使用计量数据和聚类算法检测非技术损失
2020-01-05矫真王兆军郭红霞郭红梅赵曦
矫真 王兆军 郭红霞 郭红梅 赵曦


摘 要:减少非技术损失(NTL)是实施智能电网所带来的潜在利益的重要组成部分。提出了一种基于智能电表数据的聚类算法来检测窃电和其他原因所导致的非技术性损失。通过对智能电表采集的数据进行聚类,提取正常用电行为的数据原型。然后对待检测数据样本和正常数据的聚类中心之间的距离进行计算,如果距离明显,则将其分类为NTL数据样本。最后对四种不同的异常用电指标进行空间分析,使分类结果更易于可视化。实验表明,基于GA聚类算法的NTL检测方法具有优于同类检测方法的性能。
关键词:智能电表;聚类;非技术损失
中图分类号:TP391 文獻标识码:A
Using Measurement Data and Clustering Algorithms to Detect NTL
JIAO zhen1,WANG zhao-jun2,GUO hong-xia2,GUO hong-mei3,ZHAO xi2
(1. Wucheng Power Supply Company,State Grid Shandong Electric Power Company,Dezhou,Shandong 253300,China;
2. State Grid Shandong Electric Power Research Institute,Jinan,Shandong 250000,China;
3. Jiyang Power Supply Company,State Grid Shandong Electric Power Company,Jinan,Shandong 251400,China)
Abstract:Reducing NTL is an important part of the potential benefits of implementing a smart grid. This paper proposes a clustering algorithm based on smart meter data to detect non-technical losses caused by electricity theft and other causes.By synthesizing the data collected by the smart meter,the data prototype of the normal power usage behavior is extracted. The distance between the test data sample and the cluster center of the normal data is then calculated,and if the distance is significant,it is classified as an NTL data sample. Finally,spatial analysis of four different abnormal power consumption indicators makes the classification results easier to visualize. Experiments show that the NTL detection method based on GA clustering algorithm has better performance than similar detection methods.
Key words:smart meter;clustering;non-technical loss
电网系统的非技术损失NTL(Non-Technical Loss)等于供电量减去用电量和线损、变压器等电力设备损耗之和。由于智能电表的日益普及,使得计量数据在用户端和电力计量系统之间实现网络传输,同时也拓宽了窃电行为的攻击面。通过电表黑客、计量数据操纵和通信欺骗等手段所实施的错误数据和不良数据注入攻击,给采用传统手段的NTL检测带来挑战。因此基于数据挖掘技术来检测NTL势在必行。
已有研究测试了多种基于数据分类和机器算法技术来检测NTL,如状态估计[1]、聚类[2]、神经网络[3]、支持向量机(SVM)[4]和决策树[5]。这些研究大多聚焦与通过数据挖掘来确定存在电力盗窃行为的可能,但是没有进一步对导致NTL的来源进行深入分析[6,7]。为此,提出了一种通过对智能电表计量数据进行聚类分析来发现NTL来源的方法。首先,从采集到的电表计量数据中计算出异常用电指标。其次,对一组正常电力用户的计量数据进行聚类分析,以发现正常用电行为的数据原型,这些数据原型代表了不同模式的正常用电行为。随后,基于距离检测方法将计算出的异常用电指标与正常数据原型进行对比。来自被分析电力用户的数据与正常数据原型的距离越远,其NTL得分越高,表明其可能为NTL数据点。最后通过实验验证了该方法在NTL检测方面的良好效果。
1 威胁模型
所提出的威胁模型能够检测可能的攻击载体和与智能电网窃电相关的主要系统漏洞。攻击载体指的是恶意影响电力系统,使其支付的电费低于其所使用的全部用电量。只要是导致智能电表发送给数据采集系统(SCADA)的计量数据发生变化或不正常的NTL都可以使用该模型加以识别。
首先对智能电网攻击面进行了分析。如果窃电行为、假数据攻击或设备故障等导致的NTL出现在NTL检测开始的第一天,则这种情况就被视为第一天NTL,否则就是非第一天NTL。考虑这种情况的原因是,在第一天NTL情况下,无法通过历史计量数据分析实现NTL检测,只能通过类似用户对比来发现该NTL行为。
用户端点所安装的智能电表具有通信功能,能够自动将计量数据发送到SCADA系统。智能电表的大规模部署会增加智能电网的安全漏洞,例如增加发送错误计量读数的可能性。不同的NTL来源和攻击载体如图1所示。带圆圈的点表示不同的可能的攻击载体。
通过对计量数据的分析,可以检测到NTL。所提出的处理方法导致消费模式改变或不规则的NTL类型(例如,如果消费者将用电设备连接到馈线前端则其计量数据将减少)。不同攻击载体所导致的计量数据变化或异常的情况如表1所示。
(1)供电馈线;(2)智能电表;(3)电表通信;(4)电力用户;(5)用户与电力公司的关系;(6)电力公司对数据的操纵;(7)电力公司的SCADA系统
通过诸如斜率分析和基于规则的系统等简单方法,可以检测出导致计量数据持续减少的情况,如电表断开或使用强磁铁干扰电表。如果窃电手段足够隐蔽,如发送看似合法的虚假计量数据,则使用上述数据分析手段则难以发现这些窃电行为。此外,如没有从窃电发起的第一天开始检测,则无法检测到计量数据的减少或异常,只有与类似的电力用户进行比较才能有效检测出这些窃电行为。
对表1的NTL类型进行总结,归纳出以下8种NTL窃电类型。其中每种窃电类型都有两个版本:第一天NTL和非第一天NTL,最终形成16种NTL类型的集合:1)随机减少计量数据(h1和h10为零);2)在一天中的随机时间段内(h2和h20),计量数据降至零;3)每小时随机减少计量数据(h3和h80);4)每小时计量数据呈现随机模式,但是平均计量数据减少(h4和h40);5)每小时计量数据恒等于平均值(h5和h50);6)反转小时计量数据:将第1个小时与第24个小时的计量数据进行切换(h6和h60);7)计量数据从高峰时间转移到一天中的其余时间(h7和h70);8)将消耗数据转移到具有较低电力需求的合法用户(h8和h80)。其中h1 ~ h8是非第一天NTL,而h10 ~ h70表示第一天NTL。
使用具有N个电力用户的智能电表计量数据集M。mi是用户i的电表读数。mi的维数是n = r × nd,其中nd是天数,r是每天的电表读数。电表读数是以小时为单位,因此每天有24个读数。电表读数表示为md,ti ,即用户i在第d天中第t小时的用电量。用户i在第d天的所有电表计量读数的向量形式为mdi = (md,1i ,md,2i ,…,md,24i )。
为了比较用户的相似度,使用了用户属性S的數据集。si是用户i的属性,其维数p等于属性数。用户属性包括年龄、就业、家庭人数等等。
描述第d天开始的影响用户i计量数据的8种窃电方式的数学模型如下所示。其中μ表示平均值函数。
1)h1(md,ti ) = αmd,ti ,α = random(0.1,0.8);
2)h2(md,ti ) = βh md,ti ,βt = 0,tstart < t < tend1,tstart ≥ t且t ≥ tend,
tstart = random(0,19),δ = random(4,24),tend = tstart+δ;
3)h3(mde,ti ) = γt md,ti ,γt = random(0.1,0.8);
4)h4(mde,ti ) = γt μ(mdi ),γt = random(0.1,0.8);
5)h5(md,ti ) = μ(mdi );
6)h6(md,ti ) = md,24-ti ;
7)h7(md,ti ) = md,ti - λmd,ti ,Pstart < t < Pendmd,ti + ε/21,eles,是三个小时内用电量峰值的开始时间Pend = Pstart + 3,ε = ■md,pstart+ j-1i ;
8)h8(md,ti ) = md,tr ,其中r为随机消费者,符合μ(md,tr ) < μ(md,ti )。
2 异常用电指标
当检测异常用电行为模式和当前未知的NTL威胁时,说明为什么用户会被标记对电力公司来说非常重要。为此提出四个异常用电行为模式指标,使所提出的检测方法更容易被理解和解释。
第一个类型的指标是用户个体用电量的变化。第二个类型的指标是用户个体与其他类似用户用电行为的比较。这两种类型的指标分别应用于累积电力消耗数据或每小时的电力消耗,则形成四个异常用电指标。
异常用电指标是根据用户i在某一天d的计量数据计算出来的。如果攻击发生在第d天,则用电行为模式的变化应反映在与过去相比用电行为的变化上。如果攻击在第d天之前就开始了,那么就应该与类似用电的用电行为相比。
所制定的四个异常用电指标表示如下:1)用电量变化指标Il表示当前用电量与过去用电量的比率;2)单位小时用电模式变化的指标I e2,I c2;3)与具有相似特征的用户相比的用电量差异指标I3;4)与具有类似特征的用户相比,单位小时用电模式差异的指标I e4,I c4。
用电量变化的指标I1是最近α天的用电量与最近β天的用电量之间的比率。
I1(i,d) = ■ (1)
每小时用电模式变化的指标I v2将一天的单位小时用电模式与前α天的平均每小时用电模式相关联。如果ν是欧氏距离(ν = e),则绝对用电量的变化与该指标最相关。如果ν是皮尔逊相关性(ν = c),则可以检测到动态变化。
I v2(i,d) = v(mdi ,μ(md-1-αi ,…,md-1i )) (2)
I3是衡量用电量差异的指标,用于比较在用户集合R中具有最大的相似性的用户r(r∈R)。该指标将最近α天的平均用电量与具有最相似特征的用户的同一天的平均用电量进行比较。电力用户r和i之间的相似性是由v(sr,si)计算的,其中v是欧氏距离。
I3((i,d) = ■ (3)
与具有最大相似性的电力用户相比,I e4和I c4是表示单位小时用电模式差异的指标。I v4表示最近α天所有用户平均每小时用电量。
I v4(i,d)=v(μ(md-αi ,…,mdi ),μ({(md-αr ,…,mdi )}))
(4)
3 检测方法
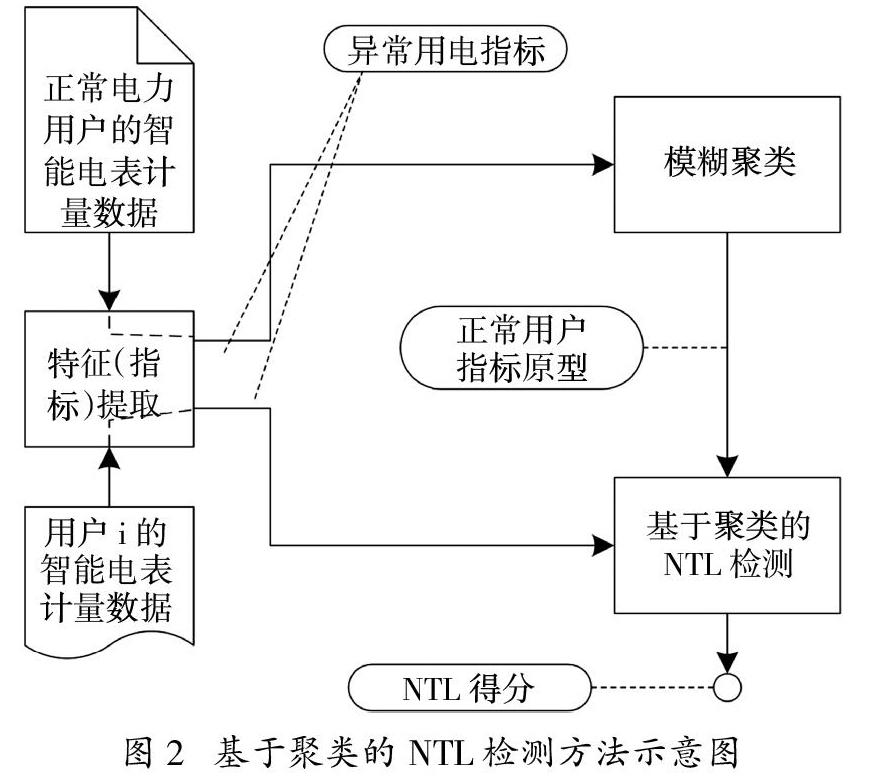
提出的NTL检测方法如图2所示。图2中的特征提取用于以异常用电指标来转换分析正常用电数据集和用户i的用电数据样本。将模糊聚类应用于正常的数据集,以产生表示“正常用电行为”的数据原型。基于聚类的NTL检测算法使用式(6)推断用户i的NTL得分。该得分是通过比较来自用户i数据样本和正常用电行为原型来完成的。以下详细说明如何基于异常用电指标,通过NTL检测算法推断用户的NTL得分。
3.1 NTL检测算法
NTL检测是通过对过去用电计量数据结构和分布的学习来检测新的计量数据样本。所使用的正常用电数据模型来自一组正常用电数据,通过该模型能够将输入的数据点分类为来自“正常”和“异常”。
本研究以NTL检测算法为框架,将从电力用户端点采集的计量数据分类为正常和异常(即NTL的来源)。NTL检测算法采用了一种基于距离的聚类检测方法。在基于距离的方法中使用一个或多个正常数据的原型,如果来自电力用户计量数据远离原型,则会导致其NTL得分较高。
3.2 基于聚类的检测
一般而言,不同的正常用电行为模式之间很大区别(例如,与退休夫妇相比,拥有全职工人的家庭在用电量、用电高峰等方面都会有较大不同)。因此需要使用聚类算法在电表计量数据集中提取不同的具有正常用电行为的数据原型。
Xid是在某一天d中与用户i相关联的特征向量。向量Xid = (I1,I e2,I c2,I3,I e4,I c4)由上述的8个异常用电指标组成。X∈R6是N个电力用户的属性数据集,由nd天的指标组成:
X=(x11,x12,…,x 1nd,x21,…,x 2nd,…,xN1,…,x Nnd)
(5)
采用模糊C聚类算法将分区X划分为C个集群Al…Ac。分区是由分区矩阵U = {uki}所定义,其中uki表示点i的属于集群k,称之为隶属度。每个聚类由原型或中心vk表示,维度等于数据点,所有中心点的集合为V。
聚类中心V代表正常用电数据,本研究对不适合任何C聚类的数据点赋予较高的NTL评分。在提出的检测方法中,对于某个数据点i,NTL得分 y(xid | V)等于其到聚类中心的最小距离,计算公式如式(6)所示。
y(xij | V) = ■d(xij,vk) (6)
y(xid | V)是第j天用户i的NTL得分。基于该分数使用阈值ζ进行二分类,当y(xid | V) < ζ时,用户不存在异常用电行为,为正常用户;如果y(xid | V) ≥ ζ则表明用户i 是NTL的来源。
該检测方法能够从一组从未用于提取正常用电行为原型的电力用户中对其计量样本进行NTL评分。聚类方法在一组正常用户空间中提取多个正常用电行为原型,然后用于与待检测用户进行比较。将电力用户的用电行为与正常用户进行比较,而不是与其自己的过去用电数据进行比较,因此能够检测到第一天NTL。下面介绍模糊GK聚类算法以及用于性能对比的其他聚类算法。
1)模糊C-均值聚类算法
模糊C-均值聚类算法(FCM)可迭代地最小化点与聚类中心之间的距离之和[8,9]。距离由点到每个集群的隶属度加权,并且模糊器参数m调整分区的“模糊性”。FCM一般使用欧氏距离作为其目标函数[10]。
J(U,V) = ■■(uij)m d2(xi,vk) (7)
λ2(xid,vk) = (xi - vk)T I(xi - vk) (8)
2)模糊Gustafson-Kessel聚类算法
模糊Guastafson-Kessel(GK)聚类算法使用模糊马哈拉诺比斯距离来代替欧氏距离[11]。
λ2(Xid,νk) = (Xi - νk)⊥ ∑ -1k(Xi - νk) (9)
∑k表示聚类的模糊协方差矩阵。这种差异性度量会导致椭圆形集群。不同的集群可以采取不同的形状。与FCM算法相比,GK算法在可以在数据中找到的集群的形状方面提供了更大的灵活性。模糊协方差矩阵使用下式计算:
∑k = ■ (10)
3)用于性能对比的其他聚类算法
将所提出的检测方法与以下检测方法进行性能对比:使用K均值(KM)和高斯混合模型(GMM)的检测方法、DBSCAN聚类和支持向量机(SVM)NTL检测方法。
KM聚类算法是FCM算法的模糊器m趋于1的一种特殊情况。GMM从训练数据中估计出一组分布的密度。使用期望最大化算法,通过最大似然拟合不同高斯分布的参数。SVM是一种常用的机器学习方法,主要用于数据分类[12]。
DBSCAN是一种基于密度的聚类算法。该算法将聚类定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为集群,并可在噪声的空间数据库中发现任意形状的聚类。基于DBSCAN的NTL检测方法将聚类中心 的集合替换为从正常计量数据集合中确定的核心点集合,于是用户的NTL分数与其数据到最近的正常计量数据核心点的距离成反比[13]。
3.3 NTL分数的应用
为了将检测方法给出的NTL分数应用于确定NTL来源,基于评估指标将得分较高用户的用电数据与正常数据原型进行分析。使用正常电力用户聚类的计量均值和归一化标准差作为NTL打分指标。归一化标准差Δ定义为:
Δl(xij | V,δ) = ■,k = argmink d(xij,vk)
(11)
式11中l表示一个异常用电指标,xij表示数据点,vlk表示正常数据原型,δlk是标准偏差来,k是最接近的聚类中心。
4 实验结果
4.1 数据集
所使用的实验数据来自大约四千个家庭用户,这些数据是在一年半(2017-2018年)内收集的,是国网公司科技项目进行智能电表试验的一部分。假设这些家庭用户不受威胁模型中考虑的NTL来源类型的影响。采集的数据包括每30分钟记录一次的用电量。实验以小时为基本单位对用电进行汇总,以方便使用本文所提出的检测方法。
实验在一组正常用电计量数据上训练所提出的检测方法,然后在另一组数据上对其进行测试。这些数据包括正常数据样本和为每个正常数据样本构造的16个合成NTL攻击。实验选择将用于训练和测试的用户分开,以减少结果的偏差。实验在每个季节随机选择5天的数据,按照以下步骤构造完整的实验数据集:1)每个季度随机抽取5个工作日;2)对于所有实验对象用户:生成威胁模型中由合成攻击产生的16条曲线;计算正常攻击和合成攻击的异常用电指标。
对家庭用户的年龄、社会阶层、就业状况、家庭中的成年人数量、儿童数量和家庭类型等属性进行调查以确定用户之间的相似性程度。本实验只使用没有任何计量数据或调查数据缺失的家庭,最终实验数据集由2515名家庭组成实验只对一半的消费者使用正常数据,对另一半使用正常和NTL攻击的合成数据,因此实验中的数据样本总数为:1258×5×4+1257×17×5×4=452540。实验数据集包括6%的阴性样本,这是由每个正常样本产生16个合成数据的结果。训练数据集根据提出的无监督分类方案的要求,呈现100%阴性数据样本的平衡。
4.2 参数
表2列出了用于计算的指标及其含义的参数。I1中的参数α的值为1,以表示在所考虑的威胁模型下可能发生的小的用电量变化。其余参数值范围为:β(I v2,I3),α(I v2,I v4)∈[1,5,10,15],τ∈[5,10,15,20]。找到的最佳配置是两组参数都等于10,这意味着将当前用电量与过去两周的用电量进行比较,并使用十个最接近的用电量进行比较。
通过对训练集和测试集中的数据进行随机划分,对所提出的方法和用于对比的不同技术进行了性能评估。训练集用于聚类和推导支持向量机模型,该模型由一组随机选择的用户(占用户总数的50%)的正常数据样本组成。其余用户(50%)用于性能评估。测试集呈现6%的负样本(来自正常用户),训练集呈现100%的非监督分类所需的负样本。使用以下评价指标:1)真阳性率(TPR):被识别为攻击的样本数除以所有攻击样本数;2)假阳性率(FPR):错误识别为攻击的样本数除以良性样本数;3)ROC曲線下方的面积(AUC):该曲线表示检测算法在TPR和FPR范围内的阈值。该指标对不平衡数据具有很强的适应性。
为了确定第4节所述方法和技术的最佳参数,使用AUC作为评价指标进行了参数搜索。参数搜索从值的集合中测试所有可能的参数组合:集群数量的取值范围在2到36之间,模糊参数m的取值范围为[0.5,0.6,…,1.9,2],v的取值范围为[0.1,0.2,…,0.9,1],γ的取值范围为[0.5,0.6,…,1.4,1.5],eps的取值范围为[0.5,1,3,6,12,24],mins的取值范围为[25,50,100,200,400,800]。表3列出了最终选择的算法参数。
4.3 结果与讨论
设置所有第一天和非第一天NTL、只有非第一天NTL和只有第一天NTL三种实验方案,对六种检测算法进行对比实验的结果如表4所示。
对表4的数据进行分析可知,在所有聚类算法中,GK的性能明显优于其他算法,而FCM和GMM的性能非常相似。对于非第一天攻击,FCM的性能最好,GK和KM稍差。对于第一天攻击,GK和GMM的性能类型。总体上GK聚类的整体性能较好。
在数据不平衡的情况下,仅有聚类准确度一个度量指标是不够的。例如,如果一个数据集包含95%的阴性类数据样本,而模型将所有样本都归为阴性,那么准确度仍然是95%。实际中用于检测NTL的数据集是不平衡的,即NTL数据样本只占少数。为此重新构造一个平衡的实验数据集(正常数据和异常数据之比为2:1),并基于该数据集对上述集中聚类检测方法进行重新测试。基于AUC指标的实验结果如图3所示。
在平衡数据集中所有算法的聚类数量统一为2(C=2)。由图4可知,除了GK算法,其他算法在平衡数据集中采用两个集群数量的测试结果都较差。这说明GK算法在数据集和聚类数量两个方面都具有较好的适应性。
4.4 应用测试
对所提出的检测方法进行应用测试。随机选择一个正常计量数据样本和一个h1类型的NTL计量数据样本。采用本检测技术给出的分数如图5所示。如果样本被归类为NTL,则条形图为红色;如果样本被归类为正常,则条形图为蓝色。如果分类正确,没有NTL的数据样本应该是浅色的,NTL数据样本应该是深色的。
(a)异常用电指标
(b)从样本到最近的聚类中心的指标值
(指标值越小表明数据越接近聚类中心)
正常样本的NSTD测试结果如图5所示。数据样本的指标值和平均值如图5a所示。正常数据样本接近大多数指标的平均值。其中I e2和I e4的值较低,因为这两个指标值代表了用户与过去和类似用户的用电差距。使用四种聚类检测方法所得出的到最近的聚类中心偏差的NSTD如图5b所示。除了I e2和I e4之外,GK聚类算法的指标值靠近聚类中心,这表明所使用的GK聚类技术能够更好地捕获正常计量数据集的形状。
h1类型NTL数据样本的NSTD测试结果如图6所示。与正常样本的平均值相比,图6a的I1和I3的值异常低,表明与过去和类似用户相比,用电量值显著减少。图6b表明,I1是NTL数据样本与最近中心之间距离增加的主要原因。
(a)异常用电指标
(b)从样本到最近的聚类中心的指标值
(指标值越小表明数据越接近聚类中心)
5 结 论
提出了一种检测智能电网中NTL的聚类检测方法。该方法通过对从智能电表收集的高分辨率计量数据进行聚类分析,得出NTL来源等的有效消息。该方法使用异常用电指标以减少数据的维数,并有助于实现检测结果的可视化。实验中使用了两千多个家庭的真实电表计量数据,涵盖了正常计量数据的多种可能的复杂变化。实验结果表明,该方法实现了高达0.741 AUC的性能,63.6%的真实阳性率和24.3%的假阳性率,优于同类研究中提出检测算法。下一步,将致力于把该方法应用于大数据和高性能计算框架中,以实现分析电网不同层级的损耗。
参考文献
[1] 李植鹏,侯惠勇,蒋嗣凡,等. 基于人工神经网络的线损计算及窃电分析[J]. 南方电网技术,2019,13(02):7-12.
[2] 李梓欣,李川,李英娜. 用电特征指标降维与极限学习机算法的窃电检测[J]. 计算机应用与软件,2018,35(12):179-186.
[3] 吴迪,王学伟,窦健,等. 基于大数据的防窃电模型与方法[J]. 北京化工大学学报(自然科学版),2018,45(06):79-86.
[4] 李宁,尹小明,丁学峰,等. 一种融合聚类和异常点检测算法的窃电辨识方法[J]. 电测与仪表,2018,55(21):19-24.
[5] 窦健,刘宣,卢继哲,等. 基于用电信息采集大數据的防窃电方法研究[J]. 电测与仪表,2018,55(21):43-49.
[6] 曹敏,邹京希,魏龄,等. 基于RBF神经网络的配电网窃电行为检测[J]. 云南大学学报(自然科学版),2018,40(05):872-878.
[7] 史玉良,荣以平,朱伟义. 基于用电特征分析的窃电行为识别方法[J]. 计算机研究与发展,2018,55(08):1599-1608.
[8] 王庆宁,张东辉,孙香德,等. 基于GA-BP神经网络的反窃电系统研究与应用[J]. 电测与仪表,2018,55(11):35-40.
[9] 邓明斌,徐志淼,邓志飞,等. 基于多特征融合的窃电识别算法研究[J]. 计算机与数字工程,2017,45(12):2398-2401.
[10] 康宁宁,李川,曾虎,等. 采用FCM聚类与改进SVR模型的窃电行为检测[J]. 电子测量与仪器学报,2017,31(12):2023-2029.
[11] 刘盛,朱翠艳. 应用数据挖掘技术构建反窃电管理系统的研究[J]. 中国电力,2017,50(10):181-184.
[12] 陈文瑛,陈雁,邱林,等. 应用大数据技术的反窃电分析[J]. 电子测量与仪器学报,2016,30(10):1558-1567.
[13] 赵磊,栾文鹏,王倩. 应用AMI数据的低压配电网精确线损分析[J]. 电网技术,2015,39(11):3189-3194.
