面向大数据的北京水务数据融合技术研究
2020-01-07高凯丽张小娟
唐 锚 ,高凯丽 ,张小娟
(1. 北京市水务信息管理中心,北京 100038;2. 北京工业大学,北京 100124)
0 引言
随着水利信息化的高速发展,北京市水务系统面对小时间和大空间尺度及多种数据类型的海量数据资源信息,为北京水务的发展与数据资源的应用提供了机遇[1]。水利信息化通过数字化技术和设备采集各种水利基础数据;利用数据库、数据仓库等技术储备和组织数据,利用决策支持和地理信息系统、数据挖掘和人工智能等技术对数据进行处理和发布。然而在社会信息化加速发展过程中,由于信息系统、数据库之间各不相同,关联度不高,造成数据难以共享,数据融合贯通困难,无法实现业务之间相互协作,系统效率低下,无法真正实现信息化[2-3]。就水利信息化方面,信息系统建设的复杂性,会产生信息孤岛。长时间信息孤岛会产生许多冗余和垃圾数据,不能保证数据的一致,降低信息的利用率。
针对北京水务数据资源所面临的信息孤岛问题,使用数据资源融合技术,目的是使大量多源异构数据变成一个有机的整体,方便进行信息共享和业务处理。目前在北京市水务局中心已经建立了 1 个综合数据库、6 个业务应用体系、3 个保障环境,并在 10 a 的系统运行期间积累了海量数据,包括结构化、半结构化及非结构化数据,因此对数据的分析和整合具有迫切需求。
大数据时代信息大量涌现,表示多样、数量巨大、关系复杂,以及对信息处理所需的及时性、准确性及可靠性,这些使得计算机需要协同利用多源信息,获得对同一事物更加全面的信息甚至是知识。在信息网络的系统中,原始采集的信息一般都是无序的、分散的,甚至有错误的,只有经过一定的信息处理分析,将大量的信息进行融合,才能得到有用、相互关联、可方便使用的信息[4]。
数据融合指组合来自不同或者同种多传感器的数据和相关信息,获得质量更高的或从单一传感器无法得到的信息。一开始概念产生于美国 20 世纪70 年代,多应用于军事中的情报搜集,Glinton 等[5]尝试通过感知活动和地形的相关数据融合预测敌人接下来的行动,后来应用于美国军事作战,Lee 和Llinas[6]结合概率模型判断对方攻击的意图。随着数据融合的应用领域扩大及技术的发展,数据融合已涉及很多领域。
数据融合系统在电子政务、城市交通、智慧水务等领域都有一定的发展,吕智涵等[7]利用 GIS 和云计算技术整合多源数据,实现了集成软件、硬件和应用程序的优势,针对不同行业需求的前端定制功能,构建了政务智慧城市服务平台。李瑞敏、陆化普、史其信[8]提出综合交通信息平台的分布式体系结构,包含数据融合、压缩、仓库及挖掘等,实现交通运输系统的有效集成和服务的优越性。黄珂萍、蒋昌俊[9]通过建立城市交通本体,解决城市交通在语义层次上信息共享和交互的问题,为上海交通服务提供语义支撑。
目前根据数据融合在水务中的应用,许多学者已经相继开展了类似的研究。西安理工大学的罗军刚[10]面对当前水务信息应用问题,提出实现共享资源、整合应用的几个办法,具体阐述如下:1)在水信息的集成应用过程中,理解需求,通过知识图,实现数据、信息及知识可视化;2)把水信息相关的方法与模型组件化;3)按照主题提供信息服务,按照需要提供计算服务,按照个性化组织应用提供决策服务。姜仁贵等[11]面对在水利防汛中雨水情应用中存在的多源数据集成困难、应用现状单一等问题,采用组件式的方法进行软件开发、框架及三维仿真等,设计和开发了基于水利防汛的组件式雨水情应用集成平台,在多源数据集成的基础上实现在渝水区的应用集成。娄渊清等[12]提出了基于 Web服务的水利领域应用集成框架,解决了开发在不同平台上的 Web 服务应用之间相互操作困难的问题和各种遗产系统转化为 Web 服务的问题,使得不同应用系统之间的整合更加简易、方便使用及更具动态可扩展性。吴苏琴等[13]针对水利行业当前的特点,构建了由数据集成中间件、应用开发框架平台、水利组件开发平台、水利信息门户等组成的管理决策支持中间件服务平台,加速了中间件技术在水利信息化应用领域的创新发展和跨越式进步。
在此研究基础上,提出一种面向大数据和云计算的北京水务数据资源融合技术框架,从北京市多种水务数据多源异构数据资源出发,提出了面向大数据和云计算技术整合水务多源数据的方法,主要通过研究结构化和非结构化数据的抽取、转换及存储技术对海量数据进行有效融合,最终达到水务多源异构数据的融合及存储,解决数据之间分散、关联性不明显的问题。
1 技术背景及数据资源概况
1.1 大数据和云计算的背景
大数据指的是无法在一定时间之内运用常规软件工具对内容进行抽取、管理及处理的大量数据集合[2]。大数据主要有 4 个基本的特征:1)数据容量大,一般能够达到 TB,PB 甚至 EB 的级别;2)数据类型多元化,具有结构化数据如表格,半结构化数据如 xml 格式的数据,非结构化数据如文本、图谱、视屏等格式的数据;3)数据资源的可靠性及价值性较低;4)数据的处理时间紧迫。大数据技术需要针对海量数据进行数据的处理、分析及挖掘,最终被有效应用。在云计算的技术背景下,大数据可以在企业中实现价值,能够为企业提供决策支持。
云计算主要通过互联网对共享资源池提供便捷的访问,用户能够根据自身的需求,在任意的时间和地点内通过计算的设施及存储的设备等开展计算[14]。云计算具有强大的大数据处理和计算能力,在数据日益增加的背景下,大数据分析离不开云计算技术。云计算可以深入挖掘大数据,使得大数据处理和分析更具有全面性,能够实现大数据的分布式计算与存储,简化数据的处理流程,实现数据信息高效整合应用。
如图1 所示,云计算具备强大的大数据处理和计算能力,当前大数据与日俱增,大数据的分析离不开云计算技术的支撑,大数据可以进行分布式数据挖掘,云计算可以在大数据基础上进行数据的分布式处理,构建分布式数据库,实现云存储及虚拟化[7]。将在此大数据和云计算的背景下进行北京水务数据资源的融合。

图1 大数据与云计算关系图
1.2 北京水务数据资源概况
1.2.1 结构化数据对象分类
北京市水务数据资源中的结构化数据是按照基于对象的数据分类组织和存储的。水务对象分类主要分为自然类和非自然类两大类,如图2 所示。
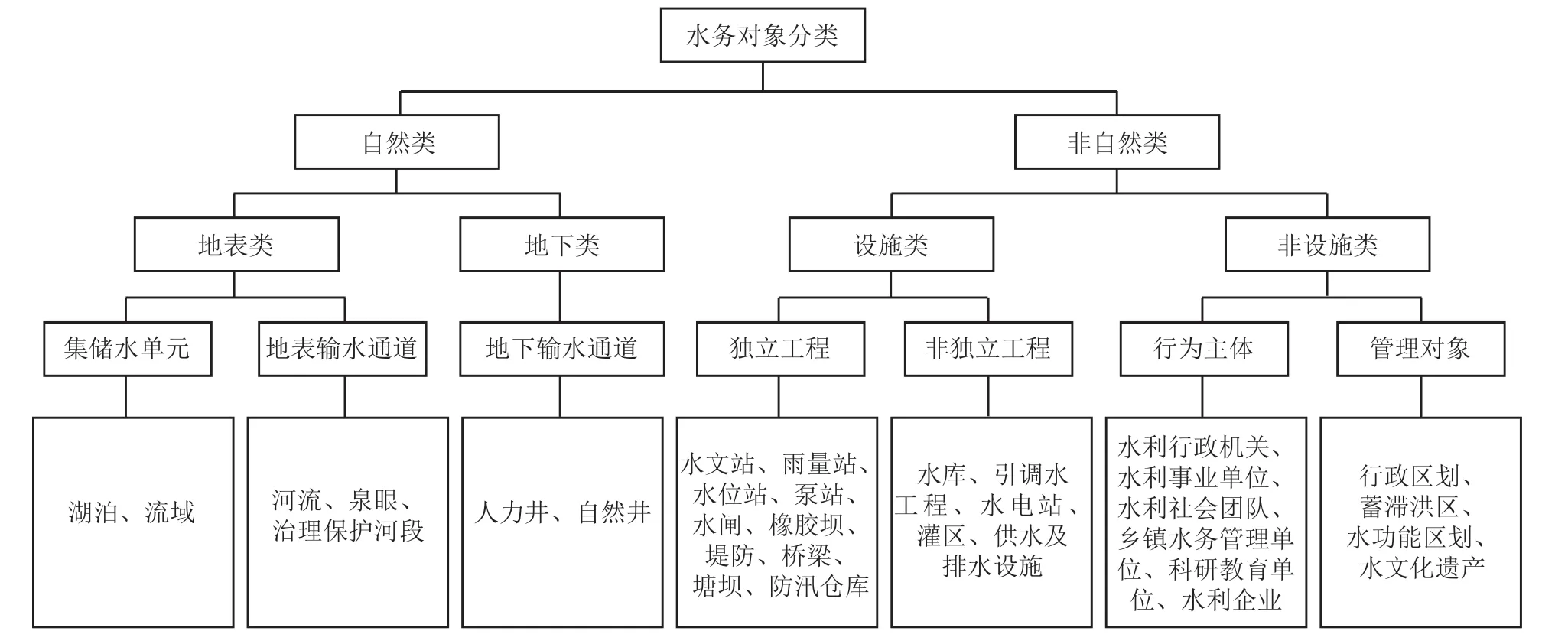
图2 水务对象分类
1.2.2 多源异构数据类型分类
水务信息化经过多年建设,积累了大量生产数据和内部的业务数据,但缺乏对数据的整合利用,使得数据价值没有得到充分的挖掘,无法为水务业务管理提供决策性的支撑。虽然通过自动化系统建设解决了工程自动化操控问题,但仍不能通过精准的预测和分析,达到智慧化管理和决策的目的。目前北京市水务局内部有多种类型不同来源的数据,针对于结构化数据有前置机、交换库、综合库的数据,这些数据部署分布在不同的服务器上,数据之间依次传输;还有存储水务基础信息的结构化数据,包含行政区数据、水务对象数据及元数据表结构等信息,每个数据库所包含的数据库表达到了上千张,数据量达到了 TB 级别。针对于半结构化数据包含水务相关的 xml,owl,rdf(资源描述框架)等格式的数据和百度百科相关水务数据。针对于非结构化数据有图像、监测视频、GIS 地图及文本等数据,由于非结构化数据更具有多源性,处理过程极其复杂,所以主要针对非结构化数据只涉及水务相关文本数据的整合处理,包含北京市水务局内部的数据库说明、水务信息标准、水务局官网上的日志及其它网站上的水务相关文本。北京水务数据资源分类如图3 所示。
2 总体技术架构设计

图3 北京水务数据资源分类
基于上述的论述背景,提出了面向大数据和云计算的北京水务数据资源融合技术架构。该架构采用 RDF 作为多源异构数据转换的格式标准,RDF 是一种用于表达关于万维网上资源信息的语言,它专门用于表达关于 Web 资源的元数据,比如 Web 页面上的标题、作者、修改时间、Web 文档的版权和许可信息、某个被共享资源的可用计划表等。然而,将“Web 资源”概念一般化后,RDF 可被用于表达任何可在 Web 上被标识的事物的信息,即使有时候它们不能够被直接从 Web 上获取。比如关于一个在线购物机构的某项产品信息(例如关于规格、价格和可用性信息),或者是关于一个 Web 用户在信息传送方面的偏好的描述。RDF 定义了一个简单的模型,通过制定的性质和相应的值描述资源之间的关系,可以表示一个实体关系图。RDF 使用 Web标识符(URIs)来标识事物,用简单的特征、性质、关系这些属性及属性值描述资源。这使得 RDF可以将一个或者多个关于资源的简单陈述表示为一个由结点和弧组成的图,其中的结点和弧代表资源、属性及属性值。RDF 由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系及实体和属性的关系。同时采用 Web Service 设计多源异构数据的接口和存储平台,该架构主要目标是解决以下 3 个问题:
1)对于不同类型的数据不能高效快速地集成。
2)数据形式多样,不同类型数据之间的关联性不明显。
3)海量数据存储负荷大,数据库扩展困难。
构建的数据资源融合架构主要包含以下 3 个层次:
1)数据源层。主要包含北京水务数据资源分类中的结构化、半结构化及非结构化数据。
2)数据融合层。针对不同类型的数据运用相应的工具将数据分别抽取出来实现数据抽取,结构化数据采用 D2RQ 工具(将关系数据库中的内容转换成 RDF 三元组的工具转换步骤)抽取成 ttl 文本,非结构化数据利用 jieba 分词工具与 tf-idf(频率-逆文本频率)算法结合,连接 CN-dbpedia(中文通用百科知识图谱),抽取其中主要的词汇信息。以结构化数据对象分类标准,将非结构化数据归类到相应的类别中,实现结构化与非结构化数据的快速融合,将结构化与非结构化数据进行关联。接着分别将抽取的结构化及非机构化数据转换为 rdf 格式实现数据转换,以便于统一存储数据,最后采用基于云计算的分布式存储技术,可实现对海量数据的高效存储与管理,将转换的数据统一存储在数据库中。
3)应用层。针对于融合的水务数据资源,可以进行数据查询的应用,包括对结构化与非结构化数据的查询,实现最终多源异构数据的融合,融合的数据可用于应急指挥、防汛决策及内部管理等。
总体技术架构设计如图4 所示。
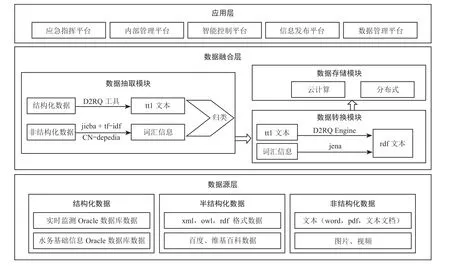
图4 总体技术架构设计
3 水务数据资源融合关键技术研究
数据融合技术是指应用计算机对按时序获得的若干观测信息数据,在一定准则下进行自动分析及整合,以完成所需的决策和评估任务而进行的信息处理技术[15]。数据融合主要有 2 种形式:1)将海量数据进行数据转换,实现对不同数据库的访问,如文献 [16]采用 XML 技术实现不同数据库之间的访问,最终实现数据的共享;2)将数据抽取成同一种格式,将其存储在同一个数据库中,如文献 [17]针对大量的结构化及非结构化数据的特点,提出一种海量数据的存储方式,以解决大量的电力数据存储及访问的难题。参考第 2 种数据融合的形式,基于大量多源异构的北京水务数据资源,在大数据和云计算的背景下进行数据的融合,主要分为 2 个步骤:数据抽取和转换。融合的数据主要包含北京市水务局内部的结构化数据库的数据及非结构化的文本数据,因此以这 2 类数据对象为基础,进行融合技术的研究。
3.1 数据抽取
数据抽取主要是运用一定的工具或技术,将不同来源和类型的数据抽取出来[18],是数据融合过程中的最基础环节。本研究在结构化数据抽取环节中,数据源主要是北京市的基础水信息和水资源实时监测的数据库。语义网技术的发展,对于结构化数据抽取也出现了许多开源软件,如 Drupal,D2RQ,Triplify 等系列工具,表1 是对这些工具的特点说明和比较。
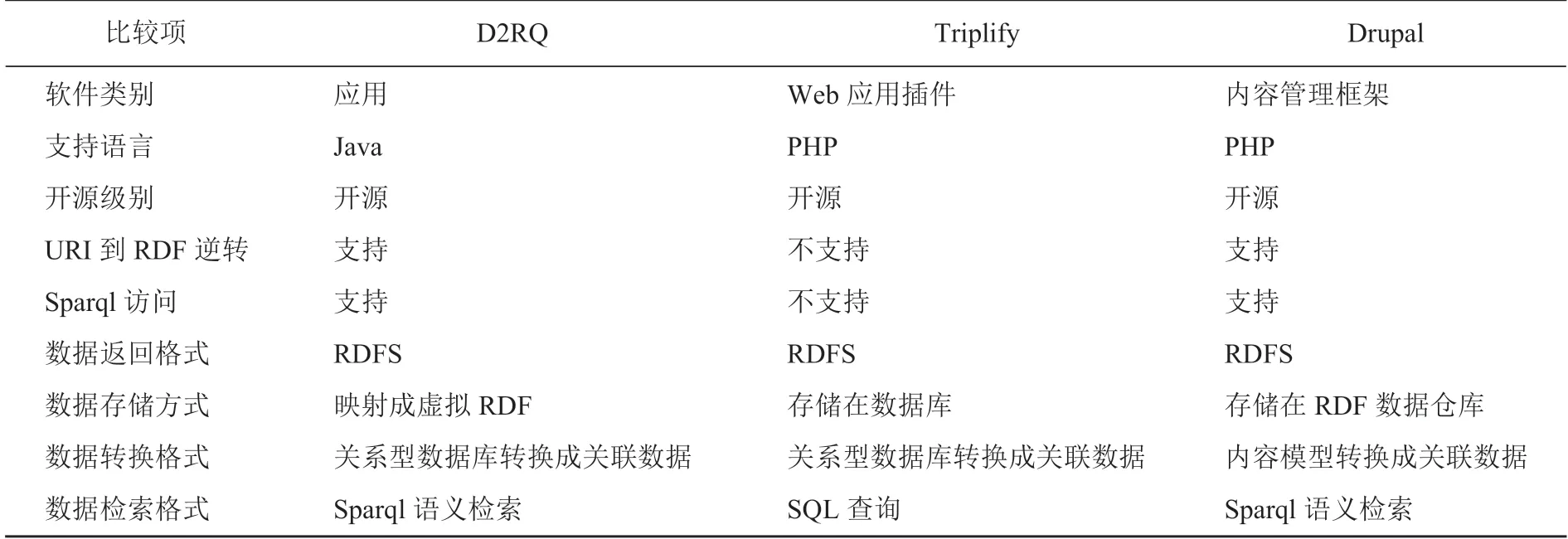
表1 关系数据发布工具比较
通过表1 工具的比较,从支持语言 Java,支持 Sparql 访问,数据存储方式为映射到 RDF,数据检索为 Sparql 检索,发现 D2RQ[19]更能符合系统需要,因此本研究针对于结构化数据的抽取采用D2RQ 工具。
D2R 主要包含 D2R 服务器、D2RQ Mapping 及D2RQ Engine[20]。其中,D2R 服务器使用 D2RQ 映射语言捕获应用程序,特定的数据库模式和 RDFS(RDFSehema,用于定义元数据属性元素,以描述资源的一种定义语言) 模式或 OWL 本体之间的映射。D2R 服务器包括一个可以从数据库的表结构自动生成 D2RQ 映射的工具。该工具为每个数据库生成新的 RDF 词汇表,将表名称作为类名称,将列名称作为属性名称。然后可以通过使用已知的 RDF 词汇表中的术语替换自动生成的术语定制映射。D2RQ Mapping 指定如何标识资源及如何从数据库内容生成属性值。D2RQ 中的中心对象是 ClassMap。ClassMap 表示从数据库中描述的 1 组实体到 1 类或 1 组类似资源类的映射。每个 ClassMap 都有 1 组PropertyBridges,它们指定如何创建资源描述。可以直接从数据库值或使用模式或转换表创建属性值。D2RQ 支持 ClassMap 和 PropertyBridge 级别的条件映射,n : m 关系的映射,并且可以处理高度规范化的表结构,其中实体描述分布在多个表中。D2RQ Engine 主要功能是运用 D2RQ Mapping 文件把结构化数据转换成 RDF 格式的文本数据[21]。D2RQ 组件的主体架构如图5 所示。

图5 D2RQ 组件的主体框架
这里以水务数据中的基本信息数据库中的水闸基本情况表ATT_RV_BASE_B 为例,其中该表的数据库用户名为 sw,数据库密码为 sw,转换的映射文件名称为 river.ttl,转换的 RDF 文件名称为 river.rdf,使用的 D2RQ 代码如下:generate-mapping-u sw-p sw-d oracle. jdbc. OracleDriver-tables ATT_RV_BASE_B-o river.ttl;dump-rdf-f RDF/XML -o river.rdf river. ttl。最后生成的 river. rdf 文件的部分内容如图6 所示。

图6 river. rdf 文件部分内容
其中第 1 行是 xml 声明(xml declaration):,它表明以下内容将是xml,xml 的版本号是 1.0。第 2 行是以 rdf: RDF 元素开始,它表明从这里开始知道为止的xml 内容,用于表达 RDF。列 URIrdf 所标识的命名空间为 http://www.w3.org/1999/02/22-rdf-syntaxns#,最后,rdf: Description 之后的是 RDF/XML 的主要部分,rdf: about 是指所描述的水闸基本情况表ATT_RV_BASE_B 的资源对象。
针对于非结构化的文本数据抽取,这部分的功能是利用 Python 及 Java 实现:1)需要运用分词工具对文本进行分词处理;2)利用 tf-idf 获取文本中的名词;3)再连接 CN-dbpedia 抽取名词的概念、属性及属性值信息;4)用 Jena 将文本信息写成RDF 文件格式[22]。
其中文本分词工具有如 jieba,SnowNLP(MIT),pynlpir,thulac,表2 是对这些工具的特点说明比较。
由表2 文本分词模式比较可以看出,jieba 具有精确、全及搜索引擎这 3 种分词模式,可以进行大量词性标注,且具有关键词提取的一些算法,如 tfidf 及 TextRank 算法(一种用于文本的基于图的排序算法),所以本研究中针对于非结构化文本的分词工具选取 jieba 分词工具。jieba 是做 Python 中文章分词的组件,具有 3 种分词的模式:1)精确模式,试图最准确地剪切句子;2)全模式,对句子中的所有单词进行扫描,虽然速度非常快,但不能解决分词的模糊性问题;3)搜索引擎模式在精确模式基础之上,再次分割长句,从而提高了召回率,适用于搜索引擎分割[23]。支持 3 种算法:1)基于前缀字典实现有效的字图扫描,然后生成由句子中所有可能的词语组合而成的有向无环图(DAG);2)动态规划可以用于找到最大的概率路径,找到基于单词频率的最大分割组合;3)对于未注册的单词,使用基于汉字能力的 HMM 模型,并使用维特比算法,分词的速度更快[23]。
针对于非结构化文本的数据抽取工作除了对文本进行分词处理外,还需要运用 tf-idf 算法计算词语权重,抽取出文本的重要主题概念词,链接 CNdbpedia 解析概念的上下位及属性信息,其中上下位信息是概念词的类别,可以依据这些向下为信息对这些抽取到的数据进行归类。至此可以抽取出文本中的重要信息,并以结构化数据的形式进行存储。
对水务相关的 500 个文本进行了上述数据转换的操作,其中大部分文本是通过 Python 从网络上进行爬虫得到的。以北京市水系.txt 文档为例,在 CNdbpedia 中的抽取的部分概念词和其上层概念信息如表3 所示。

表3 CN-dbpedia 中提取的概念和上层概念信息
通过概念词的上层概念,可以将其进行归类,并且可以发现,这些上层概念是可以与上文中提到的结构化数据对象分类对应的,从而可以看出,非结构化文本的数据是可以与结构化数据归到同一个类别下的,这样就实现了非结构化数据与半结构化数据之间的融合,通过这样一系列的数据实验与结果分析,验证了技术方法的可行性与可信度。
3.2 数据转换
数据转换是将数据从一种格式或结构转换为另一种格式或结构的过程。针对抽取出来的水务结构化及非结构化数据,需要将其统一转化为 rdf 格式的数据[24]。
需要使用 D2RQ 工具将结构化数据库数据抽取成 rdf 格式的文本,D2RQ 抽取语言如下:
语言 1:generate-mapping [-u username][-p password][-d driver][-tables tablename][-o outfile.ttl]jdbcURL
语言 2:dump-rdf [-f format][-o outfile.rdf]mapping-file.ttl
其中语言 1 是将结构化数据库表抽取成 ttl 文件,语言 2 是将 ttl 文件转换为 rdf 文本。这样就完成了结构化数据的转换。对于结构化的数据转换与抽取在一个程序中实现了,以 ATT_RV_BASE_B 为例,最终的转化结果如图6 所示。
该命令中各个参数的定义如表4 所示。
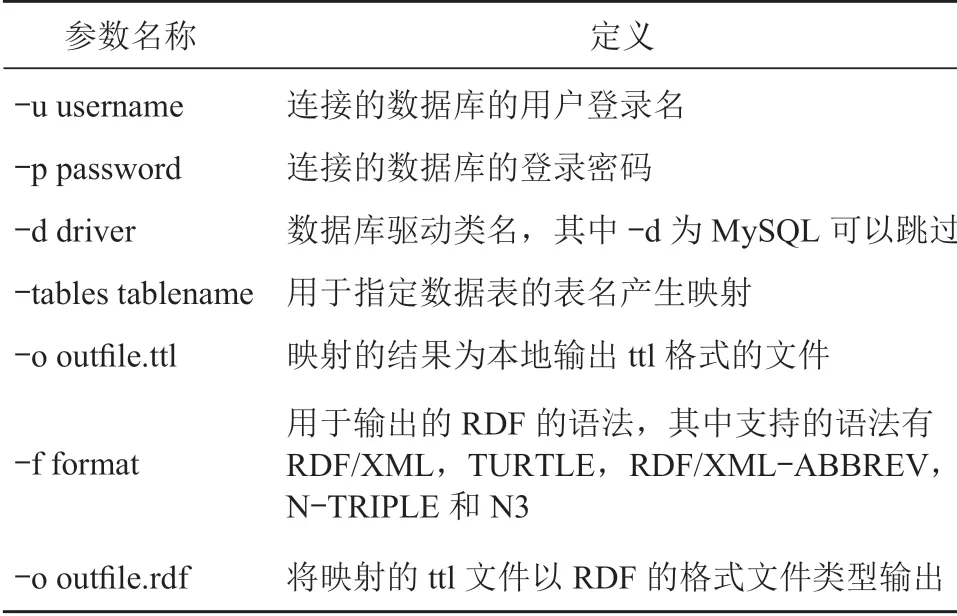
表4 D2RQ 参数定义
同时需要使用 jieba 分词工具分词的概念及连接CN-dbpedia[25]获取的概念上下位及属性等信息,并使用 Jena 工具将其转换为 RDF 格式的文件,这样就完成了非结构化文本数据的转换。
Jena 是一种 Java 框架结构用于创建语义 Web的应用系统,它为 RDF,OWL,RDFS 提供了程序开发的环境,包括对 RDF 文件及模型进行处理的RDF API,以及用于对 RDF,OWL,RDFS 文件进行解析的解析器。Jena 可以创建 RDF 模型,本体模型(OntModel)是对 Jena 的 RDF 模型的扩展,它可以处理本体水务数据。Jena 通过 model 包中的 ModelFactory 创建本体模型,ModelFactory 是Jena 中提供用来创建各种模型的类,其中在类中定义了能够具体实现模型的成员数据和创建模型的20 多种方法。Jena 构建 RDF 模型步骤如下:
1)创建模型。O n t M o d e l o n t M o d e l =ModelFactory. createOntologyModel ( )。
2)创建查询对象。Query query = QueryFactory.create (queryString)。
3)创建查询执行对象 QueryExecution,将查询的对象连接到指定模型上:QueryExecution qe =Query Execution Factroy. create (query, model)。
4)生成结果集,类似与数据库查询,生成结果集:Result Set rs = qe. execSelect ( )。
表3 数据最终所转换得到的部分 RDF 文件如图7 所示。

图7 RDF 文件部分内容
至此,完成对结构化与非结构数据的抽取与转换,并将 2 种数据通过实验进行了融合。结果表明,提出的结合 D2RQ,jieba 工具及 tf-idf 算法等技术,可以实现对多源异构数据的融合。
4 基于云计算的分布式数据存储
随着水务行业的快速发展,数据量与日俱增,云计算可以快速、高效地处理海量数据。为了保证数据的高可靠性,云计算通常会采用分布式存储技术,将数据存储在不同的物理设备中。这种模式不仅摆脱了硬件设备的限制,同时扩展性更好,能够快速响应用户需求的变化。分布式存储与传统的网络存储并不完全一样,传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
在当前的云计算领域,Google 的 GFS 和Hadoop 开发的开源系统 HDFS 是比较流行的 2 种云计算分布式存储系统。谷歌的非开源的 GFS(GoogleFileSystem)云计算平台满足大量用户的需求,并行地为大量用户提供服务,使得云计算的数据存储技术具有了高吞吐率和传输率的特点。大部分 ICT 厂商,包括 Yahoo,Intel 的“云”计划采用的都是 HDFS 的数据存储技术。未来的发展将集中在超大规模的数据存储、加密和安全性保证,以及继续提高 I/O 速率等方面。
针对于抽取转换成功的结构化及非结构化数据分别采用不同的存储方式。非结构化数据存储由HDFS 完成,通过 Hadoop 集群功能接口,完善 RDF文件的管理功能。结构化数据经由分布式数据库存储,在 HDFS 的上层利用 Hive 和 HBase,通过建立不同数据表的关联映射实现数据操作,如查询、并联查询、添加、删除等。
5 结语
针对北京市水务数据资源存在多源异构及数据库体系不同难以直接融合等导致的信息孤岛问题,提出了面向大数据和云计算的数据资源融合技术。针对结构化及非结构化数据的融合提出了一套数据融合技术方案,包括数据抽取、转换两大步骤,并通过实验验证了方法的可行性与可信度。针对融合后的数据的海量存储,提出了一种基于云计算的分布式数据存储技术。在数据抽取及转换模块,分别运用不同的技术,统一将 2 种数据转换为 rdf 格式,便于数据的统一化处理。在数据存储模块提出一种基于云计算的分布式数据存储技术,通过分布式技术可以实现海量水务数据的存储及处理。最终融合、存储后的数据可以应用到不同的平台,实现海量数据的高效查询,解决多源异构数据关联少、难以集成和高效存储的问题,能够为水务业务管理、决策指挥等提供有效的数据支撑。
由于受时间和条件的限制,本研究存在以下问题需要今后进一步的研究:1)提出的数据抽取技术,或许还有更好的数据抽取方法需要进一步研究和应用;2)提出的基于云计算的分布式数据存储需要进一步完善,未来可能会有更多类型的数据转换方式,针对不同类型的海量数据同样需要更加高效的数据存储方式;3)所融合的北京水务数据资源目前还不太全面,需继续融合更多的水务数据,以实现真正意义上的水务大数据共享及应用。
