基于Mo-RVIKOR的混合多属性决策方法
2020-01-16潘亚虹耿秀丽
潘亚虹,耿秀丽
(上海理工大学管理学院,上海 200093)
1 引言
多属性决策问题在工程、管理、军事、经济等诸多领域有着广泛的应用,如双边匹配[1]、项目选址[2]、导弹研发[3]、合作伙伴选择[4]等。在实际生活中,由于现实决策问题的复杂性和不确定性,属性值往往存在多种类型。如服务方案的评价问题,常考虑服务质量、服务流程顺畅度、客户到店量、客户满意度等属性,其中客户对服务的满意度是定量属性,常以打分的精确数型信息表示;客户到店量是不确定性的定量属性,常通过随机变量型信息表示;服务流程顺畅度是定性属性,常用语义型信息表示。这种既包括定量、定性属性,又包含不确定性的多属性决策问题,符合客观实际需求,有重要的研究意义和应用价值。针对定性属性的评价,犹豫模糊语义术语集[5](Hesitant fuzzy Linguistic Term Set,HFLTS)能很好地表现专家在复杂决策环境中进行评价的不确定性和犹豫度,近年来采用HFLTS进行评价的研究较多[6]。采用HFLTS进行评价时,犹豫模糊集中的语义集被赋予相同的权重,而在现实评价过程中,专家对语义集的偏好程度不同,赋予语义集相同的权重会造成专家偏好信息的损失。概率语言术语集[7](Probabilistic Linguistic Term Set,PLTS)对定性属性评价时,通过对语义集赋予相对应的概率以表达不同程度的偏好,能精确地表达专家的偏好信息。因此本文采用精确数型、随机变量处理定量评价信息型,用概率语义型术语处理定性评价信息。
在混合多属性决策问题的信息集结过程中,通常会将混合信息转化为同一种形式的信息进行比较。文献[8]将确定性与不确定性视为一个整体,通过不同类型属性值在D-U空间中的映射转换法则,使得不同类型的属性值在空间中统一量化;文献[9]在质量功能配置研究中运用模糊集对混合评价信息进行处理,通过二元语义模型将信息转化为精确数值来集结信息。但转化为同一种信息形式的过程使得计算繁琐或易导致信息缺失。Lourenzutti和Krohling[10]提出模块化处理思想,根据属性特征将评价信息分成独立模块进行信息处理,避免信息在集结过程中的信息损失。群模块随机逼近理想解法[11](Group Modular Random Technique order preference by similarity to ideal solution,GMo-RTOPSIS)是根据模块化思想提出的改进方案排序方法,考虑了属性评价信息为随机变量型的情况,根据属性特征将评价信息分成独立模块,分别计算各属性下的正负理想解,避免在集结过程中的信息损失。但其属性权重由专家直接评估得出,存在主观随意性。多准则妥协解排序法(VlseKriterijumska Opti-mizacija I Kompromisno Resenje,VIKOR)能同时考虑群体效用最大化和个体遗憾最小化,相比TOPSIS方法更有助于保证决策结果的合理性。本文提出模块化随机多准则妥协解排序法(Modular Random VlseKriterijumska Opti-mizacija I Kompromisno Resenje,Mo-RVIKOR)进行方案评价,分别计算每个属性的正负理想解,基于最大化群体效益和最小化个别遗憾,根据专家评价信息矩阵,对方案进行评估并排序。针对属性权重确定的问题,现有属性权重确定的方法有很多,但通常忽略了在实际决策问题中,属性权重在不同方案中的重要程度不同,因此本文采用改进离差最大化法确定方案属性权重,充分体现属性在不同方案中的重要程度,使决策过程更符合客观实际。
本文提出了基于Mo-RVIKOR的混合多属性决策方法,专家可以采用数值型、随机变量型和概率语义型混合的评价信息进行评价。根据改进离差最大化法确定各方案属性权重,基于Mo-RVIKOR方法对方案进行评估并排序,避免了混合评价信息在集结过程中的信息损失。最后以某公司C2B定制化服务质量评测项目为例对该方法进行验证。
2 研究框架
本文提出基于Mo-RVIKOR的混合多属性决策方法,专家根据属性性质确定该属性的评价信息类型;采用精确数型、随机变量型和概率语义型三种类型的评价信息对属性进行评价;通过改进离差最大化法确定各方案的属性权重;基于Mo-RVIKOR方法将评价信息矩阵根据属性分成独立模块,分别计算各属性的正负理想解,根据各方案属性权重得出最大化群体效益和最小化个别遗憾,对方案进行评估和排序。所提方法的研究框架如图1所示。

图1 本文所提方法研究框架
3 预备知识
3.1 概率语义术语集概念
在实际决策问题中,对于流畅度、理解程度等定性属性,很难用精确数型的信息进行评价。Pang Qi等[7]于2016年提出概率语义术语集,它用语义集及语义集相对应的概率组成语义集合L(p),表达专家的语义评价信息。相对于犹豫模糊语义集中每一个语义集(Linguistic Term Set ,LTS)被赋予相同的权重,概率语义集通过语义集相对应的概率,可以表现语义集的不同程度,避免专家偏好信息的损失[12]。
定义 1[12]:设S={s0,…,sα}为LTS,一个PLTS可以被定义为:

(1)
其中,L(k)(p(k))表示语义术语集L(k)的概率为p(k),#L(p)是所有L(p)中包含的语义集的个数。
如设LTS为五个粒度的语义术语集,S5=(S0=VL,S1=L,S2=M,S3=H,S4=VH)。当评价指标为对服务人员的印象时,客户给出“服务人员形象都不错,但有时不了解我的需求”,则此时记“服务人员形象都很好”为S4,其概率为0.6,记“有时不了解我的需求”为S1,其概率为0.3,此时的L(p)={(S1,0.3), (S4,0.6)}。


(2)



(3)

定义 4[12]:设L(p)={L(k)(p(k))|k=1, 2, …, #L(p)}为一个PLTS,r(k)为语义集L(k)的下标,则L(p)的得分函数如下:
(4)


σ(L(p))=
(5)
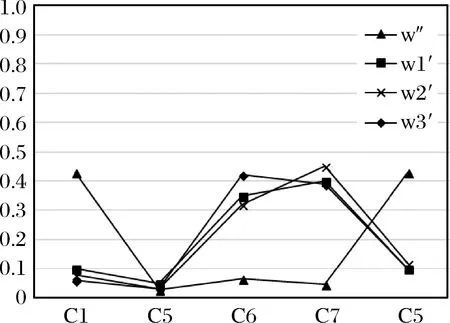
设概率语义集L(p)1和L(p)2的得分函数为E(L(p)1)和E(L(p)2),偏差度分别为σ(L(p)1)和σ(L(p)2)。当E(L(p)1)=E(L(p)2)时,如果σ(L(p)1)<σ(L(p)2),则L(p)1>L(p)2;如果σ(L(p)1)=σ(L(p)2),则L(p)1=L(p)2;如果σ(L(p)1)>σ(L(p)2),则L(p)1 若属性Cj为成本型属性: (6) 若属性Cj为效益型属性: (7) 当属性Cj为不确定性定量属性时,评价信息采用随机变量型,通过构建针对属性的占优矩阵对不确定性的定量属性进行评价[13]。构建针对属性Cj的占优矩阵Gj=[giqj]n×n,其中giqj表示针对属性Cj,其中表示针对属性Cj,方案Ai优于方案Aq的概率。 若属性Cj为成本型属性,则giqj的计算公式为: dgqjdgij(1≤i≤n,1≤q≤n) (8) 若属性Cj为效益型属性,则giqj的计算公式为: giqj=P{gij≥gqj} (9) 其中: 1≤i≤n, 1≤q≤n,fi(gij)和fq(gqj)分别为gij与gqj的概率密度函数。 根据占优矩阵Gj=[giqj]n×n度量各方案针对属性Cj的优劣程度,得到属性Cj的优势度φj,φj为精确数值,φj计算公式如下: (10) (11) 本文提出Mo-RVIKOR方法,首先根据属性性质确定该属性的评价信息类型,将评价信息矩阵根据属性分成独立模块,然后根据不同类型评价信息的优劣比较方法分别计算各个模块的正负理想解,根据不同类型评价信息的距离公式,计算各个模块的最大化群体效益和最小化个别遗憾,最后通过专家评价信息矩阵,对方案进行评估并排序。 Mo-RVIKOR方法的信息模块化处理,不仅有效避免了因评价信息类型不同,需要转化为同一种信息类型时造成的信息损失,而且能够合理处理因混合评价信息无法转化为同一种类型,无法进行方案优劣比较的问题。 X=(xij)n×m=(M1,M2,…,Mj) 步骤一:构建属性值离差。在混合多属性群决策中,若第j个属性在不同方案中的属性值无差别,则该属性对不同方案的效能影响较小,应赋较小权重;反之,在不同方案中该属性值差别较大,则该属性对不同方案的效能影响较大,应赋较大权重。 对于属性Cj,用ΔVi(j)表示方案Ai下属性值xij与其他方案下属性值xil之间的离差: ΔVi(j)=|xij-xlj|, (l=1,2,…,n) (12) 其中:概率语义型评价信息的离差通过公式(3)计算得出。 方案Ai下属性值xij与其他方案下属性值的总离差为: (13) 步骤二:基于离差最大化法,结合层次分析法对方案下属性间总离差进行两两比较,将结果映射到1~9标度中,得到相同方案下不同属性间总离差的判定矩阵B=(bij)m×m。 步骤三:求解方案Ai所对应判定矩阵的最大特征根及其对应的特征向量wj,对其归一化: 白酒贮存过程中酯含量的减少途径见图5,主要是两方面的原因:(1)贮存过程中白酒的自然挥发即物理损失;(2)白酒在贮存过程中的水解反应、酯-酸交换反应、酯氧化反应即化学损失。 (14) 步骤四:对其他方案分别执行上述操作,得到不同方案下不同属性的权重矩阵W=(wij)n×m。 计算步骤如下: 步骤一:根据专家评价信息矩阵,确定各专家对于方案的正理想解P*和负理想解P-。 (15) 步骤二:计算群体效益Si和最大个别遗憾Ri。 (16) 步骤三:计算Mo-RVIKOR方法综合指标Qi为: (17) v为最大群体效用决策策略的系数,它体现决策者的主观偏好。v>0.5时,表示决策者根据大多数人的意见,即以最大化群体效益占比重较大的方式制定策略;v<0.5时,表示根据反对的情况,即以最小化个别遗憾占比重较大的方式制定策略。v=0.5时,表示同时考虑群体效益和个体遗憾,根据均衡的情况制定策略。 步骤四:按Qi、Si、Ri的值由小到大的顺序进行排序,得到三个排序序列,数值最小表示方案最优。 步骤五:确定妥协解。 (1)如满足下面两个条件,A(1)为最优妥协解。A(1)表示按照Qi排序,排在第一的方案。 条件1:可接受优势:Q(A(2)-A(1))≥DQ,DQ=1/(n-1)。 条件2:决策过程中可以接受的稳定性:如依据Si和Ri排序,A(1)仍排序在第一位。 (2)如果上述两个条件有一个不满足,则得一组妥协解: ①若只有条件2不满足,A(1)和A(2)都为妥协解; ②若条件1不满足,由关系Q(A(x))-Q(A(1))<1/(n-1)得到最大X,A(1),A(2),…,A(x)都接近理想方案。 某公司为推广新产品,前期对产品进行了C2B定制化服务设计,通过提高顾客体验增加新产品销量。现需对其在上海的三个经销商Ai(i=1,2,3)进行服务质量评测,经讨论确定本次服务质量测评的评价属性为:客户体验等待时间(C1),单位:分钟,该项属性是指客户在体验服务时,因前一个客户正在体验而需要等待的时间,通过多次调研数据统计得出,为成本型属性;客户对服务体验的评分(C2),该项属性是指客户体验整个服务后对服务的评分,采用0-10的打分形式给出评价信息,为效益型属性;经销商对C2B设计的落实度(C3),该项属性是指经销商在接到全面实施C2B服务设计的通知后,门店的落实情况,包括服务人员的培训情况,设备到场情况等,为效益型属性;触点设计满意度(C4),该项属性是指C2B服务设计中几大触点的设计,在实际运营中是否满足客户和服务人员的需求,带来更好的服务体验,如交互大屏的灵敏性,iPad选拼系统的流畅性等,为效益型属性;体验服务后产品成交率(C5),该项属性是指在体验服务后购买产品的客户,占体验服务总客户的比率,为效益型属性。案例分析中定义5粒度的语义术语集合为LTS,根据专家为期两个月的实地调研、客户访谈和数据采集,得到各属性的评价信息如表1所示。 表1 经销商针对各属性的评价信息 通过对评价信息的标准化处理,得到集结各模块后的评价信息矩阵,如表2所示。 表2 集结各模块后的评价信息 通过公式(16)确定经销商的正负理想解,其中概率语义型信息的正负理想解,利用公式(4)~(5),计算得到正理想解P*(1,1,{S3(1),S3(0)},{S3(1),S3(0)},1)和负理想解P-(0,0, {S2(0.80),S4(0.20)},{S2(0.40),S3(0.60)},0)。 表3 Mo-RVIKOR排序结果 为了说明所提方法的有效性,通过文献[9]的方法处理评价信息,采用多粒度语义术语集评价定性属性,采用[0,1]范围内的精确数评价定量属性,定义15粒度的语义术语集合为BLTS。属性C1、C5的评价信息为规范化优势度,满足在[0,1]的范围内,视为精确数型评价信息;属性C2采用0-10的打分形式获得评价信息后,通过10:1的比例转化到[0,1]范围;属性C3采用九个粒度的语义术语集,S={S0=VL,S1=L,S2=SM,S3=MM,S4=M,S5=SH,S6=MH,S7=H,S8=VH};属性C4采用七个粒度的语义术语集,S={S0=VL*,S1=L*,S2=SM*,S3=M*,S4=SH*,S5=H*,S6=VH*}。得到各属性的评价信息如表4所示。 表4 各属性的评价信息 根据异质信息统一处理公式,将评价信息统一转化为精确数,得到各属性精确数型的评价信息如表5所示。 表5 各属性精确数型的评价信息 根据表5中各属性精确数型的评价信息,采用离差最大化法确定属性权重,得到属性权重为w″=(0.43,0.03,0.07,0.05,0.43),通过VIKOR方法得到正理想解P*为(14,12.57,10.53,6.93,14),负理想解P-为(0,11.14,7.31,4.57,0)。计算群体利益Si、个体遗憾值Ri和综合评价值Qi,分别按Si、Ri和Qi的值由小到大的顺序进行排序,当v=0.5时排序如表6所示。 表6 VIKOR排序结果 从表6可以看出,当v=0.5时,Q(A2-A3)=0.07<0.5,不满足条件1,方案妥协解为{A3,A2},且当0≤v≤1时,Si、Ri和Qi的值由小到大的排序仍如表6所示,方案妥协解始终为{A3,A2}。 图2 属性权重对比图 对比分析属性权重的获取,一方面传统离差最大化法只能得出一组相同权重,本文的改进离差最大化法可以得出每一个经销商的属性权重,符合决策问题中,属性权重在不同方案中重要程度不同的现象,使权重获得更符合实际。另一方面对比方法将混合信息转化为同一种信息形式进行评价,在异质信息统一处理后,如表5所示,由于属性C1、C5的评价信息数值差异较大,导致分配的权重过大,而属性C3、C4的评价信息差异较小,导致分配的权重过小。权重的分配差异导致计算过程中,削弱了属性C3、C4对方案效能的影响,减小了方案优劣差距,从而影响了方案评价的准确性。 对比分析结果可以看出:本文方法服务质量最优的经销商为A3,而对比方法产生了妥协解{A3,A2},虽然方案排序均为A3>A2>A1,但由于权重分配不合理,方案优劣性差距缩小,无法得到精确的最优方案。 通过敏感性分析,对比属性权重的变化对决策结果的影响,将属性Cj的权重w与参数η相乘,根据权重的归一性,属性Cj的权重发生改变时,其余属性权重与参数θ相乘,θ=(1-η*w)/(1-w),参数η依次取2,1.5,0.5,对各属性进行相应调整后,得到本文方法的排序结果如表7所示。 表7 Mo-RVIKOR敏感性分析排序结果 参数η依次取2,1.5,0.5,对各属性进行相应调整后,得到对比方法的排序结果如表8所示。 表8 VIKOR敏感性分析排序结果 从敏感性分析结果可以看出,随着参数η的取值变化,本文排序结果最优经销商均为A3,而对比方法的排序结果方案A2优于A3的达到33.3%,对比方法对权重变化相对敏感,使排序结果不稳定。 由此可见,本文的Mo-RVIKOR方法不需要将评价信息转化为同一种信息类型,减少了在转化过程中的信息损失,保证了决策信息的精确性和属性权重获取的合理性,从而能获得更稳定、准确的决策结果。 为解决具有混合评价信息的多属性群决策问题,本文提出基于Mo-RVIKOR的群决策方法,所提方法的特点如下: (1)针对属性特征为定性形式,运用概率语言术语集进行评价,能很好表现专家评价的不确定性和犹豫度,且有效避免了专家偏好在表达时的信息损失; (2)针对属性特征为不确定性的定量形式,采用随机变量型评价信息进行评价,通过优势度矩阵进行信息处理,操作简单; (3)针对混合型评价信息在评价阶段进行信息集结会造成信息损失,提出Mo-RVIKOR进行方案的评价和排序,避免信息转化,简化计算。 通过对某公司C2B定制化服务质量评测项目的研究分析,验证了所提方法的有效性与可行性。由于服务设计是一个测试与迭代反复验证的过程,下一步研究考虑多阶段下的群决策问题。3.2 数值型评价信息的处理

3.3 随机变量型评价信息的处理
4 基于Mo-RVIKOR的方案评价
4.1 计算综合评价值

4.2 运用改进离差最大化法确定属性权重

4.3 基于Mo-RVIKOR的方案排序


5 案例分析
5.1 基于Mo-RVIKOR的定制化服务质量评测











5.2 对比分析






6 结语
