基于多特征融合深度神经网络的作者识别系统设计
2020-01-03郭旭
郭旭
(大连外国语大学语言智能研究中心,大连 116044)
0 引言
随着人工智能时代的到来,使计算机“理解”文本的写作风格成为了自然语言处理领域的热点研究方向,而如何根据写作风格识别出匿名文本的作者,即匿名文本的作者识别,是这一研究方向主要解决的问题。在实际应用中,作者识别可以用于舆情分析、作者文体风格分析和学术不端检测等领域,具有重要的实际应用价值。
在给定一个匿名文本t和作者候选集A={a1,a2,…,an}后,匿名文本的作者识别要解决的问题是[1,2]:为匿名文本t指定一个最可能的作者a*,其中a*属于A。当使用作者书写的文本表征作者时,作者候选集A={T1,T2,…,Tn},其中Tx为作者ax书写的文本集,匿名文本的作者识别转换为:为匿名文本t指定一个最可能的文本集T*,也就是将匿名文本t分类给最可能的文本类别,属于典型的文本分类问题。
为了解决匿名文本的作者识别问题,文本设计完成了支持传统机器学习和深度学习的作者识别系统,该系统功能完备,不仅可以完成大多数主流机器学习算法和特征工程算法,还能以可视化的方式呈现识别结果。此外,本文采用的基于多特征融合深度神经网络的作者识别方法,可将特征工程与深度神经网络结合到一起,充分发挥两者的优势。
1 研究现状
目前,作者识别的研究方法主要有基于传统机器学习的方法和基于深度神经网络的方法两类。
基于传统机器学习的方法通过特征工程技术提取作者的写作风格特征,将一段匿名文本转换为作者写作风格特征矩阵,构建写作风格特征模型。如祁等人[3]使用包括句法结构树和依存关系在内的多层面文体特征,将作者文体风格转换为多层面特征模型,针对15位作者的10895篇博客进行识别,取得了较好的实验效果;李等人[4]使用复杂网络理论,将文本视作一个复杂网络提取路径长度等复杂网络特征,并与文本统计特征相结合,构建基于复杂网络的特征模型,针对多名记者撰写的25542篇新闻报道进行识别,也取得了较好的实验效果。
基于深度学习的方法通常将一句话或多句话直接作为输入,通过深度神经网络自主学习文本的写作风格特征,这样可以最大限度的保留句子之间的特征。基于深度学习的方法往往可以获得比传统方法更高的评价指标,但由于作者的写作风格特征是由深度神经网络自主学习得来的,因此深度神经网络提取的特征往往难以解释,这在一定程度上限制了基于深度学习的方法的实际应用效果。如Prasha等人[5]采用卷积神经网络识别Tweet短篇幅文本的作者,准确率高于传统方法6个百分点左右;徐晓霖等人[6]采用卷积神经网络与长短时记忆网络相结合的方法构建深度神经网络,针对新浪微博中的10位作者共计10000篇的微博进行作者识别,取得了较好的实验效果。
2 系统设计
2. 1 系统组成
作者识别系统的主要功能是识别匿名文本的作者,由数据集管理、文本预处理、自然语言处理、特征表示、传统机器学习、深度学习和可视化七个模块组成,如图1所示。
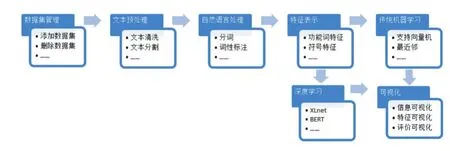
图1 作者识别系统模块图
(1)数据集管理模块。该模块主要负责候选作者文本集的管理,包括增、删、改、查候选作者文本集等功能。
(2)文本预处理模块。该模块主要负责文本的预处理,包括文本清洗、文本分割、文本联合等功能。
(3)自然语言处理模块。该模块主要负责文本的基本自然语言处理,借助斯坦福自然语言处理工具包[7]和Han自然语言处理工具包[8]等开源工具包设计完成,包括分词、词性标注、句法分析和依存关系分析等功能。
(4)特征表示模块。该模块主要负责提取文本的写作风格特征,构建文本的写作风格特征模型,包括功能词特征、标点符号特征和字/词N-Gram特征等。
(5)传统机器学习模块。该模块主要负责传统机器学习算法的实现,借助scikit-learn机器学习工具包设计完成,包括朴素贝叶斯、最近邻和支持向量机等算法的实现。
(6)深度学习模块。该模块主要负责深度学习算法的实现,借助TensorFlow和Keras等开源工具包设计完成,包括循环神经网络、卷积神经网络、带有注意力机制的深度神经网络、Transformer[9]、BERT[10]和XLNet[11]等算法的实现。
(7)可视化模块。该模块主要负责以可视化的形式输出作者识别的评价指标。借助Matplotlib工具包设计完成,包括文本集统计信息可视化、作者写作风格特征可视化、作者识别评价指标可视化等功能。
2. 2 系统流程
本文设计的作者识别系统,运行流程图如图2所示,包括5个步骤。
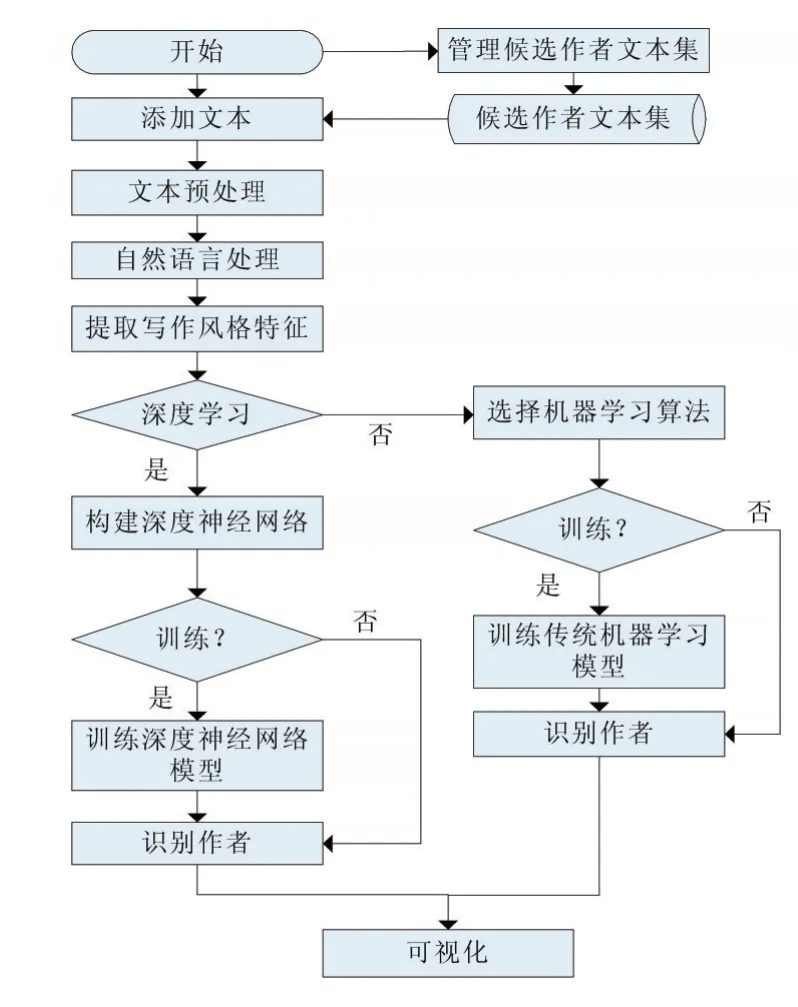
图2 作者识别系统流程图
(1)添加文本。选择添加待识别文本或从候选作者文本集中选择训练文本。此外通过数据集管理模块,可以管理候选作者文本集。
(2)文本预处理。清洗文本并生成样本。
(3)自然语言处理。选择需要进行的自然语言处理,包括分词、词性标注、分句、句法树分析和依存关系分析等。
(4)提取作者写作风格特征。包括字符统计特征、词汇统计特征和句子结构统计特征等。
(5)选择传统机器学习方法或深度学习方法。如果选择深度学习方法执行步骤①,否则执行步骤②。
①训练深度学习模型,并识别作者。
②训练传统机器学习模型,并识别作者。
(6)结果可视化。以可视化的形式,显示评价指标。
3 实验结果
本文选择13位作者共计31部作品构建候选作者文本集,作品包括小说、散文和网络文本三种体裁,其中,同一作者书写的网络文本按一部作品计算。小说和散文删除了首行缩进、标题和换行符、超链接等非作者原文中出现的特殊符号,网络文本删除了转发、@和超链接等内容,以求最大限度的保留作者的写作风格。本文按照512字长,将每部作品分割为多个文本块,每位作者随机抽取100个文本块,共计1300个文本块,作为候选作者文本集。
本文采用多特征融合深度神经网络的方法识别作者,与典型的深度神经网络方法相比较,该方法除了将完整的文本块作为输入外,还融合了字符统计特征、词汇统计特征和句子结构统计特征,具体如下:
字符统计特征:所有字符个数、中文字符个数、数字字符个数、字母个数、空符号个数、特殊符号个数、标点符号个数、不同标点符号个数。
词汇统计特征:所有词个数、词最大长度、句子最小长度、平均词长、词长方差、长词个数、短词个数、四字词个数、词汇丰富度。
句子结构统计特征:句子总个数、句子最大长度、句子最小长度、平均长度、句长方差、长句子个数、短句子个数。
本文采用5折交叉验证的方法,对候选作者文本集进行作者识别,平均识别准确率达到了89.6%。
4 结语
针对匿名作品的作者识别问题,本文设计了由数据集管理、文本预处理、自然语言处理、特征表示、传统机器学习、深度学习和可视化七个模块组成的作者识别系统,该系统支持传统机器学习和深度学习两类作者识别方法。最终,本文采用多特征融合深度神经网络的方法识别由13位作者,每位作者100个文本块组成的候选作者文本集,获得了89.6%的准确率。
