深度学习在视频动作识别中的应用
2020-01-05潘陈听
潘陈听
摘 要:快速有效地识别出视频中的人体动作,具有极其广泛的应用前景及潜在的经济价值,深度学习的火热给视频动作自动识别带来了巨大的发展。提出了一种基于深度学习和非局域平均法的自注意时间段网络,作用于剪切好的视频片段。通过构造非局域模块并将其加入到以ResNet为基本模型的时间段网络,可以得到新模型。经过在TDAP数据集上验证,该模型可较为精确地识别出人体动作,与原有模型相比在不增加时间复杂度的前提下有一定程度的提升。
關键词:动作识别;非局域模块;时间段网络
中图分类号:TP391.4 文献标识码:A
Application of Deep Learning in Video Action Recognition
PAN Chen-ting
(Collegeof Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing,Jiangsu 211106,China)
Abstract:Recognizing human actions in videos quickly and effectively,has broad application prospects and potential economic value. Deep learning has been widely used for action recognition. We proposed self-attention temporal segment networks,whose inputs are clipped video clips. This network is based on deep networks and non-local means. By adding non-local modules to temporal segment networks with ResNet as the basic model,we can get our new model. Verified on TDAP dataset,our new model can recognize human actions more accurately than the original model,without increasing much time complexity.
Key words:action recognition;non-local module;temporal segment network
视频动作识别在计算机视觉领域占据着重要的一席之地,由于广泛的应用场景,近年来其吸引了大量的目光。随着人工智能的迅速发展,特别是随着对机器学习与深度学习的深入研究分析,激发了国内外研究学者对人体动作识别问题的研究,已经有了大量的研究成果。基于卷积神经网络的方法在图像分类上取得了很大的成就而且相比视频数据集有更多的图像数据集可用于训练网络。基于以上两点,目前出现的很多视频分类方法都是基于原有的图像分类方法。然而视频不仅包含大量与目标动作无关的无关信息而且在帧之间还隐含着大量重要的时序信息。
为了解决上述问题,提出了自注意时间段网络。该方法将图像处理中经典的非局域平均法引入时间段网络。我们的工作类似于机器翻译领域的自注意力(self-attention)方法[1]。自注意力模块关注特征图中所有位置并在嵌入空间中计算它们的加权平均以此得到序列中某个位置的响应。正如接下来讨论的,自注意力可以被视为一种非局域平均[2]。使用非局域方法有几个优点[3]:(a)与卷积神经网络和循环神经网络的先进效果相比,非局域方法通过直接计算任意两个点的联系来获取长远依赖关系;(b)就像实验中展示的,非局域方法效果很好并且在网络层数相近的情况下达到了较好的结果;(c)最后,非局域方法支持不同的输入规模并且能轻易地与其它方法相结合。
1 相关工作
1.1 基于手工设计特征的人体动作识别
在深度学习出现前数十年已经出现了许多动作识别技术。这些方法大多关注的是是局部时空特征的有效表示,例如HOG3D[4],SIFT3D[5],HOF[6]和MBH[7]等,而前几年提出的IDT[8]则是在这之中最先进的手工特征。尽管有着不错的表现,但手工特征有几个不可避免的缺陷,例如计算复杂度高,很难获取语义信息以及缺少判别能力和扩展性。因此这类方法逐渐失去了吸引力或只是作为深度方法的补充。
1.2 基于深度学习的人体动作识别
自2012年深度网络开始火热,用于图像表示的架构取得了极大的进展,然而目前仍然没有视频领域的权威架构。目前视频架构之间主要有以下区别:网络的输入只包含RGB视频还是包含了预处理的光流,卷积核是采用2d(基于图像)还是3d(基于视频),以及在2d网络的基础上帧间信息如何整合。
双流神经网络(Two-Stream ConvNet)[9]在动作识别领域是一类很常用的方法,该方法简单却有相当优异的效果。双流网络顾名思义由时间流与空间流两路网络组成,空间流网络将视频单帧或堆叠帧输入卷积网络学习空间域上的视频信息,时间流网络将光流图以多通道的形式输入卷积网络学习时间域上的视频信息。两路网络各自对视频输出属于各类的概率,最后平均两个概率向量得到最终的分类结果。
3D神经网络[10]是另一类很常用的方法。随着近年来计算力的进一步提升以及数据集规模的进一步增加,3D神经网络发展迅速,从最开始的不如传统方法到如今与双流网络并驾齐驱。3D网络在设计之初就是一种端到端的网络架构,它可以直接将视频作为输入,并输出最终分类类别。由于网络结构复杂,3D网络需要很大的数据集才能得到较好的结果,并且网络层数不能过深。
RNN可以处理时域信息,因此将CNN与RNN相结合也可以学习视频中时间维度的信息。LSTM(Long Short-Term Memory)[11]和GRU(Gated Recurrent Unit)[12]是RNN中两类常用的变种架构。它的基本思想是用RNN对CNN最后一层在时间轴上进行整合。这里,它没有用CNN全连接层后的最后特征进行融合,是因为全连接层后的高层特征进行池化已经丢失了空间特征在时间轴上的信息。目前效果最好的此类方法为长时递归卷积神经网络(Long-term recurrent convolutional network,LRCN)[13]。
2 网络模型
将详细介绍非局域时间段网络的设计原理和实现细节,具体地展示该网络模型如何对视频动作进行有效识别。
2.1 非局域方法
类似非局域平均法,定义了一种在深度网络中更通用的非局域方法:
yi = ■■f(xi,xj)g(xj) (1)
这里i是需要计算响应的输出位的索引,j是枚举了所有可能位置的索引。x是输入信息(图像,序列,视频;通常是他们的特征图),y是x的同等规模的输出信息。匹配函数f计算i和所有j之间的标量。一元函数g计算位置j的输入信息的表示。最后再将所得通过因子C(x)归一化。
公式(1)中的非局域方法是基于考虑了所有位置j的事实。作为对比,卷积方法在某个区域计算了加权输入,循环方法在t时刻通常只考虑当前以及接下来的一段时间。非局域方法与全连接层也不同。公式(1)计算了不同位置间基于关系的响应,然而全连接层使用学会的权重。换句话说,全连接层中xi和xj间的关系不是输入数据的函数,不像在非局域层中。另外,公式(1)支持不同规模的输入,并维持对应规模的输出。相反,一个全连接层需要固定规模的输入/输出。
非局域方法是一个很灵活的构造模块并且可以与卷积/循环层很简单地一起使用。它可以被添加到深度网络的底层中而不像全连接层只能添加到顶层。可以构造同时包含非局域和局域信息的更深層网络。
2.2 非局域模块
把公式(1)中的非局域方法嵌入到非局域模块就可以使之成为许多现有的网络的一部分。如下定义非局域模块:
zi = Wz yi + xi (2)
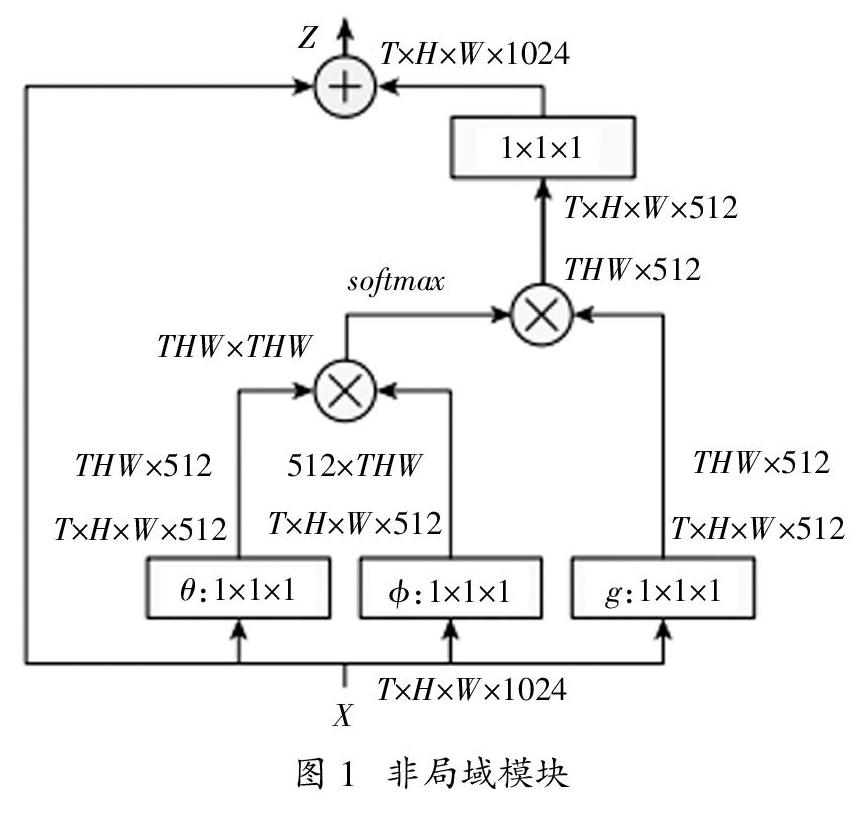
yi由公式(1)给出,而“+”表示残差连接。残差连接允许把一个新的非局域模块插入任何预训练过的模型。图1为非局域模块的一个例子。
当用于高层次采样的特征图时,非局域模块的匹配运算是很轻量的。举个例子,图1中传统参数为T=4,H=W=14或7。由矩阵相乘实现的匹配计算相当于基础网络中传统的卷积层。另外采取了以下措施使之更高效。
将以Wg,Wθ和W?准表示的通道数设置为 的通道数的一半。这里使用了瓶颈设计并把一个模块的计算量减少了一半。还采用了一个次采样技巧来减少计算量。将公式(1)修改为yi = ■■f(xi,■j)
g(■j),■是x的次采样(如通过池化)。在空间域实现可将匹配运算的计算量减少到1/4。这个技巧不会改变非局域操作,但可以使计算更稀疏。它可以通过在图1的?准和g函数后添加一个最大池化层实现。
考虑将f函数设置为嵌入高斯函数:
f(xi,xj) = e■ (3)
这里θ(xi) = Wθ xi以及φ(xj) = Wφ xj是两个嵌入。再设置C(x) =■f(xi,xj)。
注意到最近机器翻译领域的自注意力模型是非局域方法在嵌入高斯函数下的一个特殊情况。可以看到给定I,就是对于维度j的softmax运算。所以有y = soft max(xT WθTWφ x)g(x),即自注意力的形式。同样,揭示了自注意力模型与计算机视觉领域传统的非局域均值法的内在联系,并且将序列自注意力网络拓展为计算机视觉中视频动作识别的更通用的时空非局域网络。
2.3 非局域时间段网络
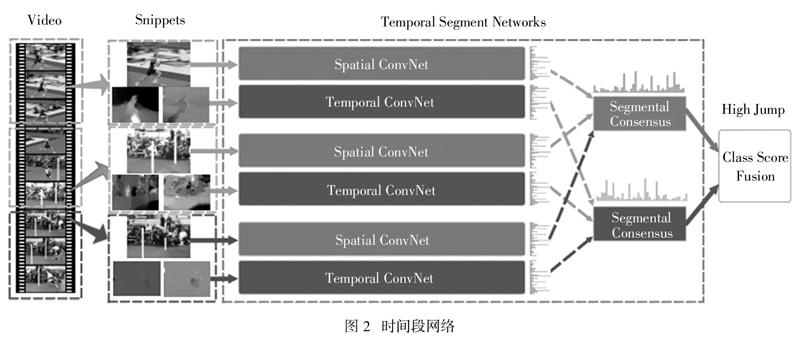
双流神经网络的一个很明显的问题是其现有形式在建模长期时序结构的羸弱能力。这主要归咎于其对时序上下文的处理方法有限,因为它本身是为单帧(空间域网络)或一小段时间内的堆叠帧(时间域网络)而设计。然而复杂行为例如运动包含相当长时间内的多个阶段。如若无法将利用这些动作的长期时序结构训练卷积网络,那将产生相当大的损失。为了处理这个情况,使用时间段网络,一个视频级别的框架,可建模整个视频的动态变化,如图2所示。
特别地,时间段网络是为了利用整个视频的时序信息来进行视频级别的预测。它也是由空间流卷积网络和时间流卷积网络组成。并非处理单帧和堆叠帧,时间段网络处理从整个视频中进行稀疏采样所得的切片序列。序列的每个切片会对动作类进行初步预测,然后对这些预测进行整合得到整个视频级的预测。在训练过程中,迭代优化视频级预测的损失值,而不是切片级的预测。
给定一个视频V,把它分成相同时间的K段{S1,S2,1,SK},然后时间段网络将对序列切片进行如下建模:
TSN(T1,T2,L,TK) =
H(G(F(T1;W),F(T2;W),L,F(TK;W)))
(4)
这里(T1,T2,1,TK)是切片序列。每个切片在其对应时间段SK内随机采样得到。F(Tk;W)是以参数W表示的处理切片TK并生成每类的分数的网络函数。段融合函数G整合所有切片的输出并取得其类别假设。基于此融合,预测函数H对整个视频预测其对每个动作类别的可能性。这里选择选择广泛使用的softmax函数。与基础的类交叉熵损失相结合,最后关于段融合的损失函数为:
L(y,G) = -■yiGi - log■exp Gj (5)
C为动作类别的数量而yi为关于类Ⅰ的真实标签。融合函数G的形式仍是个问题,使用最简单的形式,Gi = g(Fi(T1),…,Fi(TK))。这里类别分Gi由对所有切片关于同一类的分数采用聚合函数g所得。评估了几种不同形式的聚合函数g,包括平均法,最大值法以及加权平均。在以上方法中,平均法取得了最好的结果。
以ResNet-50[14]作为基准模型,此模型可以在ImageNet上进行预训练,唯一包含时间域的操作是池化层。换句话说,此基准简单地融合了时序信息。将非局域模块插入ResNet使之成为非局域网络并尝试了增加1,2,4或8个模块。
3 实验及结果分析
3.1 数据集和实现细节
为了验证模型的性能,在TDAP数据集进行了实验。TDAP数据集包含6个手势动作类别以及684个剪切好的视频片段。使用随机梯度下降(SGD)算法来更新网络参数,批大小(batchsize)设置为16。网络在ImageNet上进行预训练。空间流网络的学习率初始值为0.001,每迭代100次减小到原来的1/10,整个训练过程迭代250次。时间流网络的学习率初始值为0.001,每迭代150次减小到原来的1/10,整个训练过程迭代350次。也使用了抖动,水平翻转,角裁剪等技术进行数据增广。采用了TVL1算法进行光流图像抽取。在预训练后,冻结所有批正则化层的均值方差参数。
3.2 对比实验
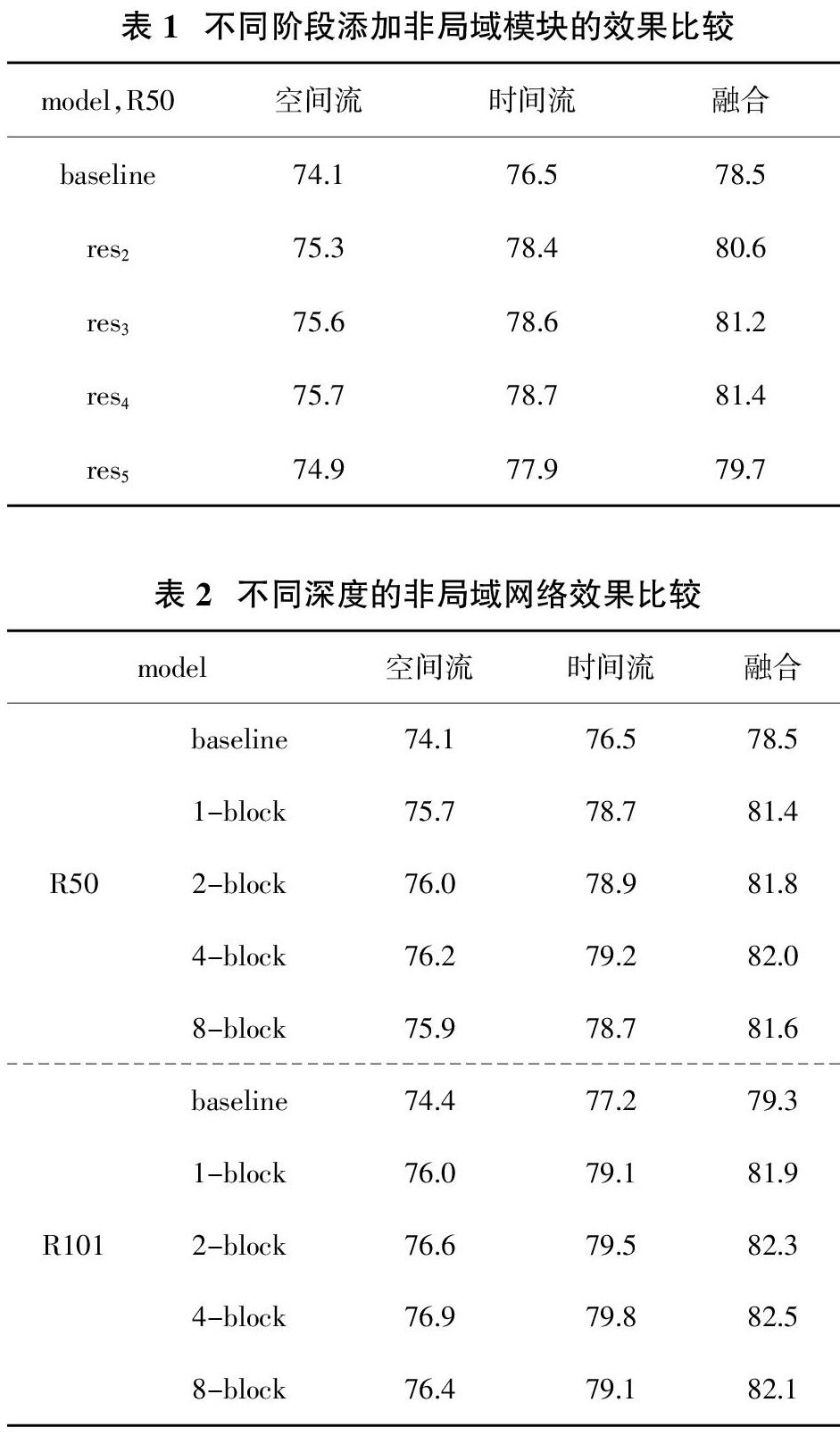
表1比较了将非局域模块加入ResNet的不同阶段的效果。非局域模块被插入到某个阶段的最后一个残差块之前。从表2中可以看出,插入res2,res3以及res4的效果是相似的,而插入res5的效果偏低。可能的解释是res5的空间规模很小所以它提供的空间信息不充分。
表2比较了添加更多非局域模块的结果。分别尝试在ResNet-50网络中添加1个模块(res4),2个模块(res3和res4),4个模块(每层1个)以及8个模块(每层2个)。在ResNet-101中也将其添加到相应的残差塊。从表3可以看出并不是添加越多的非局域模块越好,可能的解释是数据量太少以及网络结构过深导致其过拟合。
4 结 论
针对近几年来提出的视频动作自动识别问题,引入了计算机视觉中经典的非局域均值法,提出了自注意时间段网络,并分析了其与机器翻译领域先进的自注意力方法的内在联系。为了验证模型的性能,在TDAP数据集上进行了相关实验。实验结果表明本模型拥有较好的性能并且产生极少的额外训练时间。
参考文献
[1] XU K,BA J,KIROS R,et al. Show,attend and tell:neural image caption generation with visual attention[C]// Proceedings of the International Conference on Machine Learning. 2015:2048-2057.
[2] BUADES A,COLL B,MOREL J M. A non-local algorithm for image denoising[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2005,2:60-65.
[3] WANG X,GIRSHICK R,GUPTA A,et al. Non-local neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:7794-7803.
[4] KLASER A,MARSZALEK M,SCHMID C. A spatio-temporal descriptor based on 3D-gradients[C]//Proceedings of the British Machine Vision Conference. 2008:275:1-10.
[5] SCVANNER P,ALI S,SHAH M. A 3-dimensional sift descriptor and its application to action recognition[C]// Proceedings of the 15th ACM international conference on multimedia. 2007:357-360.
[6] CHAUDHRY R,RAVICHANDRAN A,HAGER G,et al. Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2009:1932-1939.
[7] WANG H,KLASER A,SCHMID C,et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International Journal of Computer Vision,2013,103(1):60-79.
[8] WANG H,SCHMID C. Action recognition with improved trajectories[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2013:3551-3558.
[9] SIMONYAN K,ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]//Advances in Neural Information Processing Systems. 2014:568-576.
[10] TRAN D,BOURDEV L,FERGUS R,et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015:4489-4497.
[11] HOCHREITER S,SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997,9(8):1735-1780.
[12] CHUNG J,GULCEHRE C,CHO K H,et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv:1412.3555,2014.
[13] DONAHUE J,ANNE HENDRICKS L,GUADARRAMA S,et al. Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:2625-2634.
[14] WANG L,XIONG Y,WANG Z,et al. Temporal segment networks:towards good practices for deep action recognition[C]//Proceedings of the European Conference on Computer Vision,2016:20-36.
[15] HE K,ZHANG X,REN S,et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778.
