基于信息聚合的银行理财产品管理系统设计
2020-01-10温腾灏郑亮朱婧雯曾昭平
温腾灏,郑亮,朱婧雯,曾昭平
(上海立信会计金融学院,上海 201209)
0 引言
当前,各家银行都推出了各种各样的理财产品,供人们去选择购买。但是,面对如此多的理财产品,许多用户在购买时无从下手。同时这些理财产品之间实际上的差异不大。一个能够提供对理财产品信息进行筛选并整合,最后能供用户进行挑选、购买理财产品的系统这时就变得非常重要[1]。
信息聚合技术常用来同质信息的管理及整合。最常见的应用之处在管理图书方面,为了能够快速便捷的找到需要的数据,图书馆采用信息聚合技术[2-4]。但是在理财产品方面,国内的信息聚合技术的应用就比较缺乏。通过浏览商业银行的关于理财产品的网页发现网站只是将理财产品根据收益率、期限等指标进行简单排序呈现,并没有做到聚合成类的。其他的理财平台,如京东金融、支付宝理财和360理财,前两者同样是和商业银行的网站一样简单的根据一项指标排序,将全部的数据直接呈现给用户,而360理财主要提供理财网页的导航,根据理财产品种类的不同,提供方不同,分别提供导航。
本文设计了一个银行理财产品管理系统,用来解决当下理财产品信息太过繁杂,用户很难精确找到自己所需要的产品的问题。本系统通过采集不同商业银行的理财产品信息,提取产品特征进行信息聚合展示,同时构建一个理财产品的评价体系,并且通过收集分析用户行为对理财产品进行综合评价排序。
1 系统总体设计
1.1 系统业务流程
系统将管理员和用户的登录分开操作。管理员能够直接管理用户信息,还可以对爬取数据的管理,对信息进行聚合及其评价从而进行聚合效果管理、聚合结果管理、查看理财产品信息聚合,还可进行点击量管理和产品或产品组收藏管理。
用户登录系统可查询到个人信息、理财产品资料和自己的交易记录,更改个人信息,还可以购买理财产品。用户可对理财产品进行评论、点赞与分享。管理员主要负责对理财产品进行爬取和管理,并管理用户权限。
1.2 系统架构
本系统采用三层设计,主要根据其实现层次划分为数据层、业务层和界面层。
●数据层:本系统数据层是设计系统底层基础环境的搭建,选择要采用的操作系统和数据库,其中数据库采用MySQL为数据库服务器支撑软件,为数据存储和管理的核心部分,也是决定整个系统总体性能的关键所在。提供用户和管理员进行增删改查。
●业务层:该层是根据系统的需求,把各个模块细分到各自的服务上,整体将系统分成日常管理、系统管理、查询管理、报表管理、产品信息管理、数据缓存、日常交易监控、日终报表八个模块。主要提供用户登录注册、购买产品的业务逻辑以及系统通用日志服务、权限管理控制。将使用Spring Boot集成。
●界面层:该层提供用户接口,使用HTML+Java Script组件完成系统界面的开发,使用Spring MVC完成系统API接口的实现。
2 系统功能模块设计
2.1 用户业务功能
系统管理员是针对理财产品管理系统本身进行管理的模块,主要实现各类理财产品的爬取、清洗、存储功能,用户信息权限的设置管理功能以及理财产品的设置、修改、查询功能。
管理员是系统的核心管理人员,要求在网上各大银行或外企爬取理财产品,并进行清洗整合后保存到本地数据库。主要爬取的对象有招商银行、中国银行、美国的Lending Club、Prosper和英国的Zopa。还要求提供管理员对用户和产品进行相应的管理功能,例如用户账号管理、用户购买权限管理设置等。
用户是本系统的主要使用者。用户可以在本系统进行登录注册,查询自己的个人信息、理财产品的信息,购买理财产品后可以进行点评与分享,在个人界面能查询到具体的交易记录。
2.2 信息聚合功能模块
该功能最终实现的是通过使用爬虫采集商业银行的理财产品的信息,经过数据预处理以及聚合算法,对理财产品进行聚合分析显示。功能的具体实现通过四个步骤:数据采集、数据预处理、聚类分析及结果显示。
(1)数据采集
本系统使用爬虫完成数据的采集,爬虫的实现通过使用Scrapy框架。第一步:搭建爬虫项目框架。第二步:框架配置文件编写。第三步:数据存储文件编写。第四步:管道文件的编写。第五步:蜘蛛文件的编写。第六步:Scrapy项目与Django项目的API连接。
(2)数据预处理
第一步:读取原始数据:本系统通过引入pandas包来读取并且操作数据。
第二步:变量编码。数据千奇百怪,有中文表示的,有英文表示的,还有数字表示的,为了方便计算机处理,统一处理成数字格式的。
第三步:缺失值处理。根据观察爬取的原始数据得出预期年化收益率这一特征的缺失率较为严重,必须经过缺失值处理。
(3)无监督学习-聚类分析
本系统选择的聚类分析算法为K-means算法[5],该算法对于给定的样本集,选定k个初识质心,迭代计算每个样本点距离最近的质心并且标记自己的所属的簇,直到质心不再发生变化。本系统将经过预处理的数据进行训练,按照想要聚成的簇数,将具有相似性的理财产品聚合在一起,在算法的实现方面,直接调用sklearn库所提供的方法即可实现聚类分析,代码如下所示:
km=KMeans(n_clusters=10).fit(X_scaled)
(4)信息聚合展示
理财产品聚合结果前台展示页面,该功能主要上将训练好的数据显示在前台,提供给用户。由于刚训练好的数据在数值上是经过预处理的,不能直接呈现给用户,所以需要定义一个类,完成前台和后台数据之间的转换匹配,使得用户能够得到所需要的、有意义的数据。
2.3 评价分析功能模块
该功能通过系统自动评价以及用户行为来综合评价聚合结果。
(1)系统自动评价
该功能通过轮廓系数来评价聚合结果。轮廓系数是用来评估K-means聚类算法好坏的,轮廓系数计算公式(1):
其中,a(i)为样本i到同簇其他样本的平均距离,b(i)为样本i到其他簇的所有样本的平均距离。s(i)越接近1,说明样本i聚类越合理。
本系统通过用户在信息聚合展示页面的页面点击操作来分析用户的行为。通过用户评价功能模块获取点击事件以此触发本功能模块。在此功能中,通过公式(2)计算每一个收藏组的总点击量,并且根据此数据进行收藏组与组之间的排序。在每个收藏组中,单个理财产品是根据单个理财产品的点击量的大小进行简单排序,计算公式(2):
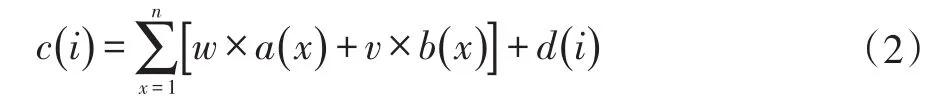
其中,c(i)为每一个收藏组的总点击量,n为每个收藏组中理财产品的总个数,a(x)为单个理财产品点击量,b(x)为单个理财产品收藏量,d(i)为用户点击第 i个“收藏组”按钮的总次数,w的取值为0.25,v的取值为0.3。将a(x)和b(x)的权重缩小的原因是存在某种情况,一个收藏组中的产品个数远远大于另一个收藏组中的产品个数,对于后一个收藏组是不公平的。所以为了排序的公平性,对于数值要加上适合的权重,将a(x)和 b(x)的重要度减少。w 取值为 0.25,v取值为0.3的原因是点击量和收藏量相比收藏量更能说明该理财产品的对用户的吸引程度。
(2)用户行为评价
该功能完成的是通过页面点击事件收集用户行为,传送给后端进一步分析。本系统对于以下具体事件进行记录分析:
第一,用户点击“了解更多”按钮,说明用户对于该产品抱有一定的兴趣,想去了解关于该理财产品的更多信息,甚至是想要去购买该理财产品。
第二,用户点击“收藏组”按钮,说明了两点。其一,说明了用户对于这一组的理财产品都有兴趣,这一组理财产品的种类对于用户更具有吸引力。其二,说明了这一组的理财产品聚合的效果比较好,同类相聚的较多,令用户比较满意。
第三,用户点击“收藏”按钮,说明了用户已经了解过或者想要去了解该理财产品,他将之收藏于个人收藏处,处于观望、比较、选择状态。展现出了对于该理财产品的兴趣,极有可能产生下一步的购买操作。
3 结语
本系统运用了机器学习算法实现聚合的效果,将理财产品信息聚合展示给用户,提供用户挑选,总的来说给用户带来了便捷。但是本系统还有很大的扩展空间,后期可以完成更多银行理财产品信息的爬取,并且可以根据用户行为个性化推荐相应的理财产品,这将更加靠近国外理财公司提供的智能投顾服务。
