COUNTER 5:关键变化及应用展望*
2020-01-09都平平江艳霞
陈 越,都平平,江艳霞
0 引言
COUNTER(Counting Online Usage of NeTworked Electronic Resources)意为联网电子资源在线使用情况统计。COUNTER Online Metrics是由图书馆、出版商和数据库商组成的非盈利标准化组织,负责通过成员间协作制定并维护COUNTER 实施规范[1]。这一规范可帮助出版商和数据库商向图书馆提供一致、可靠和可比较的使用数据[2]。2012 年4 月发布的COUNTER 实施规范第 4 版(以下简称“R4 版规范”)是目前广泛使用的版本。近年来随着线电子资源类型的扩展及资源发现与访问技术的变化,R4版规范在实践中逐渐凸显出一些问题,主要包括:
(1)使用报告数量持续增长加重了报告提供方和图书馆的统计负担。为尽可能覆盖各类资源使用统计,报告数量从规范制定之初的7个增加至R4版的27个[3]。一些过于关注特定需求的单一用途报告如移动版报告很少被使用,在增加统计工作量的同时并未发挥相应的作用[4]。
(2)因数据存在差异,部分以不同格式提供的报告无法直接比较[4]。比如R4版规范期刊报告1,表格报告中将PDF 和HTML 每月访问量合并计数[5],而XML报告则按月对两者分别统计[6]。
(3)部分定义模糊,理解和遵守容易产生分歧。比如对电子书“节段”的定义,不同资源提供商的解释和应用存在差别,对比他们提供的电子书借阅报告BR1(整本)、BR2(节段)数据可能引发困惑[7]。此外,答疑材料、帮助手册和实施文档的分散编写过程以及对规范及支持材料的不同理解,也导致不同报告提供者的具体实践存在一定差异[4]。由COUNTER Online Metrics 发起的调查显示,在下一代规范中澄清现有规范中的歧义是用户最关心的问题之一[8]。
基于广泛调研与多方协作,2017 年7 月COUNTER Online Metrics发布了下一代COUNTER 实施规范(即R5 版规范,以下简称“新规范”)。本文解读新规范的主要变化,并结合新规范的特性,讨论其创新应用场景,以期为电子资源管理及相关研究开发提供参考。
1 COUNTER 5的关键变化
面对复杂多变的信息资源环境与用户需求,新规范不是对R4版规范的简单修改或扩充,而是在规范体系结构、用户使用报告、数据供给与操作模式、实施与维护等方面进行彻底重构。这些改变使新规范简单、灵活、一致、可持续,从而具备更广阔的应用空间。
1.1 清晰的体系结构
新规范通过增加关键章节、取消重复或无意义的内容、重组相关主题等修订措施,优化规范结构,提高规范的可读性,更便于各方理解实施,详见表1至表3。

表1 新规范增加章节

表2 新规范取消章节
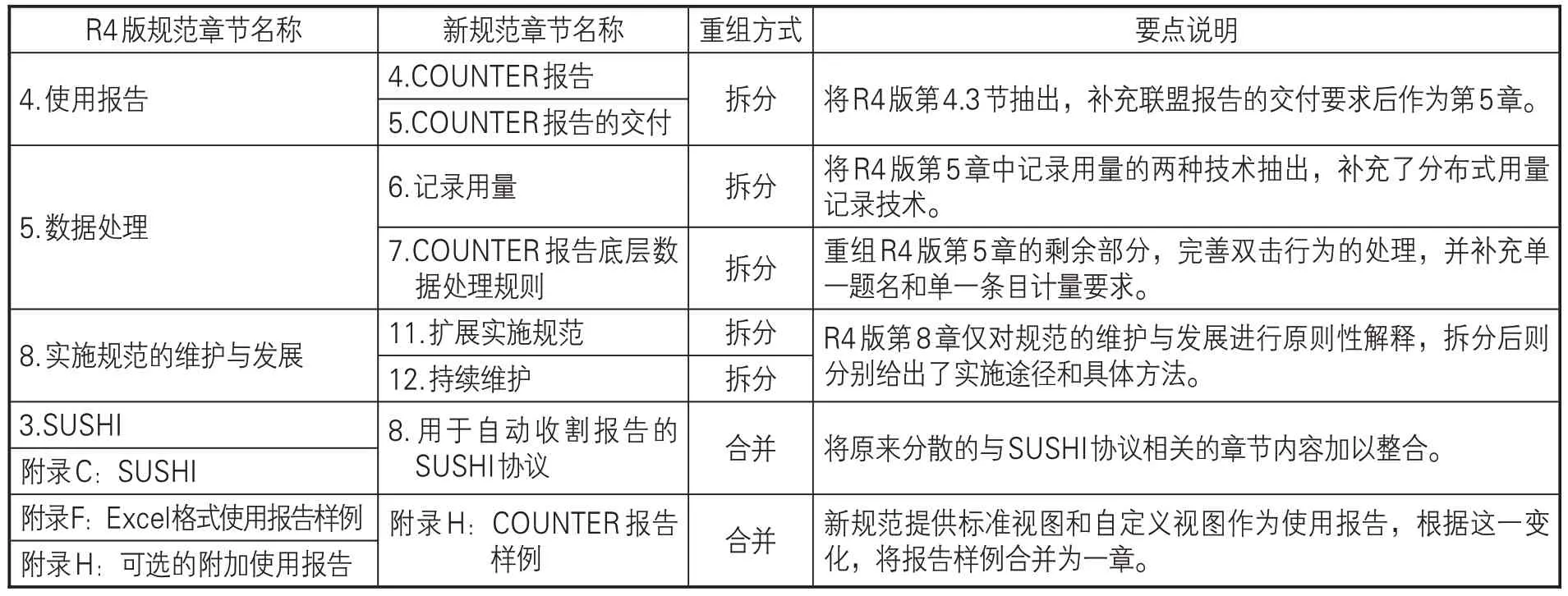
表3 新规范重组章节
1.2 灵活的使用报告模型
为解决R4版规范使用报告过多、部分报告利用率低下的问题,新规范重新设计了使用报告模型,扩充了使用报告要素,包括:(1)引入主报告(Master Report)及视图(View)概念,重新划分报告体系;(2)新增报告属性,用于统计更详细的用户行为信息。
1.2.1 主报告及视图
主报告是内容提供商在电子资源主机上采集使用数据后形成的基础数据表。新规范将电子资源主机分为电子期刊、电子书、全文集成数据库等11种主机类型(Host Type),不同类型主机采集的资源使用行为数据有所差异,据此生成对应的主报告。根据提供主报告的主机类型,可将主报告分为平台(Platform)、数据库(Database)、题名(Title)、条目(Item)等四种。主机类型与所提供的主报告之间的关系如图1所示。
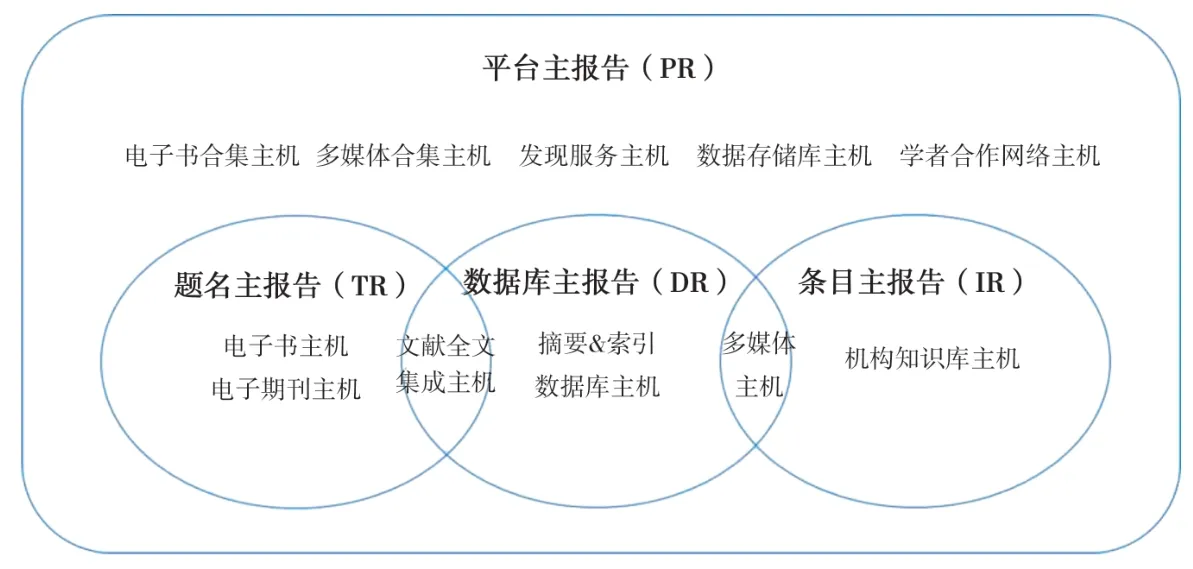
图1 主报告与主机类型
平台主报告汇总特定内容提供商的资源访问数据,所有电子资源主机均应设法收集相关数据并生成平台主报告。题名、数据库及条目主报告则由不同类型的主机生成。题名主报告统计用户访问电子书、电子期刊等资源主机的行为信息。数据库主报告统计用户访问摘要索引、文献集成等数据库主机的细节信息。条目在新规范中被定义为与资源内容有关的数据收集术语,可以是全文、全文摘要、HTML页面、补充数据集或非文本资源(图片、视频、音频等)[11]。机构知识库、多媒体资源主机收集并统计用户针对上述资源的访问信息,形成条目主报告。不同主报告面向的主机范围亦有交叉,某些类型的主机(如文献全文集成主机)需要同时提供平台主报告、题名主报告和数据库主报告。
新规范引入了关系数据库领域的视图概念,根据数据类型(Data Type)、获取类型(Access Type)等条件对主报告数据表进行过滤,生成视图并作为使用报告提供给图书馆。新规范预置了12 个标准视图,其与主报告的关系如图2所示。
新规范在引入主数据/视图模型的同时,同步建立了新规范视图与R4 版规范使用报告之间的映射机制,从而保持了统计工作的延续性,详见图3。
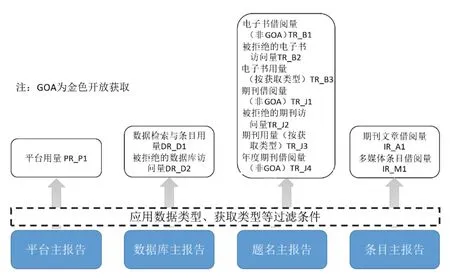
图2 从主报告生成预置标准视图
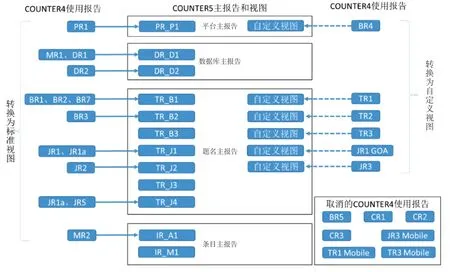
图3 新旧规范中报告的转换与取舍
R4 版规范中符合通用需求的报告在新规范中以标准视图形式提供,如平台使用量报告PR1、期刊使用量报告JR1,在新规范中转换为标准视图PR_P1、TR_J1。R4 版规范中为满足特定需求而定义的各类报告在新规范中采用自定义视图形式提供,包括:(1)在不同层次对同一行为进行的统计,如按平台归类的R4版被拒电子书访问量报告BR4;(2)对不同类型资源同一操作行为的统计,如R4版期刊/电子书章节全文借阅量报告TR1;(3)针对特定资源属性的统计,如R4版金色开放获取期刊全文使用量报告JR1 GOA。
新规范取消了因不符合技术发展或实践需要而较少使用的报告。例如,按月份和书名汇总显示用户常规/联邦/自动检索次数的报告BR5,初衷是比较用户在出版商平台访问电子书时所采用的各种检索方式[7],但由于大多数平台上的书名往往被包含在各类检索中,不同检索形式的区分度并不明显[12]。此外,即使平台在标题级别记录搜索和会话,由于用户通常很少执行此类搜索,导致这些报告中经常有零条目出现[13],因此新规范取消该报告。
1.2.2 新增报告属性
配合“主报告-视图”结构,新规范在使用报告中增加属性(Attributes)要素,对数据格式、访问行为等进行分类定义。属性可分为普通属性和特殊属性(即指标类型)。普通属性作为过滤条件,供用户从主报告中自行提取所需数据创建自定义视图;指标类型(Metric Type)则与统计值对应,用以标明统计量的含义。
(1)普通属性。普通属性定义了不同数据、不同格式、不同获取方式等资源独有特性的取值空间。图书馆可以据此对主报告数据进行过滤,以形成标准或自定义视图,新规范中普通属性见表4。

表4 新规范普通属性及取值空间
(2)指标类型。在R4版规范中,没有“指标类型”概念,只能通过不同报告展现不同资源的使用行为数据[7]。新规范引入指标类型这一特殊属性,以区分用户在线资源利用活动的总体性质,并将规范涉及的指标纳入不同指标类型,在一份报告中提供不同活动行为的统计数据。指标类型分为检索(Searches)、查看与借阅(Investigations and Requests)及被拒绝访问(Access Denied)等三组[15],见表5。
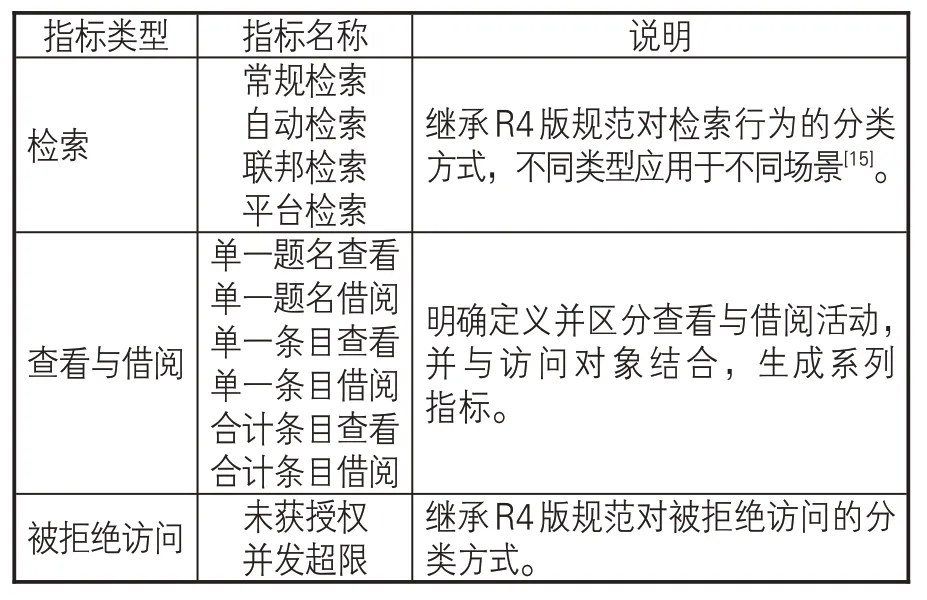
表5 新规范指标分类及说明
检索类指标和被拒绝访问类指标继承了R4版规范使用报告中的定义,其作用基本没发生变化。查看与借阅类指标则为规范新增指标,用于计量用户对单个题名和条目的访问活动,包含查看与借阅两种行为类型。用户围绕条目内容的所有活动(包括阅读和获取全文)都被当作查看,但借阅仅包括阅读或获取全文。图4解释了两种行为的联系与差异。
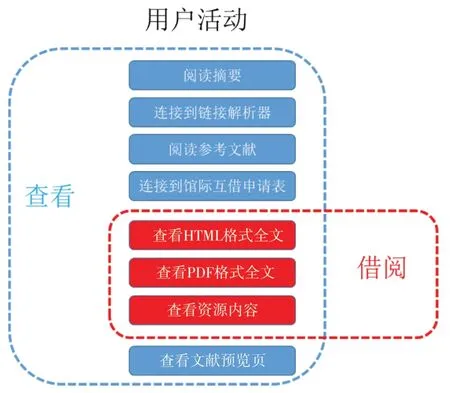
图4 查看和借阅的关系[15]
在区分查看与借阅两种用户活动的基础上,新规范进一步细化活动度量的统计粒度,将计量方式(单一/合计)、访问对象(题名/条目)与访问行为(查看/借阅)加以组合,形成了具体的查看与借阅活动度量指标,见图5。

图5 查看与借阅活动指标组合方式
单一题名前缀条件可以用于期刊和电子书。通过使用单一题名进行用量统计,在一个会话中,同一期刊/电子书无论是整体下载还是分节段下载,都只记为1次借阅,以此解决不同平台的用量比较问题。
单一条目前缀条件解决了用户接口效应带来的统计误差[16]。对同一篇文献,在同一个会话中,无论以HTML 方式查看全文还是通过下载PDF查看全文,只记为1次借阅。
合计前缀条件提供过滤重复点击后的累计查看统计。对同一用户会话,计量每一次对条目的查看与借阅,最后提供累计值。这里的条目包括文章、电子书节段、多媒体文件等。
1.3 一致的数据供给与操作模式
新规范在数据与操作两个方面强化了一致性。在数据方面,引入轻量级SUSHI协议作为传输模式,以SUSHI-Lite 中的JSON(JavaScript Object Notation)格式取代XML作为收割数据结构。同时提供RESTful风格的API接口[17],允许客户端在调用接口时附加过滤器与属性参数,获得与表格形式报告相同的数据,保证不同格式报告的数据一致性。在操作方面,新规范完整实现了R4版规范的关键功能,同时简化了图书馆员的日常操作。有研究者对比了典型用户使用场景及在两种规范下的不同操作(见表6),发现相对于旧版规范,新规范在不同场景下提供了基本一致的操作模式,更便于图书馆理解与实施。
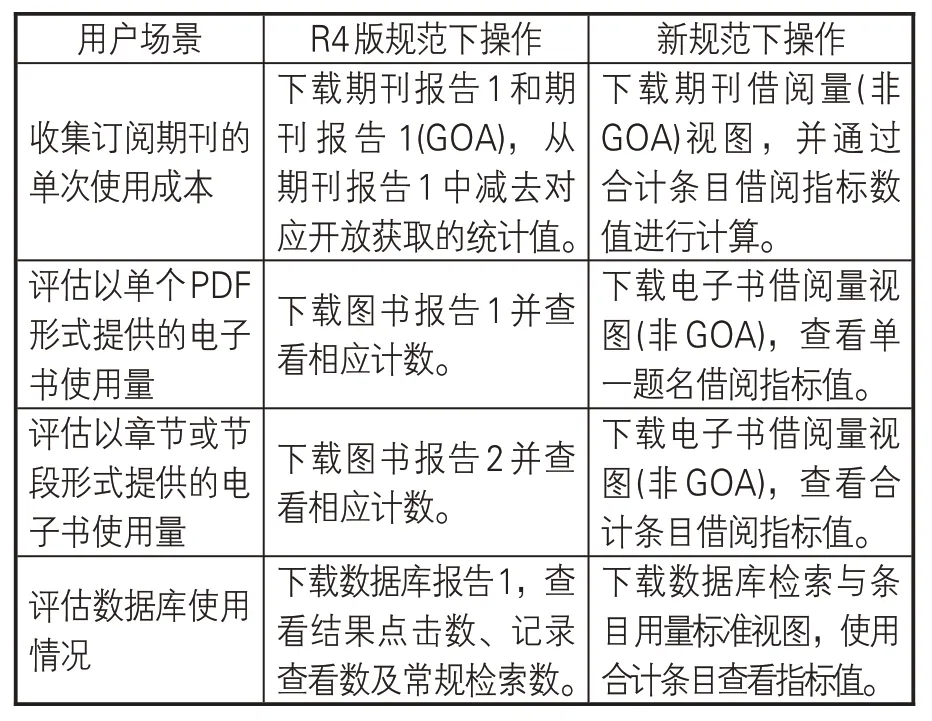
表6 新旧规范下典型用户使用场景的操作对比[16]
1.4 可持续的规范发展与维护机制
新规范在扩展与维护机制方面进行了创新。通过建立类似数字对象标识符(DOI)的命名空间机制,利用命名空间标识与报告名称、元素名称、度量类型名称以及枚举值的组合,支持参与各方对使用报告进行扩展,见表7。借鉴并导入SUSHI 标准中的持续维护过程(Continuous Maintenance Procedures)概念[18],明确关键环节的处理时限以及批准修订所需的程序要求,解决了规范修订间隔过长难以跟随用户需求变化[4]。改进后的规范修订流程见图6。
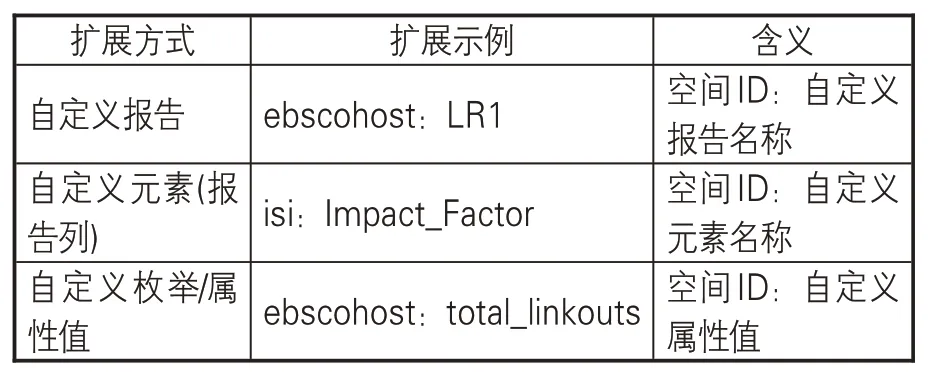
表7 报告扩展方式及示例
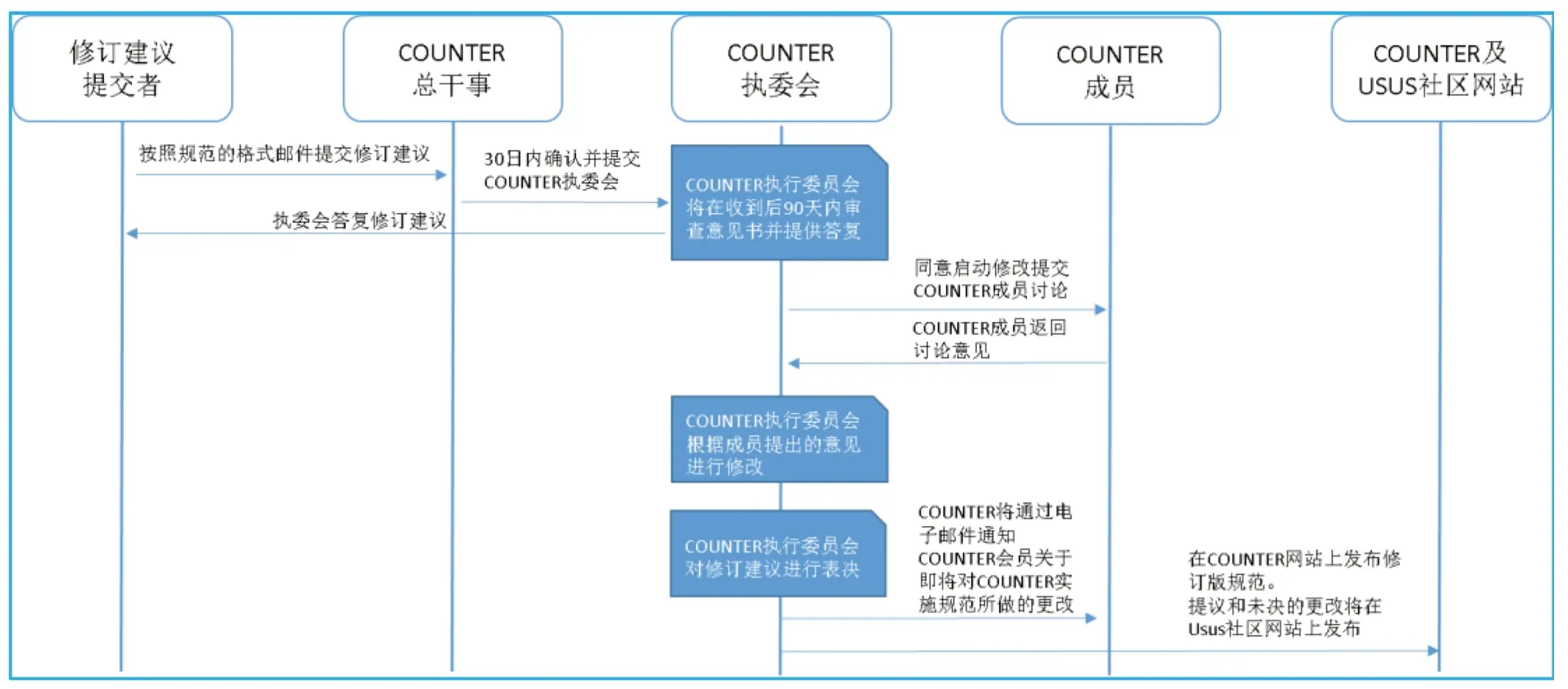
图6 规范修订流程时序图
2 COUNTER 5应用展望
2.1 支撑图书馆开展资源评估指标体系验证
图书馆对电子资源利用评估的要求日趋多样,一些研究者不满足于现有报告提供的固定指标,自行设计并研发出相关指标框架体系[19-20]。由于这些体系的研究性质,难以要求资源提供商将其纳入统计报告,从而限制了指标体系的落地与推广应用。新规范通过提供视图、元素、属性等自定义机制,可支撑研究者利用资源提供商平台开展研究性数据采集,以验证和完善个性化指标体系,也可加强图书馆与资源提供商在资源利用评估领域的互动,推动指标体系研究成果向实际应用转化。
2.2 深化用户电子资源利用行为分析
为加强资源管理、优化用户体验,需要对用户资源访问行为的特征、动机及模式进行考察与分析[21-23],尝试挖掘用户行为与资源易用性、服务可达性的关系。新规范将用户资源访问行为界定为“查看”与“借阅”,并结合资源对象类型、计量方式给出清晰的数字化指标体系,使资源提供商据此提供一致且详尽的用户访问行为数据。对细粒度行为数据的观察,可为图书馆提供问卷调查以外的研究途径;不同资源平台提供的标准一致数据,能够帮助研究者进行资源平台之间的比较分析。未来可结合用户资源访问的情境数据(如学科背景、学术身份、研究方向等)加以深入发掘,进一步多角度深化用户行为研究,推动图书馆持续优化和提升电子资源服务体验。
2.3 推动研究数据集等资源利用统计的标准化
研究数据已逐渐被认定为学术活动的重要产出。在基于出版物引用的评估机制之外,数据的使用(查看、下载等)计量也逐渐成为仅次于引用计量的数据影响力衡量方法[24-25],以推动研究数据的开放与重用。COUNTER 5已经提供了针对补充数据集、非文本资源的使用计量方法,并允许机构知识库主机、多媒体主机收集并提供对应数据。以此为基础,COUNTER Online Metrics 与由 NSF 资助的 Make Data Count 项目[26]团队合作,起草并发布了COUNTER Code of Practice for Research Data 规范第 1 版(以下简称COUNTER RD1)[27],为研究数据使用计量提供了可操作的标准。COUNTER RD1在使用报告、指标体系及操作方面与COUNTER 5保持一致,仅在必要之处根据研究数据的特性给出单独规定,如根据数据集版本对研究数据利用量进行聚合用量统计。COUNTER RD1的发布,意味着COUNTER框架有较好的包容能力,能够平衡通用功能与专有需求,具备推动其他领域资源利用统计标准化的潜力。
2.4 为本地化标准的制定与维护提供参照
在电子资源使用计量领域,我国也制定了相关标准,包括2007年教育部高等学校图书情报工作指导委员会修订的《高等学校图书馆数字资源计量指南》和2012年文化部发布的《图书馆数字资源统计规范》。在实践中,上述标准不同程度地显现了一些问题,主要有:(1)起草成员单位主要为行业主管机构及部分图书馆,缺少出版商、数据库商、一线图书馆员参与,由于资源类型繁杂,各方需求存在差异,解读与执行存在一定困难[28]。(2)“指南”及“规范”面向的对象仅为图书馆,并未明确约束数据库商执行,遵循我国标准的数据库商较少[29]。(3)没有明确规定修订过程,在实践中出现的新统计需求无法通过修订纳入标准。
COUNTER 5的发展与维护机制为我国电子资源利用统计标准的制定与维护提供了参照。一方面,标准的起草组织应包括产业链各方,除主管部门与行业协会外,还应充分涵盖公共、专业、高校等各类图书馆,以及主要出版商、资源提供商等利益相关机构,使标准的发展充分响应各方诉求,统筹参与各方权益。另一方面,应建立明确、公开、可持续的标准维护路径,给出参与各方乃至普通馆员提交标准修订建议的具体措施,如建立在线社群讨论落地与修订问题,及时公开修订建议的处理过程等。通过定期修订和更新标准,不断提高在实践应用中的影响力。
3 结语
COUNTER 5在报告模型、指标体系等方面的变革,体现出数据时代对图书馆资源提供与信息服务的全新要求。对资源与读者互动关系的观察与重估,将引导图书馆以更科学、有效的方法向读者提供预测、咨询、资源推荐等个性化服务。更重要的是,新规范所体现出的包容性及自我迭代更新能力,也为图书馆应对数据时代的挑战提供了启示和借鉴。
