基于树形拓扑网络的实用拜占庭容错共识算法
2020-01-17包振山王凯旋张文博
包振山,王凯旋,张文博
1.北京工业大学信息学部,北京100124
2.可信计算北京市重点实验室,北京100124
区块链技术的核心价值是能够在不可靠的网络环境中建立节点间的信任关系,从而形成去中心化的可信分布式系统[1].共识算法是区块链建立信任的核心技术[2],能使彼此不信任的参与者以分散的方式对区块链系统中事务的有效性进行验证并达成一致.共识算法的效率直接影响区块链系统的整体性能,因此研究高效的共识算法对区块链技术的发展具有积极推动作用.
针对不同的系统模型(同步和异步系统、许可和非许可系统)以及不同的故障模型(崩溃故障和任意故障),已经派生出许多不同的共识算法.能够容忍任意故障的共识算法也称为拜占庭容错(Byzantine fault tolerance, BFT)共识算法,该算法源于Lamport 等人提出的拜占庭将军问题[3].区块链系统属于典型的异步系统且系统中节点的行为是任意的,因此应用于区块链系统的共识算法应在异步模型存在拜占庭节点的情况下达成共识.比特币采用的工作量证明(proof of work, PoW)共识算法[4]的新颖贡献在于其首次实现了非许可系统模型下的拜占庭共识.尽管PoW 能够有效抵御女巫攻击[5],并在恶意节点算力不超过50%的情况下为比特币系统提供安全性保障;可事实证明在非许可模型下达成共识是有代价的,因为比特币系统每秒最多处理7 笔交易,并且每笔已确认交易的成本约为1∼6 美元[6].除PoW 之外,基于证明的共识算法还包括权益证明(proof of stake, PoS)[7]、委托权益证明(delegated proof of stake, DPoS)[8]等.PoS 通过币龄动态调整挖矿难度以降低算力消耗,但依然面临着严重的性能问题.DPoS 减少了参与共识节点的数量以提高性能,但在一定程度上违背了区块链去中心化的设计初衷.
以太坊[9]创始人Vitalik Buterin 提出了区块链的“三难困境”,即区块链系统必须在分散性、安全性和可扩展性之间寻求权衡.比特币等公有链系统属于非许可模型,其系统架构完全去中心化,并且不可靠的网络环境对系统的安全性提出了极高的要求.因此,效率问题将始终是公有链广泛应用的根本障碍.在许可模型中达成共识是典型的分布式系统问题,Paxos[10]、Raft[11]以及实用拜占庭容错(practical Byzantine fault tolerance,PBFT)[12]都是经典的分布式一致性算法.Paxos 和Raft 无法容忍拜占庭类型的故障,其应用场景一般为可信的分布式数据库系统.PBFT 是一种经典的基于状态机复制的一致性算法,能够在拜占庭节点数量不超过1/3 的情况下达成共识,具有高吞吐量和低响应时间的特点,因而广泛应用于许可链系统.随着许可链应用场景规模的逐渐扩大,PBFT 算法的可扩展性问题日益凸显.在具有n个共识节点的许可链系统中,PBFT 的通信复杂度为O(n2).随着节点数量的增加,网络中交换和处理的消息数量急剧增加.巨大的网络开销与计算开销将导致事务确认延迟显著增加,吞吐量明显降低.因此,传统PBFT 算法只适用于小规模的局域网,而在大规模的广域网环境下,其可扩展性瓶颈对许可链系统的性能带来了严重的影响.
自从出现PBFT 算法后,大量的工作分别从不同角度对PBFT 进行改进以提高其性能.MinBFT[13]、CheapBFT[14]与FastBFT[15]等方案使用安全硬件构建可信的执行环境以减少节点或通信阶段数量.例如,MinBFT 使用可信的计数器服务改进了PBFT,防止错误节点将相同的编号分配给不同的消息,从而将三阶段协议减少为两阶段协议并将参与共识节点的数量由3f+1 减少到了2f+1,其中f为系统所能容忍错误节点的最大数量.CheapBFT、FastBFT、SBFT[16]与ReBFT[17]均属于乐观的BFT 算法.乐观是指在没有错误节点的情况下仅由少量活跃节点执行共识过程以提高效率,而在错误节点数量超过一定阈值的情况下通过触发转换协议回退到“标准”BFT 算法.实际上,在大规模许可链场景下,系统发生错误的概率大幅增加,频繁的回退操作将使系统性能显著下降并处于极度不稳定的状态.基于委员会的PBFT 算法[18-19]选择网络节点的一个子集作为委员会,从而达到提高共识效率的目的,其中委员会代表系统中所有参与者执行小规模的PBFT 算法.然而,这种通过减少参与共识节点数量的PBFT 算法在很大程度上增强了许可链系统的中心化程度.基于聚合签名与Gossip 协议的BFT算法[20]的核心思想比较简单.每个节点不断组合来自邻居节点的部分聚合签名,然后传播这个聚合签名,从而降低消息传递的复杂性.基于短生命周期签名方案的PBFT 算法[21]使用低/中安全级别(56 位或80 位)的签名代替高安全级别(128 位)的签名,并定期更新短长度的密钥对以保证安全性.该方案通过改善签名的大小降低了系统的通信与计算开销,是一种较为实用的改进方案.在联盟链场景下,联盟由若干个在广域网中连接的成员组织构成,而这些组织可能在其局域网中维护着多个节点.采用分层设计的PBFT算法[22-23]将通信尽可能本地化以减少广域通信,从而降低系统的通信开销.然而,只有当每个组织都在其局域网内部署较多节点时,该方案才会表现出优良的性能.
大多数方案并不能真正为PBFT 算法的可扩展性提供显著的帮助,因为通信复杂度没有从根本上得到改善.为了重塑PBFT 算法的可扩展性从而提高现有许可链解决方案[24-26]在大规模应用场景下的适用性,本文提出了一种基于树形拓扑网络的实用拜占庭容错(practical Byzantine fault tolerance based on tree topology network,TTNPBFT)共识算法.TTNPBFT将全网范围共识拆分为若干子网范围共识,大幅降低了通信复杂度,为许可链在大规模广域网的应用与部署提供可能性.
1 预备知识
1.1 PBFT 算法
PBFT 是一种经典的状态机复制算法,也是当前主流的基于投票的区块链共识算法,能够在系统中拜占庭节点数量不超过f的情况下通过多轮消息交换达成共识.每一轮共识过程在确定的视图中执行,每个视图包括一个主节点和若干个从节点.PBFT 由一致性协议、视图更换协议和检查点协议组成,其执行过程如图1所示.

图1 PBFT 算法的执行过程Figure 1 Execution process of PBFT algorithm
在正常情况下,PBFT 执行一致性协议.所有正确节点通过一个三阶段通信过程达成共识,这3 个阶段分别为预准备阶段、准备阶段、确认阶段.在预准备阶段,主节点对来自客户端的事务请求进行排序并打包成区块,通过预准备消息将事务区块广播给从节点.接收到预准备消息后,每个从节点都会检验其有效性,并向其他节点广播一条包含区块信息的准备消息以确认从主节点是否收到了相同的事务区块,随后进入准备阶段.收集到2f+1 个匹配的准备消息后,所有节点广播一条确认消息以确保视图在准备阶段未发生变化,随后进入确认阶段.收集到2f+1 个匹配的确认消息后,节点可以确定已经达成共识,执行区块中的事务并将相应的结果返回给客户端.在整个过程中,节点接收到的所有有效的消息都应该添加到其本地消息日志中.若主节点发生故障,则从节点将触发视图更换协议,选择新的主节点并进入下一个视图,从而保证系统的活性.检查点协议会定期执行,用以保证所有节点状态的一致,并帮助节点及时清除过期的消息以节省存储空间.
在具有n个共识节点的许可链系统中,PBFT 算法的通信复杂度为O(n2).在事务请求阶段,客户端发送n条消息;在预准备阶段,主节点发送n −1 条消息;在准备阶段,所有从节点共发送(n −1)2条消息;在确认阶段,主节点及从节点共发送n(n −1)条消息;在回复阶段,客户端共收到n条消息.因此,PBFT 算法达成一轮共识,总共需要发送的消息数量为n+(n −1)+(n −1)2+n(n −1)+n=2n2.当节点数量n=200 时,网络中发送消息的数量达到80 000,这将给通信网络带来极大的负担.
1.2 树形拓扑网络
树形拓扑网络中的节点呈树状排列,整体看来就像一棵倒置的树,因而得名.树形网络是对星形网络的一种改进,因由多个层次的星型结构纵向连接而成,因而也叫多星级型网络.传统的有线电视网与光纤接入网均采用了树形网络拓扑结构.树形网络拓扑结构易于扩展,容易在网络中加入新的分支或新的节点.各分支节点对父节点的依赖性较大,如果高层次节点发生故障,那么对整个网络的影响也较大.从这一点来看,树形拓扑结构的可靠性类似于星形拓扑结构.树形网络拓扑结构是一种层级结构,适用于分等级的层次型网络系统.这种层次关系与PBFT算法中节点之间的主从关系非常相似.
2 许可链系统模型
2.1 网络假设
本文假设许可链系统中每对节点之间都通过可靠的点对点双向信道连接.虽然FLP(Fischer, Lynch, Paterson)不可能定理[27]已经证明:在允许节点出错的情况下,完全异步的分布式系统无法保证共识能够在有限时间内达成.实际上,在较弱的网络假设下,分布式系统依然能够在异步模型中保持活性[28],如部分同步[29]、间歇性同步[30].与PBFT 相同,本文假设网络是部分同步的,即消息自发送起到被目的节点接收的延迟存在上界.假设整个网络都是可访问的,也就是系统中的节点可以方便地将消息传输到任何节点.每个节点都在其本地维护一个节点列表,记录其他节点的编号、IP 地址/端口、公钥、信誉值与状态等信息.此外,还假设网络结构是动态的,即全网可以感知节点的加入与离开,这一假设可以通过在许可链系统中配置可信的证书颁发机构(certificate authority, CA)来实现[31].
2.2 对抗模型
本文假设许可链系统中共有n=3f+1 个节点,f为P2P 网络中任意时刻错误节点的最大数量.错误节点的行为可以是任意的,如相互勾结或保持沉默等.错误节点的存在可能使网络中传输的消息丢失、延迟、重复或者乱序,但本文假设对手不能无限期地延迟正确的节点.此外,还假设攻击者是算力有限的,不能破解许可链系统所使用的密码算法,从而不能伪造正确节点的签名以进行身份假冒攻击,不能由数字摘要进行逆运算获得原始信息,也不能找到具有相同摘要的两条消息.
2.3 基于信誉模型的树形拓扑通信网络
基于“化整为零”的思想,TTNPBFT 将全网范围的共识任务拆分为若干子网范围的共识任务,大幅减小了PBFT 算法的通信复杂度.TTNPBFT 借助于树形拓扑网络实现这一目标.每个父节点(非叶子节点)与其孩子节点形成一个子网,父节点担任主节点,孩子节点作为从节点.
构建可靠的树形拓扑通信网络是一项至关重要的任务.可靠性差是树形拓扑网络的一个显著缺点,并且错误节点所处的层次越高对网络造成的影响将越大,因此应尽可能地使高可靠的节点处于较高的网络层次上.TTNPBFT 通过信誉模型有效评估共识节点行为的准确性,并以此来衡量一个节点是否足够可信与可靠.基于节点的信誉值能够构建可靠的树形拓扑通信网络,一旦发现错误节点,网络结构便动态地进行调整.随着时间的推移,错误节点的信誉值逐渐减小,其影响力将越来越低.基于信誉模型的树形拓扑通信网络如图2所示.

图2 基于信誉模型的树形拓扑通信网络Figure 2 Tree topology communication network based on reputation model
树形拓扑通信网络的初次构建是随着许可链系统的部署进行的.由于所有节点的初始信誉值完全相同,一般可采用随机方式建立树形网络拓扑结构,但为了使系统更可靠,应当以参与者的实际情况作为参考.例如,社会影响力较大的组织或机构往往具备更可靠的信用背书.因此,以参与者的信用背书为主要依据进行通信网络的初次构建更为合理.随着时间的推移,系统的信誉模型将会完全取代参与者本身的信用背书.
3 TTNPBFT 共识算法设计
TTNPBFT 共识算法以PBFT 算法为基础,并结合信誉模型与树形拓扑网络的特征对一致性协议与视图更换协议进行了改进.本章对TTNPBFT 进行详细介绍.
3.1 信誉模型
信誉模型能够为错误节点检测提供良好的基础.一方面,通过动态调整节点的信誉值降低错误节点在树形拓扑网络中的层次,能够不断减小错误节点在共识过程中的影响力,从而使许可链系统保持较高的可用性与可靠性.另一方面,可将共识节点的信誉值作为奖励与惩罚的标准以促使节点遵循协议.
定义1信誉值是衡量节点可信程度的参考指标.信誉值R是介于0.1 和1.0 之间的实数.信誉值越高,则对应节点的可信度越高.新加入许可链系统的节点,其信誉值初始化为0.5.
定义2信誉奖惩指信誉值将根据节点在共识过程中的行为动态变化.令Rv表示某个节点在视图v中的信誉值,则该节点在视图v+1 中的信誉值Rv+1与Rv的关系如下:
1)如果主节点成功生成一个有效的区块,或者从节点的消息内容与最终结果相同,那么这些节点的信誉逐渐提高,其计算公式为
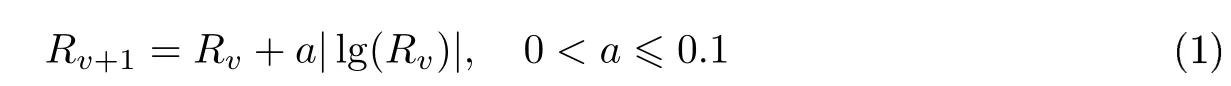
因为采用了对数公式,所以随着诚实节点信誉的不断提升,其信誉值的增长率会降低.采用这种方式可增加获得高信誉值的难度,恶意节点若想具备极高的信誉值,在树形网络中处于较高的层次,则需要付出极大的努力.参数a用于避免信誉值较低时增长幅度过大的问题.
2)如果主节点本轮未能领导产生新的区块,或者从节点消息内容与最终结果不一致,甚至没有发送任何消息,则相应节点的信誉值会线性下降,其计算公式为

信誉值的下降速度取决于参数b,b取值的大小应该根据具体应用场景的需求来设置.
3)如果同一节点向其他共识节点发送不一致的消息,那么该节点将被视为拜占庭节点,其信誉直接降为最小值,即

定义3信誉状态是限制节点权限的重要依据.信誉状态取决于节点信誉值R的大小.表1定义了节点的4 种信誉状态.

表1 节点的信誉状态Table 1 Reputation status of node
其中,参数α与β为节点状态变更的两个阈值,0.5< α <1.0 且0.1< β <0.5.信誉值大于α为最优状态,而小于β则为最差状态.α与β的取值与许可链系统对安全性的要求程度有关.图3展示了节点不同信誉状态之间的转换关系.

图3 节点信誉状态之间的转换关系Figure 3 Transition relationship between node reputation states
不同信誉状态的节点拥有不同的权限.为了保证系统的效率与安全,规定只有优秀节点可担任根节点,异常节点不能担任主节点,无效节点则不能参与共识.节点权限与其信誉状态的对应关系见表2.

表2 节点权限与信誉状态的对应关系Table 2 Relationship between node permissions and reputation status
定义4信誉恢复指节点的信誉值低于β时将逐渐恢复.从原则上讲,应当给予无效节点“改过”的机会,于是给出如下规定:每经过T时间周期,无效节点的信誉值将上升c,但不能超过β,其具体计算公式为
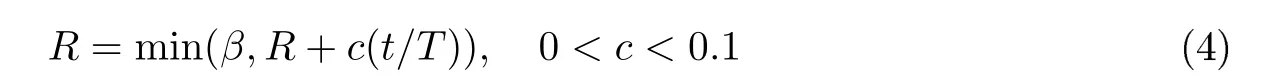
式中,t为该节点最后一次参与共识距现在的总时间.
定义5信誉更新指节点维护其本地节点列表的过程.信誉更新发生在每一次视图更换之前,用以保证具有最高信誉的节点当选为主节点.在一般情况下,各个节点只需通过其本地的消息日志,根据信誉奖惩标准对其所在子网内其他节点的信誉值与信誉状态进行更新,此过程由节点独自完成而不需要通信.但一定时间之后,可能会出现节点状态不一致的情况.因此,类似于PBFT 算法的检查点协议,子网范围的信誉更新将周期性执行,所有节点通过消息广播的方式将子网内的信誉值达成一致.信誉更新过程在各个子网内独立执行,因此不会对系统整体性能产生明显影响.
为了保证许可链系统的安全性,应及时清除系统中的恶意节点.根据式(4)可得信誉值从最小值0.1 恢复到β所需要的时间t′为

本文将“长期”定义为在10t′时间周期内达到3t′的时间,并将长期处于无效状态的节点认定为恶意节点.在信誉更新过程中,节点列表中的恶意节点将被删除.
3.2 一致性协议
TTNPBFT 共识算法使用密码技术来防止欺骗攻击与重播攻击,同时保证消息的完整性.消息包含了数字签名和无碰撞哈希函数生成的数字摘要.为了便于描述,首先在表3中定义相关符号.
TTNPBFT 通过树形拓扑网络将全网划分成若干子网,这些子网分布在不同的层次.在每个子网中,父节点作为主节点,领导其孩子节点在该子网范围内执行相应的PBFT 算法.根据树形拓扑网络的层级属性,TTNPBFT 对PBFT 一致性协议的预准备阶段和回复阶段进行了改进.在预准备阶段,全网主节点Sroot向其领导的子网内广播预准备消息,该子网内的从节点作为下一层子网的主节点将继续转发该预准备消息,直至最底层子网.与此类似,在回复阶段,最底层子网节点的回复消息将逐层向上传播,客户端最终只会收到来自最高层子网节点的回复消息.在TTNPBFT 中,只有最底层子网运行完整的PBFT 算法,而高层子网则运行简化的PBFT 算法(准备阶段与确认阶段合并).当n= 40, k= 4 时,树形拓扑网络中的所有子网处于3 个层次上.图4给出了TTNPBFT 算法的一轮完整的共识过程.

表3 相关符号Table 3 Related symbols

图4 TTNPBFT 的共识过程Figure 4 Consensus process of TTNPBFT
具体算法如Algorithm 1 所示:



该过程的详细描述如下:
步骤1客户端c向全网主节点Sroot发送消息
步骤2Sroot将来自于客户端的事务请求打包成区块b,然后在其子网范围内广播一条预准备消息<
步骤3最底层子网中的从节点接收到预准备消息后对其合法性进行验证,验证内容主要包括:预准备消息签名的正确性、视图v的正确性、摘要d与区块b的哈希值是否一致以及b中事务是否重放等.若预准备消息有效,则将其存入本地消息日志并向子网内其他节点广播准备消息,从而就区块序列号sn 达成一致.准备消息格式为
步骤4最底层子网中的节点(包括主节点)收集到2fk+ 1 条匹配的准备消息后,它们将广播一条确认消息
步骤5子网的主节点统计回复信息,若存在fk+1 个匹配的预执行结果集rs,便将rs作为该子网的共识结果.在将该结果集继续向上层子网传递之前,需在其所属的子网内确认得到了相同的事务区块且当前视图未发生变化,操作同步骤4.若发现其主节点作恶或视图已改变,则向下广播一条共识失败消息
需要注意的是:最底层子网完成确认阶段后,节点并不应该直接将事务的执行结果写入本地账本,因为共识还没有完全达成.在结果向上传送的过程中,共识依然可能会失败;而新的预准备消息的到来意味着上一轮共识已经结束,节点应当此时提交上一轮的事务到本地.
3.3 视图更换协议
视图更换协议用于为子网选择新的主节点,以保证系统在发生故障时能够保持活性.PBFT 算法基于计时器超时机制在全网范围触发视图更换事件.TTNPBFT 共识算法通过引入信誉模型,能够有效检测到主节点的异常行为.如发送不一致的消息,这将同样触发视图更换协议.此外,TTNPBFT 将全网范围共识拆分成若干子网范围共识,这些子网作为独立单元并行执行PBFT算法.它们处于相互独立的视图中,因此TTNPBFT 的视图更换是局部的而非全网的.
若某个主节点发生故障,则将在其领导的子网内触发视图更换协议.TTNPBFT 采取择优替换原则,即在该子网范围内选择信誉值最高的节点担任新的主节点.图5展示了极端情况下TTNPBFT 的全网主节点Sroot发生拜占庭错误时的视图更换过程.视图更换协议不仅要求所有节点就新视图达成一致,还需要考虑如何在新视图中处理上一视图的遗留事务,这是一个较为复杂的过程.在此采用简化后的描述,更详细的介绍请参考文献[12].

图5 TTNPBFT 的视图更换过程Figure 5 View-change process of TTNPBFT
具体算法如Algorithm 2 所示:


该过程的详细描述如下:
步骤1若某个主节点出错或成为其他子网的主节点,则其所领导子网的所有从节点将进行信誉更新,并判断该主节点的信誉值在子网范围内是否为最大值.若满足条件,协议结束;否则,从节点将向其所属的子网内广播一条视图更换消息
步骤2子网内信誉值最高的从节点收集到2fk个匹配的视图更换消息后,它将向该子网内广播新视图消息
步骤3该子网内其他节点接收到新视图消息后,验证签名的正确性以及视图更换消息的有效性,然后将新视图消息添加到消息日志中并进入视图v+1.下一层子网内从节点接收到新视图消息后验证消息的有效性,若消息有效,则检查子网范围内是否存在某个从节点的信誉值大于被派遣主节点的信誉值.若不存在,则将新视图消息存入日志并进入视图v′+1.否则,将在此子网范围内再次触发视图更换协议.
步骤4重复步骤1∼3,直至故障节点到达指定的位置,即成为较低层次子网的主节点或成为最底层子网的从节点.
信誉模型规定:故障节点的信誉值会逐渐减小,而拜占庭节点的信誉值被直接置为最小值.因此,视图更换协议结束后故障节点在树形拓扑网络中所处的层次会降低,而拜占庭节点将直接成为最底层子网的从节点,作恶代价非常大.
3.4 激励与惩罚机制
如果一个恶意节点总是付出高成本而获得低回报,那么该节点将失去攻击系统的动机,比特币就完美地诠释了这个道理.在基于PBFT 算法的许可链系统中,共识节点尤其是主节点通常是攻击者的主要目标,相对于普通的记账节点,共识节点时刻面临着严峻的安全威胁.此外,共识节点的带宽资源、计算资源与存储资源的开销也是非常显著的.因此,许可链系统同样需要建立适当的激励与惩罚机制以提高正确节点参与共识的积极性.
本文考虑了一种基于信誉的激励与惩罚机制.联盟成员共同设立奖励基金,使长期具有高信誉的成员将获得更多的实质性奖励.在惩罚方面,信誉越低的成员应缴纳更多的基金份额.同时,信誉状态长期为无效的节点将被视为恶意节点,面临被系统清除的风险.这些奖惩规则的引入都将有效减少节点的作恶动机,促使节点严格遵守协议,从而显著提高许可链系统的安全性和效率.
4 TTNPBFT 共识算法分析
4.1 通信复杂度分析
假设许可链系统中共有n个节点,而每个子网中共有k个节点.当树形拓扑网络结构为满k −1 叉树时,子网的总层次数l等于树的高度减1
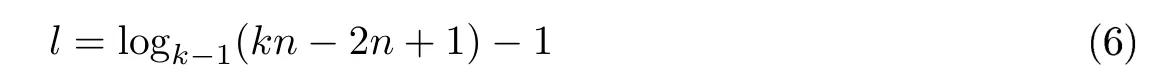
最高层子网数目为1,并且各层子网数目构成公比为k −1 的等比数列.因此,在子网层数为l的许可链系统中,子网总数s为
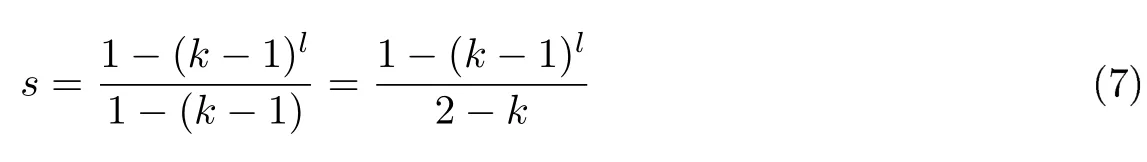
而最底层子网总数s′为

TTNPBFT 在最底层子网中执行完整的PBFT 算法.由1.1 节可知,在节点总数为k的网络中执行PBFT 算法发送的消息总数为2k2.由3.2 节可知,TTNPBFT 在高层次子网中运行简化的PBFT 算法,发送的消息总数为2k2−(k −1)2=k2+2k −1.因此,在异步网络中达成一次共识,TTNPBFT 发送的消息总数Msum为

因此,TTNPBFT 算法的通信复杂度近似为O(nk).当k=n时,即退变为全网共识,其复杂度为O(n2).当子网层数l= 5、子网节点数k= 4 时,全网节点总数n= 364.达成一轮共识,TTNPBFT 所需发送的消息总数为3 512,而PBFT 所需发送的消息总数为264 992,约为TTNPBFT 的75 倍.因此,相对PBFT 而言,TTNPBFT 极大地减小了通信开销.此外,由于相同层次子网的共识过程可并行执行,共识效率将进一步提高.
4.2 容错性分析
TTNPBFT 共识算法以树形拓扑通信网络为基础,这使得网络中的节点形成了明显的层级关系,并且节点所处的层次越高,它们在共识过程中的影响力越大.因此,错误节点在树形拓扑网络中的分布情况对许可链系统的容错能力有着直接的影响.当错误节点均匀分布在每个子网范围并且子网内错误节点数量不超过(k −1)/3 时,TTNPBFT 算法的容错能力与传统PBFT 算法相同,能够容忍错误节点的数量为f, f=(n −1)/3.事实上,信誉模型能够帮助形成良好的节点分布,即高可靠节点处于较高层次发挥领导作用,故障节点处于较低层次产生较小影响,而拜占庭节点则在一定时间周期内不能参与共识.理论上,信誉模型的引入使得TTNPBFT 能够在一定程度上容忍超过1/3 数量的拜占庭节点.
4.3 正确性分析
作为新型的分布式数据库,一个完全正确的区块链系统必须能够满足分布式系统的两个重要特性:安全性和活性.在许可链场景中,关于安全性与活性的定义如下:1)安全性指每个达成共识的块中的事务都是有效的,并且诚实节点在任何给定高度上的区块都是相同的.2)活性指许可链系统在有限时间内对客户端提交的事务做出正确的响应.
本文在对抗模型中假设攻击者不能破解许可链系统使用的密码算法,因此节点只要对事务的数字签名、数字摘要及内容格式的正确性进行验证,就很容易保证事务的有效性.接下来将证明所有诚实节点的本地存储中区块的一致性,即在一轮共识中,若有效区块b1、b2分别被两个诚实节点提交到本地,那么b1=b2.
证明在某个子网中,若b1是有效的,则至少2fk+1 个节点对b1中的事务表示认可并将b1提交到其本地.同理,同样需要2fk+1 个节点对b2中的事务表示认可并将b2提交到其本地.因此,至少需要2(2fk+1)−(3fk+1)=fk+1 个节点同时认同b1与b2.其中,最多有fk个错误节点,而至少有一个诚实节点.诚实节点将严格遵守协议,不会在一轮共识中提交两个不同的区块,因此必定满足b1=b2.
与PBFT 相同,TTNPBFT 可在网络部分同步假设下通过更换视图为系统提供活性.在预准备阶段,从节点在接收到一个有效的区块后将启动计时器.若系统处于良好状态,则区块中的事务请求按照一致性协议正常被处理,并且客户端将接收到来自系统的响应.若计时器超时或主节点作恶,则从节点将向其所属子网内广播Mview-change消息,新视图的主节点在收集到2fk个Mview-change消息后,通过广播一条Mnew-view消息成为新的主节点并继续领导其他节点执行共识.
综上所述,TTNPBFT 要么在某个确定的视图下正确地产生新区快,要么视图发生变化.因此,TTNPBFT 能够满足许可链系统对安全性与活性的要求.
5 TTNPBFT 共识算法性能评估
本文选择Hyperledger Fabric[32]作为实验的基本平台,Fabric 是一个模块化、可扩展的开源系统,可用于部署和运行许可链应用.本文改进了Fabric v0.6,实现了TTNPBFT 算法,并与Fabric 中的PBFT 算法进行了比较.所有实验均在广域网环境下的10 台配备英特尔i5-8500 处理器和8 GB DDR4 内存的台式电脑上进行.在每台主机上运行30 个Docker[33]容器以模拟最大300 个节点的许可链系统,虽然可能会造成一定影响,但不会改变实验结果的正确性.接下来从延迟、事务吞吐量两方面将TTNPBFT 与传统PBFT 算法进行比较.
5.1 延迟
区块链系统的延迟可以定义为从客户端提交事务请求到客户端收到响应结果的时间差.分别测试了全网节点数量n为20、40、60、80、100、120、140、160、180、200、220、240、260、280、300 且子网节点数量k为4、7、10 时PBFT 与TTNPBFT 算法的延迟,结果如图6所示.
总体而言,PBFT 算法的延迟随着n的增加而急剧增长,这是由其O(n2)的消息复杂度造成的,因为验证大量的消息签名将花费很长时间.虽然TTNPBFT 算法的延迟随着n的增加同样有所增长,但基本保持稳定,因此能够为大规模的许可链系统带来良好的用户体验.对于不同的子网规模,k值越小,树形拓扑网络的层次数越大,消息通信阶段则越多,延迟相对较大.随着n的增长,网络中消息数量急剧增加,成为产生延迟的主要因素;k越小,网络中消息数量增长得越慢,因此越小的k对应的延迟增长率越小.
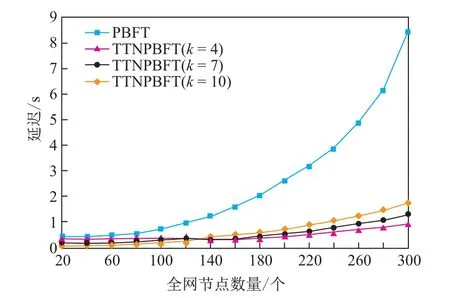
图6 PBFT 和TTNPBFT 的延迟与节点数量的关系Figure 6 Delay of PBFT and TTNPBFT in relation to number of nodes
5.2 事务吞吐量
区块链系统的吞吐量可以定义为每秒处理的事务数量.分别测试了全网节点数量n为20、40、60、80、100、120、140、160、180、200、220、240、260、280、300 且子网节点数量k为4、7、10 时PBFT 与TTNPBFT 算法的事务吞吐量,结果如图7所示.

图7 PBFT 和TTNPBFT 的事务吞吐量与节点数量的关系Figure 7 Transaction throughput of PBFT and TTNPBFT in relation to number of nodes
由结果可知,PBFT 算法的性能受节点数量的影响较大.当节点数量超过一定的阈值(大约为120)时,吞吐量会明显降低,可扩展性问题非常明显.TTNPBFT 算法的性能随着节点数量的增加基本保持稳定,这是因为TTNPBFT 将全网范围共识拆分为若干子网范围共识,大幅度减小了通信与计算开销.因此,即便在节点数目较多的情况下,TTNPBFT 依然能够保持较高的吞吐量,表现出了极高的可扩展性.此外,随着k的减小,TTNPBFT 的整体性能有所提升,但k的取值太小会导致子网的容错性下降.在实践中,选择k的最优值是需要进一步讨论的问题.
此外,还测试了全网节点数量n=80,子网节点数量k=4 时PBFT 与TTNPBFT 的事务吞吐量随时间的变化情况,结果如图8所示.
初始时刻,TTNPBFT 性能表现不如PBFT,因为高层次主节点若发生故障,将连续在多个子网内触发多次视图更换协议.就整体而言,随着系统运行时间的增长,PBFT 的吞吐量基本保持不变.TTNPBFT 的吞吐量前期增长比较明显,随着时间的推移,增长速度逐渐放缓,吞吐量逐渐趋于稳定,这归功于TTNPBFT 良好的信誉模型.随着时间的推移,故障节点的影响逐渐减小,拜占庭节点参与共识的概率逐渐减小,视图更换频率明显降低,许可链系统渐渐达到最优状态.事实证明,信誉模型能够有效地提高许可链系统的可靠性与稳定性.
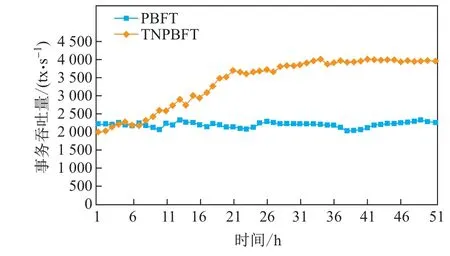
图8 PBFT 和TTNPBFT 的事务吞吐量随时间的变化情况Figure 8 Transaction throughput of PBFT and TTNPBFT over time
6 结 语
本文提出了一种基于树形拓扑网络的实用拜占庭容错共识算法TTNPBFT.该算法对全网共识任务进行拆分,减小了任务的整体规模,将通信复杂度降低到O(nk),大幅减少了带宽与计算资源的开销,即使在节点数量较大的情况下也能保持良好的输出性能.
然而,TTNPBFT 仍存在一些不足.许可链系统一旦部署,子网节点数量k将固定.事实上,k的不同取值对系统的性能与安全性都有较为明显的影响.此外,对于给定的全网节点数量n,并非任意的k值都能构成近似满k −1 叉树的网络拓扑结构,而在树形拓扑网络不同层次上实现k的动态调整就能妥善解决这个问题.因此,未来的主要工作是实现具有自适应能力的TTNPBFT 共识算法,旨在寻求效率与安全之间的均衡.
