款主板也得到了一一应用。此外,该主板还支持DTS Sound Unbound音频技术,这是一种结合空间音频与HRTF高级音效定位算法的音频技术。它不仅可以提升游戏与电影的临场感,还能增强玩家在游戏中听音辨位的能力,从而在FPS射击类游戏中更好地了解敌人的动向,先发制人。目前该技术支持《战争机器5》《无主之地3》《使命召唤:现代战争》《极限竞速:地平线4》等12款游戏大作。
CROSSHAIR MIIDARK HERO主板产品规格
接口 Socket AM4
板型 ATX
内存插槽 DDR4 x4(最高128GB DDR4 5000)
显卡插槽
PCle 4.0 x16 xl
PCle 4.0 x8×1
PCle 4.0 x4×1
扩展接口
PCle 4.0 xl×1
PCle 4.0 x4 M.2x2
SATA 6Gbps x8
音频芯片 ROG SupremeFX S1220 8声道音频芯片
网络芯片
瑞昱RTL8125-CG 2.5G有线网卡
英特尔1211-AT千兆网卡
英特尔Wi-Fi 6 AX200+Bluetooth v5.0无线网络模块
背板接口 USB 3.2 Gen l+USB 3.2 Gen2 Type-A/C+RJ45+模拟音频7.1声道接口+S/PDIF光纤输出+Wi-Fi天线接口
参考价格 新品待定
充分发挥Zen 3处理器最大性能还有三员大将来助力
除了GROSSHAIRⅦDARK HERO主板,为了充分发挥出锐龙9 5950X处理器的最大性能,我们还请来了三员大将进行辅助,它们是:
三星980 Pr0 1TB NVMe M.2 SSD
从Pro的后缀就可以看出,它是三星最新的旗舰级SSD,采用了三星支持PGle 4.0技术的Elpis主控。该主控采用三星自研的8nm生产工艺打造,支持NVMe l.3c技术标准、PCle 4.0 x4传输带宽。闪存方面,这款SSD使用了三星最新的1 36层堆叠V6 TLC闪存颗粒,相对上代的92层堆叠颗粒,增加了40%的存储密度,并减少了15%的能耗,带来了更强的性能。其处理读取、编程请求的响应速度提升了10%。经我们实测在基于锐龙9 5950×的PCle4.0平台上,其最大连续读写速度突破6700MB/s,单线程随机4KB性能突破21000 IOPS,AS SSD BENICHMARK总分达到8987分。
美商海盗船复仇者LPX DDR4 4133内存16GB套装
虽然低矮的外形、没有RGB LED的设计让这套内存从外表看起来很主流,但在性能上它却超过了很多高端产品。该内存采用8层PCB设计,从软件侦测来看,它使用了编号为“K4A8G085\NB-BGPB”的三星B-Die颗粒,因此其官标默认频率就达到了DDR4 4133。值得一提的是,海盗船还随内存附赠了一套内置风扇的主动式内存散热器,可以安装在内存上方,自上而下向内存输送强劲的风力,使内存保持在很低的工作温度。经我们测试即便在DDR4 4133下通过AIDA64内存烤机测试烤机半小时,内存散热片上的工作温度也不到36℃。
恩杰NZXTKraken海妖273360mm水冷
它是恩杰NIZXT散热器中定位高端的水冷产品,采用长度在390mm、厚度在28mm左右的大型冷排,可安装三把内置FDB液态轴承,采用倒角进气口设计的高性能Aer P风扇,兼具静音与散热性能。更值得一提的是,这款产品还使用了由纯铜打造、尺寸为79mmx79mmx52mm,提供六年质保的Asetek第七代水泵,让用户能安心使用。此外,该水冷的导液橡胶管由细尼龙网套包裹,能让产品更加耐用。与其他水冷产品最大不同是,该水冷的水冷头还内置了一块24bit色彩的2.36英寸液晶屏幕,不仅可以显示处理器的工作温度,用户还能加载自己的个人照片、搞笑GIF、标志性Logo,让您的水冷在外观上更具个性。
测试平台
主板:ROG CROSSHAIRⅦDARK HERO主板
处理器:锐龙9 5950X、锐龙9 3950X、酷睿19-10900K
内存:美商海盗船复仇者LPX DDR4 4133 8GBx2
硬盘:三星980 PROITB
显卡:GeForce RTX 3090
电源:ROG THOR1200W
接下来我们搭配目前性能最强的GeForce RT×3090显卡对锐龙9 5950X进行了测试。我们还加入了其上代产品,同为16核心、32线程设计的锐龙9 3950X,以及在游戏性能上表现突出的英特尔酷睿i9-10900K与它进行了对比测试。
大获全胜处理器性能测试
测试点评:从实际测试来看,锐龙9 5950X的表现显然令人惊喜。对锐龙9 3950X、酷睿i9-10900K形成了碾压,其测试结果完全符合AMD IPC性能提升19%的宣传——在PerformanceTest10.0 CPU单线程性能测试中,锐龙9 5950X领先锐龙9 3950X达27.4%;在CPU-Z处理器单线程性能测试中,锐龙9 5950X的分数高达689.5,领先酷睿i9-10900K达12.9%;在Geekbench 5处理器单核心性能测试中,锐龙9 5950X也有15.9%的优势。更让人值得赞叹的是,AMD处理器首次在Super Pi-百万位测试中也战胜了目前英特尔单线程性能最强的处理器,其运算时间比酷睿i9-10900K少了0.014秒。主要原因除了Zen 3架构带来的技术升级外,从我们测试观察来看,锐龙9 5950X的单核加速频率其实也超越了官方标准,达到了最高约5.04GHz,AMD处理器也终于进入了5GHz时代。当然,酷睿i9-10900K借助TVB加速技术,其最高单核心频率可以达到5.3GHz,但由于技术架构不敌Zen 3,因此频率更高的它反而无法战胜锐龙9 5950X。
大幅领先游戏性能超强的多核心处理器
测试点评:毫无疑问,锐龙9 5950X是我们所测过的1 2核心以上处理器中,游戏性能最强的产品之一。它的游戏性能不仅大幅领先于锐龙9 3950X,更超越了之前的“游戏专用处理器”酷睿i9-10900K,在1 0项测试中全胜。需要提及的是,我们的测试分辨率为1080p,并使用目前性能最强大的显卡,可以完全排除显卡性能瓶颈,充分体现不同处理器在运行游戏时的性能表现。而差异显然是很大的,在《英雄联盟》中,锐龙9 5950X的平均运行帧速比酷睿i9-10900K快了高达91.5fps;在《GS:GO》中,锐龙95950X的游戏运行帧速也比酷睿i9-10900K快了多达69.22fps;在《绝地求生:大逃杀》中的运行速度也比后者快了27.2%。两款处理器在这三款热门网游上的性能表现可以说是有质的差距。而在其他游戏中,锐龙9 5900X也拥有一定的优势,如在《全面战争:特洛伊》中,它的运行帧速也快了多达24fps。
多核心配置优势凸显处理器应用测试
测试点评:在应用测试中,凭借Zen 3架构、更强的单核心性能,以及1 6核心、32线程的配置,銳龙9 5950X同样在所有应用测试中都获得了优势明显的胜利。如与同为1 6核心、32线程配置的锐龙9 3950X相比,它的V-RAY渲染性能、GINIEBENCH R20处理器多核心渲染性能分别提升了8.3%、14,7%,其Handbrake视频转码速度提升了12.5%,7-2ip压缩与解压缩性能也提升了11.5%。与核心数只有1 0颗的酷睿i9-10900K旧比,它的优势则是压倒性的,其V-RAY渲染性能比酷睿i9-10900K领先了60.8%,7-2ip压缩与解压缩性能的领先幅度则高达93.1%,甚至在依赖处理器单线程性能的PhotoShop图片处理中,酷睿i9-10900K的处理速度也慢了近8秒,锐龙9 5950X的速度快了8.8%。
满载功耗不升反降处理器功耗与温度测试
测试点评:在功耗与温度测试上,锐龙9 5950X也为我们带来了意外的惊喜,该处理器的满载功耗、满载温度均小幅低于上一代1 6核心处理器锐龙9 3950X,体现出更好的能耗比,其在满载烤机状态下的全核心频率也有约3.9GHz,但处理器的功耗与温度都控制得比较好。
还可提升全核心性能处理器超频性能测试
最后我们还使用ROG CROSSHAIR、Ⅷ DARK HERO主板对锐龙9 5950X处理器进行了超频测试。从测试来看,由于该处理器在默认设置下的最高单核心加速频率就可以达到5.OGHz以上,但要在水冷环境下再提升到5.1GHz左右就比较困难了,所以对于这款处理器在普通散热环境下没必要再进行以提升频率为主的单核心超频。不过在全核心超频上,它还提供了一定的空间。从测试观察来看,这款处理器在运行CINIEBENCH R20时的全核心频率也就在3.8GHz左右。而如果将处理器的工作电压设置为1.36V左右,我们则可将它稳定运行CINEBENCH R20时的全核心频率提升到最高4.5GHz。在这个频率下,锐龙9 5950X的CINIEBENCHR20多核心渲染性能提升到了11626pts,《鲁大师》处理器性能提升到436925分,SiSoftware Sandra处理器算术性能达到683.7GOPS,较默认频率下分别提升19.1%、15.4%、15.1%,提升还是非常显著的。
兼具游戏性能与多核心性能的完美作品
综合以上测试来看,得益于单核心性能的大幅提升,在游戏性能方面,锐龙9 5950X能在所有测试游戏中力压之前的“游戏专用处理器”酷睿i9-10900K,而且在《英雄联盟》《CS:GO》《全面战争:特洛伊>等游戏中还具备很大的优势;在实际应用、多核心性能上,它也将同为1 6核心、32线程的锐龙9 3950X甩在身后,在基于双通道内存的主流电脑平台中,其多核心性能无人能敌,且并没有增加处理器的功耗、温度。毫无疑问,借助Zen 3架构、7nm生产工艺,AMD最新推出的1 6核心旗舰锐龙9 5950×就是兼具游戏性能与多核心性能的完美作品。
全面领先锐龙9 3900XT\酷睿i 9--10900 K
12核心次旗舰锐龙9 5900X处理器首测
锐龙9 5900X+技嘉B550 AORUSMASTER主板展示
接下来我们将要测试的就是本次Zen 3处理器中的次旗舰产品:锐龙9 5900X处理器。考虑到锐龙9 5900×的定位为次旗舰,因此在本次测试中,我们也采用了类似定位的主板来进行测试,它就是来自技嘉的B550主板:B550 AORUS MASTER。
虽然B550芯片组的规格比X570低一些,但型号上“AORUSMASTER”的出现则意味着这款主板的定位偏中高端,就像锐龙95900X-般,它也是一款仅次于X570 AORUS MASTER的次旗舰。首先从做工用料上来看,B550 AORUS MASTER主板的设计就远好于其他B550主板。该主板采用了先进的14+2相直出式供电设计,我们知道,由于大部分PWM芯片难以直接控制、管理大于1 0相的供电电路,因此主板厂商要么需要增加倍相芯片,要么需要并联设计来实现等效的多相供电电路。但这些方法可能会增加工作的步骤、多余的芯片,会造成一定的损耗。因此技嘉在部分高端主板上采用了直出式数字供电。所谓直出式就是通过新型PWM芯片直接控制每相供电电路,既不需要增加额外的倍相芯片,也不需要采用并联设计,理论上可以精准地平衡每相供電电路的负载,精确地进行电压调节,大幅提高供电效率,降低供电电路的发热量。因此技嘉为B550 AORUS MASTER采用了具备直接支持1 6相供电能力的英飞凌XDPE132G5G PWM芯片,目前鲜有PWM芯片具有直接控制16相供电电路的能力,英飞凌XDPE132G5C是为数不多的产品之一。同时,技嘉还为B550 AORUS MASTER搭配了支持70A电流负载的英飞凌TDA21472-体式MOSFET、服务器级电感,日系FPCAP黑化版固态电容,并采用了8+4Pin供电接口。其内部由实心结构的GPU供电插针组成,相对普通供电接口内部的空心插针,它能有效降低阻抗与发热量。整体来说,B550 AORUS MASTER可以轻松支持对TDP为105W的锐龙95900X、锐龙9 5950X的超频,并保持较低的工作温度。
在PCB部分,这款主板依然延续了技嘉传统的两倍铜即现在所称的2盎司纯铜电路板设计,即在印刷电路的电源层与接地层采用2盎司纯铜箔材质降低PGB阻抗,提升PCB散热性能与电源转换效率。同时,这款主板在供电部分还搭载了内置直触式热管,比传统铝挤散热片多三倍散热面积的Fin-Arrays堆栈式散热鳍片。该鳍片搭配1.5mm厚的LAIRD 7.5W/mK高导热系数导热垫,在同样的工作时间下,可提供比传统导热垫更好的散热效果。
存储接口方面,除了6个SATA 3.0接口外,该主板还提供了三个M.2 SSD插槽。这三个插槽的带宽都由CPU提供,都能支持PCle 4.0 x4,拥有多达8G B/s带宽,最高支持长度为110mm的221 10大型M.2 SSD。当然,需要注意的是,其中两个M.2 SSD插槽的带宽来自GPU提供给显卡的带宽,因此在这两个插槽上安装SSD的话,显卡带宽会降低到PCle 4.0 x8,也就是相当于PCle3.0 x16。根据我们的测试来看,这对GeForce RTX 3000系列显卡来说,几乎没有明显的性能影响。此外,这三个M.2插槽还配备了技嘉特制的M.2合金散热装甲,以及帮助SSD与散热片紧密接触的导热垫,可以有效降低SSD工作温度,避免降速。
随着近几年FPS游戏的强势崛起,玩家们也逐渐意识到游戏音效的重要性,所以越来越多的玩家看重主板在音效方面的表现,而B550 AORUS MASTER就是一款拥有出色音效的主板。其音频系统以瑞昱ALC1220-VB音频芯片为核心,同时辅以日系高品质音频专用电容、WIMA发烧级音频电容。不仅如此,B550AORUS MASTER还支持DTS:X Ultra,并且通过了Hi-ResAudio认证,让用户不论是在使用耳机还是音箱进行游戏时,都可以感受真实再现、定位精准的3D音频体验。
在网络性能方面,B550 AORUS MASTER同样走在时代前沿。这款主板搭载了瑞昱RTL8125BG有线网卡,其最大理论传输速率达到2.5Gbps,相比普通主板的干兆有线网卡,前者可提供比传统干兆网卡更高的网络带宽,并且为游戏玩家们提供更快的联网体验。随着Wi+i 6的迅速普及,目前不少高端主板都已支持Wi-Fi 6,B550 AORUS MASTER也不例外。它搭载了英特尔Wi+i6 AX200无线网卡,在5GHz@160MHz频段下的理论传输带宽可提升到2.4Gbps,相对带宽1.73Gbps的Wi+i 5有明显提升。
当然B550 AORUS MASTER主板也不会缺少技嘉传统的RGB FUSIONI炫彩魔光灯效,主板I/O装甲处设计了多颗RGBLED,并提供了12V 5050(GRBW) 4pin、5V 3pin RGB接口,可以连接各类灯带、RGB发光设备,并通过RGB FUSION 2.0灯效控制软件设置为相同的模式同步发光。
接下来我们通过技嘉B550 AORUS MASTER主板,搭配目前性能最强的GeForce RTX 3090显卡对锐龙9 5900X进行了测试。为了让大家更直观地认识锐龙9 5900×的性能,我们还加入了其上代产品,同为1 2核心、24线程设计的锐龙9 3900XT,以及价格与其接近,目前售价为41 99元的酷睿19-10900K与它进行了对比测试。
技嘉B550 AORUS MASTER主板产品规格
接口:Socket AM4
板型:ATX
内存插槽:DDR4 x4(最高128GB DDR4 5200)
顯卡插槽:PCle 4.0 x16×1
扩展接口:PCle 3.0 x4 x2、PCle 3.0 xl、PCle 4.0 x4
M.2 SSD x3、SATA 6Gbps×6
音频芯片:瑞昱ALC1220-VB 7.1声道音频芯片
网络芯片:瑞昱RTL8125BG 2.5G有线网络芯片
英特尔Wi-Fi6 AX200+蓝牙5无线网络模块
背板接口:USB 3.2 Gen 2 Type-A/C+USB
2.O+RJ45+模拟音频7.1声道接口+HDMI+无线天线接口
参考价格:2098元
测试平台
主板:技嘉B550 AORUS MASTERE主板
处理器:锐龙9 5900X、锐龙9 3900XT、
酷睿i9-10900K
内存:海盗船VENGEANCE LPX DDR4 4133 8GBx2
硬盘:三星980 PROITB
显卡:GeForce RTX 3090
电源:技嘉AORUS 850W全模组金牌电源
优势明显锐龙9 5900X处理器性能测试
测试点评:从测试结果可以看到,就像锐龙9 5950X-样,Zen 3架构为锐龙9 5900X的处理器性能同样带来了很大的提升。相对于第三代锐龙处理器中单核心性能最强的产品:锐龙93900XT,它的单核心性能在PerformanceTest 10.0 CPU单线程性能测试中提升了多达23.4%;在CPU-Z 1.94处理器单线程性能测试中提升了19.8%。与英特尔目前单核心性能最强的产品酷睿i9-10900K相比,锐龙9 5900X也毫无惧色,在绝大部分测试中都获得了胜利,如在Geekbench 5的处理器单核心性能测试中,它的性能领先幅度高达12%,而在多线程性能测试上,凭借更多的核心数,锐龙9 5900X则实现了对对手的彻底碾压。
唯一告负的是在Super Pi-百万位测试中,锐龙9 5900X不敌酷睿i9-10900K,也不如之前测试过的锐龙9 5950X,消耗时间要稍多一点。从我们测试观察来看,可能是为了区别定位,实测中显示,锐龙9 5900X在单核心任务中的最高加速频率在4.94GHz左右,虽然超出了其官方最高4.8GHz的指标,但仍比锐龙9 5950X在实测中单核最高可加速到5.04GHz,以及酷睿i9-10900K最高5.3GHz的频率低。
压到性的优势适合游戏的处理器
测试点评:在游戏玩家最关心的游戏性能测试,就如锐龙95950X,锐龙9 5900X的优势同样非常明显,在总计十款游戏性能测试中也都获得了全胜。相比锐龙9 3900XT,单核心性能大幅提升的锐龙9 5900X优势很大,毕竟目前能用到处理器全部计算线程的游戏很少,尤其是在《英雄联盟》《CS:GO》《绝地求生:大逃杀》这类热门网络游戏上,因此单核心性能就成了保证游戏性能的关键。可以看到,锐龙9 5900X在这两款游戏上的运行帧速分别比锐龙9 3900XT快了50.3%、41.8%、41.8%。即便与曾经的“游戏处理器王者”酷睿i9-10900K相比,锐龙9 5900X的帧速也分别快了40.2%、21.1%、26%,优势非常大。同时在其他游戏中,凭借更强的单核心性能,锐龙9 5900X也有明显的优势。如在《坦克世界》中,它的平均帧速领先酷睿i9-10900K约16fps;在《全面战争:特洛伊》中,它的游戏平均运行帧速速度领先酷睿i9-10900K达21.2%。毫无疑问,优秀的单核心性能大幅提升了Zen3处理器的游戏性能,将对比处理器远远甩在身后。
多核心性能优势凸显处理器应用性能测试
测试点评:在实际的应用测试中,同样IPC性能更高的锐龙95900X优势明显,在所有测试中获得全胜。其中在CINEBENCHR20处理器多核心渲染性能测试中,它分别领先锐龙9 3900XT、酷睿i9-10900K达20.3%、34.5%。在实际的应用中,由于目前大部分应用都会调用处理器的多颗核心运算,因此在V-RAY渲染引擎测试中,锐龙9 5900X的渲染性能也大幅领先两款对比产品,尤其是较核心数偏少的酷睿i9-10900K,其领先幅度更达到了36%。而在7-2ip压缩与解压缩性能测试中,锐龙9 5900X较酷睿i9-10900K的领先幅度更扩大到了惊人的63.6%。同时,在Handbrake 4K视频转1080p H.264视频测试中,锐龙9 5900X的转码速度也比酷睿i9-10900K快了28%。同样,在执行依赖单核心性能,包括色彩转换、“调色刀”、“海绵”滤镜等15项工作的PhotoShop应用体验中,酷睿i9-10900K的运行速度也比锐龙95900×慢了7.5%,消耗的时间多了6.5秒。这意味着Zen 3在日常工作中也能帮您节约时间。
压力不大功耗与温度测试
测试点评:在功耗与温度测试中,由于锐龙9 5900X与锐龙93900XT都采用相同的台积电7nm工艺生产,因此不论是功耗还是温度,它们的表现都非常接近,频率更高的锐龙9 5900X的满载功耗与温度要稍低一些,体现出更好的能耗比。值得注意的是,在同时将CPU、FPU、CACHE三部分的负载提升到最大的AIDA64处理器满载测试中,运行1 5分钟后,技嘉B550 AORUS MASTER主板供电部分的温度并不高,最高温度只有60℃左右,显示出其1 6相直出式供电的优异性。
处理器全核心超频可达4.6GHz内存频率轻松超越DDR4 4500
最后我们还通过技嘉B550 AORUS MASTER主板對锐龙9 5900X进行了超频测试。从超频测试来看,在使用恩杰NIZXTKraken海妖273-体式水冷的环境下,锐龙9 5900X进行全核心超频所能设置的最高电压还是在1.36~1.38V左右,能通过CINEBENGH R20的全核心超频频率为4.6GHz。CINEBENCHR20多核心渲染测试成绩从默认的8525pts提升到9080pts,SiSoftware Sandra处理器算术性能从495.33GOPS提升到526.31GOPS,超频提升幅度分别达6.5%、6.25%。当然你也可以关闭部分核心,对锐龙9 5900X进行单核或双核心超频,我们在只开启两颗处理器核心的情况下,也可以将锐龙9 5900X的频率轻松超频到5.05GHz左右,令其Super Pi一百万位运算时间缩短到7.032秒。
此外,借助技嘉B550 AORUS MASTER主板,锐龙95900X也拥有很强的内存超频能力,在1.5V内存电压,20-25-25-45延迟设置下,最高可将美商海盗船VENIGEANCE LPX DDR44133内存超频到DDR4 4733,在AIDA64 6.30测试中带来接近70000M B/s的内存读取带宽。
在中高端市场更具购买价值
综合以上测试,我们认为借助Zen 3架构,19%的IPC性能提升,锐龙9 5900X完美地完成了在中高端处理器市场狙击对手,大幅提升游戏性能的任务——在所有测试游戏中,它的游戏性能都明显强过酷睿i9-10900K,在《英雄联盟》《CS:GO》《绝地求生:大逃杀》这类网游中还具备很大的优势;同时单核心性能的提升,也让它的多核心性能最终变得更强,在图形渲染、视频转码、压缩与解压缩等应用与竞争对手拉开了更大的差距,甚至在依赖单核心性能的PhotoShop中,Zen 3也能获得优势。价格方面,与售价仍在4199元的酷睿i9-10900K相比,它的售价更合理。对于那些需要同时获得游戏性能、多核心性能,但预算不是太多的用户而言,锐龙9 5900X就是比酷睿i9-10900K更合理的选择。
不仅能超处理器,还能将Infinity Fabric频率超上2000MHz!
Zen 3处理器+主流500系主板超频实战
七彩虹X570M GAMING FROZWN V14 主板展示
采用Zen 3架构的AM D锐龙5000系列处理器不仅大幅提升了单核心性能,还有效提升了处理器的游戏性能、多核心性能,令锐龙5000系列成为一款兼得游戏性能与多核心性能的完美产品。根据AMD的官方消息,采用500系主板就能支持Zen 3处理器,那么除了功能丰富、供电豪华的中高端500系主板,定价在干元左右的主流的500系主板能否很好地支持Zen 3处理器,是否还能对它进行处理器超频与内存超频呢?我们特别选用了一款来自七彩虹的X570M GAMING FROZENV14主板进行测试。
该主板采用Micro-ATX小板设计,售价仅1 099元,与不少仅部分支持PCle 4.0技术的B550主板差不多,却板载完全支持PGle 4.0的X570主板芯片组,并提供了一个PGle 4.0 x16显卡插槽,一个PGle 4.0 x4插槽,以及两个支持PCle 4.0 x4标准的M.2 SSD接口、6个SATA 6Gbps接口,足以满足主流用户的需求。而这款主板之所以在型号上带有“FROZEN”(寒霜)是因为整块主板均配备了被称为“寒霜散热装甲”的亮银色铝合金散热模块。
供电方面,它采用了4+2相供电设计。其中为处理器核心供电的每相供电包含有两上两下四颗MOSFET,两颗电感,等效为8相供电。上桥MOSFET采用了来自万国半导体的AON16414A,其内阻值在10V电压下低于8mQ,典型承载电流值为30A,最高可达50A。下桥MOSFET同样来自万国半导体,不过型号换为A0N6354。这款MOSFET的性能更为优异,在10V电压下的内阻小于3.3mQ,最高可承载电流达80A,在100℃高温下也能达到52A。电感部分,这款主板采用的是全封闭F.C.G铁素体电感,可以降低电感线圈对主板其他元器件的电气干扰。电容上,根据七彩虹提供的资料,这款主板采用的是10K黑金固态电容,可以提升主板的工作稳定性。
在网络部分,其网卡芯片采用了稳定、可靠的瑞昱RTL8111H干兆网卡,内置LDO低压差线性稳压器,支持AGPI高级配置和电源管理接口、高级电源管理技术。同时七彩虹还为这颗网络芯片配备了EMI保护罩,可有效提升网络稳定性,防止周边电路和电磁波对网络的干扰。音频方面,这款主板则采用了支持7.1声道输出的瑞昱ALC 892音频芯片,同时日系尼吉康专业音频电容的采用,则能让音质更加清晰、温暖、逼真。音频部分还采用了LED分割线设计,可以进一步降低主板上的高频信号噪声干扰。
七彩虹X570M GAMING FROZEN V14产品规格
接口:Socket AM4
板型:Micro-ATX
内存插槽:DDR4 x4
显卡插槽:PCle 4.O x16×1
扩展接口:PCle 4.0 x4 xl、PCle 4.Ox4 M.2SSD×2、SATA 6Gbps×6
音频芯片:瑞昱ALC 892 7.1声道音频芯片
网络芯片:瑞昱RTL8111H千兆有线网络芯片
背板接口:USB 3.2 Gen l Type-A/C+USB 2.O+USB 3.2
Gen 2+RJ45+模拟音频711声道接口+HDMI+DP+PS/2
参考价格:1099元
碾压10900K正常发挥Zen 3处理器的最大性能
我们首先采用X570M GAMING FROZEN V14主板、GeForce RT×3090显卡对锐龙9 5900X处理器进行了测试。值得赞叹的是,作为主要主板厂商,七彩虹也早早为它的500系主板更新了BIOS,将AGESA(AMD通用封裝软件架构)升级到1.1.0.0版本,使得主板可以轻松支持最新的Zen 3处理器。从默认频率下的性能测试来看,X570M GAMING FROZENI V14主板显然可以充分发挥出锐龙9 5900X处理器的最大性能,不论是单核心性能还是多线程性能、游戏性能,锐龙9 5900X在各项性能测试中的表现都远远超越酷睿i9-10900K,展现出了Zen 3架构的技术实力。如在SiSoftware Sandra处理器算术性能测试中,锐龙95900X领先酷睿i9-10900K达23.2%,在《英雄联盟》游戏性能测试中,锐龙9 5900×的平均运行帧速比酷睿i9-10900K快了高达40.5%。
只需三步主流主板可轻松提升Ze n 3处理器多核心性能
接下来,我们使用X570M GAMING FROZEN V14主板对锐龙9 5900X的超频性能进行了测试。根据我们的多次尝试来看,在普通散热环境下,用户能有效提升的是锐龙9 5900×的多核心性能,但难以大幅提升它的单核心性能。原因很简单,锐龙95900X在默认设置下的单核心最高加速频率就达4.9GHz左右,已经接近单核心稳定运行的极限(在5.05GHz左右),另外超频时还需要关闭其他核心,才能令程序强制使用超频后的那颗核心,因此这样的单核心超频实用意义不是太大,所以能有效提升多核性能的全核心超频更具实用价值。
而在运行CINEBENGH R20这样的渲染测试时,锐龙95900×的最高频率在4.3GHz左右,因此进行全核心超频的目标是必须高于4.3GHz。而经我们的多次测试来看,在使用恩杰NIZXT Kraken海妖273 360mm水冷散热器的环境下,X570MGAMING FROZEN V14主板最高可将锐龙9 5900X的所有核心超频到4.6GHz,带来明显的多线程性能提升,其方法也非常简单:
首先在AMD官方网站下载并启动最新版本的RYZENMASTER,点击选中“Profile 1”,再点击右上角的“手动”,你就可以对处理器进行手动超频了。
接下来通过RYZEN MASTER你也可以看到Zen 3处理器最大的不同之处——只有—左一右的两个CCD大方框,也就意味着处理器内部只有两个CCD模块。此时点击CCD 0方框左侧的红色圆形标识,将其变为绿色也就意味着你开启了“将一个核心的频率镜像到所有核心”的功能,此时你只要设置一颗核心的频率,就能同步对其他核心进行相同的设置。
最后任意设置一颗处理器核心频率为4600即可将处理器的目标频率设置为4.6GHz,然后进行最重要的一步,小幅提升处理器的工作电压。锐龙9 5900X在运行CINIEBENCH R20时的处理器工作电压在1.34—1.35V左右,要想提高频率后继续稳定地运行渲染测试,需要我们将处理器工作电压调节在1.36—1.38V这个区间。要达到这个电压,在X570M GAMING FROZEN V14主板上,我们只需要将RYZEN MASTER的“电压控制”数值设定为“1.29375V”即可。可能由于软件的侦测误差,也可能是主板处理器核心电压存在一个小幅加压,虽然设置的这个电压数值低于1.3V,但处理器运行CINIEBENCH R20的实际电压数值在1.376V左右,而这一电压也可以保证处理器超频后稳定地运行各类多线程软件,并带来性能上的提升。如CINEBENGH R20处理器多核心渲染性能从8471pts提升到9120pts,提升幅度达7.6%。
可对lnfinity Fab rIc总线超频内存可轻松超频到DDR4 4000以上
除了处理器超频,我们发现X570M GAMING FROZENV14主板还具备一个非常强劲的能力,可对处理器的Infinity Fabric总线超频,增强处理器对高频内存的支持能力,并减少延迟。InfinityFabric总线是锐龙处理器内部芯片之间的互联总线,其默认最高工作频率一般在1800MHz左右,处理器内部需要通过它将内存数据传送给处理器,因此在默认设置下,Infinity Fabric的总线时钟频率与内存时钟频率以1:1的方式捆绑在一起。简单来说,工作在1800MHz下的Infinity Fabric总线的等效数据传输带宽与DDR43600内存相同,但如果用户使用频率更高的内存,如DDR44000,而Infinity Fabric总线频率仍保持为1800MHz的话,那么就必须等待速度慢的Infinity Fabric总线将数据传输完毕后,才能进行下—次传输,造成额外的延迟。
而在Zen 3处理器上,AMD提升了这一代处理器的InfinityFabric总线时钟频率的超频能力,在普通散热环境下最高可以达到2000MHz,也就是说能对DDR4 4000内存提供完美支持,不过需要主板BIOS进行相应的更新。而在Zen 3发布之初,经我们测试,七彩虹X570M GAMING FROZEN V14主板完美地实现了这个目标。超频方法也很简单,只需两步:
首先根据自己所用的内存体质,在七彩虹X570M GAMINGFROZEN V14主板BIOS中设置内存电压,在这里我们设置的电压为1.5V。
接下来在RYZEN MASTER“Profile 1”选项卡中开启手动模式的情况下点击“内存控制”,将“耦合模式”设置为“开”,保证内存频率与Infinity Fabric总线频率可以同步超频,接下来将内存频率、Infinity Fabric频率同时从“1800”设置为“2000”,并根据自身所用内存体质设置各个延迟参数后,点击应用重启即可。
可以看到,在七彩虹X570MGAMING FROZEN V14主板将处理器Infinity Fabric总线时钟频率超频到2000MHz,与DDR4 4000同步后,处理器的内存性能有了明显的提升,与1800MHz下的DDR4 4000内存相比,内存的读写、复制带宽都有明显增长,更值得一提的是,内存的访问延迟从65.3ns大幅降低到55.4ns,减少了接近10ns。
当然如果您只追求内存频率,也可以将Infinity Fabric总线时钟频率固定在1800MHz,只提升内存频率。根据我们的测试,在使用海盗船VENGEANCE LPX DDR4 4133内存,1.5V电压设置,22-22-22-52延迟设置下,七彩虹×570M GAMINGFROZEN V14主板最高可将内存频率超频到DDR4 4400,令内存的读取带宽接近65000M B/s。
主流500系主板就能玩转Zen 3处理器
综合来看,采用七彩虹X570M GAMING FROZEN V14这类主流主板,我们就能很好地使用Zen 3处理器,充分发挥Zen 3处理器优秀的单核心性能、游戏性能、多核性能。而借助RYZENMASTER超频软件,我们既能简单、轻松地对Zen 3处理器进行全核心超频,也可以对Infinity Fabric总线时钟频率、内存频率进行超频,有效提升AMD平台的内存性能。因此对于预算有限的用户而言,选择一款像七彩虹X570M GAMING FROZEN V14这样做工扎实、BIOS更新快的干元级主流主板就能让您轻松玩转大部分Zen 3处理器。
