藏文数词自动检错研究
2020-01-16冷本杰高定国
文/冷本杰 高定国
1 引言
文本校对是自然语言处理领域重要的研究课题,在计算机自动生成语料、机器翻译、文本检索、版面分析、手写体识别等研究领域和后期的文本编辑中有着广阔的应用前景。藏文数词检错是藏文词校对的一部分,也是错误出现频率较高,且相对于藏文音节检错而言,检错需要观察前后出现的字节,根据音位环境的变形情况而检错的局部校对,所以藏文数词检错实现难度较大。
藏文文本校对研究开始于20世纪90年代,目前文本校对方面的研究内容有通过采用字典匹配法和根据藏文字母的构建规则,应用规则完成音节字拼写检错;根据传统文法中的藏文虚词添接规则,生成一定规模的规则库来检查藏文虚词(自由虚词)的接续关系;再用以上藏文音节字和接续关系的检查外,进行分词,完成梵文转写藏文拼写检查、词语错误检查以及综合校对的框架设计及实现等研究。藏文词校对方面的研究成果大多属于理论性研究,具体实现中所使用方法的是词典匹配法,这就需要庞大的词典作为校对系统的基础。词典中通常收录的数词有基础的(一)到(十)、(百)、(千)、(万)、(十万)、(百万)、(千万)、(亿)等数词、特殊的变形词以及有特殊含义或和其它词性搭配的数词。藏文数词的组词功能强大,变化多,导致词典无法收录文本中可能产生的所有数词。
2 藏文数词检错的理论依据
2.1 藏文数词的词法规范研究
2.1.1 文本表示藏文数词
数词顾名思义,就是表示数目的词语,属于语法概念。不同语言中对数字有特殊简易的表示符号。比如常用的世界通用阿拉伯数字,罗马数字等。藏文中也有特定的数字符号,如表1所示。如果在常用文本中都使用这些数字符号,数词的词法规范问题就很简单,但是正规文档和大多数传统文本书籍中绝大多数都是以文本表示数词。比如:
2.1.2 藏文数位表示
藏文数词通常主要分为计数词和序列词。序列词是表示次序的词,在具体语言中通常会前面出现(第)、(数)等词,或后面会出现、等词缀[9]。传统的藏族天文历算中计数词可以列到六十位(),其中基础的藏文计数词有(一)、(二)、(三)、(四)、(五)、(六)、(七)、(八)、(九)、(十)、(百)、(千)、(万)、(十万)、(百万)、(千万)、(亿)等,其余的很少使用,所以不在赘述。

表1:数字符号

表2:数词变形规则表
2.1.3 藏文数词和数位词发生形变
藏文基本的计数词合成形成其余数词时,不能像汉语那样直接搭配,而会根据具体的音位环境变形。比如:(十五)、(二十)、(二 十 一)、(三 十 三)、(七十六)。藏文数词变形规则如表2所示。
藏文数词的变形有如下规律:
(1)藏文数词中表达个位数时,不论计数还是序数都会使用数词原形。比如:(一束花)、(吉祥八宝)、(第二名);
(3)个位和十位数合成出现时,个位数的数词会出现变形现象,会用(二)、(三)、(四)、(五)、(六)、(七)、(八)、(九)来代替数词原形。比如:(二十一)、(三十三)、(四十五)、(五十六)、(六十七)、(八十九)、(九十一);
(5)藏文日期中通常表达二十至二十九号时,中间不会加变形体(二);而表示人的年龄、金钱余额等物质数量时中间的(二)用来代替。比如:(今天是二十三号)(二十五岁男儿)。
2.2 藏文数词的特性分析
藏文数词出现在文本除了单纯的数字表示之外大多数是在修饰名词。修饰名词时通常名词出现在数词前面,所修饰的名词有所有复数可数名词和方位词或处所名词,修饰方式有直接修饰和间接修饰名词。直接修饰可数名词例如:(五个人)、(六公里)、(17m2)、(一 千 斤)、(两百亩)、(三天)、(两个任务);直接修饰方位词或处所名词例如:两方)、(四方)、(两面)、(两岸);间接修饰名词时通常名词和数词中间出现一些量词(种)、(次)、(部)和其他特殊词(数)、(倍)、(各种)、(总共)、(一共)。
另外也有数词和动词组合在一起,形成一种语义独立的词汇来修饰名词,这时数词通常不会实指具体的数目,而是泛指多或少,统一或部分、连续或扩散等和数量有关的含义。比 如:(统 一)、(集 中) 、(专心致志)、(集中力量)、(连续不断)、(九煞毕集)。数词和动词组合一起时也可以中间添加虚词来连接一起。比如:(连接)、(集中)。
2.3 藏文数词的常见词法错误分析
通过遍历大小为176MB的藏文新闻语料,抽取数词的前后共五个字节,分析词法错误情况,发现藏文数词的词法应用错误主要是原形与变体混用导致错误。数词中(一)、(二)、(三)和变形词(一)、(二)、(三)的具体用法混淆,例如:(两千年)写成(两千年)。数词和变形词在数词合成中需要查看前一个音节,而具体的应用中常出现用法混淆现象。例如:(六十),(四十)。
3 藏文数词自动检错算法设计
3.1 藏文数词自动检错算法设计
藏文中基础的数词很少,但出现频率较高,这些基础数词会通过内部合成或和其它词性搭配形成更多的词。文本中出现的藏文数词搭配错误种类少、有规则可循,所以按照一定规则可以完成常见错误的检错。
按照藏文数词的规范、特征、设计的藏文数词检错算法如下:
(1)读取待检错的藏文文本内容,以藏文音节点作为分隔符,将文本切分成音节字序列,然后每个字符存储在字符串数组String[] str中,字符串str数组如T=Z1+Z2+……Zn-1+Zn来表示,其中Zn是一个藏文音节字。
(3)如果Zn与藏文基础数词匹配成功,则执行(4),否则继续匹配。
(4)判断基础数词前后出现以下字符串数组时按变形规律检错。
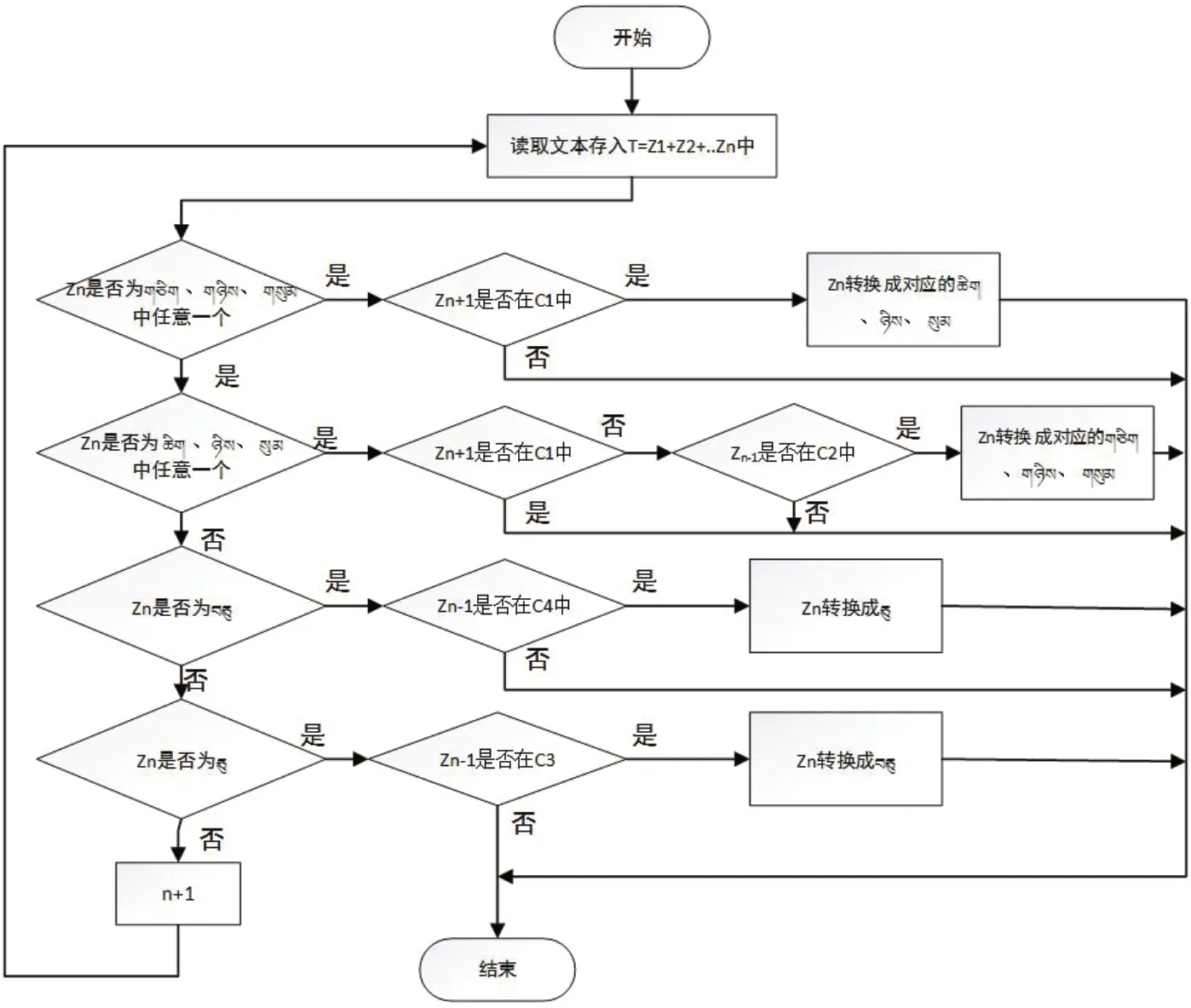
图1:藏文数词检错流程
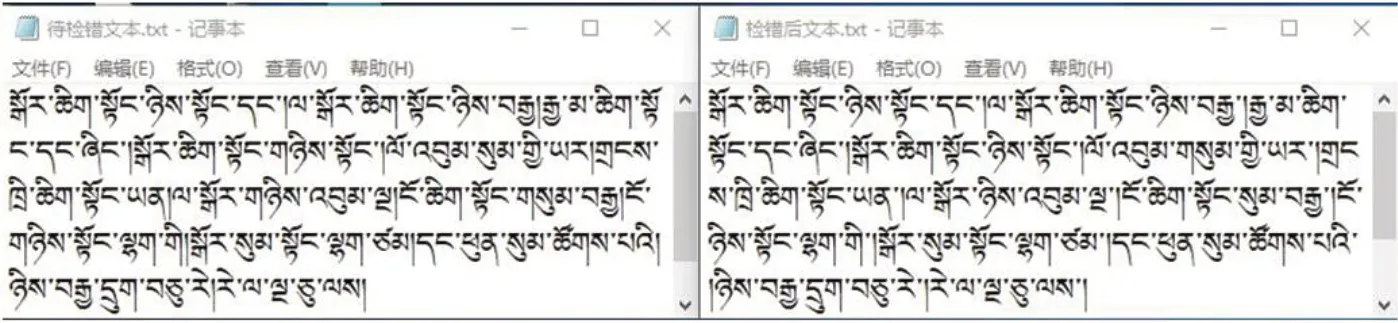
图2:藏文数词检错测试结果
按以上设计的算法和流程图实现藏文检错过程如下:
3.2 藏文数词自动检错算法测试
本次测试,为了体现检错算法的实际效果,测试文本主要选用词法错误统计处理后的语料,内容是基础数词以及前后共五个音节字符,每五个字节有单垂符隔开。将测试文本进行自动检错,检错完成的结果保存到一个新文本中,结果如图2所示。
虽然以上算法可以完成简单的常见藏文数词词法上的错误检错,但也有以下两点缺陷:
(1)藏文基础数词的音节拼写错误以及和音节错误合成的词法错误无法检错,如(一)、(三千)等。
(2)藏文数词中有兼类词,这些兼类词有时恰好和数词连续出现,虽然数量极少,但也有出现如(两层宝座)、(空屋三顶)的可能,这时检错算法会检错失误,出现错误纠正的现象。
4 结束语
藏文文本中数词有严格的词法合成规范,却词法错误出现频繁。本文详细分析了藏文数词的变形情况、语法特征、搭配规律等知识,通过统计分析常见的词法错误,提出了基于规则的数词合成检错算法,利用该方法检错成功率达到100%。
