一种适用于中文NER的自适应混合编码模型*
2020-01-18刘凯洋
刘凯洋
一种适用于中文NER的自适应混合编码模型*
刘凯洋
(深圳职业技术学院 人工智能学院,广东 深圳 518055)
由于具有特征自学习性特性,LSTM被越来越多地应用在自然语言处理(NLP)中的命名实体识别(NER)领域,并取得较优的性能.本文提出一种新颖的词语-字符自适应混合编码算法,在已有的字符和词语信息的基础上,突破词语信息的局部性限制,基于语料库进行词语全局特征的提取与选择,并将此全局特征与局部特征(字符信息)进行叠加,帮助WC-LSTM捕获更多的文本特征.实际数据实验结果表明,与最新的WC-LSTM相比较,本文提出的自适应编码可以较为明显地提升LSTM在NER上的性能.
NLP;NER;LSTM;深度学习
1 问题概述
作为自然语言处理(NLP)中一个重要的领域,命名实体识别(Named Entity Recognition,NER)受到越来越多的关注.NER问题可以转换为标签序列标注问题,从而利用已有的序列标注和预测方法,包括朴素贝叶斯方法、隐马尔科夫链、神经网络等.最新的研究表明,针对常见的英语NER问题,通过利用字符与单词混合编码,LSTM-CRF模型能够取得较优的性能[1-4].与英文NER问题相比较,中文NER问题具有一些不同特性,导致LSTM-CRF模型的性能下降较为明显.以“李朝阳先生访问了北京大学”为例,因为中文中不存在明显的词语界限,如果采取先分词的方法,则存在歧义性.例如,“李朝阳”可能会被切分为“李”、“朝阳”,因为朝阳在汉语中是一个常用的词语,表示早晨的太阳或者北京的一个区.如果仍然采用英文NER中的词语切分-序列标注方法,则词语切分步骤中引入的歧义性会影响后续的序列标注步骤,可能引起错误传递问题从而导致性能下降.例如,如果“李朝阳”被切分为“李”、“朝阳”,则有可能被标注为李-O,朝阳-O或朝阳-Loc,但是正确的标注应该是李朝阳-Per.“北京大学”也存在同样的问题,如有可能切分为“北京”和“大学”,而不是作为一个整体对待.
最新的中文NER模型同时考虑字符信息和词语信息(混合模型)[1,5-7].这些模型在基于字符LSTM的基础上,将词语信息作为额外的输入,从而提升模型性能.Lattice LSTM存在的主要问题在于其输入数据长度可变,并在极端情况下会退化成为基于字符的LSTM.文献[5]提出基于词语-字符的混合编码策略,分别是Shortest Word First、Longest Word First、Average和Self-Attention,从而改进了Lattice LSTM的上述问题,但只考虑了词语集合的局部信息,没有考虑词语在语料库中的全局信息.
本文提出一种自适应的混合编码方式,通过对全局信息进行考虑,从而挑选出重要的词语,提升中文NER性能.自适应的混合编码建立在如下的直觉感觉:给定一个词语集合中,在训练集中出现概率高的词语具有更多的信息量,在测试集出现的概率也更高.因此,我们更多的考虑这些相对出现概率高的词语信息,从而实现既考虑局部信息(字符信息),同时也包含全局信息(重要词语).通过对实际语料库进行实验表明,与目前最优文献[1]的局部编码方式相比,本文提出的自适应混合编码能取得较好的中文NER性能.
2 问题定义与自适应混合编码
与文献[5]相同,本文提出模型基于文献[1]的算法,因此先引入Lattice LSTM模型定义.
2.1 BiLSTM定义

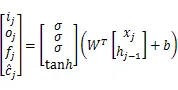
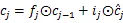
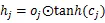


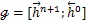
2.2 Lattice LSTM及混合编码

如图1中(a)和(b)所示,与BiLSTM相比较,Lattice LSTM增加了一个捕捉词语信息的神经元(图1(b)中标注为“w”神经元),从而提升模型性能.图1(b)同时也展示了Lattice LSTM的潜在问题,即神经元的输入数量可能不一致,如最后一个和字符“学”对应的神经元有3个输入,其原因在于匹配的词语数量有差异.
为解决上述的Lattice LSTM问题,文献[1]提出一种基于词语-字符混合编码的模型WC-LSTM,对于每个字符神经元,增加一个固定的词语信息输入,解决了Lattice LSTM的神经元输入数量不一致的问题及神经网络退化问题,其对应的模型如图2所示.
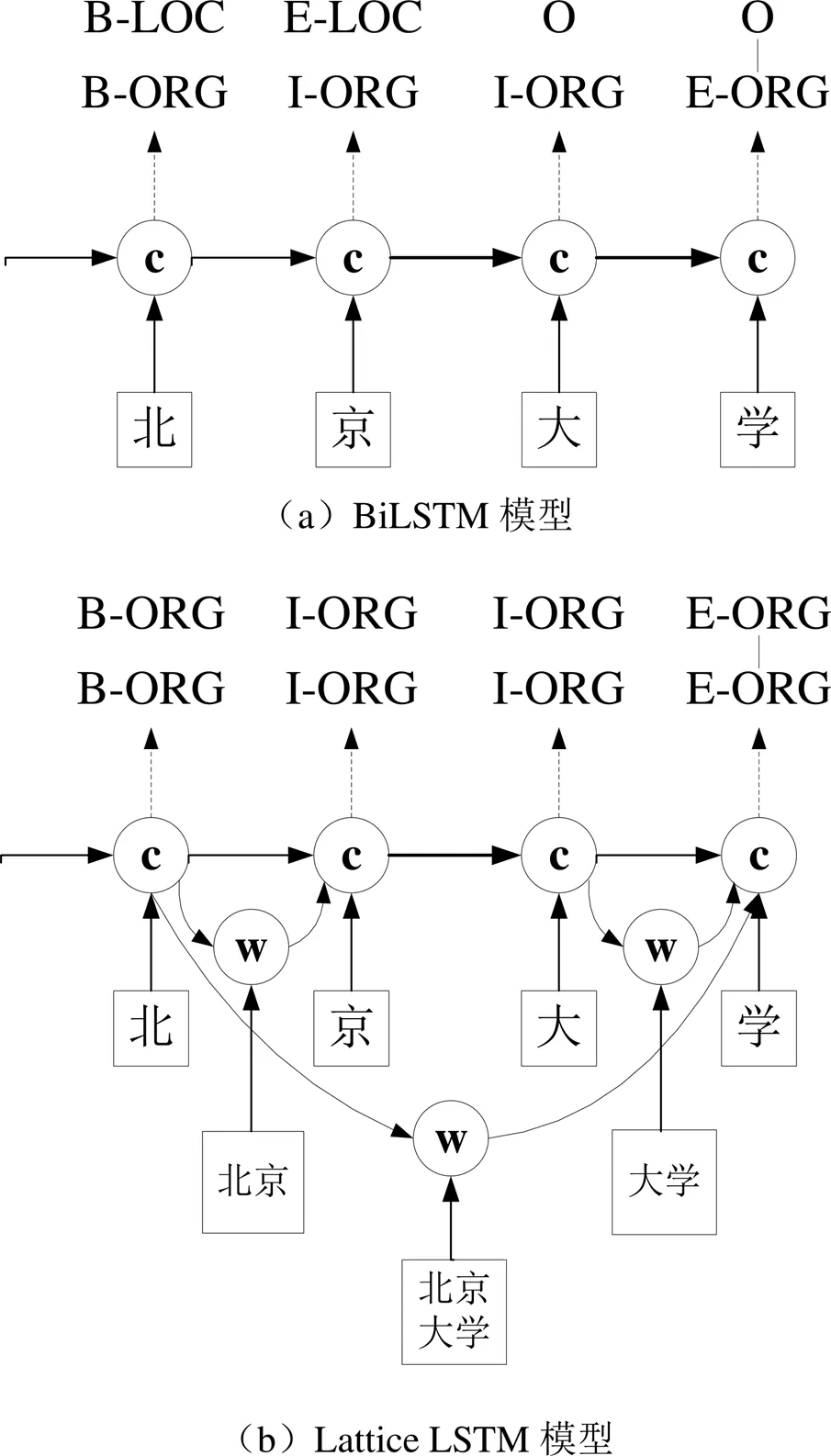
图1 BiLSTM与Lattice LSTM模型对比

图2 基于混合编码的WC-LSTM示例
2.3 自适应合编码
图2所示的WC-LSTM的主要改进之处是为每个字符神经元增加了一个记录词语信息的输入.匹配一个字符的词语可能有多个,我们以最后一个字符“学”为例,其匹配的词语集合包括“大学”、“北京大学”,因此模型需要采用一定的策略,实现从匹配的词语集合中挑选一个或者多个词语,并生成固定长度的词语向量.
为解决上述问题,我们提出一种自适应编码,并用如下的例子解释其主要创新点:以“北”字为例,匹配的词语集合包括{“东北”,“华北”,“山东北”}等.其中,“东北”与“山东北”两个词语在不同的语境中可能有不同的含义,例如“我们到达了山东北”,这句话可以理解为“我们到达了 山东北”(山东的北部),也可以理解为“我们到达了山 东北”(山的东北面).选择哪个词语取决于语境和语料库特征.如果语料库中更多的是有关山东的语句,则我们期望“山东北”出现的概率比“东北”出现的概率要高;反之,则“东北”出现的概率要比“山东北”出现的要高.因此,我们提出的自适应的含义在于可以依据语料库的全局统计特征而倾向于选择最合适的词语.
自适应编码的正式定义如下:


定义两个集合:
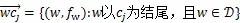


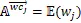
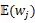
基于以上的自适应编码定义,一个基于自适应混合编码LSTM定义如下:

我们在LSTM后添加一个CRF层,并使用Viterbi算法用来对CRF的输出进行解码,具体算法见文献[1].
3 实验结果与分析
在2个真实语料库对比本文提出的自适应混合编码LSTM和WC-LSTM[1]:Weibo NER[8]及MSRA[9],其对应的统计信息见表1.
由于Weibo语料库记录数较少,因此我们采取70/15/15的方式分配训练/调试/测试数据集,而MSRA的比例为80/10/10.MSRA是中文新闻语料库,而Weibo语料库记录了微博网站上的社交媒体数据.

表2展示本文提出的自适应LSTM与WC-LSTM[1]的性能对比,可以看到基于自适应编码的模型在各指标上均要优于WC-LSTM[1],本文提出的自适应编码实现了更高的准确率,同时召回率下降幅度较小,从而达到了较高的F1.
表3展示了几种模型在Weibo语料库上的性能对比.
对比表2和表3的数据,我们发现自适应编码在Weibo语料库上的性能提升较为明显,准确率、召回率及F1都达到了目前的最优.通过对语料库及模型、实验结果进行分析可见,Weibo语料库中的数据为社交媒体数据,热点话题、热点区域、特点人物名字等出现概率较高.这些热点话题、热点区域、热点人物词语长短不一,WC-LSTM[1]无法充分利用这些信息.本文提出的自适应编码对词语长度不敏感,只对词语出现概率敏感,因此能够更多地选择这些词语作为辅助的输入信息码,提升模型的性能.

表1 实验数据集统计信息
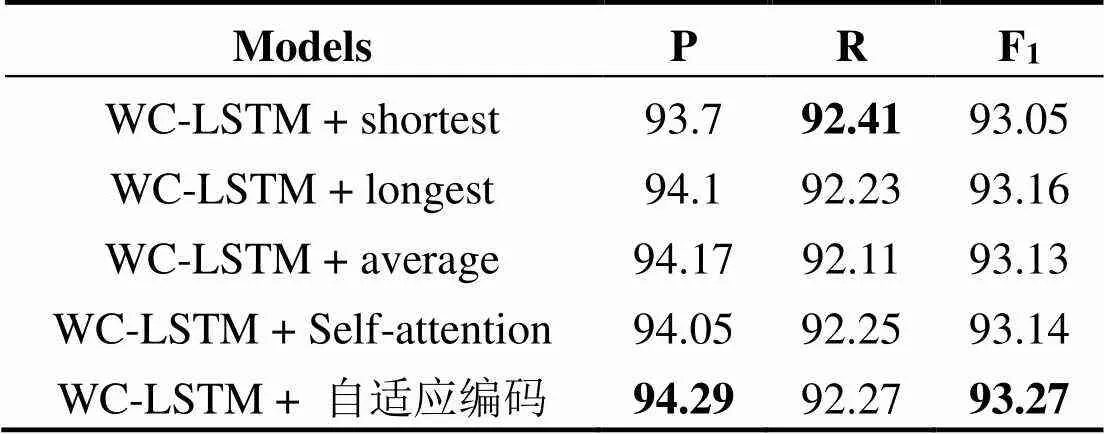
表2 MSRA语料库实验结果对比

表3 Weibo NER语料库实验结果对比
[1] Zhang Y, Yang J. Chinese NER Using Lattice LSTM [C]/Proceedings of the 56thAnnual Meeting of the Association for Computational Linguistics, 2018:1554-1564.
[2] Hammerton J. Named Entity Recognition with Long Short-term Memory [J]., 2003(4):172-175.
[3] Huang Z, Xu W, and Yu K. Bidirectional LSTM-CRF Models for Sequence Tagging[J]. arXiv: 1508.01991. 2015.
[4] Lample G, Balltesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition [C]/ NAACL-HLT, 2016:260-270.
[5] Liu W, Xu T, Xu Q, et al. An Encoding Strategy Based Word-Character LSTM for Chinese NER [C]/ Proceedings of NAACL-HLT, 2019:2379-2389.
[6] Chen X, Qiu X, Zhu C, et al. Long Short-term Memory Neural Networks for Chinese Word Segmentation [C]/Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015:1197-1206.
[7] Peng N, Dredze M. Improving Named Entity Recogni- tion for Chinese Social Media with Word Segmentation Representational Learning [C]/Proceedings of ACL, 2016.
[8] Peng N, Dredze M. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings [C]/ EMNLP, 2015:548-554.
[9] Levow G. The Third International Chinese Language Processing Bakeoff: Word Segmentation and Named Entity Recognition [C]/Proceedings of the Fifth Workshop on Chinese Language Processing, 2006:108-117.
An Adaptive Hybrid Coding Model for Chinese NER
LIU Kaiyang
()
As self-learning has its own distinctive features, LSTM has recently been widely employed to solve the Named Entity Recognition (NER) problem in Natural Language Processing (NLP), and has achieved good performance. In this paper, we propose an adaptive encoding strategy, to further improve the performance of LSTM on NER. Compared with the latest encoding strategy, our approach derives global feature of words by scanning through the entire corpus, gains insight into how to select an effective word efficiently. Besides, we enhance the ability of a LSTM to capture useful features of samples by feeding the combined information of globally selected words and character to it. Experiments on various real corpora have shown that an adaptive encoding strategy based on LSTM can significantly outperformother state-of-the-arts models.
NLP; NER; LSTM; deep learning
2019-09-02
深圳职业技术学院校级重点资助项目(6018-22K200019991)
刘凯洋,男,湖南人,博士,副教授.研究方向:大数据技术、自然语言处理、神经网络、深度学习.
TP318
A
1672-0318(2020)01-0003-05
10.13899/j.cnki.szptxb.2020.01.001
