时空域上下文学习的视频多帧质量增强方法
2020-01-02佟骏超吴熙林丁丹丹
佟骏超,吴熙林,丁丹丹
(杭州师范大学 信息科学与工程学院,杭州311121)
过去几年,视频逐渐成为互联网的主要流量,根据思科白皮书预测,到2020年,互联网有近80%[1]流量为视频。未经压缩的视频体积大,给传输和存储都带来巨大挑战。因此,原始视频一般都经过压缩再进行传输或存储。然而,视频压缩会带来压缩噪声,尤其在带宽严重受限的情况下,压缩噪声严重地影响了用户的主观体验。这时,有必要在解码端再次提升压缩视频的质量。
针对图像或视频质量增强,国内外已有不少研究。Dong等[2]设计了减少噪声的卷积神经网络(Artifacts Reduction Convolutional Neural Network,ARCNN),减少了JPEG压缩图像所产生的噪声。之后,Zhang等[3]设计的去噪神经网络(Denoising Convolutional Neural Network,DnCNN),具有较深的网络结构,实现了图像去噪,超分辨率和JPEG图像质量增强。后来,Yang等[4]设计了解码端可伸缩卷积神经网络(Decoder-side Scalable Convolutional Neural Network,DSCNN),该结构由2个子网络组成,分别减少了帧内编码与帧间编码的失真。然而,上述方法都仅利用了图像的空域信息,没有利用相邻帧的时域信息,仍有提升空间。Yang等[5]尝试了一种多帧质量增强(Multi-Frame Quality Enhancement,MFQE)方法,利用空域的低质量当前帧与时域上的高质量相邻帧来增强当前帧。同等条件下,MFQE获得了比空域单帧方法更好的性能。
在视频序列中,尽管帧之间具有相似性,但仍存在一定的运动误差。Yang等[5]所提出的MFQE做法是首先借助光流网络,得到相邻帧与当前待增强帧之间的光流场;然后根据该光流场对相邻帧进行运动补偿,即相邻帧内的像素点,根据光流信息,向当前帧对齐,得到对齐帧;最后,将对齐帧与当前帧一起送入后续的质量增强网络。上述方法能够取得显著增益,但也有一些不足:
1)视频帧之间的运动位移不一定恰好是整像素,有可能是亚像素位置,一般的做法是通过插值得到亚像素位置的像素值,不可避免地会产生一定误差。也就是说,根据光流信息进行帧间运动补偿的策略存在一定的缺陷。
2)MFQE利用了当前帧前后各一帧图像对当前帧进行增强,增强网络对应的输入为3帧图像,包括当前帧与2个对齐帧。视频序列由连贯图像组成,推测,如果在时域采纳更多帧则会达到更好效果,这就意味着需要根据光流运动补偿产生更多对齐帧,神经网络的复杂度与参数量也会急剧上升,并不利于训练与实现。
考虑到上述问题,本文提出一种基于时空域上下文学习的多帧质量增强方法(STMVE),该方法不再从光流补偿,而是从预测的角度出发,根据时域多帧得到当前帧的预测帧,继而通过该预测帧来提升当前帧的质量。在预测时,在不增加网络参数与复杂度的情况下,充分利用了近距离低质量的2帧图像、远距离高质量的2帧图像,显著提升了性能。
本文的主要贡献如下:
1)在多帧关联性挖掘方面,与传统的基于光流进行运动补偿的方法不同,STMVE方法根据当前帧的邻近帧,得到当前帧的预测帧。具体地,使用自适应可分离的卷积神经网络(Adaptive Separable Convolutional Neural Network,ASCNN)[6],输入时域邻近图像,通过自适应卷积与运动重采样,得到预测帧。该方法极大地缩短了预处理时间,并且预测图像的质量也得到了明显的改善。
2)在增强策略方面,提出多重预测的方式,充分利用当前帧的邻近4帧图像。将该4帧图像分为2类:近距离低质量的2帧图像与远距离高质量的2帧图像。这2类图像对当前帧的质量提升各有优势,设计神经网络结构并通过学习来结合其优势,获得更佳性能。
3)在多帧联合增强方面,提出了一种时空域上下文联合的多帧卷积神经网络(Multi-Frame CNN,MFCNN),该结构采用早期融合的方式,采用一层卷积层将时空域信息融合,而后通过迭代卷积不断增强。整个网络利用全局与局部残差结构,降低了训练难度。
1 相关工作
1.1 基于单帧的图像质量增强
近年来,在提升压缩图像质量方面涌现出大量工作。比如,Park和Kim[7]使用基于卷积神经网络(Convolutional Netural Network,CNN)的方法来替代H.265/HEVC的环路滤波。Jung等[8]使用稀疏编码增强了JPEG压缩图像的质量。近年来,深度学习在提高压缩图像质量方面取得巨大成功。Dong等[2]提出了一个4层的ARCNN,明显提升了JPEG压缩图像的质量。利用JPEG压缩的先验知识以及基于稀疏的双域方法,Wang等[9]提出了深度双域卷积神经网络(Deep Dualdomain Convolutional netural Network,DDCN),提高了JPEG 图像的质量。Li等[10]设计了一个20层的卷积神经网络来提高图像质量。最近,Lu等[11]提出了深度卡尔曼滤波网络(Deep Kalman Filtering Network,DKFN)来减少压缩视频所产生的噪声。Dai等[12]设计了一个基于可变滤波器大小的卷积神经网络(Variable-filter-size Residuelearning Convolutional Neural Network,VRCNN),进一步提高了H.265/HEVC压缩视频的质量,取得了一定性能。
上述工作设计了不同的方法,在图像内挖掘了像素之间的关联性,完成了空域单帧的质量增强。由于没有利用相邻帧之间的相似性,这些方法还有进一步提升空间。
1.2 基于多帧图像的超分辨率
基于多帧的超分辨与基于多帧的质量增强问题有相似之处。Tsai等[13]提出了开创性的多帧图像的超分辨率工作,随后在文献[14]中得到了更进一步研究。同时,许多基于多帧的超分辨率方法都采用了基于深度神经网络的方法。例如,Huang等[15]设计了一个双向递归卷积神经网络(Bidirectional Recurrent Convolution Network,BRCN),由于循环神经网络能够较好地对视频序列的时域相关性进行建模,获取了大量有用的时域信息,相较于单帧超分辨率方法,性能得到显著提升。Li和Wang[16]提出了一种运动补偿残差网络(Motion Compensation and Residual Net,MCRes-Net),首先使用光流法进行运动估计和运动补偿,然后设计了一个深度残差卷积神经网络结构进行图像质量增强。上述多帧方法所取得的性能超越了同时期的单帧方法。
Yang等[5]提出利用时域和空域信息来完成质量增强任务,设计了一种MFQE的增强策略。首先,利用光流网络产生光流信息,相邻帧在光流信息的引导下,得到与当前待增强帧处于同一时刻的对齐帧;然后,该对齐帧与当前待增强帧一同输入质量增强网络。受上述工作的启发,本文提出了一种更加精准和有效的基于多帧的方法,以进一步提升压缩视频的质量。
2 时空域上下文学习多帧质量增强
如图1所示,所提方法的整体结构包括预处理部分与质量增强网络。其中,预处理部分采用ASCNN网络,其输入相近多帧重建图像,分别生成关于当前帧的2个预测帧;然后,这2个预测帧与当前帧一起送入质量增强网络,经过卷积神经网络的非线性映射,得到增强后的当前帧。
2.1 光流法与ASCNN
挖掘多帧之间关联性的关键是对多帧之间的运动误差进行补偿。光流法是一种常见的方法。本文对光流法与基于预测的ASCNN的计算复杂度与性能进行了对比。
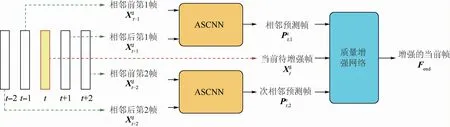
图1 时空域上下文学习的多帧质量增强方法Fig.1 Approach for multi-frame quality enhancement using spatial-temporal context learning
1)使用光流法进行预处理
f(t-1)→t表示2帧 图 像(、,t>1)。首先,通过光流估计网络HFlow得到的光流;然后,对得到光流与进行WARP操作,得到对齐帧;最后,将和一起送入卷积神经网络,可得到t时刻的质量增强帧。
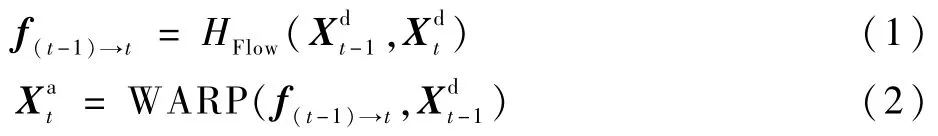
2)使用ASCNN进行预处理
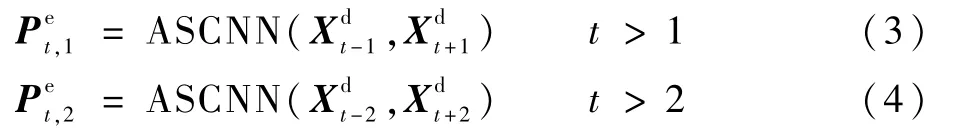
光流法的典型实现是FlowNet[17]。本文选取了4个测试序列,每个序列测试50帧,比较了FlowNet 2.0与ASCNN的时间复杂度,如表1所示。对于2个网络,分别输入2帧图像,并得到各自的预处理时间。经过预处理,光流法得到2帧对齐图像,ASCNN得到1帧预测帧。值得注意的是,由于FlowNet 2.0网络参数量较大,当显存不足时,每帧图像被分成多块进行处理。从表1可以看出,FlowNet 2.0的预处理耗时约为ASCNN的10倍。
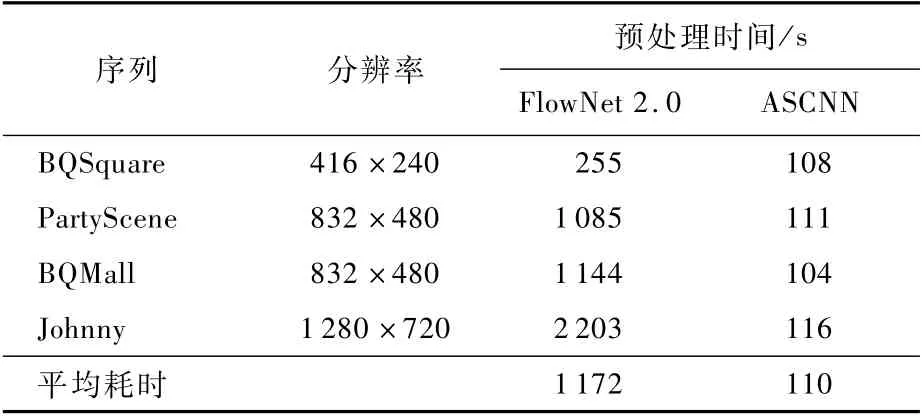
表1 光流法(Flow Net 2.0)与ASCNN预处理时间对比Table 1 Pre-processing time comparison of optical flow method(Flow Net 2.0)and ASCNN
2.2 多帧质量增强网络
多帧质量增强网络MFCNN的结构如图3所示,网络结构内部的参数配置如表2所示。在MFCNN中,HCFEN为粗特征提取网络(Coarse Feature Extraction Network,CFEN),分别用于提取、和的空间特征:
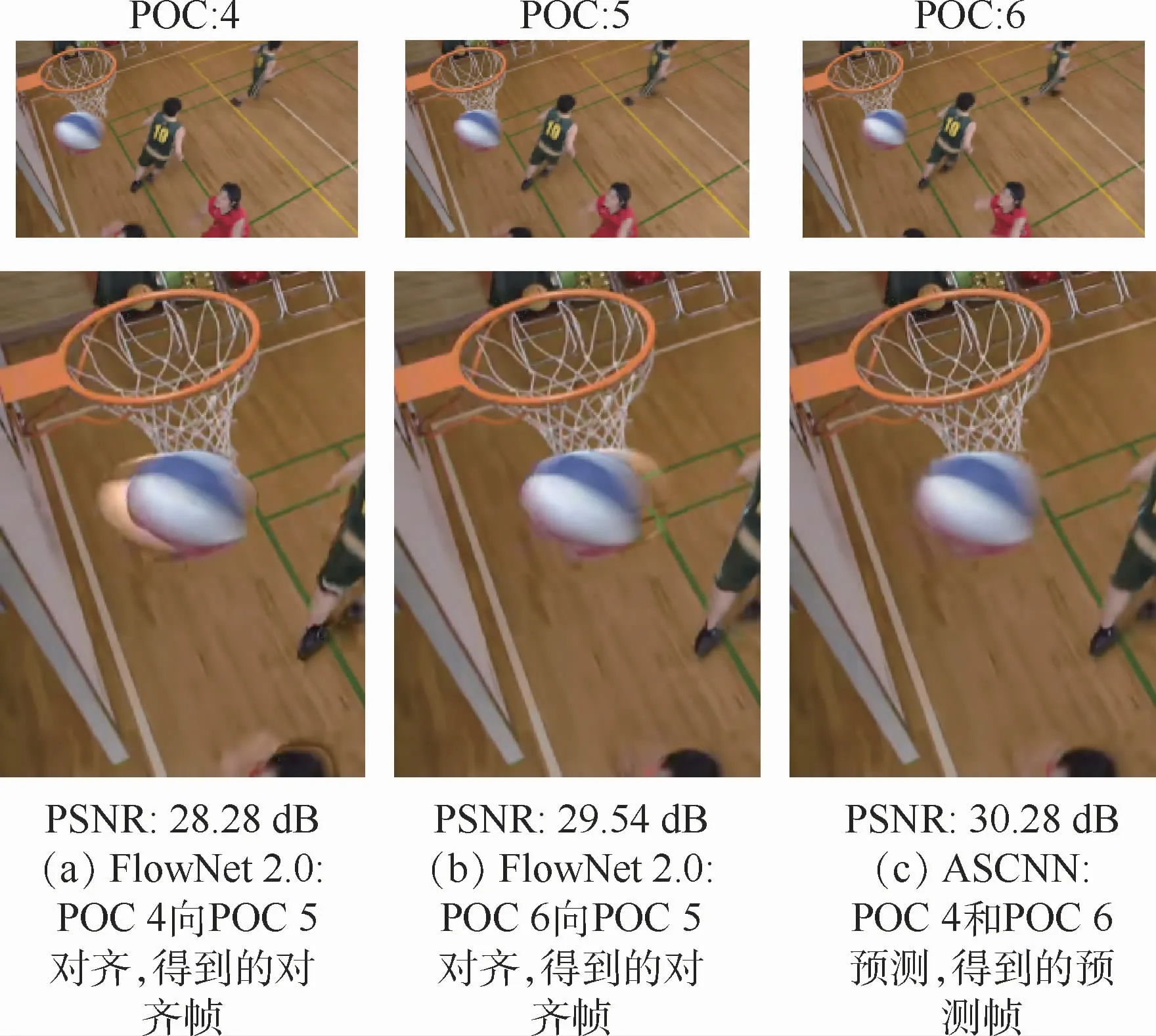
图2 光流法(FlowNet 2.0)与ASCNN预处理得到的输出图像的主观图Fig.2 Subjective quality comparison of output image preprocessed by optical flow method(FlowNet 2.0)and ASCNN


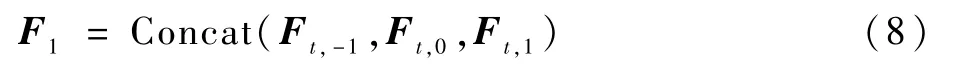
然后,送入Conv 4,将所级联的特征进一步融合,同时使用1×1大小的卷积核来降该层的参数量:

最后,经过7个残差网络[18]的残差块,得到特征矩阵为F7。在MFCNN的最后输出层,加入Xdt形成全局残差学习结构:

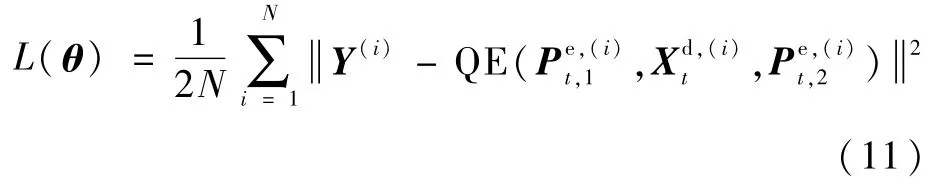
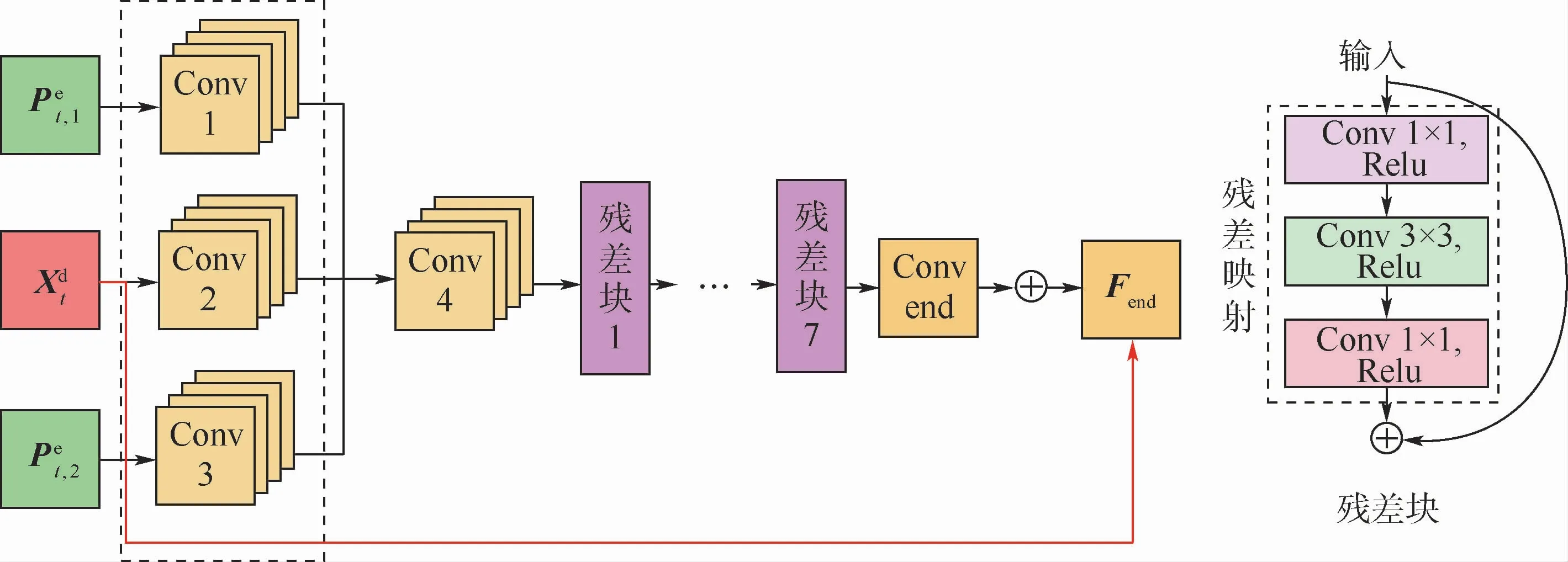
图3 早期融合网络结构及其内部每个残差块的结构Fig.3 Structure of proposed early fusion network and structure of each residual block in it
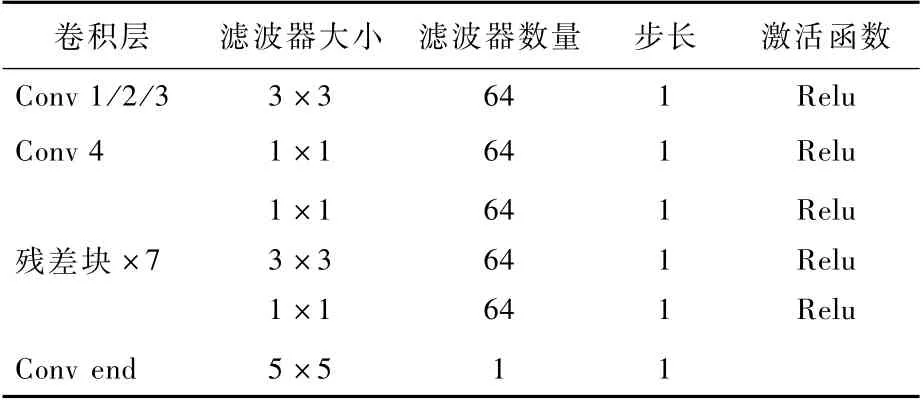
表2 多帧质量增强网络结构Table 2 Str ucture of proposed quality enhancement network
3 实验结果与分析
3.1 实验条件
本文的训练与测试环境为i7-8700K CPU和Nvidia GeForce GTX 1080 TI GPU。所有实验都基于TensorFlow深度学习框架。本文使用118个视频序列来训练神经网络,并在11个H.265/HEVC标准测试序列进行测试。每个序列都使用HM16.9在Random-Access(RA)配置下图像组(Group of Pictures,GOP)大小设置为8,量化参数分别设置为22、27、32、37,并获得重建视频序列。
3.2 实验结果比较与分析
1)与传统光流法的对比
本文采用基于早期融合的质量增强网络结构,对5种预处理方法的性能进行了对比,以图4所示的第2帧图像为例,包括:
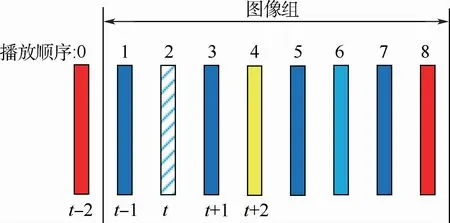
图4 以图像组为单位对低质量图像进行增强Fig.4 Enhancing low-quality images for each GOP
①使用光流法对前后t±2帧进行运动补偿,分别得到对齐帧,利用两帧对齐帧对当前帧进行增强。
②使用ASCNN利用前后t±2帧预测当前帧,利用该预测帧对当前帧进行增强。
③结合①与②,利用两帧对齐帧与一帧预测帧对当前帧进行增强。
④使用光流法对前后t±2帧进行运动补偿,分别得到对齐帧,使用ASCNN利用前后t±1帧预测当前帧,利用两帧对齐帧与一帧预测帧对当前帧进行增强。
⑤使用ASCNN,分别利用前后t±1与t±2帧预测当前帧,根据所得到的两帧预测帧对当前帧进行增强。
表3给出了上述几种方法的性能对比,其中t+n代表与t时刻相隔n帧。可见,使用ASCNN,将2对相邻帧生成当前时刻的2个预测帧的方式,取得了最优的性能。
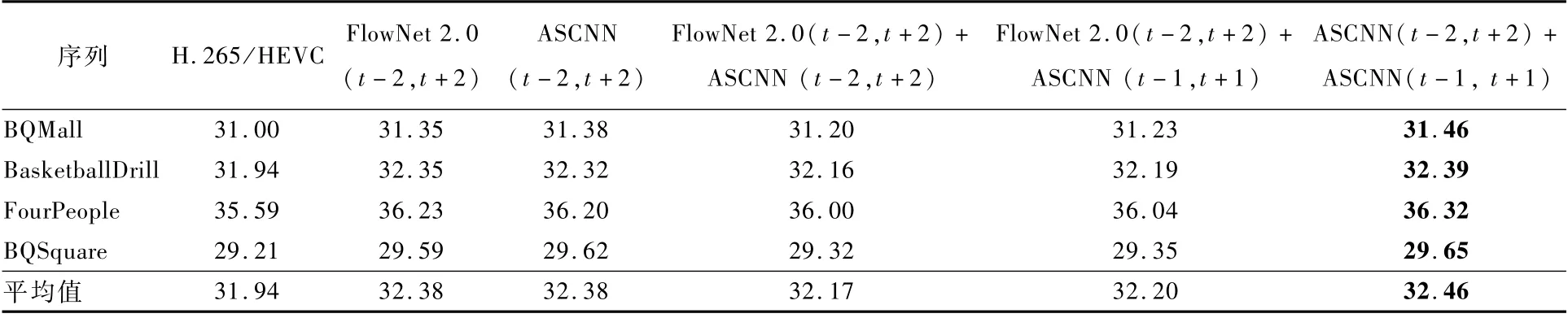
表3 5种预处理方式所获得的PSNR性能指标对比Table 3 PSNR performance indicator comparison by five pre-processing strategies dB
2)与不同网络结构的对比
本文设计了多种形态的网络结构,并对其性能进行了对比。如图5所示,分别设计了直接融合、渐进融合2种方式,并与本文的早期融合进行了对比。
3种结构的区别在于,直接融合方法直接将多帧信息级联作为网络输入,渐进融合方法逐渐地级联卷积特征图。将这3种结构设计成具有相近的参数量,实验结果如表4所示。可见,渐进融合比直接融合的性能平均提高了0.03 dB,而早期融合比渐进融合又能够提升0.04 d B。
该实验证明了对每个输入帧使用更多独立滤波器,可以更好地甄别当前帧与预测帧的重要性。但随着网络深度的增加,渐进融合方法会引入更多参数。因此,相同等参数量的情况下,与早期融合方法相比,渐进融合网络深度较浅,很可能产生欠拟合问题,无法达到同等性能。
3)与单帧质量增强方法的对比
采用ASCNN,分别对前后帧进行预测,具体地,分别使用ASCNN利用前后距离近质量低的两帧图像(如图4的第1帧与第3帧)、前后距离远质量高的两帧图像(如图4的第0帧与第4帧),得到当前帧的两帧预测帧,这两帧预测帧与当前帧一起送入所提出的早期融合网络,得到最终增强的图像。
如表5所示,本文所提出的STMVE始终优于仅使用空域信息的单帧质量增强方法。具体地,相较于H.265/HEVC,STMVE在量化参数为37、32、27、22分别取得了0.47、0.43、0.38、0.28 dB的增益,相较于单帧质量增强方法,分别获得0.16、0.15、0.15和0.11 d B的性能增益。
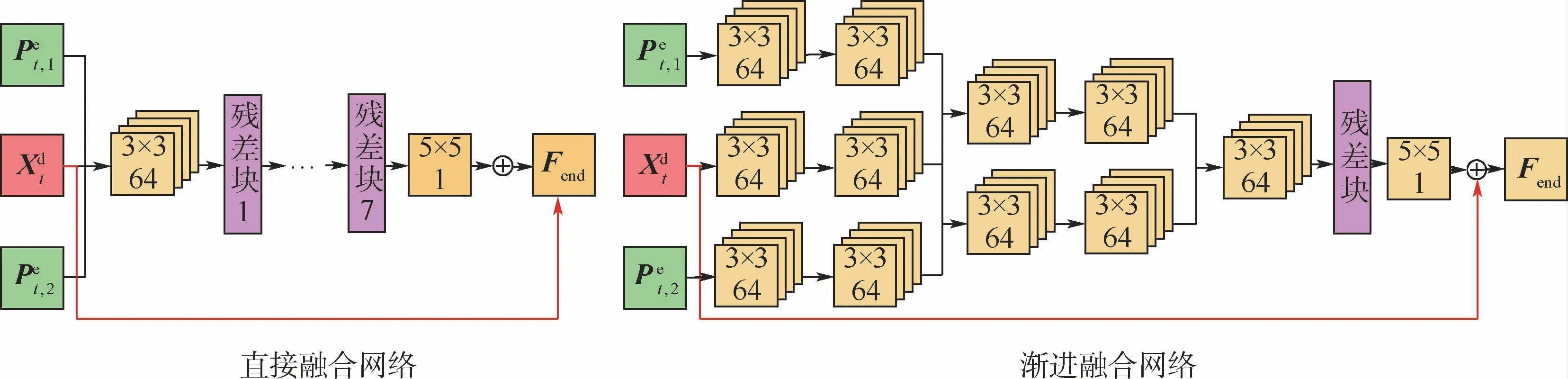
图5 直接融合网络和渐进融合网络与所提出的早期融合网络的对比Fig.5 Comparison of direct fusion networks and slow fusion networks with proposed early fusion networks
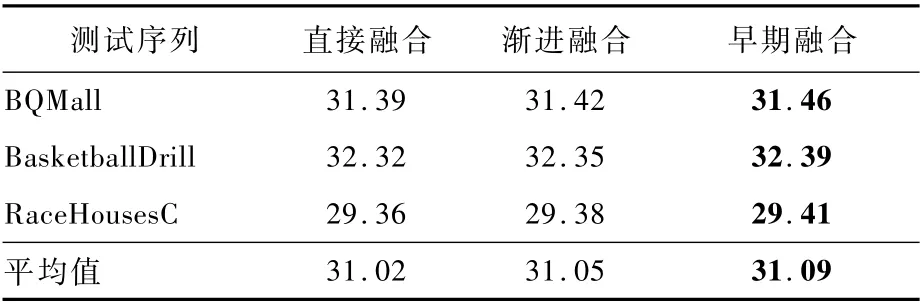
表4 三种网络结构的PSNR性能指标对比Table 4 PSNR perfor mance indicator comparison of three network structures dB
4)与多帧质量增强方法的对比
本文也与MFQE的结果进行了对比,结果如表6所示,其中,ΔPSNR代表STMVE与MFQE的PSNR之差。随机选取了4个测试序列,在量化参数为37时,测试其前36帧。结果表明,所提出的STMVE方法平均比MFQE高出0.17 d B。在参数数量上,MFQE的参数量约为1 715 360,而STMVE的参数量为362 176,仅为MFQE的21%。可见,所提出的网络虽然具有较少参数,但仍获得了较高性能。
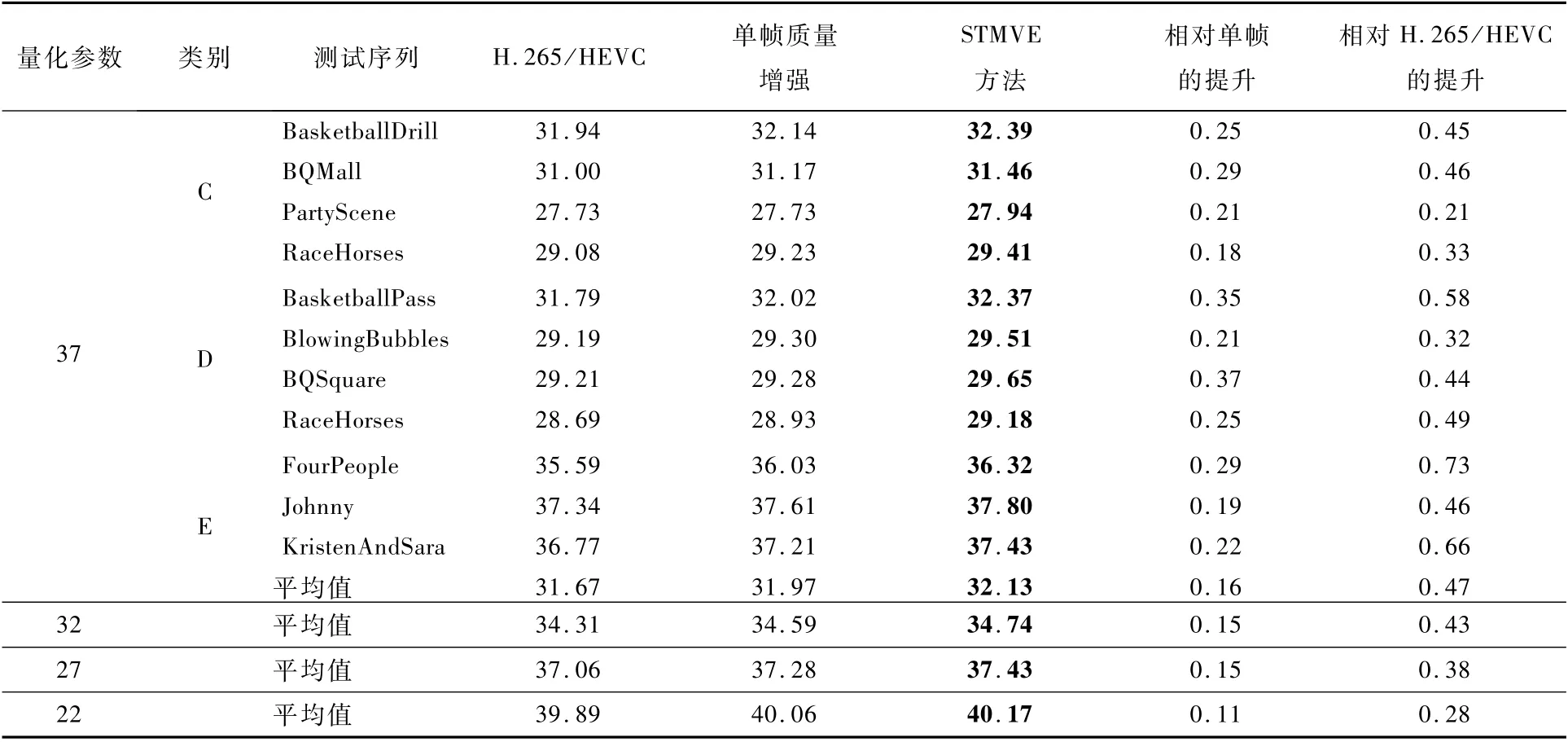
表5 不同方法的PSNR性能指标对比Table 5 Compar ison of PSNR performance indicator among different methods dB
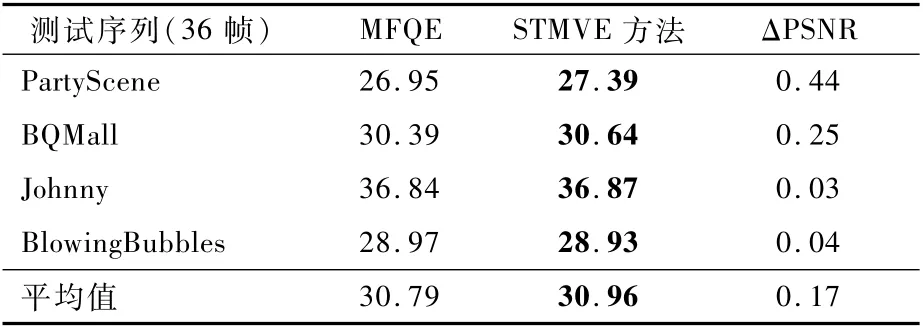
表6 STMVE方法与MFQE的PSNR性能指标对比Table 6 PSNR performance indicator comparison between proposed method and MFQE dB
5)主观质量对比
本文还比较了经不同方法处理后得到的图像的主观质量,如图6所示。经观察可见,与H.265/HEVC和单帧质量增强方法相比,所提出的STMVE方法能够明显改善图像的主观质量,图像的细节被更好地保留下来,主观质量提升明显。

图6 不同方法获得图像的主观质量对比Fig.6 Subjective quality comparison of reconstructed pictures enhanced by different methods
4 结 论
本文提出了一种时空域上下文学习的多帧质量增强方法基于STMVE。与以往基于单帧质量增强的方法不同,STMVE方法充分利用了当前帧的邻近4帧图像的时域信息。与传统的基于光流法的运动补偿方式不同,本文提出了利用预测帧增强当前帧的质量;为充分挖掘时域信息,提出了多帧增强的早期渐进融合式网络结构。其次,针对所提出的STMVE方法,分别就预处理方式、网络组合结构、质量增强方法及主观质量进行了分析,并设计实验与以往方法进行了对比。大量的实验结果表明,与其他方法相比,本文所提出的STMVE方法在主观质量与客观质量上都有显著优势。
