基于语义分割与深度估计的行车环境实时解析
2020-01-03
(同济大学 道路与交通工程教育部重点实验室,上海 201800)
0 引言
道路行车环境的感知与解析是车辆辅助驾驶与自动驾驶的关键技术,同时也是车辆进行判断和决策的基础。在目前实现道路行车环境感知的众多技术中,计算机视觉技术凭借其设备安装简单、操作方便的优点,一直以来都是研究的热点。它通过车辆前方摄像头获取的图像信息,利用设计的算法对图像中的场景进行语义分割和深度估计,实现行车环境的解析。
不过由于场景复杂、光线阴影变化大、物体遮挡等原因,使得语义分割和深度估计这两个基础的计算机视觉任务极富挑战。近年来随着深度学习的迅速发展,使得关于两个任务的研究取得了极大的进展。目前已经有不少学者提出实现语义分割和实现深度估计的神经网络,并且能达到良好的精度,但由于其网络结构过于庞大,导致模型计算量过大,无法达到实时计算和落地使用。针对该问题,不少研究者通过精简网络结构,减小网络的深度和宽度,希望能达到实时计算的目的。但由于网络结构的精简,导致了精度的下降,因此在实时计算和精度这两方面的权衡,成为了时下研究的难点。另外在道路场景的解析中,语义信息和深度信息缺一不可,目前大部分工作仍将二者当做两个独立的任务分别处理,导致在实时性上再打折扣。
考虑到语义信息和深度信息具有一定相关性,即相同的语义要素具有相近的深度信息,本文提出了一个轻量级的网络模型,同时完成语义分割和深度估计两个任务,并且实现端到端的训练与推测。在保持一定精度的情况下,实现实时计算(30 fps 以上)。本文的主要工作如下:
1)设计了一个轻量化、高效的特征提取模块。在保持模型精度的情况下,大大减少了模型的参数量,提高了模型计算速度;
2)设计了一个基于多尺度卷积和注意力机制的解码模块,用于捕捉特征间的语义信息或深度信息;
3)根据前两点设计的编码和解码模块,搭建了一个端到端实现语义分割和深度估计的神经网络,实现单个网络同时解决两个任务,并且达到实时性的要求。
1 相关工作
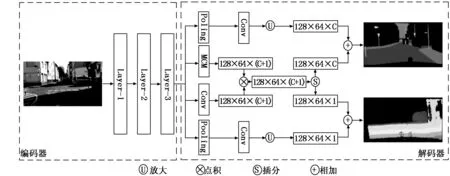
图1 网络结构图
语义分割是对图像中每一个像素进行分类的任务。文献[1] 开创性地提出了全卷积神经网络实现图像的语义分割,抛弃了后处理的步骤,使得语义分割结束了多阶段处理的时代,实现了语义分割端到端的训练与预测。在此基础上,文献[2-3]等网络提出了高效的深度卷积编码器-解码器框架,并通过编码器和解码器中部分网络结构层的直接连接,一方面使得网络的训练更加容易、提高网络的训练效率,另一方面使得解码器能够获得低阶的物体特征细节,从而改善物体边缘的预测效果,整体上提高了预测的精度。文献[4-5]等提出的空洞卷积和金字塔池化,增大了特征提取过程的感受野,考虑了图像中的上下文关系,进一步提高了预测精度。尽管上述网络能取得良好的分割效果,却是建立在结构复杂、模型庞大的神经网络基础上,无法满足实时性计算的需求。文献[6-7]等通过减少网络层数、减少特征图通道数目、精简网络结构等措施,在牺牲一定精度的情况下,将预测的速度提高到了30FPS以上。本文通过设计了一个高效的特征提取结构,减少了模型的计算量,在取得与文献[7]相近的精度下,将预测速度提高到了60FPS以上。
深度估计也是一个逐像素考虑的任务,旨在估计图像中每一个像素到观测位置的距离。文献[8]将深度估计作为一个回归问题,首先提出使用卷积神经网络估算图像深度。得益于CNN 强大的特征提取能力,针对单张RGB图像的深度估计研究涌现了诸多成果,相比于传统的方法,在精度上取得了长足的进展。在监督学习方面有文献[9-11] 等,无监督学习方面有文献[12-13 ]等,半监督学习方面有文献[14]。本文提出的模型与上述模型存在较大差异,一是在模型结构上做了精简优化,使得深度的预测速度能达到实时的效果; 二是模型不仅完成深度估计,同时也完成了语义分割任务,二者在模型训练时,能相互借鉴各自的信息,使得模型精度更高,泛化能力更强。
深度估计与语义分割的结合,一定程度上是基于二者任务特点的相似性和物体深度与语义的相关性,使得二者结合既能减少计算量,又能相互增益、提高精度。在深度估计与语义分割结合方面,文献[15]提出了一个递归处理语义信息和深度信息的网络结构,尽管能充分利用深度信息和语义信息之间的关系,但网络在深层时大量使用了大卷积核的卷积运算,导致计算量爆炸增长网络参数量更是达到350 M,导致无法达到实时计算的要求。在处理语义分割与深度估计两项任务的关系方面,本文提出的网络结构中,语义分割和深度估计任务共享了大部分的权重,使得模型能够捕捉二者之间的相关性;同时对于深度估计和语义分割,又有各自的注意力机制模块,使得网络能学习各自任务的差异性。在网络计算量和实时性方面,本文提出的网络结构能在保持一定精度的情况下达到65FPS的速度,模型参数仅为1.2 M。
2 模型结构
2.1 总体结构
模型的总体是一个编码器-解码器的结构,编码器用于提取图像的特征,解码器用于对提取到的特征进行处理,预测像素点所属的类别和深度。网络的总体结构如图1所示,输入的图片依次经过编码器和解码器,然后得到深度预测和语义分割预测的结果。
2.2 编码器
编码器部分共包含三个子层,每个子层由一个降采样单元和若干个改进的残差单元组成,各子层的组成分布如表1所示。随着层数的加深,改进的残差单元模块增加、输入的特征图尺寸减小、通道数目增加。

表1 编码器结构图
降采样单元。降采样单元设置的目的在于减小特征图尺寸同时增大通道的数目,从而达到扩大感受野和生成高阶特征的目的。文中所使用的降采样单元包含两个分支,一个是卷积核大小为3×3、步长为2 的卷积操作,另一个是池化大小为2×2、步长为2 的最大池化操作。这两个操作都能将特征图的大小缩小到原来的一半,达到降采样单元的目的之一——减小特征图尺寸。通过级联两个分支的输出,整个降采样单元输出的通道数则变成输入的两倍,实现了通道数的增加。
改进的残差单元。本文针对文献[16] 中提出的残差单元改进思路在于减少单元中的参数量和计算量,从而达到减少模型参数量、加速计算的目的。对于输入通道数为Nin、输出通道数为Nout、输出特征图尺寸为h·w、卷积核大小为fh·fw的卷积操作来说,参数量大小Np为:
Np=Nin·fh·fw·Nout
(1)
计算量大小No为:
No=Nin·fh·fw·Nout·h·w
(1)


图2 改进的残差单元结构图
另外在改进的残差单元左右两个分支中,会各自使用两个空洞卷积。空洞卷积相比于普通的卷积操作而言,能获得更大的感受野,提取得到的特征更具有全局性。对于语义分割和深度估计这种细粒度的任务而言,对单一像素的预测很大程度上可以借鉴于周围的像素点,因此当感受野较大时,提取得到的特征更有利于对像素点的语义和深度作出更准确的预测。
2.3 解码器
解码器的结构如图1所示,共包含两大部分。第一部分是中间两个分支,用于捕捉语义信息与深度信息的共同点。这两个分支分别是多尺度卷积模块(Multi-scale Convolution Module)分支和普通的卷积运算分支。两个分支输出的通道个数均为C+1, 其中C个通道为语义通道,1个通道为深度通道。由于深度特征和语义特征在一定程度上具有很大的相似性,一般而言具有相同语义的像素也具有相近的深度值。对于车、行人等交通参与者,其本身的深度和周围像素点之间会发生突变,而这变化可以通过语义的边缘捕捉到。因此,这两部分通道在分支内计算时,相互融合,从而达到捕捉语义信息和深度信息共同点的目的。两个分支的输出通过点积运算合并后,再将通道拆分成两部分,分别是包含C个通道的语义部分和包含1个通道的深度部分,再参与后续的计算。
多尺度卷积模块的结构如图3所示。编码器的输出依次进行了三个不同尺度卷积运算, 分别是7×7,5×5,3×3。不同尺寸的卷积感受野大小不一样,尺度大的卷积可捕捉距离较远像素间的语义和深度信息,尺度小的卷积则可捕捉距离较近像素的语义和深度信息,综合不同大小的卷积核,就能解析不同尺度的特征。不同尺寸卷积提取到的信息,均通过1×1的卷积操作进行特征的整合,而后小尺寸卷积分支的输出通过上采样与大尺度卷积分支输出相加,将不同尺度卷积提取到的信息融合,最终输出结果。总共有两次融合、三个上采样操作,得到和输入相同特征图大小和通道数的输出。

图3 多尺度卷积模块结构图
第二部分是旁路的两个分支,用于捕捉语义和深度各自独特的信息。分支上的操作依次是全局平均池化、1×1的卷积和上采样。语义分支输出了特征图大小不变、通道数为C的语义信息,深度分支输出了特征图大小不变、通道数为1的深度信息。
解码器最后融合两部分分支的输出,即综合考虑了语义和深度的相关信息和各自提取的独特信息,分别输出了模型的语义预测结果和深度预测结果。
2.4 损失函数
对于深度估计,我们使用文献[17] 中提出的损失函数,定义为:
(3)
式中,di是像素i预测值和实际值的差值,c为所有差值最大值的1/5,即c=max(di)/5。该损失函数对于差值较大的像素点,具有较大的梯度,使得模型在训练的时候,对于预测结果较差的部分,权重更新幅度更大,更有利于模型的收敛,加快了模型的训练。
对于语义分割,使用的是交叉熵损失函数,定义为:
(4)

(5)
3 实验结果与分析
3.1 实验设置
数据集本文实验所使用的数据集为Cityscapes 数据集[18], 包含了欧洲50个城市在不同季节、不同天气条件下的街道场景。其中语义标注数据包括19 个类别,深度标注数据为视差值。整个数据集共包含5 000张图像,训练集为2 975张,验证集为500张,测试集为1 525张。
评价指标语义分割结果采用的评价指标为平均交并比(mIoU, mean intersection-over-union),计算19 个类别的IoU的平均值,其中IoU的反映了预测区域和实际区域的重叠程度,是实际区域和预测区域的交集比上二者的并集计算方法如下:
式中,TP、FP、FN分别表示实际为真预测也为真、实际为假预测为真、和实际为假预测为假的像素点的个数。

对数空间均方根误差(rms(log)):
3.2 实验结果分析
定量分析如表2所示,在语义分割效果方面,本文取取了几个在语义分割任务重具有代表性的网络作为对比,如SegNet、ENet、PSPNet和ICNet。相比于SegNet,本文提出的网络不仅具有更高的分割精度,并且在计算速率上提升了四倍;相比于ENet,本文提出的网络在同样达到高实时性的基础上,在语义分割精度上提升了10.7%;相比于ICNet,语义分割的精度相近,但参数量更少,并在实时性上实现了翻倍;尽管精度不及PSPNet, 但在实时计算性能上提升了83倍。
在深度估计方面,各项评价指标均好于DepthNet。在深度估计与语义分割同时完成方面,本文提出的网络在语义分割和深度估计精度上均优于HybridNet,且能达到实时的效果。
定性分析图4是CityScapes测试集图片深度估计和语义分割预测结果的可视化。对比深度估计的真实值和预测值,可以发现算法能很好地捕捉场景中出现的行人、车辆等使空间距离分布发生突变的物体,这得益于网络中深度分割和语义分割共享的解码模块,使得在深度信息预测时,得以借鉴语义信息。对比语义分割的真实值和预测值,可以发现网络能将路、天空、建筑、绿化等环境要素和行人、车辆、非机动车、交通标志等交通要素完整且清晰地分割出来和ENet,并且在成块的分割结果中不会出现其他错误的分类。
整体而言,提出的网络在深度估计和语义分割任务中能达到良好的精度,并且能满足高实时性的要求,说明改进残差模块在参数量降低的情况下仍有很高的特征提取能力,整个编码器模块具有较高的编码效率;同时也说明了解码器能很好地解析出编码器提取的特征。特别是在语义任务中,无论是大物体还是小物体,都具有良好的分割精度,说明解码器中的多尺度模块能有效解析大小不同物体的特征,完成预测。
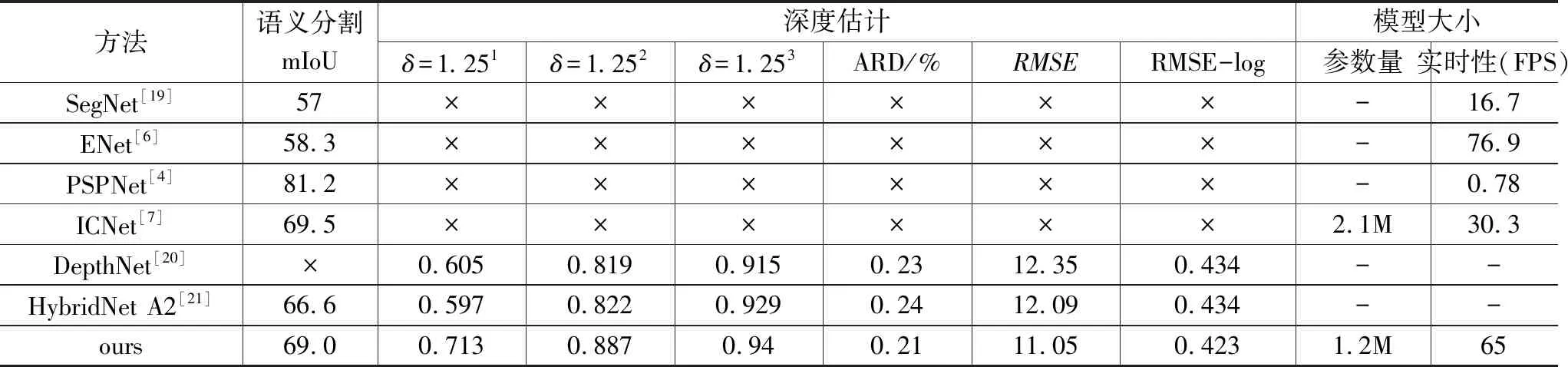
表2 实验结果对比表

图4 深度估计与语义分割结果
4 结束语
道路行车环境的实时解析是智能驾驶的关键技术,随着关于神经网络研究的迅速发展,在实现单目图像的语义分割和深度估计上已经能实现一定的精度,但仍存在模型参数多、计算量大、难以实时计算等问题,导致无法真正落地使用。针对该问题,本研究提出了一个轻量化、高效的特征提取模块和一个综合考虑语义信息和深度信息的特征解码模块,在一个网络中同时完成语义分割和深度估计两个任务。在CityScapes数据集中,语义分割预测结果的mIOU为65.0%、深度估计结果的误差为0.21, 并且在单个GPU 上推断速度达到了65 fps,满足实时性要求。
