基于基址重定位的快速域名压缩算法①
2020-01-15闫夏莉吕万波张海阔岳巧丽
闫夏莉,王 骞,吕万波,张海阔,岳巧丽,曹 爽
1(中国互联网络信息中心,北京 100190)
2(国家税务总局 电子政务管理中心,北京 100053)
DNS (Domain Name System)主要用于承载域名与IP地址之间的转换,是互联网的关键基础设施之一.权威域名服务器的性能一直是DNS的研究重点之一.在面向DNS服务器性能的参数中,平均响应时间是重要评价指标,也是用户感受服务器性能的主要体现.近年来性能测试中又引入了响应时间百分比,即响应时间小于期望时间的概率百分比来进一步度量和表示其性能,以期为用户带来更好的体验[1,2],这也是本文研究的重要性能参数.真实的响应时间包括网络传输时间、服务器处理时间等,用户的网络状况千差万别,因此本文研究的重点是提升服务器处理时间的百分比.
本文提到的DNS服务器特指权威域名服务器,其查询请求可分为两类.一类是针对特定资源记录RR(Resource Record)的查询,如A记录、NS记录查询等,查询结果返回相应的资源记录,在本文中用“常规查询”表示.另一类为IXFR[3]/AXFR[4](Incremental Zone Transfer/Authoritative Zone Transfer)查询,用于主从服务器间的数据同步,查询结果返回区域数据中变化的资源记录甚至完整的区域数据,该过程称为增量/全量区域数据传送.以根服务器为例,全球共13台根服务器及其镜像服务器支撑根区数据解析服务[5].各服务器及其镜像通过全量区域数据传送来保障根区数据的一致性[6].
为了提高响应时间百分比,有必要先确定其性能瓶颈,进行针对性的优化.在本文中,为了避免盲目的优化,首先建立了基于排队论[7]的数据模型,将DNS服务器抽象为一个M/M/c的随机服务系统,并依据此模型对响应时间百分比进行了分析,确定性能瓶颈之后,对DNS的数据特征进行了分析,并结合基址重定位技术提出改进算法.最后对提出的改进算法进行实验和性能评测.
1 DNS服务器的数学模型
1.1 模型描述
排队现象由两方面构成,一方请求服务,另一方提供服务.顾客通过排队服务系统要依次经过如下过程:顾客到达、排队等待、接受服务和离去.DNS服务器的查询应答过程符合排队服务系统的规律.服务器收到来自各客户端的查询,请求按一定的速率到达,经服务器解析返回应答包.DNS服务器可以是单个服务台,也可通过SO_REUSEPORT机制,将多个套接字绑定在同一个端口实现多个服务台.
假设DNS服务器为M/M/c随机服务系统,模型如图1所示.该系统具有以下性质:(1)查询请求为单个到达,到达的时间间隔符合参数λ的泊松分布;(2)每个请求所需的服务时间独立,服从μ的负指数分布(忽略常规查询与IXFR/AXFR查询的应答差异);(3)系统有c(c≥1)个服务台,服务的顺序按照先来先服务FcFs(First come First served)规则;(4)系统容量为N(N>c,缓冲队列长度为N-c),请求源无限;(5)如果请求到来时队列已经被占满,则出现丢包,否则进入队列等候.
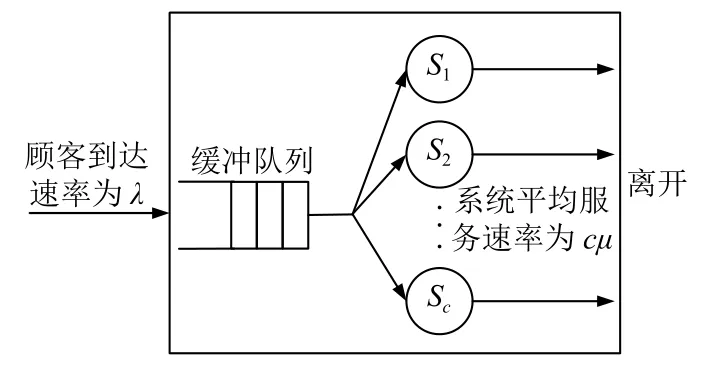
图1 M/M/c随机服务系统模型
表1显示了建模过程用到的数学符号及相关说明.其中系统负荷强度为本文只考虑稳定平衡状态( ρ<1)的情况.

表1 DNS服务器数学建模符号说明
1.2 性能瓶颈分析
服务器对查询请求的响应时间Ws为请求等待时间Wq和解析时间之和.响应时间百分比γ %可表示为其中为用户期望时间.下面将分别针对单服务台模型和多服务台模型分析响应时间百分比的分布概率.
1)c=1时,为M/M/1排队模型.
根据参考文献[8],有:

或者
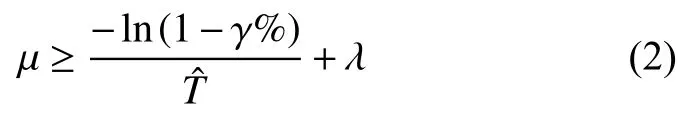
对于DNS服务器,如果不通过流量控制等策略进行人工干预,请求到达速率λ为不可控因素.为了分析的方便,在此假设λ不变,用户期望时间也不变.根据式(2)可知,响应时间百分比 γ %随着解析速率μ的增加而增加.
2)c>1时,为M/M/c排队模型.
查询请求到达时,如果缓冲队列已满,新的请求无法响应,服务器出现丢包,此时的概率称为损失概率.由参考文献[8]可知,损失概率与缓冲队列长度有关,增加缓冲队列的长度可降低损失概率.为了分析的方便,本文重点讨论没有请求损失的场景.因此,可假设缓冲队列的长度无限大,推导出响应时间的分布函数[7]为:
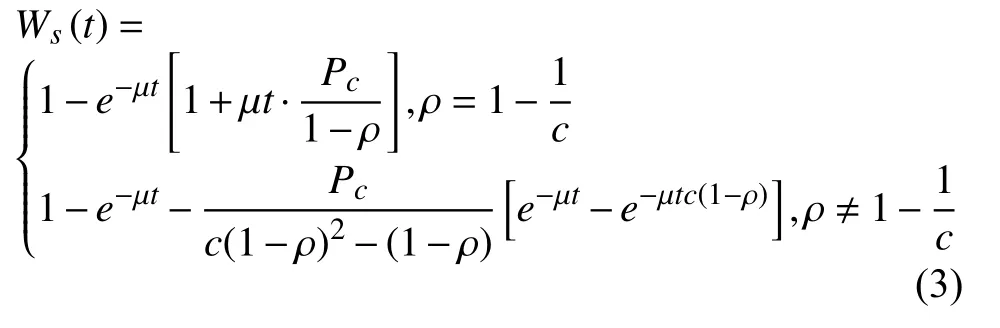
其中,
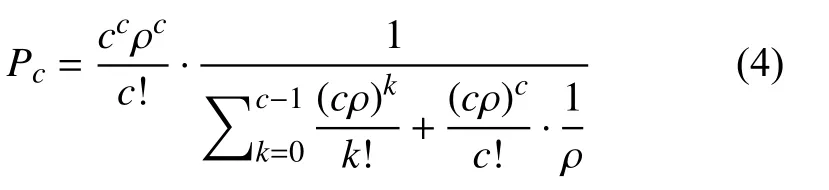
由上述公式可知,在请求到达速率λ不变的情况下,响应时间与服务台数量c和解析速率μ有关.DNS服务器实现多服务台处理查询请求的原理是提高了多核CPU的利用率,多服务台的数量与CPU数量相关.考虑到运行成本,增加多服务台数量的方式不作考虑.在服务台数量固定的情况下,需要通过提高解析速率μ,来优化响应时间百分比.
查询请求的解析过程依次为:接收请求、解压缩请求包、查找匹配资源记录、组装应答包、域名压缩和发送应答包.解压缩请求包和组装应答包规则简单,耗时少,在此不做讨论.而数据包的接收发送依赖于网络通信框架,查找匹配资源记录依赖于数据结构和查找算法,改进这两个过程成本较高.因此本文将对域名压缩算法进行针对性优化.
2 DNS域名压缩现状
2.1 传统压缩算法
为了分析域名压缩,需要对DNS服务器的数据处理流水线进行分析,见图2.为了分析的完整性,流水线中同时考虑了服务器的数据来源和数据出口.DNS服务器通过动态更新或区域数据传送对本地区域数据进行更新,收到更新数据后进行解压缩再存储到本地.服务器收到查询请求后在存储数据中查找匹配资源记录,然后对查找结果进行组装、压缩,最后返回应答包给请求端.对DNS服务器来说,数据更新频率远低于查询请求的频率,即大部分的查询使用同一版本的数据进行应答.

图2 传统DNS数据处理流程图
域名压缩通过减少DNS数据中域名的冗余来降低带宽占用.不论是常规查询应答或IXFR/AXFR查询应答,其出口带宽大于入口带宽,尤其是AXFR查询应答,这种差异更加明显.以根区的全量区域数据传送为例,数据包共包含2万多条资源记录.而CN、COM等顶级域的资源记录总数则达到了千万数量级,域名压缩的重要性可见一斑.域名压缩算法直接影响着解析性能.
传统域名压缩算法衍生于LZ77[9].该算法基于数据本身包含有重复的字符序列这个特性,使用指针来代替已经出现过的字符序列来达到压缩的目的.域名压缩利用指向数据包中已经出现过的域名的指针来代替整个域名或者部分域名[10].该压缩算法的压缩比高,但压缩过程耗时,主要消耗在域名的匹配过程[11].在高查询量场景下,在解析过程进行实时的域名压缩非常消耗系统资源.这是制约解析速率的主要原因.
2.2 改进压缩算法
根据DNS数据的特点,域名压缩只能采用无信息损失的无损压缩算法[12–14].本文对无损压缩算法进行了充分的调研[15–21],结果如表2所示,只有部分LZ77系列算法适用于DNS域名压缩.统计编码和字典编码中的LZ78算法不符合DNS标准协议.
近年来LZ77算法的改进方向可大致分为两类:一类是尝试与其他算法结合以获取更好的压缩效果,如与霍夫曼编码结合产生的DEFLATE算法等,这类改进由于结合了统计编码同样不符合DNS协议.另一类则通过优化数据结构和算法等方式提高压缩效率,如LZSS,LZO等,此类算法适用于DNS,但是数据处理流程与传统压缩算法相比并未发生实质性变化,因而同样无法减少资源消耗,提升解析速率.
根据上述分析,为了提高压缩速率,可以考虑将压缩模块前置,将实时压缩转为写时压缩,即在数据存储时进行压缩处理.结合DNS服务器的特征,压缩前置可以充分利用读写操作的不对称性,提高系统资源的利用率.但是,现有域名压缩依赖于域名位于数据包中的绝对位置,对于查询应答,服务器无法提前预知需要回复的资源记录,因而现有的压缩算法无法实现压缩模块前置.
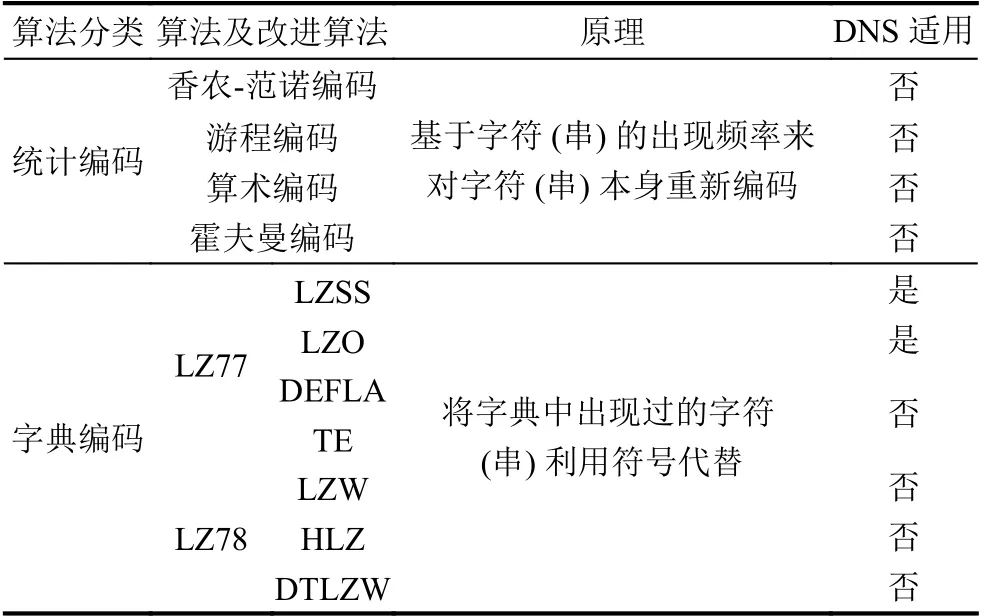
表2 常见无损压缩算法列表
3 基于基址重定位的快速域名压缩算法
3.1 DNS数据特征分析
为了改进压缩算法,需要对DNS域名压缩的原理进行分析.压缩是基于数据的冗余度进行的减小数据存储空间的过程[9].DNS根据域名空间倒置的树形结构进行区域的划分.区域数据以资源记录为最小单位进行存储,区域内资源记录的所有者(owner)都是其区域顶点(zone apex)的子域[10],因此区域内的域名具有冗余性,这是域名压缩实施的基础.此外,DNS的资源记录之间还有其他相关性,可以进行进一步的域名压缩.
对权威域名服务器来说,无论是常规查询还是IXFR/AXFR查询,其应答包大部分情况下包含多条相关的资源记录.这些资源记录可能是查询的特定类型的资源记录,也可能是帮助请求端进一步获取最终信息的相关记录.AXFR查询则为特殊情况,其应答返回了区域内的所有资源记录.分析查询应答结果后,发现DNS数据具有以下相关性.图3是域名相关性示意图.
(1)I类:相同域名,相同类型的资源记录
DNS查询应答包中,域名和类型都相同的资源记录从不单独出现,称为RRset[10](资源记录集合).AXFR查询应答时也同样如此.因而,域名和类型都相同的资源记录具有最基本的相关性,称为I类相关记录.该类记录可以进行域名压缩.
(2)II类:相同域名,不同类型的资源记录
IXFR/AXFR查询应答常常包含域名相同但类型不同的资源记录.常规查询应答时,A记录/AAAA记录也常作为glue记录[10]一同返回.部署DNSSEC[22]后,RRSIG记录与其相关记录也会同时返回给请求端.这些相关记录包含相同的域名,同样可以进行域名压缩,称为II类相关记录.
(3)III类:NS记录及其glue记录
对大部分查询请求来说,获取IP地址才是其最终目的.因此,返回NS记录时,A记录/AAAA记录常作为附加信息同时返回给请求端.此时,NS记录中的授权服务器的域名(NSNAME[23])与A记录/AAAA记录的所有者是相同的,同样可以进行域名压缩.这种相关记录称为III类相关记录.
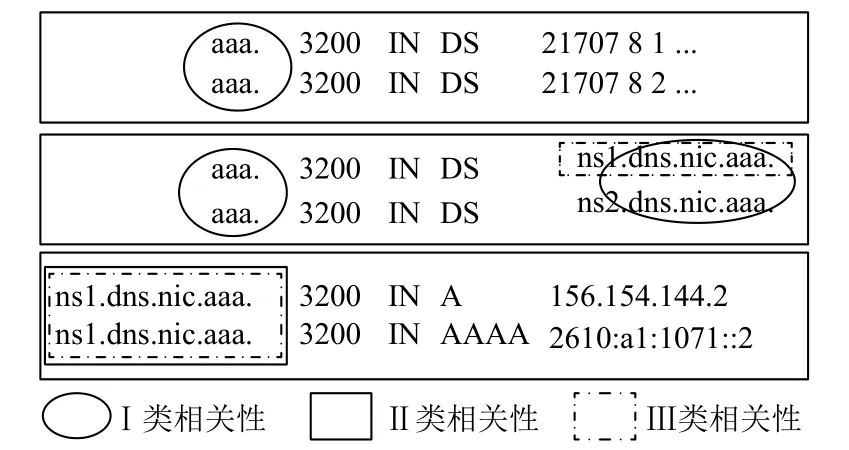
图3 域名相关性示意图
上述3类相关记录中的域名是域名压缩的主要对象.以根区数据为例,其资源记录类型多为 NS记录、DS记录、A记录/AAAA记录.全量区域数据传送时有82%的域名进行了压缩,其中根据上述3类相关性进行压缩的域名占总压缩域名中的95%(I类、II类、III类分别占36.4%、31.6%、27%).除了上述3类相关性外,根区数据还利用了NSEC记录中的next owner[22]进行域名压缩,但此类压缩不具备通用性.NSEC记录在其他区域的数据中并不常见,通常DNSSEC部署更倾向于采用NSEC3机制[22].常规查询应答时,利用NSEC记录的next owner进行压缩的可能性也很小.因此该相关性在此不做考虑.类似MX、SRV等类型的资源记录可参考NS记录及其glue记录的方式实现域名压缩,在此不再赘述.
3.2 本文改进算法
为了实现压缩模块前置,需要取消域名压缩时对数据包的依赖,因此,本文在新的算法中引入了基址重定位技术.基址重定位[24]是把程序的逻辑地址空间变换成内存中的实际物理地址空间的过程.重定位表(Relocation Table)用于记录重定位时需要修改的地址的位置(重定位入口的偏移),以便进行内存地址的修正.类似地,在域名压缩时,可以先进行域名的相对压缩,再利用重定位表,修正偏移量,最终完成传统域名压缩.
结合DNS数据特征的分析结果,本文改进算法只需聚焦于I类、II类、III类相关记录的域名压缩,即可保障原始压缩比.首先,在数据更新时完成I类相关记录中域名的相对压缩,称为分组压缩.之后,在应答时无需查找,直接利用重定位表实现I类相关记录中压缩域名的压缩偏移量修正以及II类相关记录中域名的压缩.最后实现III类相关记录的快速压缩,称为关联压缩.运用本文改进算法后,数据处理流程图见图4.

图4 本文改进算法的数据处理流程图
本文改进算法的具体步骤如下,
(1)分组压缩
将区域数据根据RRset、域名进行分组.对RRset中的域名进行相对压缩,偏移量以RRset首字节为基准,并为同一域名下的所有RRset建立重定位表.重定位表在系统启动后即可建立,并在数据更新时进行同步更新.相对压缩结果如图5所示.重定位表如表3所示.
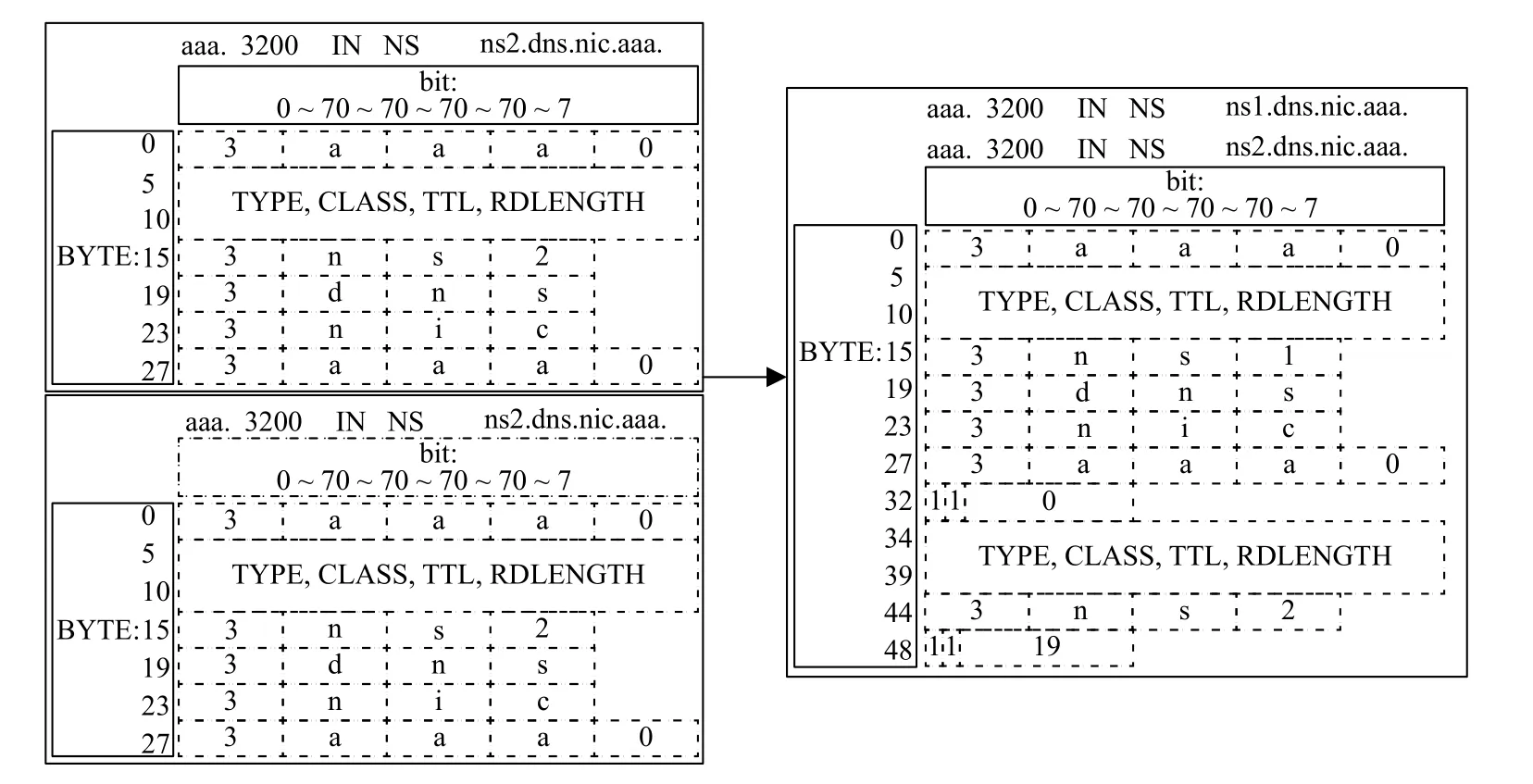
图5 RRset相对压缩示意图
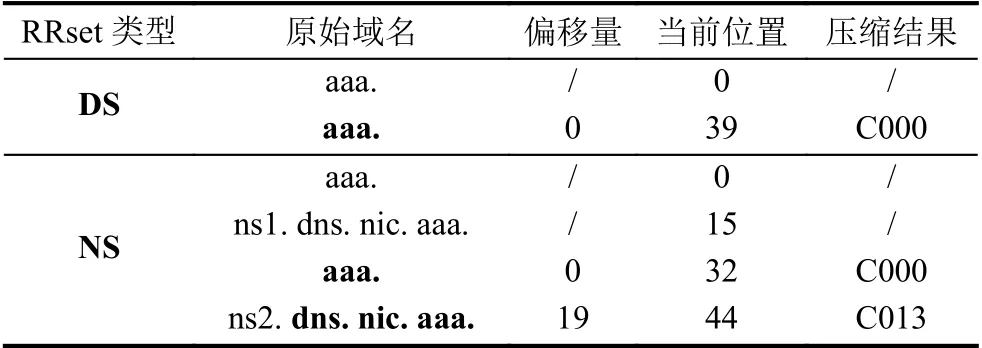
表3 重定位表
(2)利用重定位表修正压缩偏移量
在组装应答包的过程中,利用重定位表修正相对压缩的偏移量.同时,完成II类资源记录的域名压缩.上述过程支持零查找.
(3)关联压缩
对于III类资源记录,在存储时如果不做特殊处理,无法提前完成关联压缩.在不改变解析软件数据结构的前提下,可以在应答时通过动态字典实现关联压缩.动态字典只在应答过程建立,保存已添加的NS记录的相关信息.在添加NS记录或A/AAAA记录时,通过搜索动态字典,即可完成III类资源记录的域名压缩.传统压缩算法会对应答的资源记录中的所有域名,甚至其父域名建立字典,进行匹配域名的查找,字典量大,搜索速率低.而用于关联压缩的编码字典只有少量数据,搜索速率很高.表4和表5分别是相同域名资源记录的压缩结果和最终压缩结果.
4 实验结果与分析
为了验证本文改进算法的性能,本文使用一台Linux服务器作为测试平台,CPU为Intel Xeon,2*16核,单核主频2.00 GHz.测试软件采用BIND,上文已经阐述适合于DNS的改进算法是LZO与LZSS,LZO与LZSS相比算法复杂度更低,本文选择LZO算法进行对比实验.分别采用传统算法,改进算法(LZO)及本文算法实现压缩过程,并以根区数据为样本进行测试.

表4 相同域名的资源记录压缩结果

表5 最终压缩结果
4.1 压缩比
压缩比是衡量域名压缩的重要参数.本文对常规查询和AXFR查询分别做了测试,分析压缩比变化.
对于常规查询场景,测试结果如表6所示.表中(+ED)代表DNSSEC查询.结果表明,对于常规查询3种算法的压缩比相同.
对于AXFR查询,利用根区数据进行了对比测试.采用传统算法和改进算法,根区的全量数据共79个数据包,1341 181字节;采用本文算法时,根区的全量数据共79个数据包,1350 026字节.本文算法在全量区域数据传送场景下,与另外两种算法相比仅增加了0.6%的数据量.测试结果说明本文算法完全满足DNS服务器的压缩比实际需求.
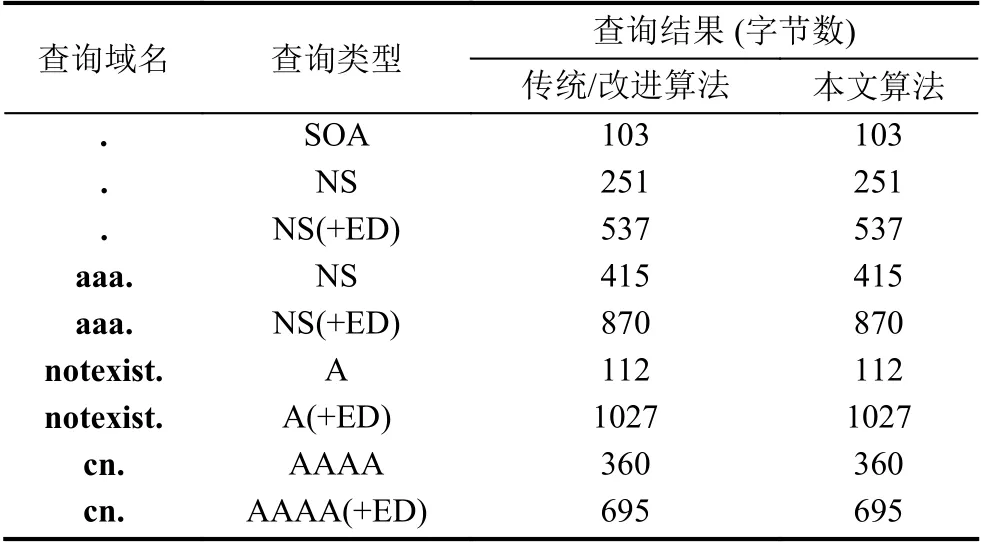
表6 压缩比对比结果
4.2 ASL
域名查找算法对域名压缩性能有重要影响.ASL(Average Search Length)[25]是衡量查找速率的主要标准.ASL指平均查找长度,其中查找成功的ASL指找到已有元素的平均探测次数,查找失败的ASL指找到元素插入位置的平均探测次数.本文对4.1节常规查询的相同场景做了ASL对比分析,结果如表7所示(“/”代表无压缩,0代表不需要查找).
采用传统算法和改进算法时,其字典保存了应答数据包中的所有域名及其子域名.采用本文算法时,其字典中只包含需要关联压缩的域名,保存的域名数要远小于另两种算法.由结果可知,本文改进算法减少了压缩时查找算法的ASL,有效提高了压缩速率.
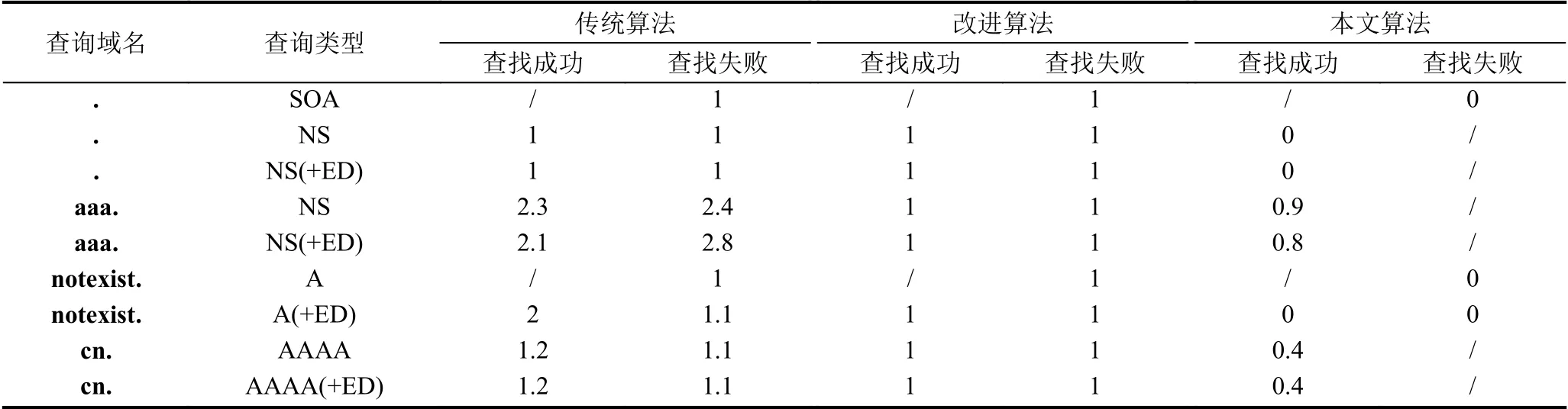
表7 ASL对比
4.3 响应时间百分比
图6显示了各不同查询响应时间的百分比的测试结果对比.
与传统算法和改进算法相比,本文的算法可以有效缩短响应时间,将90%以上的耗时控制在0.5 ms以下,而传统与改进算法只能将90%以上的耗时控制在0.65 ms以下,只有20%的耗时分布在0.5 ms以下.采用本文算法后DNS服务器的查询响应性能有明显提升,达到了预期目标.
5 结论
本文基于排队模型的分析结果,提出了一种基于基址重定位的快速域名压缩算法.新算法充分利用了DNS服务器的数据特征,在不改变原有数据结构的前提下,通过重定位表和动态编码字典实现快速压缩,提高了压缩速率.相比于传统算法和改进算法,本文算法提高了响应时间百分比,可以为用户带来更好的体验.
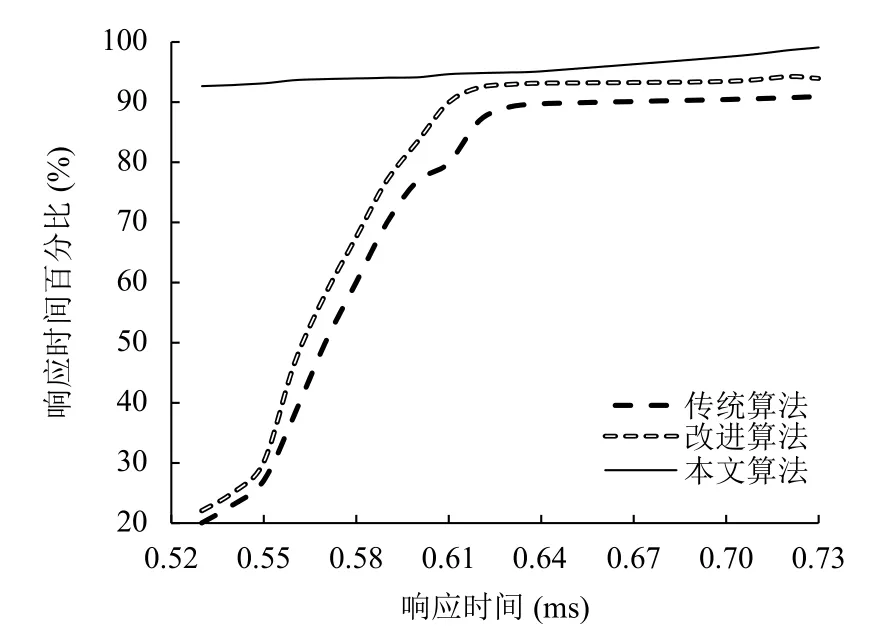
图6 响应时间百分比对比图
