基于弹性并发的文件校验模型①
2020-01-15阮晓龙于冠军
阮晓龙,于冠军
1(河南中医药大学 信息技术学院,郑州 450046)
2(郑州祺石信息技术有限公司,郑州 450008)
互联网+时代下,数字资源的数量和种类呈现出爆发性的增长趋势,数字资源的存储规模日渐巨大[1].数字资源获取过程中的漏洞、通信传播过程中的数据丢失、黑客的恶意攻击等也随之增多,数字资源的存储普遍存在质量问题[2],如不能快速验证数字资源的完整性,将极大的降低资源服务质量,甚至带来灾难性的后果.
内容服务商早期在进行文件校验时,通常直接使用Hash算法对文件进行计算,从而判断其内容是否改变.但随着数字资源的不断增大、网络的快速发展,其效率低下、校验存在限制的特性越来越突出.
目前针对解决数字资源问题的相关技术手段越来越多,比如:文献[3]中Long Wang等人针对流媒体服务提出采样验证、本地文件格式检查、特定编码协议语法验证3种文件完整性验证方法;文献[4,5]中针对P2P文件提出了延时计算、基于Merkel校验的文件验证方法;文献[6]中方燕飞等人提出基于多层MD5消息摘要,并行计算的文件完整性校验方法;文献[7,8]中张永棠等人提出基于粒度抽样的文件校验方法,在舍弃一定准确性将校验安全性能控制在可接受范围内的情况下,大幅提升文件校验效率;文献[9]中李昊宇等人提出基于B+树技术,在云存储环境下多副本数据的完整性验证方案.
以上的研究在校验效率方面均有有较好的提升,但并没有与校验准确性、服务器性能做到完全兼顾,也没有充分考虑到在不同服务器下的实际应用.针对现有方案存在的未能兼容服务器环境、准确性与效率等问题,本文提出一种弹性快速的文件校验方法,对存储的数字资源进行评估,从而解决数字资源的质量问题,提升文件校验速率,保障数字资源服务者的效益.
1 文件校验分析
1.1 分析模型
在介绍本文提出的文件校验模型之前,首先需要清楚文件校验耗时的组成,具体如式(1)所示.

对于文件来说,一次校验耗费时间由文件读取耗费的总时间t′以及文件Hash计算耗费的总时间t′′组成,两者综合起来就是决定文件校验耗费时间的主要因素.
在对文件进行Hash计算时,CPU核心处理能力越好、CPU使用率越高,计算耗费时间也就越短.但在进行Hash计算的同时要充分考虑到服务器的磁盘I/O效率,一般来说主要通过磁盘I/O、内存等方式实现文件的读取,毫无疑问放在内存中进行处理是最优的选择,然而对于大文件来说,无法通过内存映射文件的方式将其直接放置,这时就需要将文件进行切分处理,从而使并发计算成为可能.
1.2 分布式校验支持
对于分布式存储系统来说,其存放资源可能是碎片化、重复性的,通过调配系统将这些资源进行集中调配,为文件校验处理引擎添加校验任务;文件校验引擎根据派发的任务,按照校验模型进行文件校验,并将结果回写至调配系统,从而完成文件的校验.本文主要阐明文件校验的算法模型,关于分布式多系统调配的业务逻辑在此不再做进一步的介绍.本文全部实验均是在单台服务器环境下进行,通过优化单个节点的执行效率,从而提升整个系统的运行性能.
2 文件完整性校验方法
2.1 文件校验原理
基于上述文件完整性校验方法,综合其优缺点,本文提出基于弹性并发的文件校验模型:对于待校验文件f,将其分为m个数据块,对m个数据块同时进行多并发切割计算,然后判断切割后的数据块是否超出限制长度l,如果超出则继续进行递归切割计算,否则直接进行Hash计算,最终得到结果值为a1;比对a1、文件隐藏属性记录值a2、数据库记录值a3三方是否完全相同,若相同则说明文件正确,不同则表示该文件已被篡改,其算法流程如图1所示.

图1 并发文件校验算法流程示意图
本模型使用弹性并发计算资源文件,其耗费时间主要由并发读取文件耗费最长时间t′、计算耗费最长时间t′′所决定,其具体耗费时间计算如式(2)、式(3)所示.


其中,n为递归次数,tr为每次递归切割读取文件块所耗费的最长时间,tj为每次递归切割计算文件块所耗费的最长时间.因此,并发校验文件耗费总时间的计算公式如式(4)所示.

本文进行文件校验时,通过指针对待处理文件进行读取,每次读取指定长度l,然后将其转存至内存中进行计算,计算完毕则自动释放内存,直至全部计算结束,因此内存占用会维持在l*并发数(以下定义为i)左右.
在操作系统中进程是其管理单位,线程则是进程的管理单位.不管是在单线程还是多线程中,每个线程都有一个程序计数器、一组寄存器、堆栈.进程进行切换的实质就是被中止运行进程与待运行进程上下文的切换,在进程未占用处理器时,进程的上下文存储在进程的私有堆栈中[10].这就像多个同学要分时间使用同一张实验桌,所谓要回收正在使用同学的使用权,就是让其把属于自己的东西拿走;而赋予某个同学实验桌使用权,只不过就是让他把自己的东西放到实验桌上罢了[11].
与进程切换不同,线程的切换开销则小很多,只需要保存和恢复线程的寄存器内存,栈的切换也是通过寄存器的切换来完成的.由此可见线程的切换比进程的切换代价要低很多,因此本文使用单进程多线程的方式进行文件并发校验.
2.2 最优并发数量
当进程、线程的乘积大于等于设备总CPU核心数时,其处理效率是相对最优的.这是因为进程需要一些资源(CPU使用时间、存储器、I/O设备等)才能进行工作,且为依序逐一进行,也就是说每个CPU核心任何时间仅能运行一项进程.因此并发数为CPU核心数时,即可达到最优的程序执行效率.继续增加并发数,执行效率会持续提升,多余的并发线程将排队等待被执行.由于本文读取文件会占用一定的时间,为了使CPU始终处于工作状态,并发线程数最好是CPU核心数的两倍,最大并发处理量每次应不超过磁盘I/O的瓶颈,同时应充分考虑服务器内存容量等资源.
本文使用MD5计算算法以512 bit为最小单位,因此CPU核心的每个计算量应为512 bit的倍数,综合考虑服务器磁盘I/O、计算损耗,每次切割计算的文件大小不易设置过大,应根据业务处理实际情况进行设置,本文将其初始值设定为10 MB.设定读取长度为l(10 MB),CPU核心数为c,内存容量为m,读取长度l、并发数i的初始值计算方法如式(5)、式(6)所示.

当内存容量m大于2*c*l时,并发数i为CPU核心数的两倍;当m大于等于c*l且小于等于2*c*l时,并发数i为c;当m小于c*l时,并发数i为m除以l的向下整数商值.因此在进行并发计算时首先应得到待校验文件大小,当其大小不超过10 MB时直接进行Hash计算,超过时先得到服务器CPU核心数量、内存容量,然后按照公式创建对应数量的并发执行文件校验.对于CPU来说每颗核心都要处理10 MB左右大小的数据,一直递归执行直到全部计算完毕为止.
3 实验结果与分析
3.1 实验环境
本次实验服务器资源配置如表1所示.

表1 服务器配置信息
为排除其它因素对本次实验的影响,此次实验仅保留原生的操作系统,不安装任何软件/服务/组件(测试程序除外),最大程度的减少实验影响因素.
3.2 实验结果
本文提出的文件校验算法模型可根据服务器环境自动弹性设置参数,为验证其灵活性及通用性,本次实验采用不同存储规模的文件进行验证,一是使用小文件(1 GB以下)进行算法模型验证,二是使用大文件(10 GB)进行验证.
通过实验,得出MD5计算耗时是线性变化的,文件越大耗费时间越长,使用传统MD5校验与本文校验模型对比测试,其实验结果如图2所示.
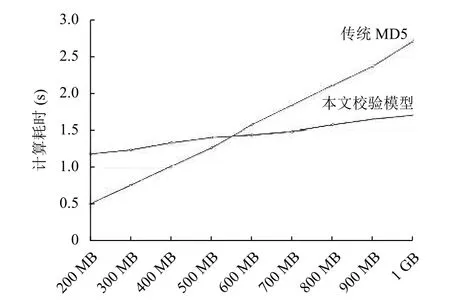
图2 传统MD5与本文校验模型计算耗时对比图
从图2可以看出传统MD5计算文件大小与耗费时间呈正比关系,耗费时间随着文件的增大而线性增加,由于MD5自身以及服务器内存等实验环境因素的影响,当待校验文件超过1 GB之后耗费时间递增,因此以下实验进行对比时使用其理论值做比较,实验结果如图3所示.
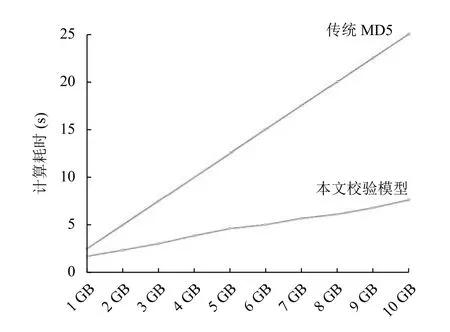
图3 传统MD5理论值与本文校验模型计算耗时对比图
从上述实验结果来看,当待校验文件大小不超过600 MB时,传统MD5校验方式比本文校验模型耗时要短,这是因为实验时本文校验模型包含了文件切割、内存转存等开销.当待校验文件超过600 MB后,本文校验模型与传统的MD5串行计算对比,其计算效率明显提高.
下面从服务器资源占用方面对其进行分析,进行文件校验时本文校验模型服务器资源占用情况如表2所示.
从表2中可以看出CPU使用率逐步增高直至稳定,内存占用大小从c*l左右直至升高到c*l*2左右,其内存占用率很低CPU利用率很高,而待校验文件比较小时CPU利用率比较低,这是由于文件切割耗时较长,导致了整个校验时间耗时较长.

表2 本文校验模型服务器资源占用情况
在小文件处理上本文校验模型相比于传统MD5校验耗时更长,但在大文件校验中计算效率十分明显.由于实验环境条件影响,并无法做到在上万台服务器上运行本文校验模型,即便如此,通过在实验室CPU内存2核4 GB、4核8 GB、8核16 GB、16核16 GB等几种当下常见服务器配置上的运行,也能够很好的印证上面的结论.
3.3 实验分析
对于文件校验来说其优劣主要由结果的正确性、时间成本、适应性、可移植性、鲁棒性这5个方面决定,通过这些判断条件能够很好的评估文件校验算法模型是否准确高效.
本文提出的校验模型基于MD5算法进行优化,其本质相当于对待校验文件进行了一次完整的MD5计算,得到最终结果与事实复杂度完全相符.在保持计算复杂度不变的前提下,使用并发计算能够大大节约时间成本.通过自适应弹性并发,可以变相调节服务器磁盘I/O占用时间以及CPU核心占用时间,其几乎能适应所有规模的文件校验以及各样服务器环境.通过采用小批量循环计算、自适应参数的方式,确保了服务器资源占用始终处在正常的范围内,不会因磁盘I/O占用时间过长或者CPU占用时间过长导致系统出现宕机或假死情况.
为更好的分析本文校验模型,将其与传统MD5、普通多线程、抽样校验进行对比,对比结果如表3所示.
本文校验模型相对于抽样校验,其执行效率并不算高,但其准确性更高,可将其准确率等同于传统MD5校验准确率.相对于普通多线程校验其最大的特点就是灵活适配服务器环境,有效提升文件校验执行效率的同时,兼容各种不同容量规模的数字资源.无论是流式碎片还是虚拟机导出的超大服务器备份文件,
即便是在服务器资源配置十分低下的情况下,也能保证高效的执行效率,降低服务器故障、业务无法正常运行的风险.

表3 不同文件校验模型对比
综合以上实验及分析,可以认为本文校验模型自适应能力强、能够有效的提升执行效率.
4 结论与展望
本文提出的一种基于弹性并发的高效文件校验算法模型,综合服务器磁盘I/O效率、服务器CPU处理能力,在将服务器资源占用控制在正常范围内的同时,充分利用CPU核心计算资源提高校验效率,对于存储的资源文件能够快速进行校验,确保其完整性.同时对于超大文件,比如1 TB大小的文件,利用小批量循环切割、读取、计算的方式极大的降低磁盘I/O和内存的占用.
本文校验模型可适应于各种文件校验场景,假如对文件校验效率要求比较高,则可以使用抽样校验+本文校验模型,在舍弃一定准确性的前提下,对抽样文件弹性并发校验,更进一步地提升其计算效率;如果对文件准确性要求比较高,则可以使用本文校验模型+MD5结构改造,由于 MD5 算法本身就具备一定的碰撞特性[12],通过对MD结构基础上的改造,在牺牲一部分处理时间的前提下,能够有效规避MD5碰撞问题,保障文件校验的准确性.
