高速公路站级联网收费数据挖掘应用
2020-01-09崔毓伟李隆杰
崔毓伟, 李隆杰
(中远海运科技股份有限公司,上海 200135)
0 引 言
随着我国高速公路省界站联网收费系统的撤销和自由流收费模式的推广,收费系统软件的业务逻辑发生变化,站级收费系统在流量统计和交通状态识别等方面变得更加准确、便捷。目前站级收费系统软件主要负责接收和执行上级管理中心下发的费率表及相关配置参数,按车道数据操作流程采集并上传车辆信息,控制和管理车道设备和人员,监测各类异常信息等[1]。此外,站级收费系统软件还具有基本的数据统计功能,实现交通量统计并生成图文报表,记录收费站通过的交通量和收费额等。目前该系统在数据智能分析处理方面的应用还较为匮乏[2],虽然积累有海量的流水数据,但在站级管理和服务方面没有产生与这些数据相匹配的价值。因此,本文从站级层面分析联网收费系统流水数据的特点及其价值,建立站级数据的多视角统计框架,将站级历史收费流水数据作为输入,提取宏观流量的时空分布特征、车辆使用频度特征和通行时间特征等参数,采用时间序列聚类算法观察日流量序列的变化规律,以在新一轮高速公路联网收费系统变革中增强数据统计方面的管控职能。
1 站级联网收费数据分析方法
随着大数据、云计算、移动互联网和人工智能等信息技术的不断发展,高速公路信息化已上升到智慧高速的阶段。张纪升等[3]认为“智慧高速”相比传统的“智能交通”更加强调平台性、互联性和终端化,其中融合多种交通数据来源的交通大数据分析技术是构成现阶段智慧高速公路技术体系的关键技术之一。当前各类监控收费系统设备已积累很多形式多样的数据,但这些数据并不直接表现为信息,数据本身是抽象的、冗余的,甚至是杂乱的。例如,收费流水字段的数量多达百余个,包含车辆属性及出入口信息、收费站运营情况和路段通行状态等信息。这些不显示规律的数据通过收费流水表达,需先将其处理为一系列有用的特征及不同特征间的关联关系,再利用统计学习模型将其提炼为可辅助决策的规律。因此,先由原始数据得到特征信息,再从中提炼出运行规律,即构成交通大数据分析的基本框架。
联网收费流水数据包含车辆驶入驶出高速公路的位置、时间和各类属性,是掌握收费站车辆通行情况和高速公路运行情况的重要基础数据。图1为联网收费流水数据挖掘分析框架。
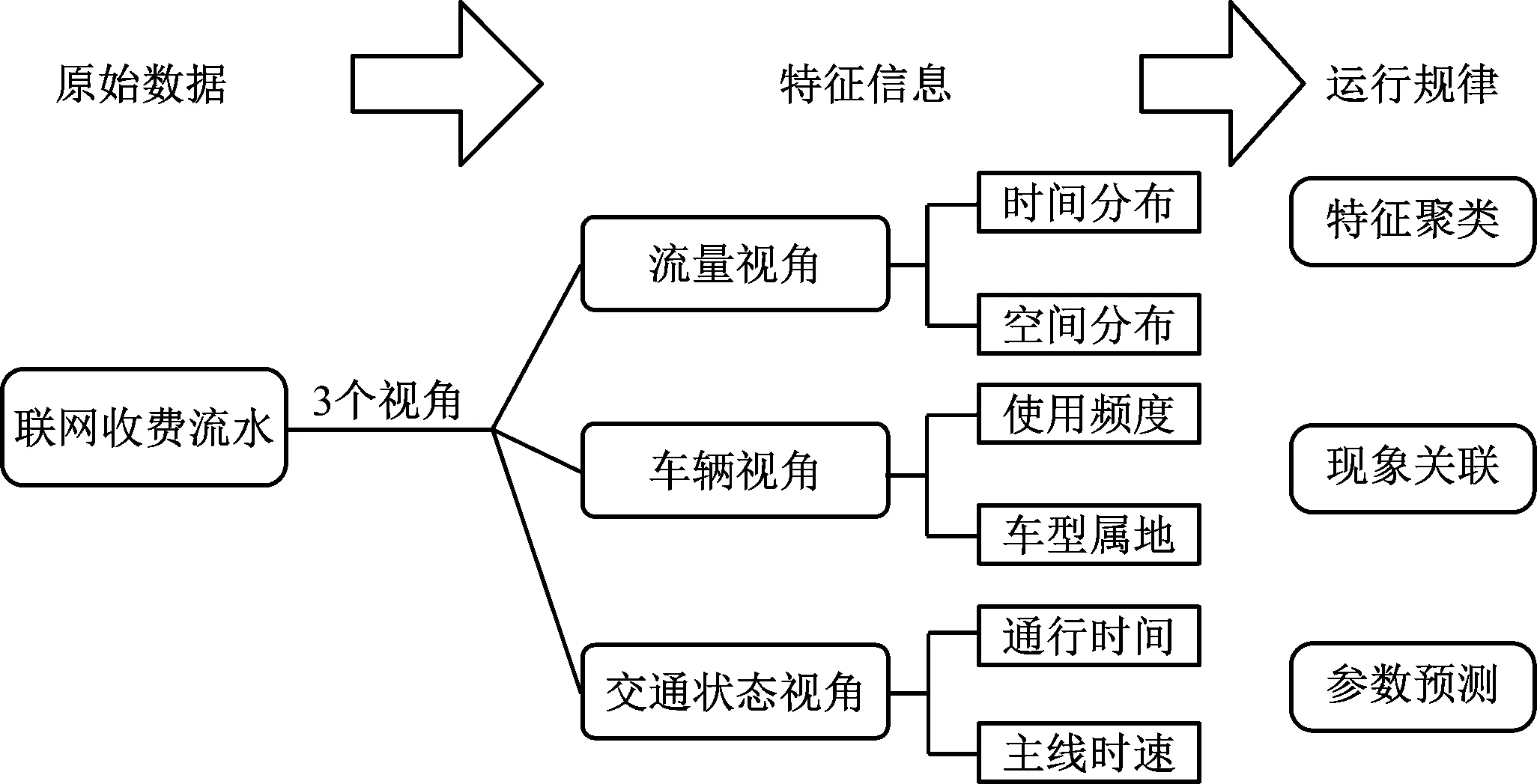
图1 联网收费流水数据挖掘分析框架
无论是封闭制式还是开放收费制式,均可将原始收费流水数据划分为流量、车辆和交通状态等3个视角下的特征信息,作为数据挖掘算法的输入,其中:流量视角是收费站的宏观视角,反映收费节点的整体通行能力;车辆视角是个体车辆的视角,反映个体的通行特征;交通状态视角是基于流水数据间接推断路网的交通状态信息。关联分析是指研究不同视角下特征参数的关联关系,如车辆的个体属性表现在宏观上的时空分布和交通状态与流量的关联及不同属性车辆在交通参数上的关联等。
本文的数据来自于广东省常虎高速公路某收费站2018年9月至11月的出口流水数据,共计531 099条,涉及广东省联网收费出口流水表中的字段,包括出入口流水记录号、出入口站编号、出入口时间戳和出入口车牌照等自由流模式下的收费节点同样具备的采集参数。
2 不同视角下的联网收费数据资源的特征
2.1 流量视角下的宏观分布特征
从收费站视角出发,将原始数据处理为流量在宏观上的时空分布特征。预测通行流量及其在时间和空间上的分布规律是分析区域物流、交通经济和公路设施养护的基础。将出入站流水记录号作为车辆驶入、驶出的标识,剔除出入流水记录号不完整的数据,得到收费站日通行流量在日期上的分布见图2。
除了国庆7天假期的日通行流量有明显减少以外,其余日通行流量均在5 000~7 000辆,其中:9月份日最高通行流量出现在9月27日,总计6 881辆;10月份日最高通行流量出现在10月19日,总计6 624辆;11月份最高通行流量出现在11月19日,总计6 779辆。将3个月的日通行流量进一步分解为小时上的分布,得到每小时的通行流量时间序列,从而观察日流量波动和峰值的出现规律。图3为收费站日小时流量时间序列散点图。
从图3中可看到:日小时通行流量在07:00—19:00波动明显,在23:00之后,每小时仅有百余量车通过;9月份日小时通行流量峰值出现在9月23日的10:00—11:00,共计581辆/h;10月份日小时通行流量峰值出现在10月31日的10:00—11:00,共计643辆/h;11月份日小时通行流量峰值出现在11月11日16:00—17:00,共计591辆/h。将上述波动明显的06:00—23:00日小时通行流量序列作为本文第3节时间序列聚类算法的输入,进一步分析日流量的波动规律。

a) 9月

b) 10月
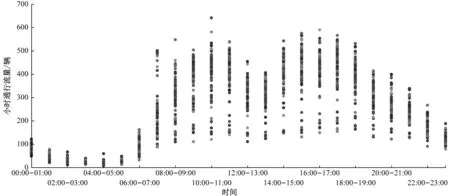
图3 收费站日小时流量时间序列散点图
流量视角下收费站在空间上的分布表现为所统计的车流量驶入收费站或驶入路段的来源,通过对流量来源的交通出行量(OD)进行划分,分析收费站所在区域的社会经济特征。本文所用的3个月出口收费流水来自于42个进口站,排名前五的驶入站占总记录的63.93%,排名前十的驶入站占总记录的84.16%,排名第一的驶入站占总记录的26.25%,由此可看出所研究收费站区域经济的主要辐射范围。图4为收费站车辆入口站分布情况,其中rank表示车辆来源数量的排序。
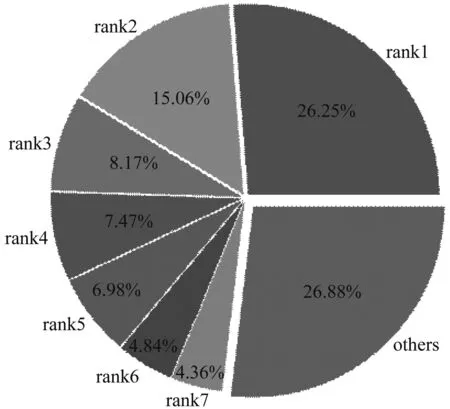
图4 收费站车辆入口站分布情况
2.2 车辆视角下的个体使用特征
从车辆个体的视角出发,从原始数据中得到车辆的个体属性和使用频度等特征。宏观上的流量数据是由具有不同属性的单个车辆组成的,不同车辆在车型、属地和通行频度等方面具有不同的特点。研究车辆个体属性特征是解读宏观规律、分析用户对不同服务模式的响应情况的基础,为推广自由流收费和移动支付提供依据。
分析车辆的使用频度特征要按车牌数据对出口收费流水数据进行重组,筛选原始数据中入口识别车牌与出口识别车牌一致的记录。车牌识别数据具有对个体连续追踪的能力[4],适合捕捉车辆的活动特征。本文选择所研究收费站11月份的出口流水记录,共计183 254条,去除识别错误和出口车牌与入口车牌不一致的数据,剩余174 620条,车牌判读识别准确率约为95.28%,其中:122 816辆从MTC(Manual Toll Collection)车道出口驶出;51 803辆从ETC(Electronic Toll Collection)车道出口驶出。识别出月通过次数超过1次的车辆占比为26.33%,95.00%的车辆月通过次数不超过6次。因此,多次通行车辆的月通行频度分布图呈现出明显的长尾特点(见图5)。
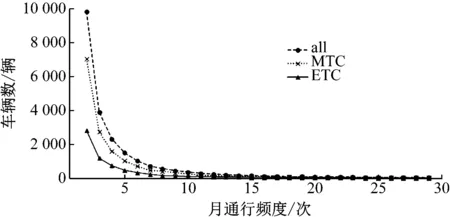
图5 多次通行车辆月通行频度分布图
由图5可知,当月通行频度超过5次时,使用MTC车道的车辆仍多于使用ETC车道的车辆,这是由于很多办理粤通卡的用户会因ETC设备出现故障或交通堵塞而选择从人工车道驶出。但是,从总体趋势来看,随着使用频度的上升,MTC用户数量减少的速度更快,经常使用高速公路的用户倾向于办理ETC业务。
2.3 交通状态视角下的参数特征
在交通状态视角下,将原始数据处理为交通状态参数特征。与流量视角和车辆视角不同,统计收费流水数据的主要目的不是统计交通状态信息,而是间接推断车辆从起点到终点的通行时间、行驶速度等主要参数,并将其作为专用交通调查采集数据的补充。根据收费流水记录的驶入时间和驶出时间,可计算车辆在高速公路上的通行时间。目前通行时间主要包括出站排队时间、主线和匝道通行时间,随着自由流开放收费制式的推广,由收费流水数据得到的通行时间即可等价估计主线行程时间和平均速度。本文选择与所研究收费站不存在多义性问题的起始站(编号为12),采用合理阈值区间的方法[5]剔除异常数据,得到出口站和入口站不同月份的日平均通行时间在不同时段的分布情况见图6。
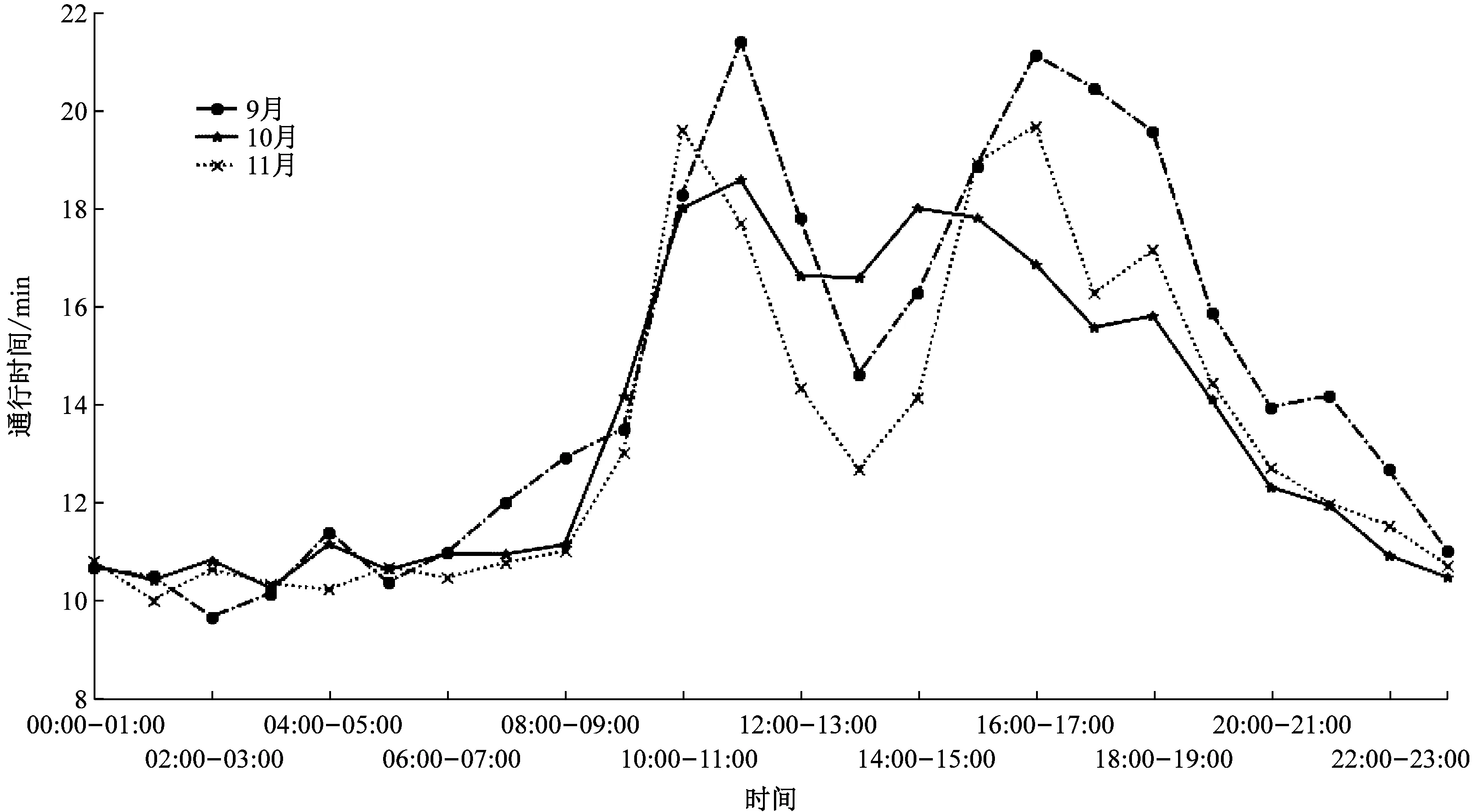
图6 不同时段出口站和入收费站口站日平均通行时间分布图
图6与图3呈现出相似的图形样式,即1 d内出现2次峰值,流量高峰时段的通行时间会变长,反映出了2种视角下特征参数的关联。以9月份为例,自由流状态下全程通行时间约为11 min,其中11:00—12:00通行时间达到一天的峰值,平均通行时间约为20 min。
3 流量视角下日小时流量时间序列聚类特征
特征提取和聚类分析在交通大数据度量体系建立中发挥着重要的基础支撑作用[4]。本文从流量、车辆和交通状态等3个视角提取了出口收费站联网收费数据的主要特征。根据这些特征参数,可采用统计学习模型挖掘、预测与收费站运营管理和用户服务相关的问题。3个月的历史流量分布特征显示,日通行总流量在一定范围内波动,日小时流量序列在相近的时间段内达到1 d的峰值。对日小时流量序列进行聚类,可发现流量变化情况与时间的关联及站日流量变化的不同模式。
k-means聚类算法通常采用欧式距离度量样本间的相似度,而在时间序列中,不同时刻的属性之间存在关联,相似属性可能在时间上超前或滞后,用欧式距离度量2个时间序列的相似性会有较大偏差。动态时间归整算法(Dynamic Time Warping,DTW)是一种利用动态规划寻找2条序列最优匹配的方法[6],在满足约束条件的情况下,通过对2条序列元素的对应关系进行一定的扭曲来计算2个序列之间的最小距离。采用基于DTW距离的聚类算法对收费站9—11月共88条有效的日小时流量时间序列进行分析,将轮廓系数作为聚类个数的选择依据,轮廓系数随聚类簇个数的变化情况见图7。
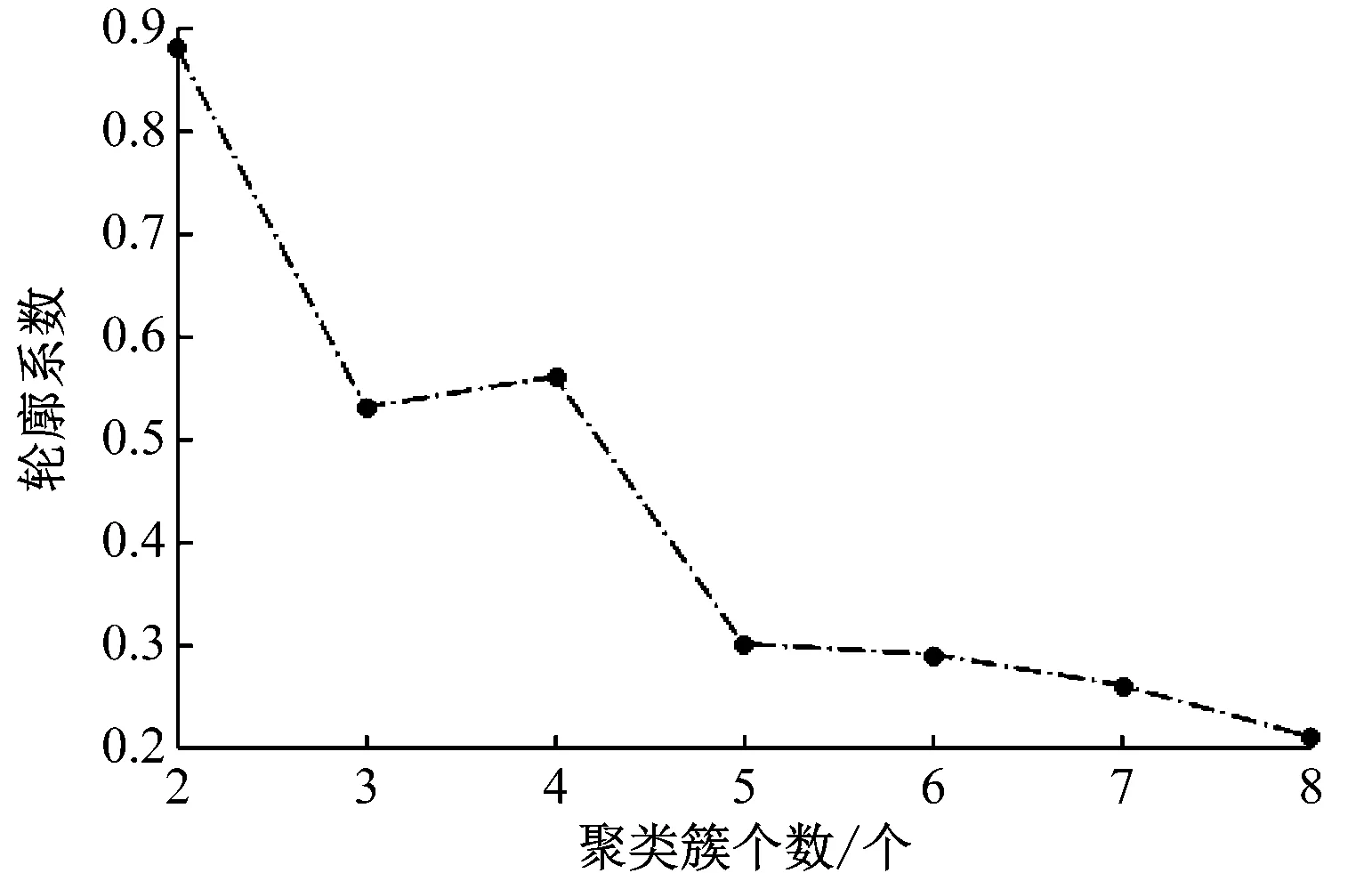
图7 轮廓系数随聚类簇个数的变化情况
轮廓系数值越大,对应的分类效果越好,同时需结合具体研究的问题和数据容量。若取2个类别,则数据被分为国庆7 d假期和非国庆7 d假期2个集合,表明7 d假期的日流量序列与平时显著不同,但考虑到假期的情况特殊,为体现平时日流量的规律,取2个以上的类别,结合轮廓系数,选择类别数为4。图8为4个类别的时间序列聚类中心线分布图,3个月的日通行流量时间序列被划分为4个类别。
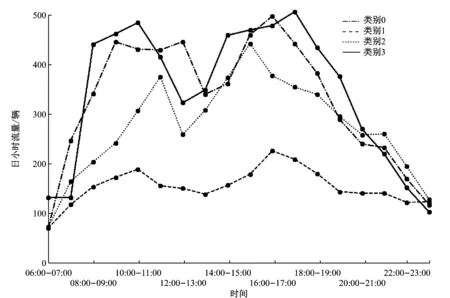
图8 4个类别时间序列聚类中心线分布图
国庆7 d假期被划为类别1,其日通行流量比平时显著减少,波峰变化不明显;类别2的日通行流量只高于国庆7 d假期,低于其他类别,具有双波峰特点,且划入类别2的流量序列有13 d,其中10 d为周日;类别3的日通行流量最高,波峰持续时间更长,且全部为周一;其余日期序列划入类别0。由此可看出,该收费站流量分布较为均匀,周六的通行流量与工作日差别不明显,但周日的通行流量明显少于工作日。一周流量的高峰通常出现在周一。
4 结 语
本文从流量、车辆和交通状态等3个视角提取了站级收费流水数据中包含的高速公路运行信息,分析了收费站流量的宏观分布特征、车辆的使用频度特征和交通状态特征等,并采用基于DTW距离的时间序列聚类方法分析了日通行流量序列的类别划分。本文所述方法和所得结论有助于评价高速公路运行情况,掌握车辆的社会经济属性,为推广自由流收费系统中的增强数据统计挖掘功能提供参考。
