基于空间变换密集卷积网络的图片敏感文字识别①
2020-01-15林金朝蔡元奇张焱杰
林金朝,蔡元奇,庞 宇,杨 鹏,张焱杰
1(重庆邮电大学 光电工程学院,重庆 400065)
2(重庆邮电大学 通信与信息工程学院,重庆 400065)
1 引言
随着互联网的快速发展,信息传播日趋复杂多样化,大量的包括政治反动、暴力、色情、违禁小广告等类型的敏感信息也在肆意传播.存在部分个人和团体利用互联网上合法的图片嵌入文字信息等方式散播敏感内容信息,严重影响了互联网健康环境.因此,对图片敏感文字的有效识别是保障互联网健康发展的迫切和合理的必要手段.嵌入到图片的文字通常为印刷体,常常为了混淆信息而带有大量干扰字符,而且中文字符结构复杂,包括偏旁、部首和字根,这给准确区分形近字增加了识别难度.场景文字识别(Scene Text Recognition,STR)指识别自然场景图片中的文字信息,而自然场景中的嘈杂背景、光照不均、字体变化、文字排布不规律等问题都会影响识别效果.针对技术发展过程可以分为单一文字识别[1,2]和基于文本行的识别两个方面[3–6].文献[1]利用字符笔画特征和HOG算子来提取文字块的特征,随后采用随机森林模型对文字进行分类处理从而达到文字识别的目的.文献[4]采用深度卷积神经网络算法来对图像信息进行处理,在复杂场景情况下提升了对文字识别的效果.文献[5]采用了一种基于深度学习的图片敏感文字检测算法,其重点在于BP神经网络算法和深信度算法在算法上的理论研究与优化,并没有考虑工程复杂程度和系统可实现的问题.文献[6]在深入研究和利用深度学习相关算法的基础上采用了基于FPJA与CPU的异构架构对含有敏感文字图片进行检测与识别,其方案中特征提取部分采用的是VGG-16网络,随着网络规模和深度的提升,产生过拟合并难以实现收敛.本文将密集神经网络与空间变换网络结合,能比较准确地识别复杂的背景、被扭曲、3D凹凸、艺术化、倾斜等复杂中文文本.DenseNet网络在底端接收图像输入,经过多层的神经网络进行特征提取与抽象,对得到丰富的卷积特征信息进行仿射变换,矫正过的图像信息然后被送入序列识别网络,对网络进行训练时,使用CTC[7]损失概率模型以实现网络识别优化.
2 相关工作
2.1 DenseNet网络
卷积神经网络深度的提升往往伴随着网络性能的提升,随着网络在广度和深度的扩展延伸,导致训练参数出现梯度消失、模型过拟合的现象发生,为了解决这一问题就提出了密集连接的卷积网络(DenseNet)[8].DenseNet是在Hightway Networks[9]和Residual Networks[10]以及GoogLeNet[11,12]的基础上产生的.区别于传统方法上单纯地拓宽或加深特征提取网络,DenseNet通过对特征信息的交叉复用,最大限度发挥网络的潜能,生成易于训练和参数高效化的精简模型,可以达到更好的效果.它的主要特点是前后层直接相连接并传导信息,获取信息的输入层集合了前面所有层输出的信息,而该层将学习到的特征信息作为输入传入到下面所有层级,这样就有效地提高了特征信息的利用率,避免梯度消失和过拟合的问题.
一个DenseNet由多个Dense Block模块和过渡层Transition layers组成,如图1所示.一个Dense Block模块中的每一层的输入集合了前面所有层输出的信息,过渡层Transition layers通过卷积和池化操作来改变特征图的大小.Dense Block可以从前面层级创造更短、更直接的特征并传递到后面的层级,在传递过程中不断改进信息和梯度流.DenseBlock模块使得它具有缓解梯度消失、加强特征传递、提高特征利用率和减少参数数量等优点[8].H4层不仅直接用原始信息x0作为输入,同时还使用H1、H2、H3层对x0处理后的信息作为输入;用一个如下的式子描述DenseNet中每一层的变换:

式中,Hl代表第l层的合成函数,常对应Batch Normalization (BN)[13]、ReLu和Convolution三个连续运算操作;xl是第L层的输出.

图1 生长速率为k = 4的5层Dense Block模块
2.2 STN网络
2015年由Jaderberg等人[14]提出空间变换网络(Spatial Transformer Network,STN),该网络可以对输入的图像信息在不改变其尺寸的情况进行旋转、平移缩放、对齐等变换操作,能有效地提高系统对特征信息的旋转不变性和尺寸不变性.空间变换网络的基本结构包括定位网络(Localisation Net);采样网格(Samples Grid);可微图像采样(Differentiable Image Sampling)三部分.
定位网络将输入特征图I∈RC,H,W,通过卷积网络后输入到回归层,生成空间变换系数θ,使用定位网络floc来预测2D仿射变换矩阵Aθn.
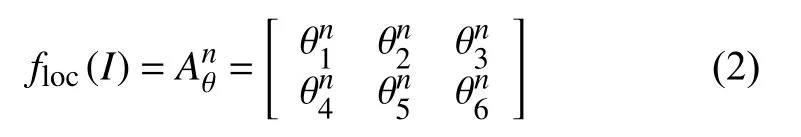
采样网络根据定位网络生成的变换系数θ构建一个采样网格Gin,Gin=(xin,yin),Tθ为二维空间的变换函数,输出特征图V上的坐标(xin,yin)通过Tθ映射到输入特征图I上的坐标(uin,vin),对应关系为:
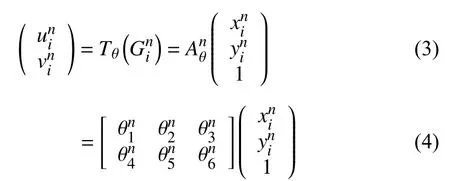
可微图像采样根据上面的处理结果,完成对输出特征图上每个坐标点的采样转换工作,并且采用双线性插值的方式来表示:
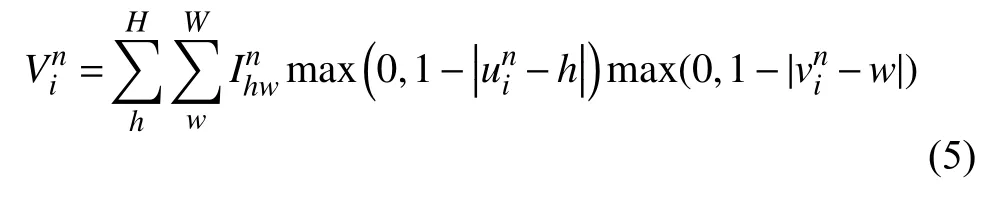
其中,Ihwn是输入特征图I在通道n处(h,w)位置的坐标,是输出的特征图Vin在n通道(xin,yin)位置处的坐标,n代表特征图的通道数,H、W分别代表输入特征图的高度和宽度.通过上述的3部分组成的空间变换网络可以独立地插入到神经网络中,并可以在网络中不断训练来修正参数完成对特征信息的仿射变换.
2.3 BGRU网络
Hochreiter等[15]出了一种循环神经网络最常见的变形——长短时记忆模型 LSTM.循环神经网络会以不受控制的方式在每个单位步长内重写自己的记忆,而LSTM有专门的学习机制能够在保持先前状态的情况下,记忆当前时刻数据所输入的特征.LSTM神经网络包含有3个门函数:输入门、输出门和遗忘门.
LSTM的改进版本GRU[16]只包含两个门函数:更新门和重置门.更新门zt表示过去时刻的状态记忆信息保存到当前时刻的程度,更新门zt的值越大,过去时刻的状态记忆信息保存到当前时刻的信息就越多.GRU的重置门rt表示当前时刻忽略过去时刻的状态信息的程度,重置门越小说明当前时刻保存信息越少,对过去时刻忽略的信息就越多.对GRU而言,由于GRU参数更少,不容易发生过拟合,收敛速度更快,因此其实际消耗时间要少很多,这就大大加速了算法的迭代过程[16].GRU神经网络的传播公式如下所示:

其中,xt表示当前时刻的输入;ht表示上一时刻的输出;Wz、Wr、Wh表示对应的权重矩阵;zt、rt分别表示更新门和重置门;*表示矩阵元素相乘.本文使用深度双向GRU神经网络模型如图2所示,网络包含左右两个序列方向上下两层的GRU网络.其中每层的GRU包含的隐含节点数目为256个,文本特征序列x={x1,x2,…,xt}在该层进行正向和反向处理后输出中间序列m={m1,m2,…,mt}.将中间序列作为第二层的输入进行正向和反向后输出向量y={y1,y2,…,yt},y包含了序列每一帧的预测概率值.
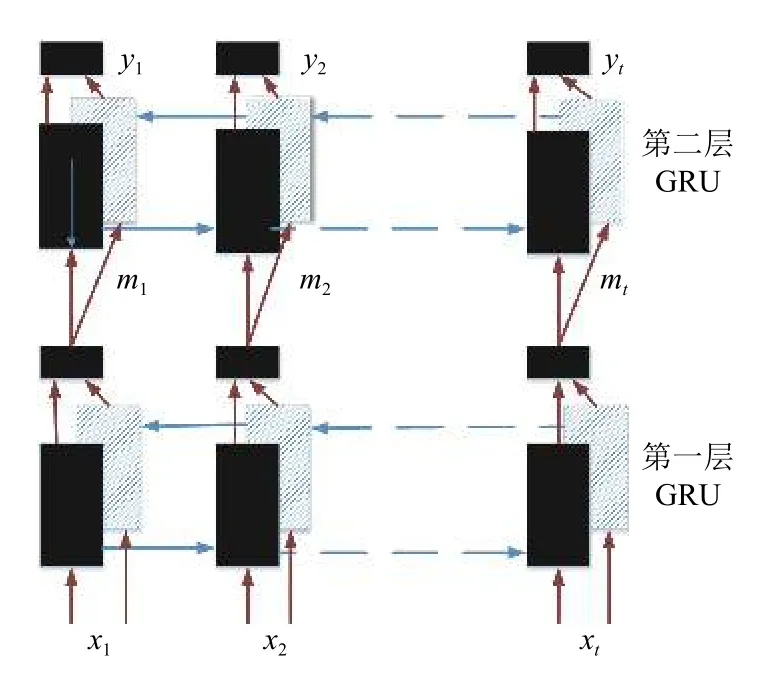
图2 双向GRU网络
3 本文模型结构
自然场景图片背景复杂,汉字种类繁多结构复杂,一方面使得简单的卷积网络(AlexNet[17]网络和VGG[18]网络)难以完全提取图像的底层特征细节,另一方面随着网络复杂性的提高又导致网络出现过拟合、参数繁多、难收敛等现象.DenseNet网络结构先提取图像底层特征,并通过空间变换网络对中文字符在大小、宽高比、角度、倾斜等方面进行2D仿射变换,从而提高文字的识别率.循环神经网络层BGRU对输入的特征序列x进行标记预测,输出序列y包含上下文信息可以得到距离较宽的文字进行更加精确的预测信息.对于包括含有模糊不清的并含有其它特殊文字,特征序列包含的上下文信息也有更好的优化处理效果.CTC层计算输入序列y={y1,y2,…,yt}对应的(汉字、英文字母、数字和标点共5990个字符)种标签元素序列的概率分布,映射函数通过去除空格和去重操作后输出可能的序列ι,统计并计算每个标签序列的条件概率p(ι/y),求出标签序列ι.CTC输出的序列标签ι参照概率字典上的文字,就可得到图片上的文字信息.将得到的文本送入到敏感语义分类器当中进行分类.
在模型训练的过程中,首先对图片进行归一化到相同尺寸且标签的长度保持一致,本模型统一尺寸设置为280×32,标签长度设置为20.通过一个卷积核为7×7,卷积步长为2的卷积层和卷积核为3×3,卷积步长为2的最大池化层.DenseNet包含了3个DenseNet Block模块,每个模块包含了16个dense layer层,生成率(growth rate,即加进每层的卷积核数设置)为12.实验中使用的过渡层包括批归一化层、Relu层和1×1的卷积层,然后是2×2的池化层,同时去掉DenseNet的全连接层直接连接到STN网络上.实验中将Transition Layer3作为子卷积网络,后面接入一个线性回归层和Relu,作为定位网络.根据定位网络回归得到的变换系数θ进行仿射变换,采样网格的生成和输出图片的采样,完成对图片的矫正工作,在此过程中特征图的尺度保持不变.
4 实验
4.1 实验数据集
实验数据集CTW (Chinese Text in the Wild)包含32 285张图像,总共有1018 402个中文字符,并包含平面文本、凸起文本、城市文本、农村文本、亮度文本、远处文本、遮挡文本,数据集大小为31 GB.以(8:1:1)的比例将数据集分为训练集(25 887张图像,812 872个汉字),测试集(3269张图像,103 519个汉字),验证集(3129张图像,103 519个汉字).Caffe-OCR中文合成数据集是人工生成的自然场景文本数据集,利用中文语料库,通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成,共360万张图片,图3是部分人工合成图片的示例.将该数据作为敏感文字图片训练集,同时图像分辨率为280×32.
鉴于含有敏感文字图片的特殊性,在互联网网络平台只收集到360张含有敏感信息文字的图片,同时制作2000含有少量字符的敏感文字图片作为敏感图片测试数据集.数据利用中文语料库(新闻和常见用语),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成.包含汉字、英文字母、数字和标点共5990个字符,每个样本固定20个以下字符,字符随机截取包含敏感词汇和非敏感词汇的句子.图4(a)为未标注的图片,图4(b)、图4(c)标注图片.

图3 人工合成的图片
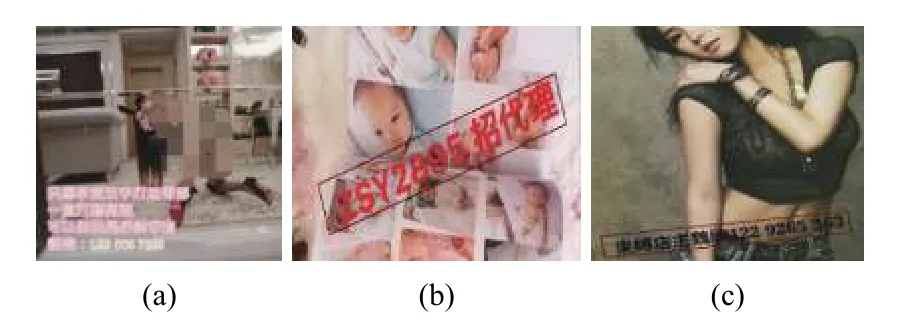
图4 含有敏感字符的图片
4.2 实验设置
实验基于Pytorch和Keras框架,所有实验的训练和测试是在计算机配置为内存为16 GB,显卡GPU为GTX TITAN X的服务器上进行的.
本模型的输入尺寸为设置为280×32,采用随机梯度下降法(SGD)进行训练.动量和权重衰减分别被设置为0.9和2.5×10–4,首先对数据集CTW进行处理归一化处理,学习率初始值为10–4,学习率每隔10 K次迭代变为原来的0.5倍.然后在Caffe-ORC中文合成数据集进行训练,采用的是ADADELTA梯度下降优化算法,该算法是对Adagrad的扩展,方案对学习率进行自适应约束,但是进行了计算上的简化.Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值.初始学习率设置为0.01.在模型微调的阶段,没有设置特定的终止迭代次数,保证对每一个模型结构进行充分训练,直到各个模型最终收敛为止.随后,我们使用一个10–4的权重衰减,并使用高斯分布来初始化权重.在数据集里,我们在每一个卷积层(除了第一个)后加上一个Dropout层,并设随机丢弃率(dropout rate)为0.2.测试误差仅对一项任务进行一次评估.为了验证本文模型的有效性,在敏感图片测试数据集上设置了两种类型的对比:(1)VGG、ResNet、DenseNet之间常用典型的卷积神经网络的对比.(2)循环神经网络两个变种GRU与LSTM的对比.具体包括以下的端到端文本识别模型实验:“DenseNet+CTC”、“DenseNet+STN+BGRU+CTC”、“DenseNet+BGRU+CTC”、“ResNet+CTC”、“+ResNet+BGRU+ CTC”、“VGG+CTC”、“VGG+BGRU+CTC”、“DenseNet+STN+LSTM+CTC”.
实验设置采用了控制变量法的准则,包括对数据集的训练和测试,尽可能地控制其他因素对实验的影响,这些影响因素可能包括:优化方法、机器配置、学习率和迭代次数等.本文采用的识别算法评价标准为编辑距离(Edit Distance)、单词识别准确率(Words Recognition Accuracy).编辑距离[19]指的是任意两组字符串st1和st2,由其中一组字符串转化为别一组字符串所需最少的编辑次数.通常编辑距离越大,也就说明两组字符串相似度越低,编辑距离越小,则说明相似度越高.编辑距离相似度表示为:
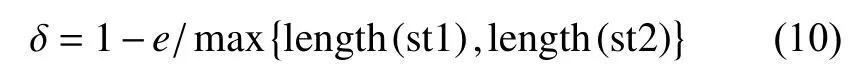
单词识别准确率指的是正确识别序列的总数与标签序列总数的比值.识别准确率表示为:

4.3 实验结果与分析
4个卷积神经网络结构的模型在数据试集CTW上的文字识别准确率随迭代次数变化的曲线图如图5所示,实验设置每训练迭代5 k周期测试一次.通过实验曲线图中实验数据对比,本文设置的模型网络(DenseNet+STN+BGRU+CTC)测试准确率要高于没有STN结构的网络,随着测试次数的提升,含有STN结构的网络收敛最快,最终的准确率为0.87,比没有STN结构的网络更加稳定,识别准确率更高.
4个典型卷积神经网络结构的模型在数据集CTW上的编辑距离相似度随迭代次数变化的曲线图如图6所示,设置每迭代5 k次测试一次,开始训练时模型编辑距离相似度就迅速攀升,并且很快达到平稳状态,曲线更加的平滑,相比之下,无STN的结构的曲线在测试次数为2–13的阶段波动更大,但也慢慢趋于稳定.
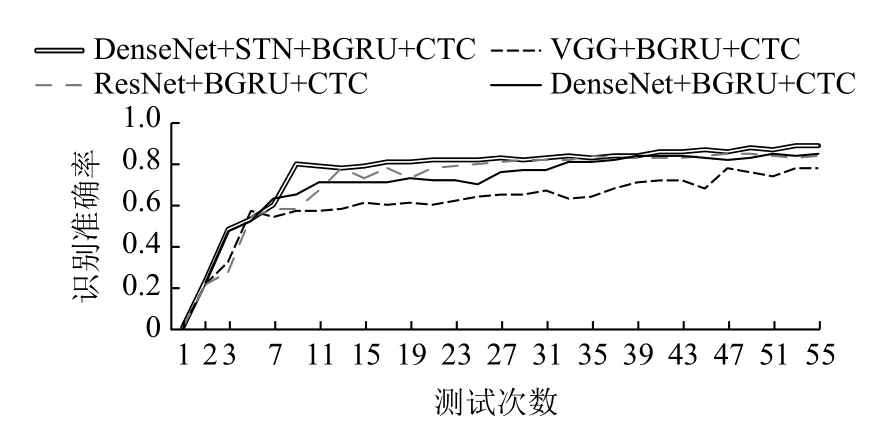
图5 模型识别准确率变化曲线
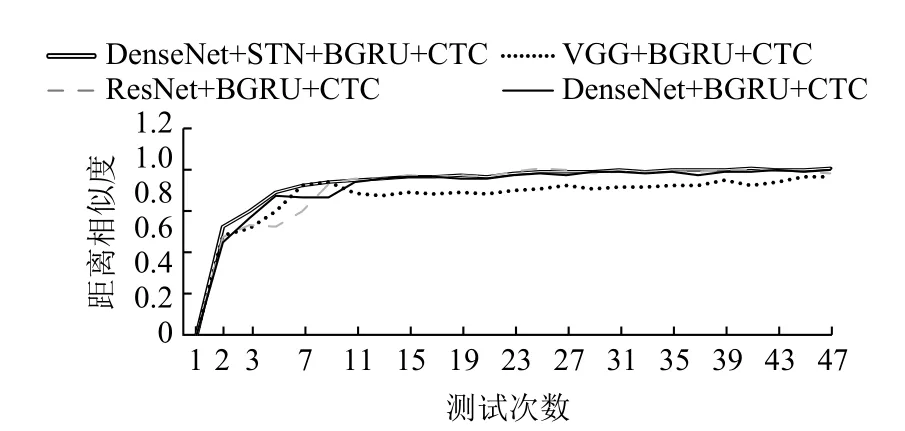
图6 模型编辑距离相似度变化曲线
在DenseNet的输入特征图的数量并有效提高该网络的计算效率,就引入一维卷积层到DenseNet网络中,即BN-ReLU-Conv1×1-BN-ReLU-Conv3×3版本的合成函数Hl,也就是DenseNet-B,一维的卷积层能有效的减少实验中的输入特征.在实验后续设置中,为了进一步提高模型的紧凑性,可以减小Transition layers层的特征映射数量.当Dense Block模块包含了m个特征图时,可以让Transition layers层生成不超过θm的最大整数个特征图,其中0<θ≤1称为压缩因子.当θ=1时,转换过程中的特征图的数量保持不变.我们称DenseNet当θ<1时为DenseNet-C,我们在实验中设定θ=0.5.当同时使用了瓶颈层(Bottleneck layers)和压缩(Compression)的方法称为DenseNet-BC[8].本文DenseNet网络设置为DenseNet-BC.
通过分析表1使用的经典卷积网络与改进的DenseNet-STN网络以及GRU和LSTM的循环网络层对比.相较于VGG和ResNet,具有一维卷积和压缩结构的DenseNet-BC结构具有更好的识别效果,模型整体的文字识别准确率也就更高,同时这表明在相同深度和宽度的神经网络框架下DenseNet可提高对特征信息的变现力.
在实验的过程中,发现含有DenseNet特征网络的模型出现过拟合或者优化难等问题概率小于含有VGG网络和ResNet网络,对参数的利用也更高效,相同的数据集上,可以得到更好的识别效果.与此同时可以发现,基于GRU和LSTM网络的模型并没有在识别率上有直观的提升效果,但是对比表1的对应实验模型的大小来看,我们可以发现,前者比后者有更小的内存容量,由此说明在模型训练的过程占有更少的显存空间.
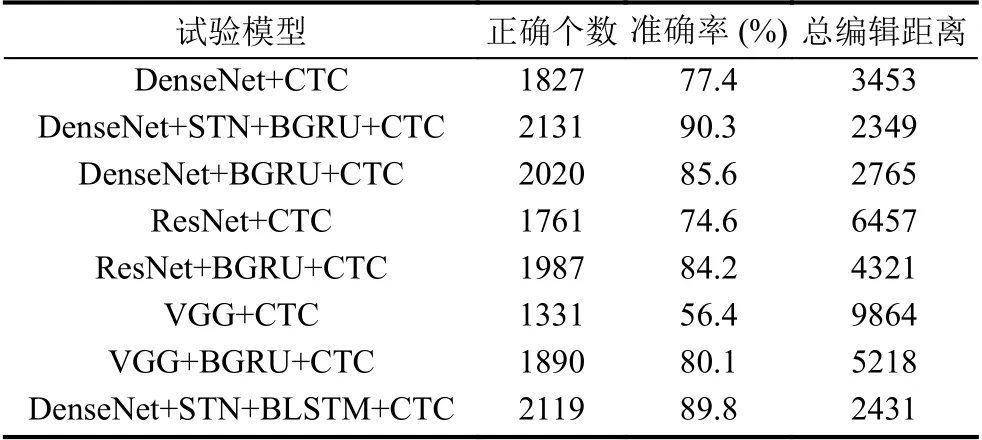
表1 模型在敏感图片数据测试集的识别统计结果
表2总结了各种模型组合在模型大小与运行时间方面的实验结果.通过分析可以发现,使用不同的特征提取层使网络模型在模型大小与平均识别时间上有着比较大的差距.本文提出的DenseNet-STN特征提取网络结构在敏感图片测试集上的平均识别时间为26.3 ms每张图,大致相当于1 s处理38张图片,符合实际应用之中对敏感信息图片处理的要求.通过比较发现,DenseNet-STN网络结构处理图片用时最多,其主要原因把时间用在特征提取和空间变换阶段.DenseNet虽然具有较好的加强特征传递和提高特征利用率等优点,但DenseNet Block内部联系紧密导致特征提取阶段相对VGG网络和ResNet网络的模型更加耗时,占用更多的GPU显存,而本实验中实验机器显卡内存只有16 GB基本够用.在实际应用环境下对硬件平台有了更高的要求,同时本模型对图片相对处理速度也符合要求.
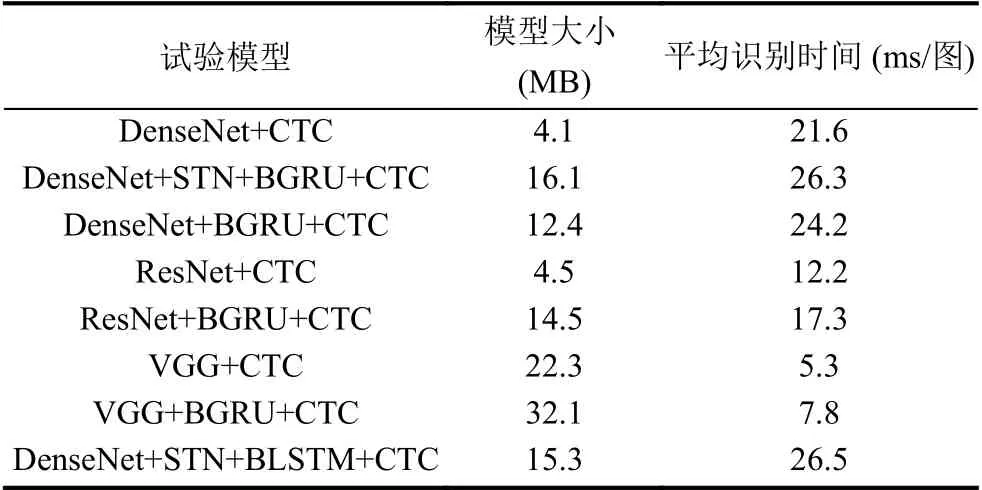
表2 模型在敏感图片数据测试集上的大小与时间效率的统计结果
5 结束语
本文提出了一种网络敏感文字图片识别的新方法,DenseNet-STN对复杂背景下的敏感文字图片进行特征信息提取和变换矫正,相比于前人研究的VGG网络和ResNet网络,实验表明本文模型能准确地识别被扭曲、3D凹凸、艺术化、倾斜等复杂短文本,模型的识别准确率、编辑距离相似度有着良好表现.与此同时,本文提出的方法在效率和算法还有很大的提高,在缺乏足够样本下对文字图片进行分析理解仍旧是个难题.
