基于DE-YOLO的室内人员检测方法①
2020-01-15张明伟蔡坚勇曾远强
张明伟,蔡坚勇,2,3,4,李 科,程 玉,曾远强
1(福建师范大学 光电与信息工程学院,福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室,福州 350007)
3(福建师范大学 福建省光子技术重点实验室,福州 350007)
4(福建师范大学 福建省光电传感应用工程技术研究中心,福州 350007)
1 引言
目标检测的场景分为室内和室外,室内环境的变化虽然不如室外环境那么复杂,但它们对于运动物体的检测也将产生显著的影响.由于对室内人员检测的需求性更强,本文主要研究室内人员的检测.比如,教室学生检测就是室内场景下人员检测的一个重要的方向.针对教育中的室内人员检测问题,本文完全可以通过计算机视觉的相关技术——目标检测,从而解决教室学生检测问题.
有关目标检测的技术,分为传统算法和深度学习算法.传统算法主要分为目标实例检测与传统目标类别检测.自2010年,深度学习成为计算机视觉的主要研究方向,使用卷积神经网络进而大幅提高了图像检测的准确率,因此越来越多的人将深度学习的思想应用到目标检测类别检测中.在这方面,基于深度学习的目标检测与识别算法已经成为主流,主要有三大类:基于快速CNN的目标检测技术,如R-CNN、Mask RCNN[1]等;基于回归学习的目标检测与识别,如SSD[2]、YOLO等;基于学习搜索的目标检测与识别,如AttentionNet、FSRL[3]等.其中YOLO系列的算法是一个端对端的模型,其模型结构复杂度要优于R-CNN系列,很适合对实时性要求较高的应用场景[4].
本文采用回归的目标检测与识别方法,以深度学习网络YOLO v3为基础,将教室中的学生作为待检测目标.因为检测目标只有室内人员,为了降低模型的冗余度和提高检测的精确度,提出一种DE-YOLO神经网络结构,对网络的结构进行改进,并对层级结构中的参数进行调整,使得不仅减少模型的占用空间大小,而且能准确识别教室中的学生.通过本文对DE-YOLO和YOLO v3的实验结果对比,DE-YOLO运行速度明显优于YOLO v3,同时保证了预测准确率.并且基于内存大小为8 GB和型号为Inter i5的CPU硬件环境处理,不使用GPU情况下,检测速度提升了3FPS.
2 相关工作
2.1 YOLO v3的原理
2016年Joseph Redmond 等人提出了YOLO (You Only Look Once)算法,它主要基于回归学习,实现用单一网络对图片只要看一次就能检测与识别目标[5].通过完善发展,于2018年提出YOLO v3,也是目前效率最高的版本[6].YOLO v3依然保持了YOLO v2的快速检测,并大大提高了识别的正确率,尤其是在小目标的检测与识别上,识别率也有较大的提升.相对于YOLO v2,YOLO v3结合ResNet的思想,运用了若干个ResNet模块[6].YOLO v3在网络框架方面,大量使用具有良好表征能力的3×3和1×1的卷积层,并网络结构中不断穿插着一些ResNet.最终YOLO v3整体的网络结构中包含了53个卷积层,因此Joseph Redmond也把它称为Darknet-53,如图1所示.
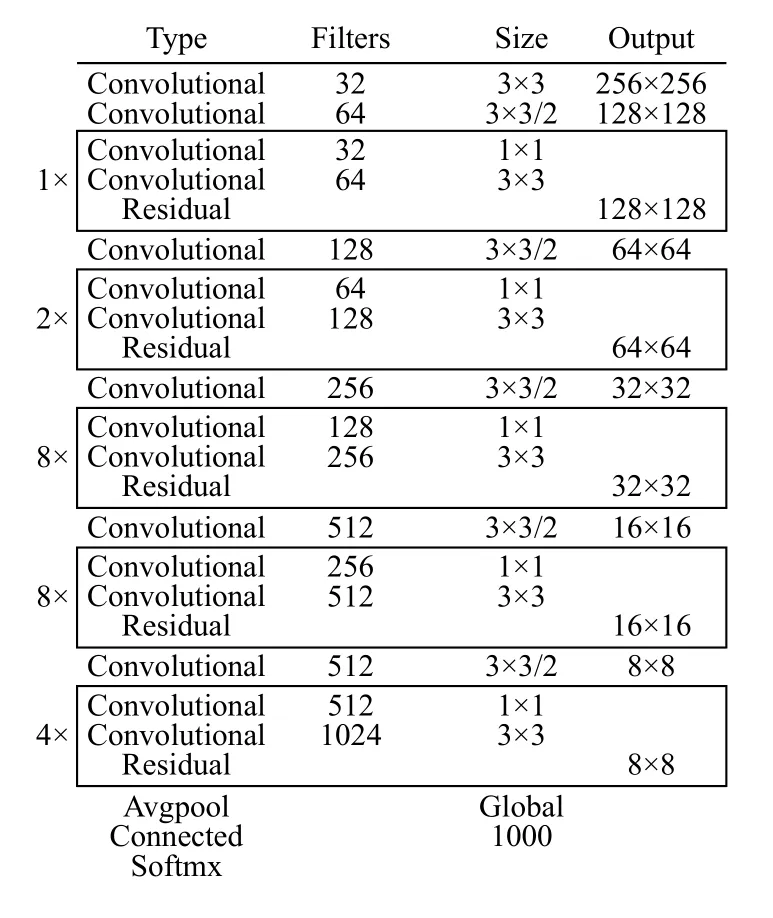
图1 Darknet-53网络结构图
借鉴Faster RCNN的思想,YOLO v3还引入了多尺度预测方式.每种尺度预测3个boxes,anchor的设计方式依然使用聚类,将其按照大小均分给3种尺度[7].同时网络结构中最后的分类器也从Softmax函数改为logistic函数,使得能够支持多种类型目标的检测与定位.
2.2 DenseNet的原理
2017年 Huang 等提出了 DenseNet (Densely connected convolutional Networks)网络[8],主要对ResNet和Inception两种网络的对比学习:如果卷积神经网络在每个单元的输入及输出之间有更短的连接,它实质上有更深、更精准、训练更高效的特点.DenseNet的本质是在于对目标特征的学习,通过的表征信息的最大化利用,来达到网络模型的最简化和最优化,尽可能降低参数冗余.
DenseNet网络结构中内嵌3个dense block,每个dense block中串连着4个卷积层,在每个dense block中,可以把每个卷积层之前所有前置卷积层的输出汇总为输入.每个dense block的结构如图2所示,层与层之间可以用池化层相连.
DenseNet引入这样的dense block有如下优点:
(1)由于网络中每层都会接受前面所有层的特征输入,为了避免随着网络层数的增加,后面层的特征维度增长过快,在每个阶段之后进行下采样时,会首先通过一个卷积层将特征维度压缩至当前输入的一半,再进行池化操作,即解决梯度消失的问题;
(2)通过每层之间的跳跃连接,加强了网络模块之间的信息交流,其本质就是特征的复用.与ResNet不同的是,这样的密集型连接,使得信息流更大,不是简单的叠加效果,使得小模型产生大数据.
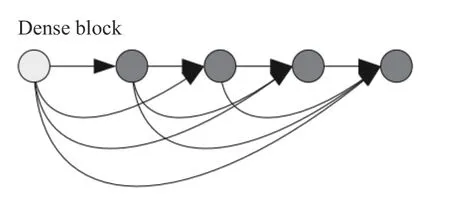
图2 密集卷积块结构图
本文正是对DenseNet的上述优点的充分考虑,在YOLO v3上提出DE-YOLO网络,达到对目标特征的重复的学习和利用,使得算法在室内人员检测方面有着更优的效果.
3 DE-YOLO的设计
本文考虑到室内人员检测时,存在检测目标比较密集,且先验框大小不一.比如,教室中学生的检测就是一个很好的例子.所以,首先需要对数据集进行预处理,再对网络层级结构进行删减和替换,并将密集连接的思想更新进去,搭建一个全新的网络,最后达到设计的效果.
3.1 基于K-means的数据集预处理
当神经网络来检测一幅图像中的多个目标时,其实网络实际上需要大量的先验框执行预测,并只显示出它确定为一个对象的那些检测结果.由于R-CNN系列中先验框的高度和宽度都是手动设置的,客观性较差.如果选取的的先验框的高度和宽度比较合适,所得的模型的性能将更优,使得预测效果更好.所以,YOLO v3中为了针对数据集的目标框大小进行聚类分析,可采用K-means算法.
K-means算法是一种经典的聚类算法,通常使用欧几里得度量等方式作为两个样本相似程度的评价指标[9].因为先验框设置的最初目的是为了使得ground truth与预测框的重合度尽可能高,即式(1)中的交并比IOU的值越接近为1越好.但是由于这些经验值不一定适用于对室内人员检测的场景,会对最终的检测产生一定的干扰.例如使用欧几里得度量会让大的边界区域比小的边界区域更易出现误差,导致精确度下降.我们希望通过先验框来获取良好的IOU,因为它不受边界框的尺寸影响.因此我们选择新的方式来表达IOU,如下[10]:
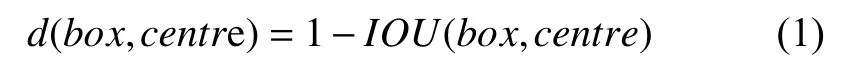
其中,centre表示为类簇中心,box表示为目标,IOU(box,centre)表示类簇中心框和目标框的交并比.交并比IOU表示预测框的准确程度,其公式为:
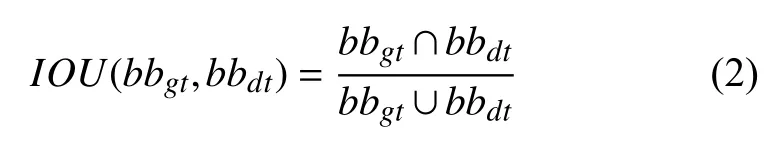
其中,bbgt表示真实框,bbdt表示预测框.
由于K-means算法具有收敛于局部最优解的特性,所以本文起初会选取多组初始值,对其分别运行算法,如果获得目标函数值最小,则选取这一组方案作为最后聚类结果.最终的聚类结果受初始化的影响很大,一般采用随机的方式生成中心点[11],对于比较有特点的数据集可采用一些启发式的方法选取中心点.如果目标的边界框大小太多,反而会增加一定的计算量而导致效率降低.所以,实验选取K=[1,20],统计出不同锚点框数量(K的大小)下所对应的IOU值,具体的关系 如图3所示.
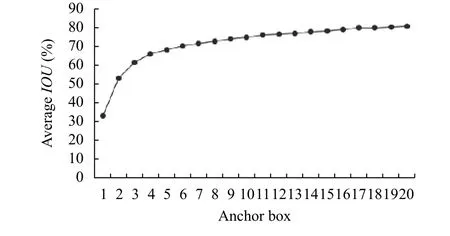
图3 锚点框数量与平均交并比的关系
根据图中锚点框数量与平均交并比的关系可知,在K=6之后,曲线变化趋于稳定,且先验框数量合理,不会带来过多的计算开销,所以本文得到的6个聚类的中心为(10,14)、(23,27)、(37,58)、(81,92)、(136,169)、(344,319).
根据Joseph Redmond的工作,YOLO v3在COCO和VOC数据集上分在32×32、16×16、8×8这3个不同的尺度上进行预测[12],最后判断最终结果,如图4所示.
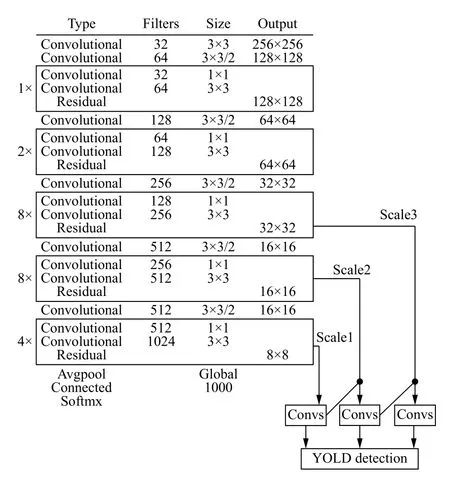
图4 YOLO v3多尺度预测方式
图4中YOLO v3分别在3个尺度上对目标进行预测:尺度1上,在基础网络之后添加一些卷积层再输出box信息;尺度二上,在尺度1进行上采样再与16×16大小的特征图相加,卷积输出box信息;尺度3上,与尺度2类似,使用了32×32大小的特征图.
3.2 DE-YOLO网络结构的设计
随着网络层数的加深,虽然ResNet模块可以缓解梯度爆炸的现象,使得精确度不会随之降低.但是,这是基于网络结构可以比较复杂,对内存占用没有较高要求的前提下.为了尽可能减少网络结构的复杂度,降低网络模型对内存的占用,并保证较高的精确度.使用Dense block模块将表现的比ResNet模块更好.
本文借鉴DenseNet网络的思想,为了压缩模型并提高特征信息的复用率,需要对网络结构进行调整.考虑到在32×32、16×16尺度的特征图上,包含较多的表征信息,而在8×8尺度上的表征学习能力有限.所以将YOLO v3这三个尺度上的ResNet模块替换为与其维度相适应的Dense block模块,其更新的网络如图5所示.通过对尺度2、尺度3构建这样一种密集连接的网络结构,使得不同维度学习到的表征信息得以极致的利用和汇总,为下一步的精准预测提供的有效的保证.
4 实验分析
4.1 实验环境与数据
实验环境如表1所示.
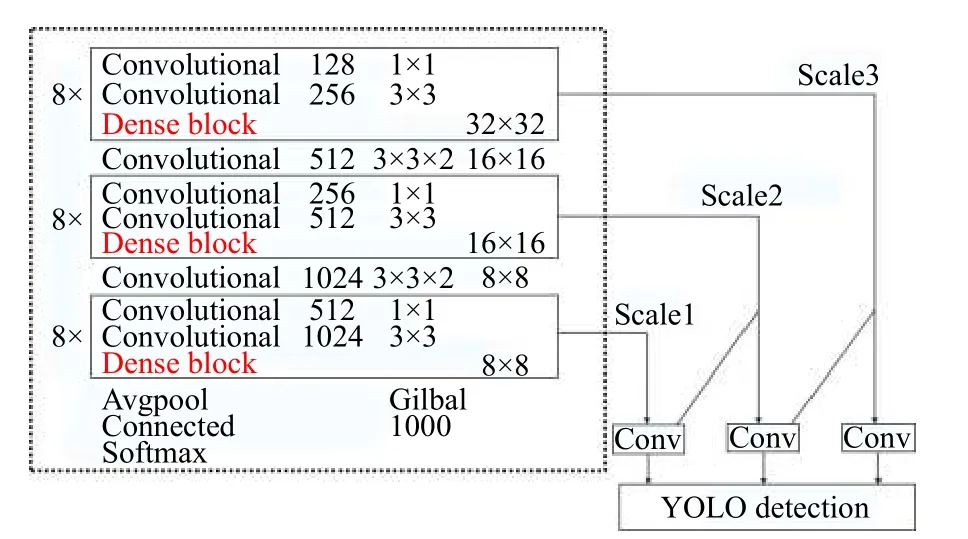
图5 DE-YOLO网络结构

表1 实验环境
为了保证实验结果的可靠性,数据集的选用十分重要.Pascal Visual Object Calsses (VOC)[13]是计算机视觉领域中的一个公认的数据集,具有一定权威性.本文选用VOC2012数据集,并提取了数据集中1000张不同的person照片.随机抽取820张图片作为训练集,80张图片作为验证集,100张图片作为测试集.
4.2 实验设计
数据集用labelImg软件标注完成后,分别对YOLO v3和DE-YOLO网络进行训练.实验过程中,网络的学习率(learning rate)为10–4,梯度下降的优化器选用Adma,以便快速收敛并正确学习,训练迭代次数为1000.实际训练过程中,为了避免过拟合情况的出现,每迭代50次对模型进行保存,输出后缀为.h5文件.
本文算法流程图大致如图6所示.
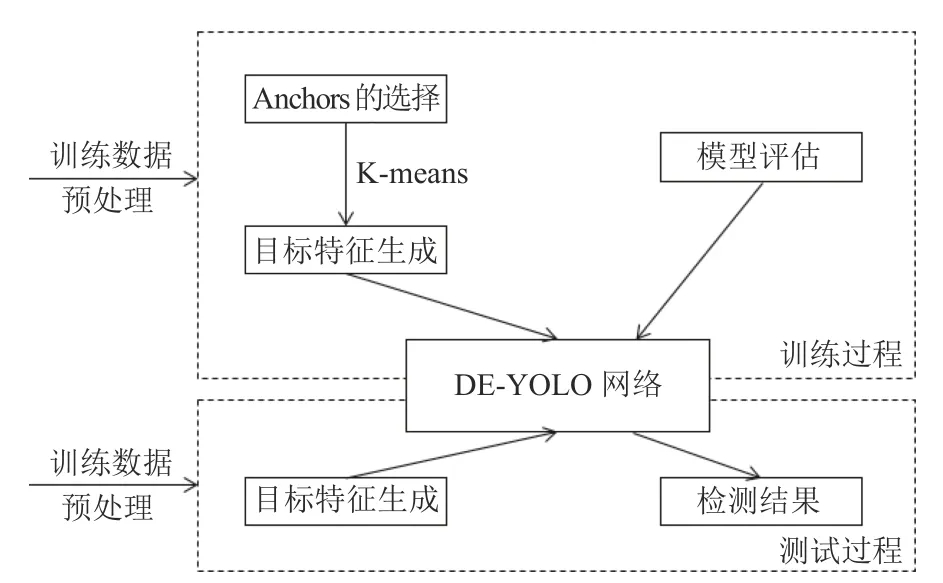
图6 算法流程图
从图中可以看出,实验分为训练和测试两个部分,分别对训练数据和测试数据进行预处理.通过对训练集的K-means聚类分析,得到相应目标特征,并通过DE-YOLO模型进行训练.最后进行测试并模型评估.
本文方法总体流程图,如图7所示.
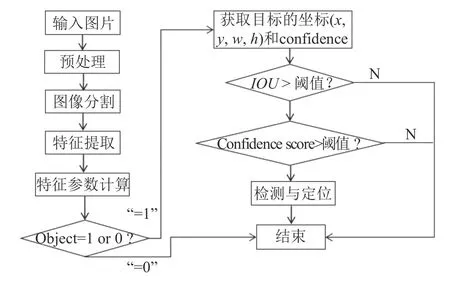
图7 室内人员检测方法流程图
4.3 模型评估
为了避免数据集中的常出现的类不平衡的现象,使得无论正负样本如何变化,都不影响模型表达的准确性.本文采用准确率P(precision)、召回率R(recall)、精确率ACC(accuracy)、F1值(F1-score)值作为评价指标,通过ROC曲线图来评估其模型的性能[14].
precision表示被分为正例的示例中实际为正例的比例,其中设TP为将正类预测为正类数,FP为将负类预测为正类数,公式如下:
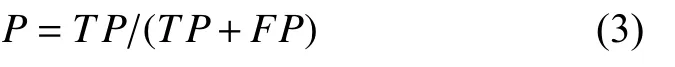
recall是覆盖率的度量,度量有多少个正例被分为正例,其中设FN为将正类预测为负类数,公式如下:
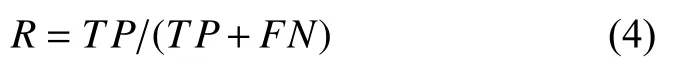
accuracy是被分类正确的样本数占总样本的比例,其中设TN为将负类预测为负类数,公式如下:

F1为p recision和 r ecall的加权平均调和,公式如下:

4.4 实验结果
为了评估DE-YOLO性能,与YOLO v3进行对比,其迭代次数与精确率关系对比如表2所示.DE-YOLO算法较于YOLO v3算法更能有效的对室内的人员进行检测.
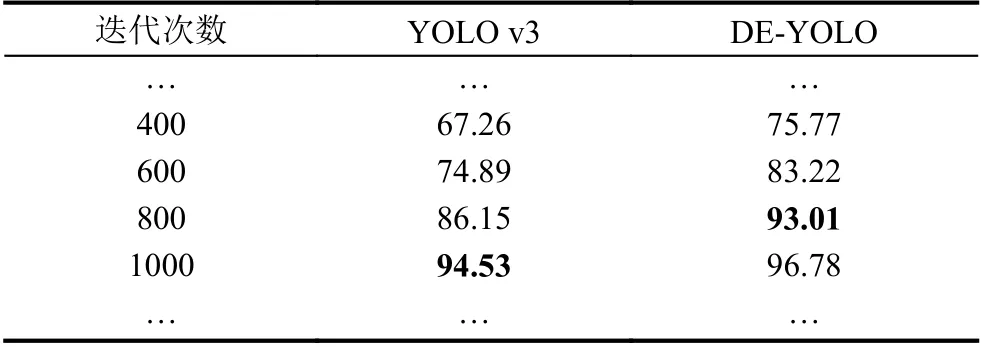
表2 迭代次数与精确率关系对比(单位:%)
从表2中可以看出,DE-YOLO在迭代800次的精确率已达到93.01%,与YOLO v3迭代1000次时的精确率相差无几.当DE-YOLO迭代1000次时,比YOLO v3的精确率提高了2.38%.对于DE-YOLO网络误检情况,选取部分经典的实验结果,如图8和图9所示.

图8 DE-YOLO误检情况(a)

图9 DE-YOLO误检情况(b)
在图8和图9中存在的误检情况,主要是由于神经网络很难区分现实与画像中的人物,只要是是符合目标的特征的对象,都将被检测输出,很难避免.
绘制YOLO v3和DE-YOLO的ROC曲线,如图10所示.这里引入AUC (Area Under roc Curve)概念,即ROC曲线下的面积大小[15].AUC的值越接近为1,则模型性能越突出.由图10可得,本文的DE-YOLO模型性能优于YOLO v3的原网络.

图10 ROC曲线图
5 结语
本文提出了一种基于密集型连接的DE-YOLO卷积神经网络,旨在通过网络之间的密集型,连接提高其通道中的特征信息的利用率,并减少内存占用空间.另外,网络通过K-means对数据集的预处理,提高对室内人员检测的精确性.通过实验表明,DE-YOLO在保证与YOLO v3相近正确率的情况下,减少了模型大小和内存占用空间,可以将模型大小从235 MB减少至33 MB,实现了轻量化处理.另外,由于存在数据较少、目标标注引入干扰背景的问题,DE-YOLO检测的精确度提升会遇到瓶颈,同时网络结构如何进一步的压缩和裁剪也是一个值得研究的方向,后期的工作将针对这些问题进入深入的研究.
