改进的LDA文档主题模型的实现
2019-12-31张腾岳
张腾岳
(延安大学 数学与计算机科学学院,陕西 延安 716000)
随着计算机网络的普及与发展,基于互联网的各种应用层出不穷,特别是自媒体时代的到来,网络上出现了类型各异,体量巨大的数据和信息,这些数据与信息与传统时代的数据有着根本性的不同,非结构化的数据占据了很大的比重,其中包含文档信息,音频信息,图片信息和视频信息,这些数据中往往隐含着丰富的信息,对这些信息的处理已经成为目前计算机领域研究的热点,对文本信息的挖掘和处理是这些热点之一。
在文本数据挖掘的研究中,有时候需要将文档划分成若干个主题,进而可以对文本进行各种的后继处理。LDA(Latent Dirichlet Allocation,潜在狄利克雷分布)是一种文档主题生成模型。它能够将语料库中的文档自动划分为不同的主题,文档以概率的形式表示该文档归属于某个主题,而每个主题又以不同词语在该主题中占有的权重给出。LDA模型由于贝叶斯理论的支持,使得该模型被广泛的应用到文档分类[1]、文档聚类[2]、图像标注[3]、话题检测[4,5]、推荐系统[6]、情感分析[7,8]、图书自动分类[9]、文献检索[10]、数据可视化[11]、用户画像[12,13]等不同的领域。
1 算法原理及改进
1.1 算法原理
LDA由Blei D M、Ng A Y和Jordan于2003年提出[14]。它是一种文档主题生成模型,本质上是一个三层贝叶斯概率模型。LDA模型认为一篇文档包含若干主题,而每个主题又有若干词语体现,因此生成一篇文档的过程也就包含两个阶段:由文档到主题,再由主题到词语。
生成一篇文档之前,应该先确定这篇文档包含哪些主题,这些主题的分布是什么,先假设在文档中包含K个主题,这些主题在文档中的分布为θm,主题分布符合公式(1)所示的Dirichlet分布。
f(x1,x2,…,xk;x∝1∝2…∝n)=
(1)
其中参数B(∝)如公式(2)所示。
(2)
其中的Γ是Gamma函数,满足Γ(x)=(x-1)!,在Dirichlet分布中,向量∝是一个K维向量,与文档中包含的主题个数K相同。
在主题的多项式分布θm中取样生成文档m第n个词语的主题Zm,n。多项式分布是Dirichlet的共轭分布。重复上述的步骤,从Dirichlet分布β中取样生成主题Zm,n对应的词语分布φZm,n,然后在根据φZm,n采样得到最终的词语Wm,n。
在文档主题模型生成过程中,两个Dirichlet分布分别有一个超参数α和β,参数α控制了文档中包含主题的多少,α越高,文档包含的主题更多。β表示一个主题中词语的多少,β越大表示主题中包含的词语越多。
LDA模型生成文档的过程可以用图1表示。
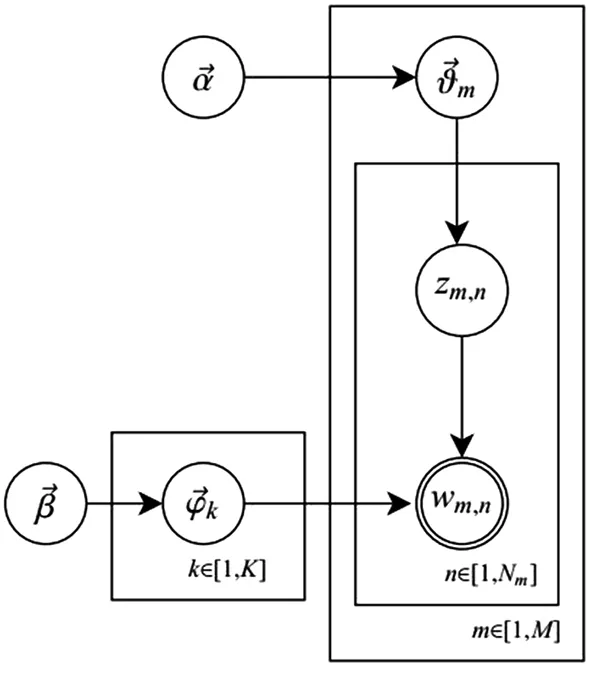
图1 文档生成过程图
基于LDA模型求解每一篇文档的主题分布和每一个主题中词的分布可以使用两种方法,第一种是基于Gibbs采样算法求解,第二种是基于变分推断EM算法求解。
本文采用gensim工具包提供的LDA模型进行求解,采用的是Gibbs采样算法。其算法步骤是:
(1)随机为每一篇文档的每一个词W,随机分配主题编号Z。
(2)统计每个主题Zi下出现字W的数量,以及每个文档N中出现主题Zi中的词W的数量。
(3)每次排除当前词W的主题分布Zi,根据其他所有词的主题分类,来估计当前词W分配到各个主题Z1,Z2,Z3,…,Zk的概率,即计算p(zi|z-i,d,w)。得到当前词属于所有主题Z1,Z2,Z3,…,Zk的概率分布后,重新为词采样分配一个新的主题Zj。用同样的方法不断更新这个词的主题,直到每个文档下的主题分布θm和每个主题下的词分布φk收敛。
(4)最后输出待估计参数,θm和φk,每个单词的主题Zm,n也可以得到。
1.2 算法改进
经典的LDA算法完全依靠某个词语Word在一个文档中出现的频率,认为词语Word在文档中出现的频率越高表示该词语Word越重要,但这与实际情况并不完全相符,比如在本文中经常同时出现“文档主题模型”,分词后将会是“主题”、“文档”、“模型”三个词,这些词语在文档中的频率一样,但是并不能说明这三个词语的重要程度是一样的,为了更加合理、客观的评价一个词语的重要程度,所提出的算法采用TF-IDF方法来计算词语Word的重要程度。
TF-IDF算法除了使用词频作为衡量词语Word重要程度的指标,还引入了逆文档频率的概念,逆文档频率表示词语Word在整个语料库中出现的文档数与语料库中所有文档的数量的比值。它表示一个词语在文档中出现的次数越多但是在语料库中包含该词语的文档数量越少,表示该词语越重要[15]。
因此,TF概念衡量的是一个词语在一个文档中的重要程度,表示的是词语Word在一个文档中的局部信息,而IDF概念反映了一个词语在整体语料库中的信息,表示的词语Word的全局信息。
在TF-IDF算法中,TF采用公式(3)来计算:
(3)
逆文档频率IDF采用公式(4)
(4)
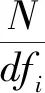
文档中每个词语Word的权重采用公式(5)进行计算:
Wtf=tfi×idfi
(5)
公式(3)的计算表明,如果一个词语在某个文档中出现的次数越多但是在语料库中包含该词语的文档数量越少,该词语在该文档中越重要。
经过分析,词语Word在文档中的重要程度比单纯的词频更具有说服力[16],因此可以使用词语Word的TF-IDF值代替LDA算法中的词频。但大部分的LDA工具包在进行模型训练的过程中,往往要求词频矢量矩阵的值为整数,但词语Word的TF-IDF值一般都是小数,因此直接用TF-IDF值代替LDA算法的词频矢量矩阵的做法是不可取的,需要对TF-IDF值进行适当的变换,既能保持词语在文档重要程度又能符合LDA算法的要求。
2 实现过程
一个完整的LDA实现过程如下:
(1)获取需要处理的数据,这个数据为原生数据Raw_Data。
(2)对原生数据进行数据清洗。由于原生数据获取的途径等问题,这些数据中往往包含有一些噪声,比如从网页上抓取的数据中可能会包含HTML标签和数据实体等噪声数据,在数据进一步处理之前必须清除掉这些噪声。处理掉噪声后的数据称为字符串类型的语料库String_Corpus。
(3)对String_Corpus包含的每篇文档Text进行分词操作,每个文档Text处理成为一个词语Word的列表。在分词的过程中首先需要加载用户自定义的词语库,词语库中的词语Word在分词过程中具有更高的优先级。比如“延安大学”词语在分词的过程中往往会被分为两个词语“延安”和“大学”,为了让其成为一个词Word,需要在用户自定义词语库中添加“延安大学”。然后去掉一些停用词,一篇文档中往往包含有很多“的”、“地”、“得”、“啊”等虚词,这些词语对于文档的主题生成不具有任何意义,所以需要去掉。为了更能体现文档的意义,还需要根据词性过滤掉一些词,在实现中,本文将词性为“介词”、“连词”、“助词”、“叹词”、“拟声词”、“语气词”、“处所词”、“方位词”、“状态词”、“标点符号”、“None”的词语舍弃掉。
(4)生成词袋即字典Dictionary。将String_Corpus分词得到的词语装入词袋,词袋中的每个词语不重复,进行唯一的编号并计算该词语在整个语料库中出现的次数。
(5)生成词语矢量矩阵Corpus。根据词袋Dictionary和String_Corpus生成一个二维矩阵M×N,M是语料库中文档的个数,N为词袋中词语的个数。每一篇文档都转换称为一个长度是N的矢量。词语矢量矩阵Corpus如下。
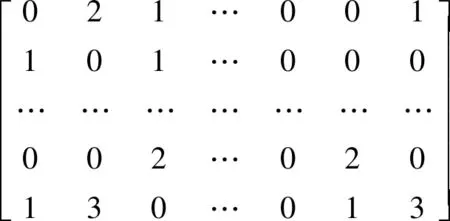
矩阵中的每一行代表一篇文档,从词袋Dictionary取出编号为1的词语,查看该词语在该文档中是否出现,如果没有出现,写入0,否则写入该词语在该文档中出现的次数。显然词语矢量矩阵Corpus是一个稀疏矩阵,如果语料库中的文档篇数巨大,矩阵Corpus将会占用大量的内存空间,所以Corpus采用压缩格式存储,一篇文档压缩后的矢量存储如[(1,2)(5,1)(6,1)…(10,2)(21,3)(200,1)]所示。
其中元组(X,Y)表示在字典Dictionary中编号为X的词语在该文档中出现了Y次,由于没有对出现0次的词语存储,所以节省了大量的存储空间。
(6)根据Corpus计算每篇文档的TFIDF值,得到矩阵Corpus_TFIDF.。Corpus_TFIDF矩阵的形式与矢量存储基本类似,只是原来词语的词频用TFIDF值代替。对矩阵Corpus_TFIDF中的TFIDF值进行适当转换,使TFIDF值成为整数,得到整数类型的词语矢量矩阵Corpus_TF_Int。
(7)根据得到的Dictionary、Corpus_TF_Int、传入迭代次数参数iterations、主题数num_topics等参数开始模型训练,最后得到LDA模型LdaModel。
(8)对LdaModel模型进行评价。根据评价指标的提示,调整训练参数重新训练模型,最后得到满意的模型。
(9)对模型的可视化。
3 仿真实验
本文采用从网络上采集的《南方周末》1525篇新闻为数据源[17],采用著名的文档处理工具包gensim进行仿真实验,模型评价指标使用Topic Coherence[18],超参数α、β采用工具包中的默认组,对影响模型的迭代次数和主题数进行最优化测试。
先固定主题数,模型迭代次数从50开始,每次训练迭代次数增加50,一直迭代到2000次结束。图2是不同迭代次数对模型的影响。然后固定迭代次数,选择不同主题数对模型的影响如图3所示。
最后算法使用pyLDAvis工具包对LDA模型进行了可视化显示,如图4所示。
表1列出了改进后的算法和经典算法随着算法迭代次数的变化,模型评价指标Topic Coherence的变化,评价指标Topic Coherence越小表示模型的效果越好。行号是1的表示经典LDA算法的Topic Coherence,行号为2的表示改进算法的Topic Coherence。
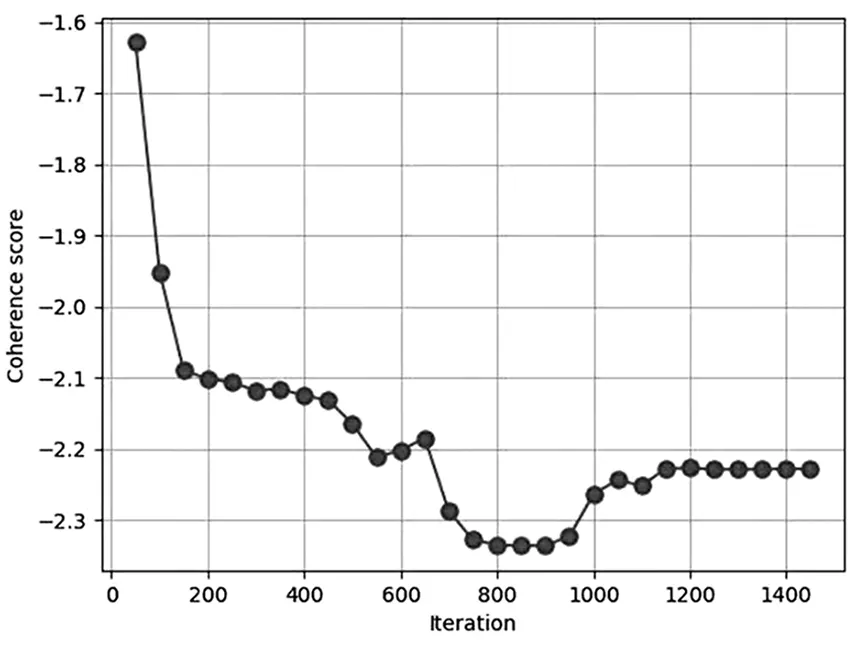
图2 不同迭代次数对模型的影响
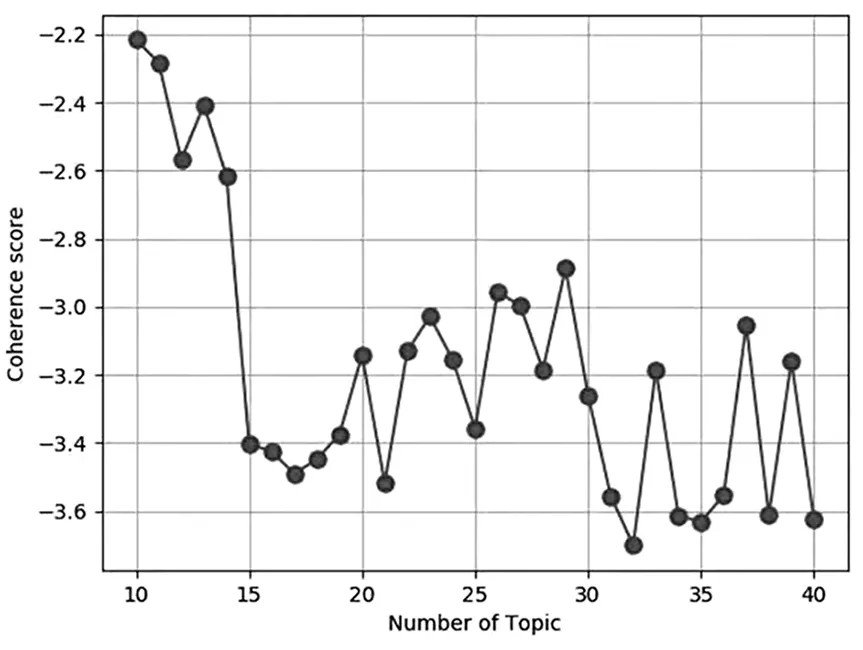
图3 不同主题数对模型的影响
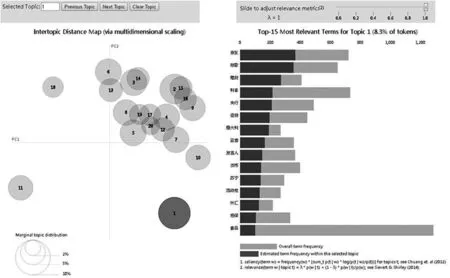
图4 LDA结果可视化显示

表1 不同迭代次数不同模型TopicCoherence的比较
4 结论
通过仿真实验,可以看出使用TFIDF替换经典的LDA算法的词语矢量矩阵,可以使得模型的TopicCoherence大幅度减小,按照文献[18]的描述,文档对象模型效果应该有很大的改善,但TFIDF不能直接放入LDA模型中,需要先转换为整数类型的矩阵。
对模型效果影响的因素很多,包含Dirichlet分布的超参数α和β,gensim工具包已经进行了优化设计,因此可以采用默认值,除此之外对模型训练效果影响的因素还包含随机种子数的设定、模型迭代次数、主题数目的选择,这些参数的取值都需要根据原始语料库的变化而探索获得。
