多节点系统异常日志流量模式检测方法∗
2020-01-02王晓东赵一宁肖海力迟学斌王小宁
王晓东,赵一宁,肖海力,迟学斌,王小宁
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
系统日志是由Linux 系统syslog 服务产生的日志,用于记录系统中发生的各类事件信息,在大规模系统中具有很重要的意义.中国国家高性能计算环境是由国内众多超算中心和高校的计算集群组成的国家级大型高性能计算环境,采用中国科学院计算机网络信息中心自主研发的网格环境中间件SCE[1]聚合了大量的通用计算资源,为全国众多高校和研究机构的用户提供了优质的计算服务.由于环境的系统中存在种类繁多的应用和服务,使得每个节点都会产生大量的系统日志,这使得最终的日志文件变得极为庞大,直接采用人工的方法处理这些日志显然是一项不可能的任务.而这些日志中往往包括各种异常现象的信息,为了从大量的日志中提取出这些异常的流量信息,我们需要使用一些异常检测方法对其进行分析.
传统的流量异常检测方法基于签名,这种方法有一个显著的局限性,它们的本质是利用以前出现过的攻击来过滤发现异常,即它们无法检测出可能会出现的新异常.此外,即使一个新的攻击被检测到了,对应的签名也得到了开发,但是该签名在网络上的部署通常会有延迟.这些限制使得基于机器学习的入侵检测技术越来越受到关注.基于机器学习的检测技术主要分为两大类:误用检测和异常检测[2].误用检测属于机器学习中的有监督算法,这种算法在使用时需要将所有训练样本标记为“正常”和“异常”,然后通过输入这些有标签的数据进行学习训练,更新模型参数.当新的流量特征输入时,就可以通过学习到的模型预测对应时刻的流量为“正常”还是“异常”.误用检测的主要优点是在检测已知类型的异常时具有很高的精度,但其缺点是无法检测未知的流量异常.而异常检测在使用时不需要提前得到数据的标签类型,属于无监督学习算法.其主要思想是:根据已知的大量数据进行模型建立,然后自动地从这些数据中找到偏离数据中心的少量数据作为潜在可能的异常.因此,此类异常检测技术可以自动地识别任何新的异常,但其缺点是可能出现误判的情况,即将正常的流量标记为异常.高性能计算环境中,多节点产生的日志复杂,内容丰富,迭代性强,因此使用无监督学习算法较为合适.
Vaarandi[3]提出了一个轻量级的、开源的、与平台无关的基于规则的事件相关的工具,称为SEC(简单事件相关器),并在文献[4,5]中描述了它的应用经验.该工具的主要思想是:通过写配置文件对日志中的不同日志类型进行匹配,然后通过匹配的类型出现顺序来进行模式判定.比如匹配出一条端口扫描的日志,随后匹配出一条防火墙生成的拒绝日志,则代表有人企图访问一台主机的一种流量异常.因此,不同类型的日志按照一定顺序出现,可能代表一种异常的流量模式.其不足之处是:所有配置文件都必须自己完成,对于不同的日志系统都需要修改配置文件.
本文在对日志进行分析时,首先自动地将日志分类,然后通过无监督异常检测方法得到异常日志类型的序列,并将这些序列所代表的异常日志流量模式进行聚类,最后分析结果并得出结论.本文的整体流程除了设定少量阈值外,得到异常日志流量模式的过程全自动化进行,这样使得系统管理员对系统日志流量的监控变得简单.
本文第1 节介绍相关研究内容.第2 节描述系统日志前期的分类研究和后续讨论中使用的数学符号.第3节对整体方法进行描述.第4 节设置实验并对实验结果进行分析.最后在第5 节进行总结和展望.
1 相关研究
本节简单讨论一下日志模式分类、日志后验分析以及日志类型序列度量的相关研究.
(1)日志模式分类
Vaarandi[6]对于日志文件数据展示了一种创新的聚类算法SLCT,该聚类算法基于Apriori 频繁项集,需要使用者提供支持阈值作为输入.这个支持阈值既要控制这些算法的输出,同时也是其内部实现机理的基础.之后,他又在文献[7]中改进了日志的聚类算法,得到名为LogHound 的算法.这一算法是一种基于广度优先搜索的频繁项集挖掘算法,用于从事件日志中挖掘频繁模式.该算法结合了广度优先和深度优先算法的特点,同时考虑了事件日志数据的特殊属性,因此比SLCT 更接近地反映Apriori 算法.SLCT 和Loghound 两种算法都将那些不匹配任何频繁模式的日志分类为离群值.Makanju 等人[8]引入了IPLoM 算法,这是一种用于挖掘事件日志簇的新算法.与SLCT 不同的是,IPLoM 是一种层次聚类算法,它以整个事件日志作为单个分区开始,并在3 个步骤中迭代分割分区.与SLCT 类似,IPLoM 将事件日志行中的位置视为单词,因此对单词位置的移位敏感.由于其分层性,IPLoM 不需要支持阈值,而是需要其他一些参数(如分区支持阈值和簇优度阈值),这些参数对分区的划分进行了细粒度的控制.IPLoM 相对于SLCT 的一个优点是能够使用通配符尾部(例如Interface * *)来检测日志行模式,其作者将IPLoM 算法与SLCT 和LogHound 算法进行比较,并得出其效果优于上述两种聚类算法的结论.此后,Vaarandi 和Pihelgas[9]提出了logcluster 算法,该算法对于文本事件日志进行数据聚类和日志行模式挖掘,并修复现有聚类算法的一些缺点.而本文使用基于字符匹配的分类算法,针对于国家高性能计算环境的系统日志进行分类,代码压缩率和后续特征创建都显示出了不错的效果.
(2)日志后验分析
一些学者在分析日志寻找相关异常方面进行了研究,比如,Xu 等人[10]通过源代码匹配日志的格式找出相关变量,通过词袋模型提取对应日志变量的特征,然后使用这些特征,通过主成分分析方法降维,根据主成分分析的最大可分性检测异常的日志文件,最后使用决策树可视化该结果.Fronza 等人[11]使用随机索引为代表的操作序列,根据其上下文为每个日志中的操作特征化,然后使用支持向量机关联序列到故障或无故障的类别上,以此来预测系统故障.Weiss 等人[12]研究了从有标签特征的事件序列中预测稀少事件的问题,基于遗传算法的机器学习系统,能够在预测稀有任务上达到比较好的结果.Yamanishi 和Maruyama[13]提出了一种新的动态系统日志挖掘方法,以更高的置信度检测故障症状,并发现计算机设备间的连续报警模式.Yuan、Mai 和Xiong[14]提出了一个名为Sher-Log 的工具,它利用运行时日志提供的信息来分析源代码,以推断在失败的生产运行期间必须或可能发生的事情.它不需要重新执行程序,也不需要知道日志的语义.它推断关于执行失败的控制和数据值信息.Peng、Li 和Ma[15]应用文本挖掘技术将日志文件中的消息分类为常见情况,通过考虑日志消息的时间特性来提高分类的准确性,并利用可视化工具来评估和验证用于系统管理的有趣的时间模式.Wang[16]也使用机器学习方法对日志进行后验分析,但是主要突出的是日志线上的可视化展示.本文使用文献[10]中描述的异常检测方法,但是输入的日志类别对应于基于字符匹配生成的分类结果,同时,研究对象为日志类型的有序排列,在得到未知的异常日志流量模式上更有优势.
(3)日志类型序列度量的研究
日志类型序列的分类问题,实际上可以归类为字符匹配模式.在字符匹配中,为了判别两个序列的相似度,Hamming[17]在对两个字符串之间进行比较时使用了最直接的一对一匹配法,以两个序列匹配的字符数目作为两个序列之间的相似度衡量指标.Damerau 和Levenshtein[18]使用两个序列之间的最小操作数(包括序列的插入、删除、替换或两个相邻字符之间的转换)作为两个序列之间的相似度衡量指标.在序列对比方面,Needleman[19]和Smith[20]分别对序列进行全局对比和局部对比,用以得到最符合两个序列的全局序列和局部序列.本文在选择日志序列特征时考虑到了字符串序列的特点.根据Seker[21]在字符串匹配算法中对人名字符度量上选择的方法,即前K个频繁出现次数的字母项和其对应数量作为识别序列的关键要素.将不同类型的日志抽象为不同的字符,根据其特点实现自适应K值的挑选,在日志类型序列的比较上更为适合.
2 背 景
2.1 系统环境日志前期分类研究
日志预处理需要完成的主要任务是如何将日志内容压缩并分类,这样做既可以减少数据量,又有利于后续使用相关机器学习算法进行分析.我们在前期工作中,使用了一种基于字符匹配的方法对系统日志的分类问题进行研究,主要方法是根据字符匹配原则对系统日志进行分类[22].日志模式匹配的核心思想是字符一一对应,即:将整体匹配的字符数与总字符数进行比值,并将得到的数值与设定的阈值进行对比,如果结果超过设定的阈值,则将这两行日志定义为一类[22].
我们在对日志类型进行字符对比分类时,为了减少分类的模式,在字符匹配时引入了最长公共子序列的概念[23],这样使得计算时得到的匹配模式大量减少.得到分类结果后,可以验证日志的压缩率达到99%以上.
2.2 后续内容中基本符号解释
后续系统设计和分析时,我们为了简化讨论,将定义一些数学符号,具体解释见表1.

Table 1 Mathematical notation and interpretation表1 数学符号与解释
3 方法结构
为了适应高性能计算环境下出现的流量异常检测问题,我们根据系统中产生的日志特性,选择适当的预处理和无监督机器学习算法来对系统日志的分析过程进行整体的构建与规划,设计出一种异常流量模式检测的方法,该方法的结构主要包含3 部分:预处理模块、异常处理模块、分类模块.各部分的功能简述如下.
(1)预处理模块:根据日志匹配算法对输入的大量日志进行分类,输出日志类别文件;
(2)异常处理模块:根据输入的待分析日志以及上一步得到的日志类别文件,使用基于主成分分析的异常检测方法,得出异常的时间片内不同节点的异常类型序列;
(3)分类模块:根据输入的大量异常类别序列,使用基于最长公共子序列的距离度量进行层次聚类,得出不同的异常日志流量模式.
根据各个功能的作用,我们得到日志整体结构图,如图1 所示.

Fig.1 Flow chart of log overall structure图1 日志整体结构流程图
3.1 预处理模块
异常流量模式检测方法进行预处理的目的是将日志类型记录在本地的日志类型仓库中,以便后期分析.日志类型提取的具体方法[23]是读取一行日志,并与日志仓库中的日志类型逐一进行比较.设该条日志l包含n个单词,日志仓库中取出的待比较日志类型l′包含m个单词,则定义l与l′的相似度为
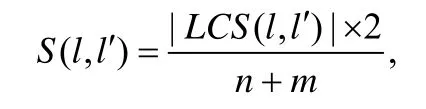
其中,|LCS(l,l′)|表示l与l′的最长公共子序列的单词数量.计算出S(l,l′)后,即可将该值和预定义阈值t(0<t<1)进行比较:如果结果小于该阈值,则将该类型加入到日志类型仓库中;否则,读取下一条日志进行比较.其处理流程如图2 所示.

Fig.2 Flow chart of preprocessing module图2 预处理模块流程图
需要指出的是:预处理模块分析的对象是所有待分析的系统日志,并根据这些日志进行模式匹配,得到不同的日志类型,然后根据这些日志类型建立日志仓库.其目的是化简日志类型的维度,本身并没有过滤掉任何待分析的日志.在后续进行实际流量分析时,可以将每个时间片内出现的日志与日志仓库中的日志类型进行对比,抽象出不同类型的日志在对应时间片内出现次数的一个向量,以利于使用相关机器学习算法进行分析.
3.2 异常处理模块
日志的异常处理输入需要用到上一小节得到的日志类型.我们首先根据日志仓库中不同日志的类型生成日志类别文件,然后基于该日志类别文件,将需要具体分析的日志文件进行特征创建,得到日志时间片向量,之后根据待分析日志的格式特点将日志文件的每一行数据按照数据表的格式存储,得到结构化的日志数据,最后将上述得到的3 个文件加载,并使用无监督异常检测方法进行分析,即可得到对应具有异常流量特征的时间片.具体实现方法如下.
(1)特征创建
我们首先在内存中加载待分析日志,然后根据日志的时间计算出时间戳,在得到时间戳后,即可根据时间戳的大小将日志按时间顺序进行排序,并根据实际情况把日志按照给定的时间片进行拆分,每一个时间片可以作为一个样本的输入向量.该向量的每一个维度代表一种类型的日志,而其对应的数值等于该类型在当前时间片段内出现的次数.例如:如果取时间片为5 分钟,并且假设在t1时间片内得到的日志可见表2.

Table 2 Log in t1 time slice表2 t1 时间片内得到的日志
根据该时间片内不同类型日志出现的次数,可以得到的样本输入向量见表3 中的t1行.
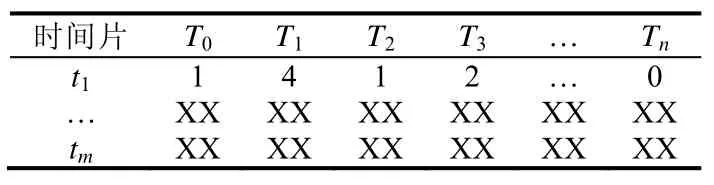
Table 3 Log type’s vector of time slice表3 时间片日志类型向量
表3 代表待处理日志经分析后得到的输入矩阵,其中,n代表预处理模块中使用日志模式匹配得到的日志类型数量,m代表待分析日志按照固定时间片分割的时间片个数.假设待分析日志的总时间跨度为T,则可得到.根据上述方法即可将待分析日志转换为m行、n列的数据矩阵,该矩阵每行代表一个样本数据,每列代表一个样本的特征段位.
(2)基于主成分分析的流量异常检测
主成分分析是一种常用的机器学习算法,该算法在推导过程中使用了最近重构性原理,即:将高维的数据映射到低维空间中,使得每个高维空间中的数据映射到低维空间后的距离之和达到最小.这样做使得原始数据投影到低维空间时的距离最小,所以当找到这个最近重构的低维空间后,计算出原空间样本点到低维空间的距离,该距离即可以作为异常与否的度量标准.即:该距离越大,原来数据更可能是异常数据.该方法的具体实现步骤如下.
步骤1 将m行n列的数据矩阵A输入,将所有数据中心化得到矩阵B.
步骤2 解得BTB的特征值λi(i=0,1,…,n).注意:这里需要自己选择降维后的方差比重,这里我们选择90%为方差比重.带入计算使得>90%.
步骤3 将得到数值最高的k个特征向量V1,V2,…,Vk组成矩阵P=[V1,V2,…,Vk],计算该矩阵的正交投影矩阵为VP=P(PTP)-1PT=PPT.
步骤4 如果原来的向量为y,则该向量到其映射的子空间的欧几里德距离可以通过计算平方预测误差SPE=||ya||2得到.注意:其中,ya是y到异常子空间sa上的投影,并且可以通过式子ya=(I-VP)y=(I-PPT)y计算得到.
步骤5 根据上述算法计算出每一个点到子空间的距离,将其与检测阈值Qα进行比较:如果SPE=||ya||>Qα,则标记y是异常的.其中,Qα表示在(1-α)置信水平下SPE 残差函数的阈值统计量.基于主成分分析检测的方法来源于文献[10],其检测的异常数值Qα可用如下公式得到[24]:

公式中的λj代表样本数据协方差矩阵第j个主成分投影在子空间的特征值.Cα表示标准正态分布的1-α百分位数.
上述方法进行异常检测的基本原理是:系统在产生不同类型的日志时,在正常情况下,各个类型日志出现的比例趋于稳定.如果各个类型日志在某些时间段内出现大量的比例失衡的情况,则很有可能在这个时间片内有异常的情况发生,则这些时间片段需要重点关注和分析.
3.3 分类模块
日志异常模式是由不同类型的日志有序连接而成的.单个节点的异常日志流量模式可定义为日志类型的有序排列.单独一种日志类型的出现并不能说明什么问题,比如单独出现一次T7(认证失败)类型的日志,可能是由于用户不小心密码输入错误引起的.但是如果在一定的时间片内,同一个主机频繁出现T7(认证失败)类型日志、T11(密码错误)类型日志、T3(连接断开)类型日志,则说明该类型序列可能是一种暴力破解登录的尝试.因此,异常模式提取的思想就是在异常时间片内找到同一个主机产生的日志类型的关联规则,然后得到异常日志流量模式.
(1)异常流量筛选
将日志时间片向量带入上一小节中介绍的方法,即可得到日志流量中对应的异常时间片.我们统计出正常、异常时间片中不同类型日志出现数量的分布,计算出其对应正常、异常日志和出现数量的中位数来进行后续比较.根据比较的差值来得出正常、异常时间片主要差异的日志类型.
为了将时间片内所有的日志类型序列得到,我们单独将每个异常时间片进行抽离.对于每个单独的异常时间片,根据不同节点将对应的日志类型序列记录下来.比如某个时间片内出现了异常,我们将时间片内的全部日志提取出来,根据这些日志数据得到所有节点名,之后根据节点名单独挑选出每个节点在对应时间片内的所有日志类型,组成一个日志类型序列.这些序列中有许多并非异常流量的数据,因此我们根据两个规则进行异常类型序列的筛选,具体规则如下.
A 该主机日志数量超过给定阈值HTN(host threshold number);
B 该主机日志的类型包含前面检测出的主要差异的日志类型.
选择机制A 的主要原因是:如果时间片内出现的日志数量比较少,则说明该节点并没有发生流量异常现象,因此可以不予考虑.选择机制B 的主要原因是,根据正常异常类型分布得到的是最能区别出正常与异常的日志类型.
例如:检测出的某一个异常时间片内出现的日志见表2,则根据节点名得到3 个不同的日志类型序列:Node1产生的序列S1=T1,T3,T1,Node2 产生的序列S2=T0,T2,T1,Node3 产生的序列S3=T3,T1.假如设定的阈值为HTN=2,根据中位数得到的异常比正常多的日志类型为T3,则根据过滤规则A 将会把S3过滤掉,根据过滤规则B 将会把S2过滤掉,这样过滤后留下的日志类型序列是S1.
使用这两种过滤机制筛选后,依然可以得到大量的异常流量类型序列.其中,各个序列之间有大量重复的流量序列特征,因此需要对这些日志类型序列进行模式分类,建立异常日志流量模式库.
(2)基于最长公共子序列距离度量的层次聚类方法进行异常流量分类
层次聚类法是一种基于距离度量的聚类算法,其特点是可以根据距离阈值的变化得到原始数据的分类数目,因其显示效果和解释效果好,而在机器学习中非常常用.我们使用基于最长公共子序列的相似度算法对两个日志类型序列计算距离,然后将上一小节得到的大量异常流量类型序列进行层次聚类.使用最长公共子序列度量两条日志类型序列,是因为日志类型的有序排列可以决定一个节点的异常日志流量模式.在实际运算时,我们认为最长公共子序列匹配的日志类型数目越大,则代表两条日志序列匹配的效果越好.为了使得两个类型序列的相似度越高,距离越近,我们以如下方法定义两条日志类型序列的距离.
设两个待比较日志类型的序列为S1和S2,通过最长公共子序列得到匹配的类型序列为S,则距离计算公式为

例如,有两条日志类型序列分别是S1=T7,T11,T7,T11,T3,T2,T1和S2=T7,T11,T7,T11,T2,则对这两条日志类型序列进行最长公共子序列比较后的结果见表4.
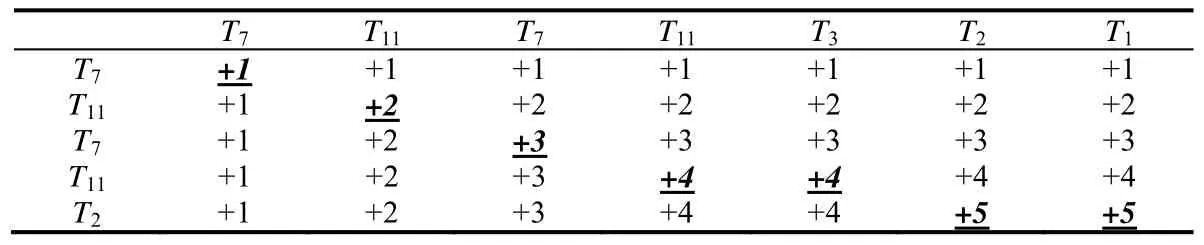
Table 4 Comparison results of the longest common subsequence表4 最长公共子序列比较结果
可以看出,得到的匹配序列为S=T7,T11,T7,T11,T2.根据上述公式,我们可以得到当前变量:|S1|=7,|S2|=5,|S|=5,则计算得到这两个序列之间的距离为.
3.4 基于自适应K项集的标准进行类别选择
层次聚类中,我们选择的距离度量仅能计算出两条日志类型序列的距离,但无法将任意一个日志类型的序列映射到向量空间,这样就无法通过求日志类型序列的几何中心得到中心位置的日志类型序列.因此,我们需要从其他角度来处理这个问题.
日志类型序列可以看成字符串数据.Seker[21]在使用字符串匹配算法匹配人名时,通过选择人名中前K个频繁出现次数的字母项和其对应数量作为识别人名的关键要素.我们也可以使用相似的方法来确定日志类型序列的中心位置和单条日志距离其中心位置的距离.即,将同一种异常日志流量模式中所有出现的日志类型数量的平均值作为该异常日志流量模式的中心数量.在寻找最靠近中心数量的日志类型序列时,考虑到日志序列类型较多,数量分布不均匀的特点,因此不适合使用原文中固定K值法对序列进行比较.在实践中,我们提出一种自适应K值的算法,该算法在计算不同类型日志中心距离时,采用了平均流量的数值进行比较,而对进行比较的类型数目K的选择采用如下公式:
K=CountIf(AverageNumx>AverageTotalNum×Threshold),x=1,…,n.
AverageNumx代表第x类型日志在该异常日志流量模式中出现次数的平均值,AverageTotalNum代表所有类别日志在该异常日志流量模式中出现的平均值之和,Threshold代表异常百分比阈值.在实际操作时,我们将Threshold取值为.这样选择是因为在异常流量筛选时,我们确定的日志数量阈值为HTN,即保证了筛选出来的每条日志异常流量所包含的日志数目大于HTN.因此,设定就保证挑选出的前K个频繁类型的日志数量至少超过1 条.因为如果一种类型的日志数量低于1 条,则显然为不频繁类型.日志数目超过1条证明如下:

在确定K值后,即可根据平均流量计算每条日志模式序列与中心流量之间的距离,第m个日志类型序列与中心之间的距离公式为

其中,AverageNumi代表第i种类型日志在该日志类型序列集合中出现数量的平均值,TypeNummi代表第m个序列中第i种类别日志出现的数量.根据距离公式将所有距离值计算出来后,将所有序列计算的d值中结果最小的序列作为该类型异常流量的特征序列代表.
假设上一小节聚类后得到的m类异常日志流量模式记为{Y1,Y2,…,Ym},第m类异常日志流量模式Ym包含的日志类型序列的集合记为,则自适应最大k项集算法具体步骤如下.
步骤1 读取第w类日志流量模式的全部日志类型序列集合Yw=;
步骤2 统计Yw包含的所有日志类型{Tw1,Tw2,…,Twt};
步骤4 得到前K种频繁日志类型∈{Tw1,Tw2,...,Twt},满足在集合Yw包含的日志类型序列中出现数量的平均值大于阈值AT;
步骤5 根据公式dm=计算所有序列对应的距离{d1,d2,…,dnw};
步骤6 得到最小距离dxw=argmin{d1,d2,…,dnw}对应的序列Sxw即为该异常日志流量模式NMw;
步骤7 返回步骤1 并重复,直至得到所有异常流量模式NM1,NM2,…,NMm.
4 实验结果与分析评价
本节我们将第3 节介绍的方法用于国家高性能计算环境系统在实际工作中产生的系统日志中.我们选取其系统日志的secure 类别日志作为数据输入.在日志分类时使用了2017 年7 月~2017 年12 月的日志进行分类,得到了84 种类型的日志.考虑到日志在每天不同的时间段产生的异常日志流量模式的不同,因此我们将日志按照3 个时间段分段,即白天、晚上、深夜(参见表1).我们将时间片跨度设定为5 分钟,然后按照上一小节介绍的方式得到输入矩阵并进行测试.
4.1 日志异常检测和筛选的分析评价
本小节我们使用第3.2 节中介绍的基于主成分分析的异常检测技术对实验日志进行检测,得到各个时间片的Q值并与模型的阈值Qα进行比较,从而得到异常时间片.各个时间片的Q值和阈值Qα如图3 所示.

Fig.3 Q-value and threshold Qα figure of secure logs图3 Secure 类型日志的白天模型Q 值和阈值Qα图
从图3 可以看出,异常类型时间片均匀地分布在整个日志周期时间片内.根据得到的异常时间片,我们可以统计正、异常时间片内不同类型日志的中位数的差异,经过实验分析,异常比正常时间片内日志类型的中位数差值为1 进行区分,即可达到很好的过滤效果.通过该差异,我们进行了第1 步过滤.第2 步过滤使用基于数量的过滤,实际过滤时我们取主机阈值数HTN=10 即可达到很好的过滤效果.根据这两条规则进行筛选后,最后得出的所有异常流量数目见表5.

Table 5 Number of abnormal flow and its filtered表5 异常流量与过滤后的数目
由表5 可以看出:通过我们的异常检测方法和过滤规则,使得大量的流量片段数据压缩成少量的日志类型序列,大大降低了后续分析的难度.
4.2 日志层次聚类和关键类型挑选的分析评价
本节介绍由上一小节得到的大量异常日志流量序列按照第3.3 节的方法进行层次聚类的相关实验.使用层次聚类时有两个关键参数需要定义:一是不同数据之间的距离度量方法,二是不同簇之间的距离度量方法.不同数据之间的距离定义我们按照第3.3 节中介绍的距离公式进行计算,而不同簇间距离度量方法具有多种不同的选择.在实验中,我们先使用不同簇间距离度量方法进行计算,然后根据结果计算其对应的共表性相关系数(cophenetic correlation coefficient)[25]来进行评价.共表相关系数越大,表明效果越好.我们使用半年secure 类型日志的白天模型进行计算,得到不同的簇间距离计算方法对应的共表相关系数,见表6.

Table 6 Cophenetic correlation coefficient obtained by calculating the distance between different clusters表6 不同簇间距离计算方法得到的共表相关系数
根据表6,我们选择使用基于平均值距离标准方法进行簇间距离的计算,因为该方法对应的共表相关系数为最大值0.55.最终得到的层次聚类图如图4 所示.

Fig.4 Hierarchical clustering of the secure logs’ daytime sequence图4 Secure 类型日志白天序列的层次聚类图
通过图4 可以看出:所有数据在横坐标为1~3 内大量且迅速地聚集,之后趋于稳定.因此,选择层次聚类的距离度量的阈值大致在相对较高的位置.在实际计算时,我们选择的阈值为3.5.使用该值进行层次聚类得到的聚类结果既可以保证类别较少,又可以使得每个小类别的聚集程度比较高.按照该阈值,我们将半年的secure 日志早、晚、夜数据分别进行层次聚类,得到日志流量类型序列.之后使用第3.4 节中所描述的自适应K项集的方法进行类别选择,得到3 个时间区间内日志异常类型序列的代表.结果得到的前K项类别数量平均值以及对应的K值见表7.其中,距离几何中心最近的日志异常类型序列比较长,这里就不再罗列.

Table 7 Table of secure logs’ sequence表7 Secure 日志类型序列表
由表7 可以看出,使用半年secure 类别日志产生的类型序列根据白天、晚上和半夜分别生成了5、3、3 类的异常序列.我们将这11 条异常序列继续进行层次聚类,结果如图5 所示.根据该图可以看出:白天的模式代表包含了大部分夜晚和半夜的模式代表,在满足将所有原本模式代表都分开的前提下,一共可分为7 种异常日志流量模式,见表8.
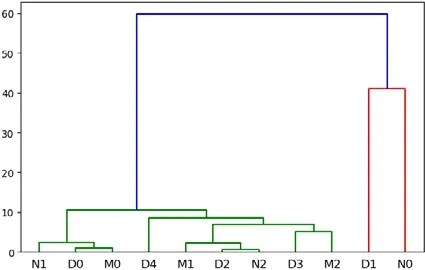
Fig.5 Hierarchical clustering of type sequences of secure log in day,night,and midnight图5 Secure 类型日志的白天、晚上和半夜代表类型序列的层次聚类图
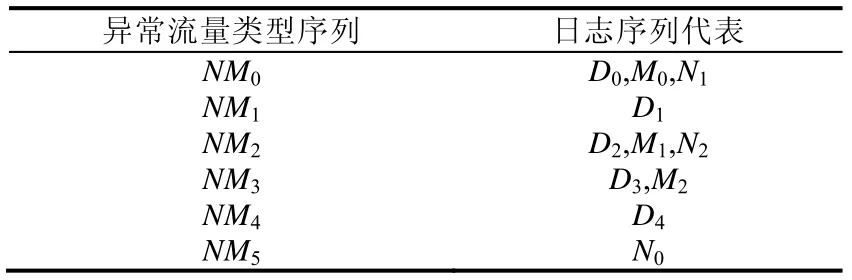
Table 8 Table of sequence type of secure logs表8 Secure 日志序列类型表
我们将找出的6 大类异常日志流量模式NM0、NM1、NM2、NM3、NM4、NM5序列对应的日志类型代表D0、D1、D2、D3、D4、N0的各个类型数量绘制的梯形图绘制出来,结果如图6 所示.

Fig.6 Type number trapezoid diagram of secure logs图6 Secure 型日志的类型数量梯形图
根据图示,我们可以分析以下异常流量情景.
· 情景0:流量序列中占据异常最重要比重的日志类型是T11(failed password for invalid user 0000 from〈IP〉 port 〈PORT〉 ssh2)和T7(pam_unix(sshd:auth):authentication failure).该种异常日志流量模式表明,此时间段内可能有人进行暴力破解密码的行为;
· 情景1:流量序列中占据异常最重要比重的日志类型是T11(同上)和T6(pam_unix(sshd:auth):check pass;user unknown).该种异常日志流量模式表明,此时间段内出现大量登录的行为,并且检测通过了,说明系统密码可能已经被攻破;
· 情景2:流量序列中占据异常最重要比重的日志类型是T7(同上)和T2(pam_unix(sshd:session):session opened/closed for user).该种异常日志流量模式表明时间段内会话数量突然增多;
· 情景3:流量序列中占据异常最重要比重的日志类型是T1(connection closed by 〈IP〉)和T11(failed password for root from 〈IP〉 port 〈port〉 ssh2).该种异常日志流量模式表明,此时间段内可能有人进行暴力破解密码的行为;
· 情景4:流量序列中占据异常最重要比重的日志类型是T1(同上)和T28(usr1:TTY=pts/0; PWD=〈PATH〉;USER=root; COMMAND=/bin/tail -f/var/log/messages).该种异常日志流量模式表明,该时间段内用户使用的命令突然增多;
· 情景5:流量序列中占据异常最重要比重的日志类型是T11(同上)和T7(同上).该种异常日志流量模式与情景1 相同,但是出现的数量比情景1 高出很多.
需要指出的是:由该方法得出的日志流量异常模式仅代表由机器辅助分析得出的流量异常情况,并不等同于该时间片内发生了实际的用户非法行为或系统错误.具体是否存在需要处理的异常状况,仍需要人工判断.但该方法可以自动缩小异常状况的观测范围,极大地减小了人工处理所需的工作量.
4.3 算法效率方面的分析评价
本小节统计出进行日志异常检测算法时在早、晚、深夜这3 个不同时间段的不同操作中各个步骤所用的时间,并对结果进行分析与对比.上述讨论中,半年的日志数据在不同时间段进行检测时各个阶段所用时间详见表9.

Table 9 Time spent in each stage of the test in different time periods表9 不同时间段在进行检测的各个阶段所用时间
由表9 我们可以分析得出如下结论.
(1)通过总时间的纵向对比我们可以发现,本文系统在处理白天产生的流量数据所用的时间明显多于晚上和夜里.这说明从总体来看,白天访问高性能计算环境的人数较多,进行的操作也较多,因此容易出现异常流量;
(2)通过不同检测阶段的横向对比我们可以看出,层次聚类步骤消耗的时间较多.因为层次聚类算法本身的时间复杂度是O(n2logn)(这里的n代表待聚类序列的数量),同时,我们选择的距离度量基于最长公共子序列算法,该算法仅需得到子序列长度,无需构造出最长公共子序列,其时间复杂度是O(mn)(这里的m和n分别代表待比较的两个序列的长度).根据以上分析我们可以看出,层次聚类模块处理流量数据时受到待分析日志的数量以及每个流量序列的长度影响较大.对比白天和晚上层次聚类算法的占比也可以看出:当总时间较长时(白天>晚上),层次聚类所用时间的占比也会变大.
需要指出的是:虽然本文介绍的方法在计算时较为费时,但是该方法所进行的异常流量判别可以得到各个异常流量的情景,该步骤属于异常流量情景数据建模.当建模结束后即可得到各种异常流量情景,此时即可根据新的流量的数字特征与已经得到的异常流量情景进行对比,从而较快速地分析出流量的异常与否以及其所属的异常流量情景.因此,后续可关注的一个研究方向是,如何将该方法得到的异常检测模型运用于实时线上的异常流量检测中.
5 总结和展望
本文介绍了一个无监督异常检测方法自动挖掘系统日志的异常日志流量模式,该检测方法可以自动找到系统日志的异常时间段,并统计时间段内不同节点的日志出现序列.本文定义了日志类型序列代表异常日志流量模式,且基于日志类型序列的相似度进行层次聚类.聚类过程中,可以全自动地得到最优参数.聚类结果根据日志类型的平均数量得到易于判断的异常日志流量模式.我们使用该系统对国家高性能计算环境下半年产生的系统secure 类型日志进行测试,最终得到6 种异常日志流量模式.本文在处理日志分类时,采用的是字符串比较法.所以理论上,只要是ASCII 码格式的日志都可以自动进行分类,然后即可将单位时间的日志流量抽象成向量进行后续的异常检测处理.在实际使用中,本方法对于自然语言文本类型的日志适用性更好(该类型日志内容通常为一个英文句子,易于分类),而对于纯变量类型的日志适用性相对一般(例如tomcat 的access log).
本文只是针对单一日志异常流量做了一些前期探索工作,未来还有很多值得关注的研究点.今后的工作主要针对以下几个方面:将该异常模式得出的结果运用在流量的监控和预测上;该方法用于不同种类的日志,通过不同种类日志的关联关系进行分析,以找到更全面的异常日志流量模式;基于日志类型序列的角度进行更多不同维度的日志分析方法研究,例如日志类型序列的关联性分析等.
