基于混合注意力与强化学习的文本摘要生成
2020-01-06党宏社陶亚凡张选德
党宏社,陶亚凡,张选德
陕西科技大学 电气与控制工程学院,西安710021
1 引言
文本摘要生成是自然语言处理的一个重要的方向,要求机器阅读一篇文章后自动生成一段具有概括性质的内容[1],比如生成摘要[2]或标题[3]。与一些其他的应用不同,如机器对话[4]、机器翻译[5]等输入和输出文本的长度较为接近,文本摘要的输入的文本长度往往远大于输出的文本长度,输入与输出的不对称也使得其较为特殊,因此诞生了一种抽取式的方式[6]——在原文中寻找重要的部分,将其复制并拼接成生成的摘要[7],但是抽取的单词往往因为缺少连接词而不连续,而且无法产生原文中不存在但是需要的新单词。因此人们需要一种类似人类书写摘要的方法,先阅读文章并理解,再自己组织语言编写摘要,摘要与原文意思接近且主旨明确。随着序列到序列(Sequence-to-Sequence,Seq2Seq)模型的成功[8],使用递归神经网络(Recurrent Neural Networks,RNN)来阅读文章和生成题目成为可能[9]。
但是常规的Seq2Seq模型[10]存在一些问题,首先,进行摘要生成任务之前,需要先建立固定大小的词汇表,在处理文本时将文本的每个单词用其在词汇表中的索引代替。但是几乎所有的文章都会出现词汇表中没有的(Out-of-Vocabulary,OOV)单词,如人名、地名、比分等,当常规Seq2Seq 模型遇到这些单词后,只能将其统一视作不认识的单词(Unknown Word,UNK),因此输出也经常会出现UNK[11]。目前该问题已经有较好的解决方案,如指针网络[12]。
然而有很多其他的问题目前并没有统一的解决方案。在生成多句话的摘要时,常常会生成重复的单词或句子[13]。See 等人[13]利用修改损失函数,加入coverage项,强制要求每个时间步的输出注意力分散,此方法在一定程度上改善了重复问题,但是由于修改了损失函数,使得优化目标与真实目标存在了一定偏差。Liu等人[14]增加判别网络来评估生成的摘要,可以达到识别重复句子的效果,但是增加了一倍的计算量,且生成网络和判别网络在训练时需要达到动态平衡,非常难以训练。
此外,在序列生成的任务中还有一个较为常见的问题,称为曝光偏差(exposure bias)[15],即在训练过程中,解码器的每一个输入单词使用训练样本中正确输出的上一个单词,而在测试阶段,解码器每一个输入单词为自己的上一个输出单词,因此造成的测试与训练时结果的偏差。经过较长时间的训练后,模型在训练集上的ROUGE 得分常常出现50 以上,而测试集却只有30 多。这种现象说明产生了较为严重的过拟合,对最终的效果带来一定的负面影响。
针对以上问题,本文研究思路如下:(1)对于重复问题,对历史生成的单词增加注意力,使得模型在生成当前单词时考虑到历史生成的单词,防止生成已经生成过的单词,称之为解码自注意力,同时考虑历史的注意力,防止与之前的注意力过于相似,鼓励模型注意其他部分,称之为存储注意力。(2)现有的注意力大多采用向量点积来衡量相似度,但是实现更复杂的关系则无法实现,因此我们对注意力计算方式改进为单层神经网络,使其具备避免重复的能力。(3)对于曝光偏差问题,根本的解决方法是在训练时输入上一个时刻的输出,但是这样会造成训练极不稳定通常不收敛,而借助强化学习(Reinforcement Learning,RL)[16],把整个模型当作一个智能体(agent),将生成的摘要作为与参考摘要的ROUGE得分[17]作为奖赏(reward),以生成的整个句子作为优化目标来增加训练时的稳定性,最后通过策略梯度[18](policy gradient)来训练。
2 方法与模型
将使用到的符号做如下定义:ne表示编码器(encoder)长度,nd表示解码器(decoder)长度,x={x1,x2,…,xne}表示编码器输入单词序列,h={h1,h2,…,hne}表示编码器的输出序列,s={s1,s2,…,snd}表示解码器的输出序列,y={y1,y2,…,ynd}表示最终输出的单词序列而表示训练样本参考摘要中的单词序列,[a,b]表示将向量a 和向量b 合并为一个向量。
2.1 整体架构与训练方法
在强化学习领域,一般的模型结构如图1(a)所示,智能体首先从环境获取当前的状态,然后进行运算得到动作输出至环境,环境再根据智能体的动作计算奖赏同时得到下一个时刻的状态,由此循环一直到终止状态停止,将此过程称为一次完整交互。智能体根据一次完整交互中获得的奖赏通过强化学习算法来更新智能体的输出规则。

图1 模型整体结构
将强化学习应用在文本摘要生成任务中,结构如图1(b)所示,将评价指标和训练样本组合抽象为一个整体作为环境,摘要生成模型抽象为一个智能体,一次完整的交互和训练过程为:
(1)环境中由训练样本提供文本x,作为状态送入摘要生成模型。
(2)摘要生成模型根据文本x 生成摘要y,并送入环境。
(3)环境中的评价指标结合生成的摘要y 与训练样本中的参考摘要y*计算得分,将得分作为奖赏再返回给摘要生成模型,同到达终止状态,一次完整的交互结束。
(4)摘要生成模型根据此次交互得到的奖赏通过强化学习算法训练生成模型。
2.2 摘要生成模型结构组成
摘要生成模型包括编码和解码两个步骤,编码时每个时刻输入文本中的一个单词,其目的为让模型理解每个单词的意思和整体的意思;在解码时,第一个时刻输入表示开始信号的特殊字符,其余时刻输入上一个生成的单词,第i 个时刻的输出为生成的第i 个单词yi。解码时的第三个时刻的摘要生成模型示意图如图2所示,此时输入为y2输出为y3。生成模型以输出表示结束的特殊字符结束。本文主要改进了其中的注意力机制和上下文向量,模型的训练过程如下所示:
(1)输入单词序列经过嵌入层得到同样长度的向量,再送入编码器中。
(2)对所有输入文本编码后,将编码信息送入解码器。
(3)将上一个时刻的输出经过嵌入层送入解码器,得到当前时刻的输入。
(4)计算存储注意力和解码自注意力,得到编码器与解码器的上下文向量。
(5)将上下文向量和解码器输出送入生成与指针网络,得到输出的单词。
(6)重复(3)到(5)直到输出单词为表示结束的特殊字符或超过设定最大长度,至此完成整个摘要的输出。
(7)将生成的摘要与训练样本中的参考摘要通过评价指标计算奖赏,并由此训练生成模型。
下面分别对文本预处理、基本结构、存储注意力、解码自注意力、生成与指针网络、损失函数和强化学习进行详细介绍。
2.3 文本处理和基本结构
在将文章送入模型前,首先需要进行文本预处理,处理的过程如下:
(1)首先对所有的文章按照单词进行分割,截取固定长度的单词(如前400),长度不够的文章将在后面添加表示填充意义的特殊字符。
(2)根据单词的出现频率对单词进行编号,取一定长度的个数建立编号与单词一一对应的全局单词表(如选取出现频率最高的5万个单词)。
(3)在编码时将每个单词的编号输入模型,每个时刻输入一个。每个批次中未在全局单词表中的单词会建立一个临时单词表(仅在这个批次训练中使用)。
模型最终输出为每个单词的编号,再根据全局单词表和临时单词表还原出单词。
模型的基本结构包括嵌入层、编码器和解码器,我们的基本结构参考文献[10],嵌入层为一个全连接层,输入单词的编号,输出固定长度的词向量,词向量再输入编码器或解码器。编码器采用单层的双向LSTM,由前向LSTM(LSTMf)和后向LSTM(LSTMb)组成,编码器的的输出由前后向LSTM 的输出合并而成,即第i个时间步的输出
2.4 存储注意力
为了防止生成重复的单词,引入存储注意力,即在每个解码时间步将注意力进行保存,在新的时间步得到的注意力除以历史注意力之和,削弱之前注意力高的部分,增强之前较少关注的部分。解码器的第t 个时间步的输出对编码器每个时间步的注意力计算公式如下:

在传统的注意力机制中,没有对历史的注意力进行保存,因此传统的注意力机制的的计算公式为
根据第t 个时间步对编码器每个输出的注意力,可以得到编码器的上下文向量(context vector),其计算公式如下:

图2 摘要生成模型在解码的第三个时刻的示意图

2.5 解码自注意力
除了临时存储注意力机制,还引入解码自注意力,为了在生成新单词时可以对之前生成过的单词进行关注,防止重复。在第t >1 个时间步时,解码器输出对于第0 <j <t 个时间步的输出的注意力的计算公式如下:

其中,vd、、和都是需要学习的参数。
在第t=1 个时间步时,解码器上下文向量cdt 为0向量,当t >1 时,cdt 的计算公式如下:

2.6 生成与指针网络
第t 个时间步最终输出单词的分布为Pv,表示单词表中输出每个单词的概率,Pv与编码器的上下文向量、解码器的上下文向量和解码器当前输出st均有关,使用线性函数加softmax 来计算:

其中Wout和bout是需要学习的参数。
综合Ptv和指针网络,得到最终输出单词yt的概率为:

当然,若单词表中不存在单词yt,则
2.7 损失函数与强化学习
在训练RNN 做序列生成任务时,最常用的方法为“teacher forcing”[19],在解码的每个时间步以最大化似然估计作为目标进行网络的训练。用表示正确的摘要中第t 个单词,最大化似然估计等价于最小化下面的损失函数:
首先,使用这样的损失函数,训练时解码器输入为真实输出,然后测试时为自身的输出,会造成“exposure bias”;其次,似然估计的目标与评价指标如ROUGE 存在一定偏差,会出现损失函数的值降低,ROUGE反而升高,或相反。
为解决这两个问题,构建了强化学习模型。将输入的文本作为状态,网络模型作为Actor,输出的整个摘要作为动作,输出摘要的ROUGE得分作为奖赏。构建的网络模型中,无论在训练还是在测试中解码器的输入均为自己上一个时刻的输出,因此可以避免曝光偏差的产生。而由于奖赏的计算直接使用了最终的评价指标,因此也不存在优化目标的偏差。
设θ 为网络模型中所有可训练的参数,则训练的目标为计算最优的θ 使生成效果最好。在训练时,网络先生成摘要,然后计算奖赏,再计算损失函数关于θ 的梯度,使用梯度下降的方法更新所有θ。
将输出摘要y 的奖赏记做R(y),最大值为1最小值为0,训练的目标为最大化生成摘要的期望奖赏,即损失函数LRL(θ)为负的期望奖赏:

根据策略梯度算法可以得到损失函数关于θ 的梯度:为了减小梯度的方差,向公式中增加基线b(baseline):
为了计算R(y)和b,定义了两种产生输出的规则,用ys表示根据分布采样得到的输出,用yg表示根据分布贪婪得到的输出。
将R(yg)作为优化目标,而R(ys)作为基线,得到式(14)所对应的损失函数为如下形式:

该公式也可以直观的解释,当R(yg)大于R(ys)时,需要增大输出使用贪婪方法得到摘要中每一个单词的概率,即最大化,其等价于最小化LRL。
在更新参数时,首先根据损失函数计算关于最外层参数的梯度,再根据链式求导法则逐层向前计算梯度,然后选择优化方法(如Adagrad[21])迭代更新参数。由于如今的深度学习框架只需要构建前向计算图,然后根据损失函数自动反向计算梯度,且计算梯度并不是本文的重点,因此省略损失函数关于模型中每个参数的梯度的计算。
3 实验与分析
3.1 实验数据
选择在数据集CNN/Daily Mail 上进行训练并验证,该数据集由网络新闻组成,平均一篇文章781 个单词(tokens),每篇文章匹配一个平均3.75句话的摘要,平均56个单词。通过文献[13]提供的方法,获得了与其相同的287 226 个训练样本,13 368 个验证样本,11 490 个测试样本,并在使用过程中未对样本进行预处理。
3.2 模型参数
对于所有的实验,词向量的维度为128,未使用预训练的词向量如word2vec[20]等,LSTM 的内部状态为256维,单词表使用5 万个单词。优化方法使用Adagrad[21],学习速率为0.15。使用文献[13]提供的预训练的模型,增加存储注意力、解码自注意力和强化学习。批大小(batch size)使用20,解码时使用beam 为5 的集束搜索(beam search)。
3.3 实验环境
使用单台计算机,显卡为NVIDIA GeForce GTX 1080Ti,CPU 为Intel Core i7-7700K,4.2 GHz,内存为32 GB。使用ubuntu16.04 操作系统,编程语言使用Python,版本为3.5,深度学习框架使用tensorflow[22]。
3.4 测试结果
首先,在测试集上对比了基础结构、存储注意力、混合注意力以及混合注意力加强化的模型生成的摘要中的重复情况。统计了生成结果中含有重复的2单词组、3单词组和句子的样本占总测试集大小的百分比,统计结果如表1所示。
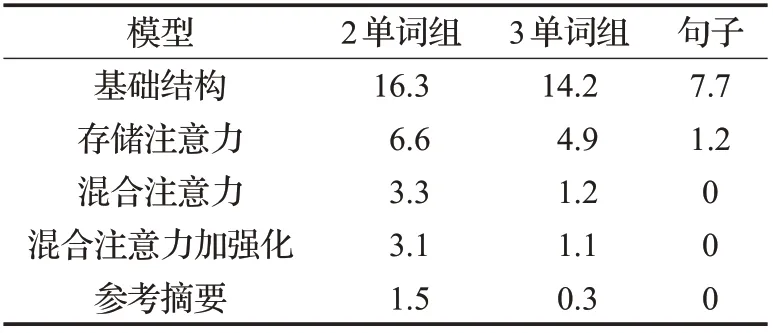
表1 生成摘要中的重复率
由统计结果得知,参考摘要中单词组重复率非常低,且不存在句子重复,而基础结构存在大量的重复单词组和句子,增加存储注意力后无论是单词组还是句子的重复率大大下降;而增加混合注意力后单词组的重复率又大幅下降,且句子已经没有重复;但增加强化学习对于重复问题的帮助并不是特别明显。
对于生成的摘要,使用ROUGE-1(RG-1)、ROUGH-2(RG-2)和ROUGE-L(RG-L)为评价指标,来衡量生成的摘要与参考摘要的相似程度,值越大表明相似程度越高,在使用强化学习的模型中的优化目标为ROUGE-L。测试结果如表2所示。
在基本结构上增加存储注意力、混合注意力和混合注意力加强化的效果依次增加,说明混合注意力与强化学习在一定程度上对现有问题起到较好的效果,且对比了Nallapati 等人提出的抽取式的方法[10]、See 等人提出的Pointer-Generator Coverage(PGC)方法[13]以及Liu 等人提出的Generative Adversarial Network(GAN)方法[14],在三个指标中均有超越。

表2 模型在测试集的ROUGE得分
其中,抽取式的方法同样采用了序列到序列的架构,但没有用来阅读文章和生成标题,而是在原文中选择重要的单词抽取出来组合为摘要。PGC 与本文架构部分重合,不同的地方在于其采用传统的注意力机制,训练方法也使用的传统的“teacher forcing”的方法,但使用一种coverage 方法强制解码时不同时刻注意力的分布要不同。采用GAN 的方法包括两个网络架构、一个生成器、一个判别器,而生成器同样使用传统注意力的序列到序列架构,使用判别器来区分生成的摘要和参考的摘要,而生成器的目标为生成高质量的摘要来骗过判别器,两个网络周期性交替训练。
同时,统计了PGC 与加入混合注意力和混合注意力加强化的模型在训练集训练时的ROUGE得分,如表3所示。
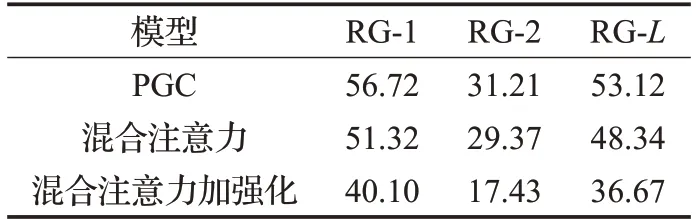
表3 模型训练收敛时的ROUGE得分
结合训练和测试时的ROUGE得分,不难发现PGC和混合注意力模型在训练集的得分远高于测试集的得分,这就说明产生了曝光偏差,也就产生了较严重的过拟合,主要原因是在训练时每个时间步输入为参考摘要的上一个单词,因此模型是在已知上一个单词的情况下去预测下一个单词的。这种过拟合所带来的最直接的影响就是恶化了测试集的结果。而使用强化学习这种方法使得模型在训练集和测试集的结果基本接近,也就消除了曝光偏差,最终在测试集的效果带来一定的提高。
4 结束语
本文针对文本摘要生成的任务,采用Seq2Seq 架构,引入存储注意力和解码自注意力来解决重复问题,使用指针网络来解决OOV 单词的输出,引入强化学习来针对评价指标做定向优化并解决“exposure bias”问题。使用数据集CNN/Daily Mail 对本文模型进行验证,实验结果表明混合注意力机制和强化学习可分别带来一定程度的优化,最终效果超越了世界先进的模型。
对于文本摘要生成,有很多还可以探讨的地方,如:
(1)词嵌入可以使用最先进的预训练模型(如BERT[23]或XLNet[24])。
(2)网络架构除了Seq2Seq,也可选用ConvS2S(Convolutional Sequence to Sequence[25])、全注意力模型[5]或神经微分方程[26]等。
(3)解码部分可以引入逆强化学习(Inverse Reinforcement Learning)[27]来对网络的生成结果进行评估,并使用蒙特卡洛树搜索(Monte Carlo Tree Search)[28]来寻找最优的生成结果。
