面向冷启动用户偏好获取的自适应物品询问列表生成方法
2020-01-08赵海燕陈庆奎
汪 静,赵海燕,陈庆奎,曹 健
1(上海市现代光学系统重点实验室,光学仪器与系统教育部工程研究中心,上海理工大学光电信息与计算机工程学院,上海 200093)2(上海交通大学 计算机科学与技术系,上海 200030)
1 引 言
推荐系统可以为用户主动选择和推送他们可能感兴趣的信息.近年来,推荐系统引起了电子商务应用的普遍关注并得到了广泛应用.推荐系统利用用户已有的行为数据、项目和用户的特征来获取用户的兴趣模型,在预测活跃用户的兴趣时表现出了较高的准确性.然而,推荐技术在实际应用中遭受冷启动问题的阻碍,包括新用户冷启动和新项目冷启动问题.
冷启动是指系统中没有或没有足够的关于新用户或新项目的信息(评级、标签等),现有的推荐技术在新用户或新项目上的应用没有很好的效果.在基于内容的推荐技术中,利用项目的属性可以减轻项目冷启动问题带来的负面影响,并且这些项目信息也易于获取.相比较而言,用户冷启动更难以处理,因为需要新用户主动提供他的相关信息(如年龄,喜欢的风格等)或直接表达他对项目的感觉(如提供评分、提供标签等),但大多数用户厌烦于提供太多信息或评价太多项目[1].此外,推荐的准确性与用户的满意度也直接相关[2],新用户从首次使用推荐系统时,就开始评估系统,如果系统不能为用户提供可靠的建议,就可能使用户在系统学习并返回正确的建议之前离开.所以,新用户冷启动问题成为推荐系统中需要解决的首要问题.
用于缓解新用户冷启动的技术可以分为被动学习和主动学习.被动学习依靠评分的慢慢积累,因此学习新用户的偏好非常缓慢[3].主动学习允许系统与用户交互,有选择地挑选项目请求用户评分,或者创建个性化问卷,从而获取用户数据.现有的主动学习方法基于不确定性、熵等信息选择物品让用户提供反馈[3].然而由于用户的差异性,其适合的最佳策略是不一样的.
本文提出了一个解决用户冷启动问题的自适应列表生成的主动学习策略,通过用户提供的前一阶段的评分,采用训练出的分类器为用户选择生成下一阶段问卷内容的策略,从而对不同的用户呈现不同的问卷内容,最终使新用户跨过冷启动阶段.同时,本文中提出了采用优化算法来优化各个阶段问卷长度(物品数量),以获得最佳效果.
文章的后续内容安排如下:第二部分介绍相关的研究工作;第三部分描述算法思想;第四部分介绍具体的实验过程、对照试验以及实验结果分析;最后是文章的总结以及对未来工作方向的分析展望.
2 相关工作
2.1 生成询问列表的方法
研究者近年来提出了一些生成询问列表的方法.基于不确定采样的方法的主要思想选取那些评分差异较大的物品,即有争议性的物品,让用户提供评分;而variance策略会选择样本池中方差最高的物品呈献给用户;entropy策略选择熵值最高的物品询问用户评分.也有一些方法将几种方法进行集成,采用多个模型的综合意见来决定选取哪些物品.但是,这些方法都忽略了不同用户最适用的询问列表生成方法可能是不一样的.
2.2 考虑自适应调整的推荐方法
很多学者都认识到自适应推荐能够给系统带来更快更好的性能提升.文献[4]将老用户当作“假设的”新用户看待,将数据集划分成多个包含相似实例的子集,并在子集上构建决策树,依据决策树对新用户进行分类,并呈现不同的推荐物品.文献[5]提出的ADTS模型,在对系统中用户进行推荐时,建立用户之间的信任机制,随着获取到的评分数量不断增多,实时更新用户间的信任强度,动态调整用户看到的推荐内容.文献[6]的作者主张将推荐作为一个排名问题看待,提出将矩阵分解(MF)与AdaRank算法相结合对模型分多轮进行训练,对系统中用户设置权重,重点增加训练成绩较差的用户的权重,不断修正模型中的推荐组件.文献[7]根据时间因素建立自适应推荐,利用时间上下文感知的推荐系统关注评分的时间上下文,追踪用户的偏好演变,并相应地调整推荐建议.
以上研究从多个方面考虑对推荐模型进行调整,但是这些研究不是针对新用户的.
2.3 决策树
决策树是运用于分类以及回归的一种树结构.决策树自上而下建立,依据内部节点的不同取值建立分支,划分数据子集,并在子集上重复重复建立下层节点,最终生成完整树结构.本文中用决策树对用户进行分组,对于不同分组的用户运用不同的预测模型,实现询问列表的个性化.文献[8]提出FDT(Factorized Decision Trees)算法重新定义决策树的生成方式,并用MPS(Most Popular Sampling)方法加速决策树的生长.文献[9]用分类器依据用户对物品评分的高低将用户分为三组:喜欢、不喜欢和未知,并以组为单位对那些未评价过的物品进行评分预测.
2.4 遗传算法
遗传算法的基本思想是模拟自然界物种进化过程与求解极值问题的一种自适应全局优化搜索算法[10].遗传算法对种群中个体的基因进行编码,经过交叉、变异以及优胜劣汰的自然选择,最终留下最优个体,适用于解决复杂的非线性和多维空间寻优等实际问题,并已成功应用于自动控制、无线传感、药物开发等领域.
本文使用遗传算法自动地对不同阶段的列表长度进行优化,以找到最佳的列表长度设置.
3 算法描述
本文提出的算法会根据用户对上一列表的不同反馈(评分)决定用户下一列表的内容.询问列表具体层次的设计可以根据数据集特点以及应用情况进行扩展或缩减,但是当列表层次过多时会导致模型计算复杂,交互过程时间过长,用户体验差等,而列表层次过少时就无法呈现适合目标用户的物品,无法获取充分或有价值的信息,所以本文中算法以三阶段询问列表(阶段1,阶段2,阶段3)向用户展示物品并获取评分,但是本文的方法可以用于更多阶段.
为了便于形式化的表示,本文用到的符号标记如表1所示,符号之间的具体关系如图1所示.
表1 数学符号
Table 1 Math notation

符号意 义I,U分别代表物品集合、用户集合A,B,C分别表示不同的模型L表示询问列表k表示列表总长度ki表示第i个列表的长度T1阶段1构建的决策树T2阶段2构建的决策树T3阶段3构建的决策树S1表示阶段1的初始训练集S2·表示阶段2的初始训练集S3··表示阶段3的初始训练集
3.1 阶段1列表生成方法
在本文提出的方法中,要保证三点,一是每层的决策树都能够被成功构建,这就要求询问物品时要能收获足够多的反馈,不能冷门;二是由于实验方法逐级分组的特点,要求有足够多的用户能支持实验中的不断的划分;三是由于每个阶段都需要建立分类器,而逐级分组的特点又会加剧数据的稀疏性,所以要求用户集的筛选过程要尽量选用活跃用户或评分更多的用户.综上,实验中的第一个询问列表L1采用popularity作为选择策略.
首先,根据公式(1)计算物品的流行度,其中表示对该物品打分的用户集.
Popularity(i)=|U(i)|
(1)

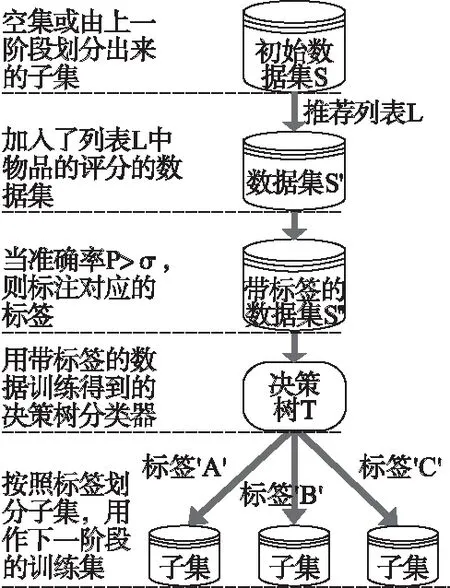
图1 算法过程图Fig.1 Algorithm process
(2)
Log(popularity)*Entropy策略是一个平衡策略,其在保证获取的评分数据量的同时,将物品的携带的信息量加入考量范围,log函数试图克服entropy与popularity间的分布差异对实验结果带来的影响.Entropy的计算公式见公式(3),式中,P(ri=r)表示评分r的概率,k表示用户可以给出的评分数,如在EachMovie中采取0到5分制,此时k=5,r从0开始.
(3)
(4)
本文使用准确率Precision来评估某一策略在目标用户上的运用效果,计算方法见公式(4),R(u)表示推荐系统给出的物品集合,T(u)表示测试集上用户u喜欢的物品集合.若Precision大于某一阈值σ时,即有理由相信该用户“适用于”该策略,并在数据集中对该用户标注该策略对应的标签,A模型对应′A′标签,B模型对应′B′标签,C模型对应′C′标签.接着用这些被程序标注过的记录构建决策树T1,决策树的构建可以参照文献[14],这边不再赘述.用构建好的对数据集中那些没有标注的记录进行分类标注,再根据标签分组,将数据集划分成三个数据子集,作为阶段2的训练集.
3.2 阶段2列表生成方法
第2阶段的生成方法有三个版本,具体版本的选择是根据用户对阶段1中物品的评分,分类器T1得出的类别.阶段1用流行度对用户进行大类别的划分,而阶段2开始对不同用户使用不同策略进行细化分组.由阶段1分好的三个子集,S11,S12以及S13分别作为三个版本的阶段2的初始训练集,并用不同的策略生成询问列表,其他的处理方法基本相同,所以在这里采用子集S11作为代表,阐述阶段2的思想.
子集S11用A模型选择k2个物品(S12用B模型选择物品,S13用C模型选择物品),生成询问列表L2,发起第二轮询问.获取用户对L2中物品的评分,形成新的数据集S21.再对S21中用户随机划分,并分别运用A、B、C模型,当准确率P>σ时,则对该用户进行标注.用带标签的数据构建决策树T2,并用T2对未标注用户进行标注.最后按照标签将S21划分成三个部分S111、S112、S113.
3.3 阶段3列表生成方法
阶段3是在阶段2的基础上对用户进行更细致的分组.阶段3要用策略选择出k3个物品作为L3,其他处理方式与阶段2基本相同.
4 列表长度的优化设置
上述阶段1、阶段2以及阶段3中都有一个重要参数:询问列表长度,即k1、k2、k3,也是影响实验结果好坏的决定性参数.设k=k1+k2+k3,在k值一定的情况下,(k1、k2、k3)有很多不同的组合,所以本文用带有约束条件的遗传算法对(k1、k2、k3)组合进行编码,具体的约束条件可以根据算法要求和实际问题设计.
将解空间中的所有(k1、k2、k3)组合视为一个个体,k1、k2、k3分别用n位基因表示,个体染色体共用3n位基因位表示,并随机生成种群(共m个个体),设置交叉因子λ、变异因子μ,对个体染色体上的任意位置进行变异或交叉.在自然选择阶段,考虑约束条件对个体的淘汰机制,若新生个体不满足约束则保留老个体;若新生个体满足约束则淘汰老个体,保留新个体,并设置种群迭代次数γ,此过程中始终保持种群规模不变,得到最终的新种群.最后对新种群中的个体染色体进行解码,前n位、中间n位以及最后n位分别转换为k1、k2、k3,得到m个(k1、k2、k3)组合.
由于本文试验中的k设置为30,所以种群中的个体用15位二进制编码,前5位代表k1值,中间5位代表k2值,最后5位代表k3值,并根据构建决策树的条件以及列表长度的考虑,对k1、k2、k3加以约束条件如公式(5)所示:
(5)
5 实验过程与结果分析
5.1 数据预处理
文中所提算法有逐级分类的特点要求有足够多的用户及评分,所以本文的实验采用美国DEC系统研究中心提供的EachMovie数据集1.该数据集有72916名用户,1628部不同的电影(电影和录像),总计2811983个评分,每条记录分别由用户编号(Person_ID),电影编号(Movie_ID),评分(Score),权重(Weight)以及时间戳(Modified)组成.EachMovie中的评分由0.0,0.2,0.4,0.6,0.8,1.0,共6个等级组成,为了方便计算,将评分统一转化成0-5分制,0.0分对应0分,1.0对应5分.此外,Weight字段的不同值有不同的意义,Weight=1时,表示用户对该电影的评分为0分;当Weight<1时,表示用户觉得该电影“听起来很糟糕”,虽然没看过但表示不会看,因此在处理数据集时,将Weight<1的记录中Score字段直接设置为0,与“用户对该电影评分为0分”的情况做相同处理.
实验过程中,以用户为单位划分训练集与测试集.通过对数据集稀疏度的计算,选用3000名评分数据最多的用户构成用户集U,剩余用户中抽取340名用户作为测试集,保证9:1的训练集与测试集.
5.2 算法过程
综合上一节对阶段1,阶段2、阶段3以及遗传算法的介绍,实验步骤详述如下:
1)用遗传算法得出(k1、k2、k3)组合.
2)第1阶段,根据流行度,选择k1个物品和用户集U中用户的评分作为训练集S.
3)对S中的用户随机运用任某一模型,计算准确率P,若P>σ,则对该用户标注对应模型的标签.
4)用带有标签的用户及其评分信息构建第一层决策树T1,并用T1对其他未标注的用户进行标注.
5)按照用户的标注分组,得到的多个数据子集即为下一阶段的训练样本集.阶段1内容结束.
6)用户进入2阶段,根据阶段1得到的数据子集,运用相应的模型(A、B或C)选择k2个物品,获取用户评分,扩充训练样本.
7)对训练样本中用户随机运用某一模型,计算准确率P,若P>σ,则对该用户标注.
8)用带有标签的数据构建第二层决策树T2,并对其他未标注数据进行标注.
9)按照标签分组,分成的数据子集将作为下个列表的训练样本集.阶段2内容结束.
10)用户进入阶段3阶段,用阶段2分出来的数据子集,运用相应的模型,选择k3个物品,获取评分,扩充样本.
11)随机运用模型,按照准确率进行标注,构造第三层决策树T3,并对未标注内容进行标注.
12)按照标注的标签分组,得到最终的用户群组,以便对新用户进行推荐.阶段3内容结束.
13)将L1中的物品向新用户u发起询问,根据新用户的回答,用T1决定该用户适合于阶段2的某一模型,再向新用户询问L2中的物品,用T2决定该用户适合阶段3的某一模型,最后向新用户询问L3中的物品,用T3得到该用户的类群W.
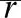
15)或者,根据W中不同用户对目标用户的影响大小对评分加权,预测出加权评分r′作为该用户u的预测评分,计算RMSE.
5.3 对照试验
本实验采用两个对照实验:基于决策树的方法D-Tree以及基于流行度的方法Popu.
对照实验D-Tree针对本文所提出的算法中会根据用户对列表的不同反馈,选用不同的模型的特点而设计,D-Tree实验会从物品列表中随机选出L1,用用户集对L1中物品的评分构成训练集,并对训练集中的用户随机分类,构建出决策树T;再随机选择物品生成L2,用新加入的评分数据再训练T;按照同样的方式生成L3,训练出成熟的决策树T.新用户u分别给出L1,L2以及L3中的物品评分,用T决定新用户u的最终类别组U,再借助U中其他用户的评分信息对该用户做出推荐预测.对照实验Popu是针对算法中多个询问列表相互关联,后一个列表的具体内容依据用户对前一个列表的反馈不同进行动态调整而设计的,Popu实验按照物品流行度,一次性给出三个列表的全部内容,没有分级询问和用户分类的设置,最后根据协同过滤的方式对新用户做出推荐.
5.4 实验结果分析
实验中,列表呈现的物品长度组合(k1、k2、k3)对实验结果的好坏起决定性影响,故接下来着重对这三个参数的不同组合下的RMSE进行讨论分析(以下所有图例中ADL(Adaptive Dynamic List)表示自适应动态列表策略结果,D-Tree表决策树策略的结果,Popu表示流行度策略的结果,其中Popu策略并无k1、k2、k3参数,在图中仅作参考对照效果).
1)k1=10不变,k2递增,k3递减
图2中纵坐标表示RMSE值,横坐标表示(k2,k3)的组合.在k1=10,k2+k3=20的前提下,ADL的实验效果最优,Popu的实验效果最差,并且不论是ADL还是对照试验D-Tree,RMSE值的总体波动不大,表明RMSE值的变动与k1和k2+k3相关.因为实验的第一次分类是划分粗粒度的大类别,而第二、三次划分类别是细粒度的划分,划分出的类别之间差异性相对较小,所以从实验结果也体现出k2、k3单独作用于RMSE的影响较小,该结论在后面的实验结果中也将体现.图2(a)和图2(b)相比较,加权评分的预测精确度比平均评分的预测精确度更高.

图2 不同(k2,k3)组合下不同算法的RMSE的比较Fig.2 Comparisons of RMSE between different algorithms with different (k2,k3)
2)k2=10不变,k1递增,k3递减
图3中纵坐标表示RMSE值,横坐标表示(k1,k3)的组合.在k2不变的前提下,当k1>4时,RMSE随着k1的增大而

图3 不同(k1,k3)组合下不同算法的RMSE的比较Fig.3 Comparisons of RMSE between different algorithms with different (k1,k3)
增大,随着k3的减小而减小,实验结果在(4,10,16)处取得最优.当k1<4时,由于物品数目过少,构建出的决策树不成熟,分类准确度较低,导致实验误差较大.
3)k3=10不变,k1递增,k2递减
图4中纵坐标表示RMSE值,横坐标表示(k1,k2)的组合.在k3不变的情况下,RMSE随着k1的增大而增大,随k2的减小而减小,ADL在(4,16,10)组合处取到最小值,D-Tree在(5,15,10)组合处取到最小值.结合图2可以看出,RMSE随着k1的减小而减小,因为阶段1呈现的是根据流行度策略选择的物品,这些物品过于流行,对用户的正确分类不具有太大的价值,所以列表长度在一定范围内是越小越好.
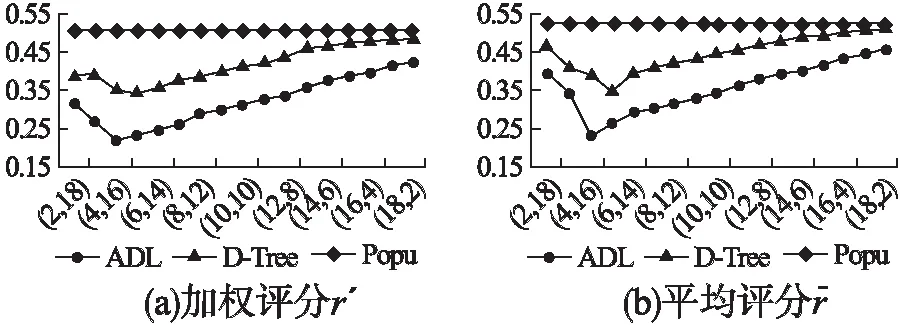
图4 不同(k1,k2)组合下不同算法的RMSE的比较Fig.4 Comparisons of RMSE between different algorithms with different (k1,k2)
4)遗传算法寻优

图5 遗传算法寻优Fig.5 Genetic algorithm optimization
设置交叉因子λ=0.1,变异因子μ=0.05.遗传算法寻优的实验效果如图5所示,横坐标表示种群迭代次数γ,纵坐标表示实验结果的平均RMSE和最优RMSE.由图可见种群在迭代次数γ=6次左右就开始收敛,实验的误差达到最小,并趋于稳定.
综上所述,各个策略对应的最优RMSE如表2所示,其中ADL策略的结果是在k1=4,k2+k3=26,λ=0.1,μ=0.05,γ=6,σ=0.8的参数组合下得到的.
表2 各个策略对应的RMSE值
Table 2 RMSE of different strategies

RMSEADLD-TreePopu加权评分r'0.22190.34250.505平均评分r0.23660.34360.524
6 总 结
本文提出的针对用户冷启动的自适应动态列表生成的策略,将要询问的物品分批次呈现给用户,并根据用户的回答动态调整列表的内容,使得获取的数据更能体现用户的兴趣,也避开了问卷决策树的弊端.主动学习中,询问列表的内容很大程度上决定了策略的优劣,ADL算法模型在面临新用户时也能很好的拟合出用户的偏好.实验的最终结果也表明,通过分层级向用户询问物品评分并找到新用户的群组,能够在新用户进入系统的最初就能有不错的推荐准确率,提高新用户对系统的忠诚度.
本算法虽然取得了一定的效果,但仍有许多值得深入研究的地方.例如,在构造决策树时,中间节点都是由物品构建的,后面也可以考虑将某些数据特征(平均值、中位数、流行度等)也加入中间节点中,并且还可以将时间因素考虑进来,对不同时间阶段的用户可以有不断更新的物品集合,提高预测准确率,这些都是后续预备研究的方向.
