基于特征模型和遗传算法的测试用例自动生成∗
2019-12-27江志强王金波王晓华
江志强 王金波 王晓华
(中国科学院空间应用工程与技术中心 北京 100094)
1 引言
测试是软件开发的关键一环,测试用例生成是测试过程的重要环节。测试用例是否有效、快速地生成,影响了整个测试的效率[1]。一个好的测试用例集,能以较低的测试开销保障较高的测试性能[2]。现有常见的测试用例生成方法有基于UML模型[3],向量机[4]等方法。它们注重测试性能的同时并不能有效减小测试开销。因此,本文选用了特征模型。特征模型作为一种功能性的模型,可对功能模块实现高可复用性,从而有效降低测试开销。
当前,特征模型的应用主要运用于产品线领域的测试开发。它使用特征表征功能,同一产品线中不同的产品以不同的特征组合方式表达,而每个特征又通过UML等模型方法建立测试用例[5]。因此,这些产品的测试用例,是通过复用这些选择特征的测试用例进行组合得到。与之相比,本文对被测产品进行特征建模,并将特征与被测件输入关联,不需要将特征与其他模型相结合。由于使用组合测试策略能够进一步提高复用率[6],因此本文采用组合策略对特征模型进行选择,得到较优的测试用例集。
2 特征模型基本概念
特征模型[7]是在产品线分析的领域分析中诞生的,通常被视为一个产品与其它产品不同的地方,它关注的是产品系列中的需求和功能,并且通过需求分析构建产品。
特征模型被视作一个四元组[8]:(F,≺,λ,Φ)。其中F代表一组有限的特征节点,≺代表各特征节点的关系,通常是以树状图的形式体现,λ代表了特征的四类分配规则,分别是必选特征mandato⁃ry和三类非必须的特征:可选择特征optional,多选一特征alternative,和至少选取一个的特征or规则。Φ则代表了特征节点集合中可能的约束,通常包括两类约束条件:其一是依赖性约束require,也就是某个特征的存在必须以另一个特征存在为前提;其二是互斥性约束exclude,也就是两者不能同时出现在同一个产品中。
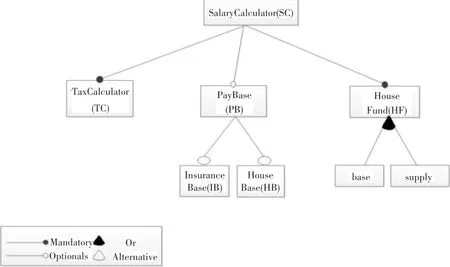
图1 工资计算器的特征模型
本文用于说明的实例是一个网页应用工资计算器 SalaryCalculator(SC)[9]。它的特征模型如图 1所示。其中,根特征SC有三个功能,对应三个特征:分别是税率计算TaxCalculator(TC),缴纳基数PayBase(PB)和住房公积金计算 HouseFund(HF)。其中,PB特征含有两个不同的特征:保险基数InsuranceBase(IB)和公积金基数HouseBase(HB)。它们都是optional规则特征。而HF下有两个满足or规则的特征:代表基本公积金的Base和补充公积金的Supply。
3 模型构建
3.1 模型细化
图1中特征都对应了被测软件的一个功能模块。相对于传统的特征模型,对每个特征不再建立诸如UML等对应的实体关系模型。而是将特征继续细化,对应测试的输入值,建立子特征。
特征与输入之间存在相互映射的关系。对特征的测试是通过一组输入得到相应的反馈,根据反馈结果检查特征对应的功能是否符合预期[10],因此特征与输入就存在相互影响。这种关系通常都不是一对一的关系。子特征则是特征的一部分,指该功能在部分输入下得到相同反馈或者同一性质的反馈的部分功能。根据特征与输入的关系,子特征的建立按如下方式进行。
第一,如果一个特征中受多个输入影响,则每一个输入都作为该特征的一个子特征。这些子特征会根据特征分配规则,被赋予四类分配规则的中的一种。
第二,如果一个输入影响多个特征,该输入受到特征组合的影响,其生成通过后文特征组合实现。
第三,当特征或子特征中只含有一个输入且反之亦然时,此时分为两类情况:
第1类:布尔型特征:该特征是一个布尔型变量。具体表现为此输入只会对特征对应的子功能产生两种互斥的状态。例如开关的开启和关闭;该特征自身就是其子特征。在特征选择中,选择与不选择两个状态分别对应其互斥的两个结果,并根据其选择状态表征其测试输入值。
如图1中的Base,Supply特征,它们各自都只有一个输入,表现为选项框,因此只有选择和非选择两个输入状态表示该功能是否激活。而IB和HB,它们也是选项框输入,选择与非选择分别代表该特征输入值为系统设置的默认值或最小值两个状态。这四个特征符合布尔型特征。
第2类:非布尔型特征:该特征与第一类不同,随着其对应输入值的变化,子功能反馈两种以上的结果。因此,该特征可以视作以分段函数,输入值变化区间是该分段函数的定义域,可以划分为多个子区间,不同输入区间对应分段函数的不同的子函数,每个子函数都可被视作一个子特征。这些子特征之间是互斥的,对应了特征模型中的Alternative特征。在测试用例中,该类子特征可以使用边界值或者等价类直接表示。在特征选择中,被选中的子特征的值作为其父节点的值输出,没有被选择的其他子特征的值被舍弃。
例如图1中的TC特征,它的输入是一个数值,随着数值的变化,对应的计算税率的函数会发生变化,因此符合非布尔型特征,可以按照测试文档说明按税率变化分为图2中TC下的8个子特征,分别是无税率noTax,第一等税率Tax_1,直到第七等Tax_7。这些子特征按照非布尔型特征规则,应该满足optional规则。
将特征模型通过树形图表示,在细分子特征之后,每个叶子节点都对应一个值。而通过选取叶子节点,就可以得到一个特征组合并形成测试用例[11]。因此在实际运用中,只选取所有的叶子节点作为全部特征列表。为了描述测试用例生成,首先有以下定义:

图2 建立子特征的测试特征模型
定义1:特征模型中所有的叶节点特征构成的集合被称为特征列表(Feature List,FL)。
如图1中,所有叶子节点构成的集合{noTax,Tax_1,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,IB,base,supply}就是一个特征列表FL。
定义2:特征配置(FeatureConfigure,fc)是一组满足特征模型规范和约束的特征组合,定义为fc={sel,},其中 sel⊆FL,sel代表该选定的特征,而都是未选定的特征,它们都是FL的子集,
如图2中,存在一特征配置fc1={{Tax_1,IB,base},{noTax,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,supply}},其中 fc1.sel={Tax_1,IB,base},代表了特征 Tax_1,IB 和 base被选取,={noTax,Tax_2,Tax_3,Tax_4,Tax_5,Tax_6,Tax_7,HB,supply},代表这些特征未被选择。因为所有的叶子节点都对应一个值,它们根据选取或未选取的状态返回相应的值,或者舍弃该子特征,返回值会根据特征和输入的相互关系反向获得测试用例的输入,并根据测试需求得到预期结果,组成测试用例[12]。因此一个特征组合就能对应一个测试用例。
定义3:特征配置fc构成的集合被称为特征配置集(Feature Configure Set)FCS。其中,特征列表FL中满足特征模型规范和约束的全部特征配置构成的集合被称为完全特征配置覆盖集。
完全特征配置覆盖集代表了该被测件所有可能的特征配置形式,即全部的测试路径。但一般来说这是一个较大的值。例如图2中,12个叶节点就构成了96个特征配置。
3.2 组合测试
完全特征配置覆盖通常意味着庞大的测试用例集和大量测试开销。而好的测试用例集,是选取一个较小的特征配置集合,实现特征覆盖。测试用例的生成就转化为了特征选取的问题。本文采用组合测试策略解决该问题[13],并通过遗传算法实现。研究表明,在特征模型中,采用组合测试的方式能够实现更小的组合配置,并且有更好的检错能力以保障其测试性能[14]。
本文在特征模型中采用二元组合策略实现特征配置,相关定义如下:
定义4:二元组合配置是一个二元组c,定义为的特征和非选择的特征,并且有
相对于一般特征模型只覆盖全部特征的方法,二元组合的特征配置集合需要对RC进行完全覆盖。由前文可知,测试用例对应的一个特征组合。目标测试用例集所满足的特征配置集应该实现对RC全覆盖。这样的特征配置集合被称为结果集合(Result Set,RS)。为了定义RS,首先引入定义5。
因此结果集合RS如下定义:
定义6:存在一个特征配置集合CFS={fc1,fc2,… fcm},其中 ∀fci∈CFS,fci的二元覆盖集合为cfci,对所有 fsi∈CFS,使二元组合覆盖集RC=该 CFS被称为结果集合(Result Set,RS)。其中,在所有的RS中,m最小的RS是最优的结果集合。
因此测试用例的生成就从组合特征和选取特征转化为寻找最优的RS,也就是寻找一个足够小的特征配置集合,使得其能够实现对RC的完全覆盖。
4 算法描述
一般来说,组合测试覆盖问题是一个NP难问题,常见的解法有贪心算法和启发式算法[15]。前者虽然运算速度快,但是作为一种近似算法,贪心算法只是近似解。而以遗传算法为代表的启发式算法相对于贪心算法可以跳出局部最优陷阱,能够得到更好的近似解。因此文本采取了遗传算法[16]实现组合测试策略。计算流程如图3所示。
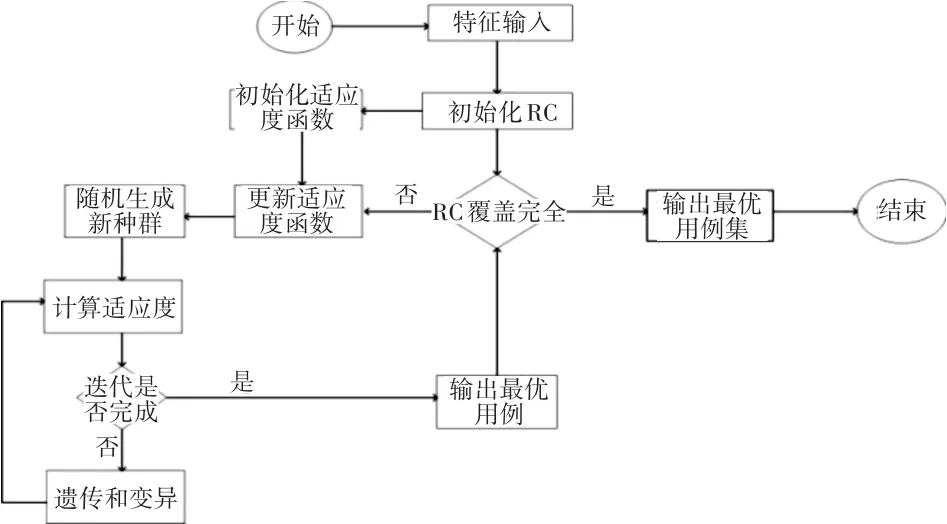
图3 基于组合测试的遗传算法框架
在初始化RC之后,开始对组合测试进行遗传算法运算。每一次遗传算法初始种群都采用随机选择产生。并不断调整适应度函数寻找最优解。本文中适应度函数主要有两部分构成。
第一项:判断个体是否符合特征模型规则。所有不符合特征需求的个体都会被淘汰,在遗传中被遗弃;
第二项:判断个体对当前RC的覆盖情况。RC的覆盖率再每一次输出一个最优用例的后都收到一个反馈,对当前的RC进行修正。其中每个个体的RC覆盖率RCcover计算如下:
其中,RCcover代表RC覆盖率值。此外,三个覆盖集合被定义,分别是所有的二元组合覆盖集AllCover,已经被覆盖的集合RubCover,有效地覆盖集合 VaildCover;其中 AllCover=RubCover∪ Vaild⁃Cover;RubCover∩ VaildCover=∅ ;每个个体所包含的二元组合覆盖定义为ChroCover;
根据上述定义,式(1)被修改为
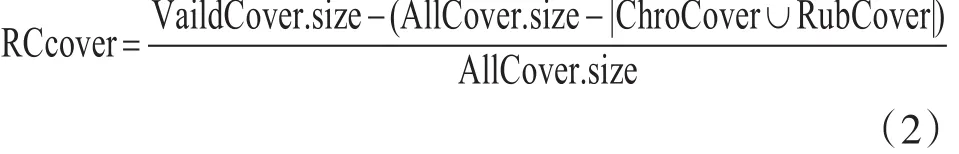
每个个体的适应度函数通过上面两个项确定,因此,在每进行一次遗传算法后,选取一个适应度最高的个体,该个体是一个特征配置fc,它是当前种群中拥有最高RC覆盖率的个体。将其保存在结果集合RS中,并且从RC中删去该最优解所覆盖的二元组合。经过多次运算,当RC变为空集的时候,意味着RC已经被完全覆盖,此时得到的RS就是实现了对RC的完全覆盖的用例集,是通过遗传算法求得的最优解。
在运算结束以后,最终得到的一个输出结果是一个由特征配置fc构成的集合FC,FC的所有元素都是相互独立且不相关的。根据前文中在子特征分解中所述,对每一个特征组合,都可按照其对应的功能关系和特征模型关系反向得到相应的被测软件输入数据以及期望结果,该输入数据和期望结果构成测试用例,进而获得所需要的测试用例集。
5 实验验证
为应用本文中提出的测试用例自动生成的设计方法,本文对三个被测系统进行了运用,其中第一个被测件SalaryCalculator是前文特征模型图建立的被测系统,该系统是一个运算模块,它拥有一个数字输入和四个参数调节项,包含12个特征;第二个被测件Blog[17]是另一个有一个输入项和多个可选择组合的被测项目,包含18个特征;第三个被测件WebLogin[18]是一个有两个输入项和多个可选组合的被侧项目,包含25个特征。三个被测件都被注入了10个错误。
由于遗传算法在产生初代种群的时候采取的是随机生成,因此我们对每个被测件进行10次运算,将其反映在表1中。
表1中,pp是该测试用例覆盖全部测试用例的比例,全部测试用例数量是穷举所有满足特征模型的特征配置得到。其中,SalaryCalculator被测件一共有96个测试用例,Blog被测件有55520个测试用例,WedLogin被测件包含451584个测试用例。从表1中可得,三个被测件均以较小的开销实现二元组合的覆盖,而且错误的验证率都在70%以上,尤其是后两项产品,它们相对于第一个被测软件,全路径分支的测试用例数更大,但是生成的最小用例集合更小,而且保持了较高的错误检测率,分别有87.8%和94.4%。因此,可以验证得到,本文提出的测试用例自动生成方法能够大幅度降低了测试开销,也可以保持一个高效的错误检测率。
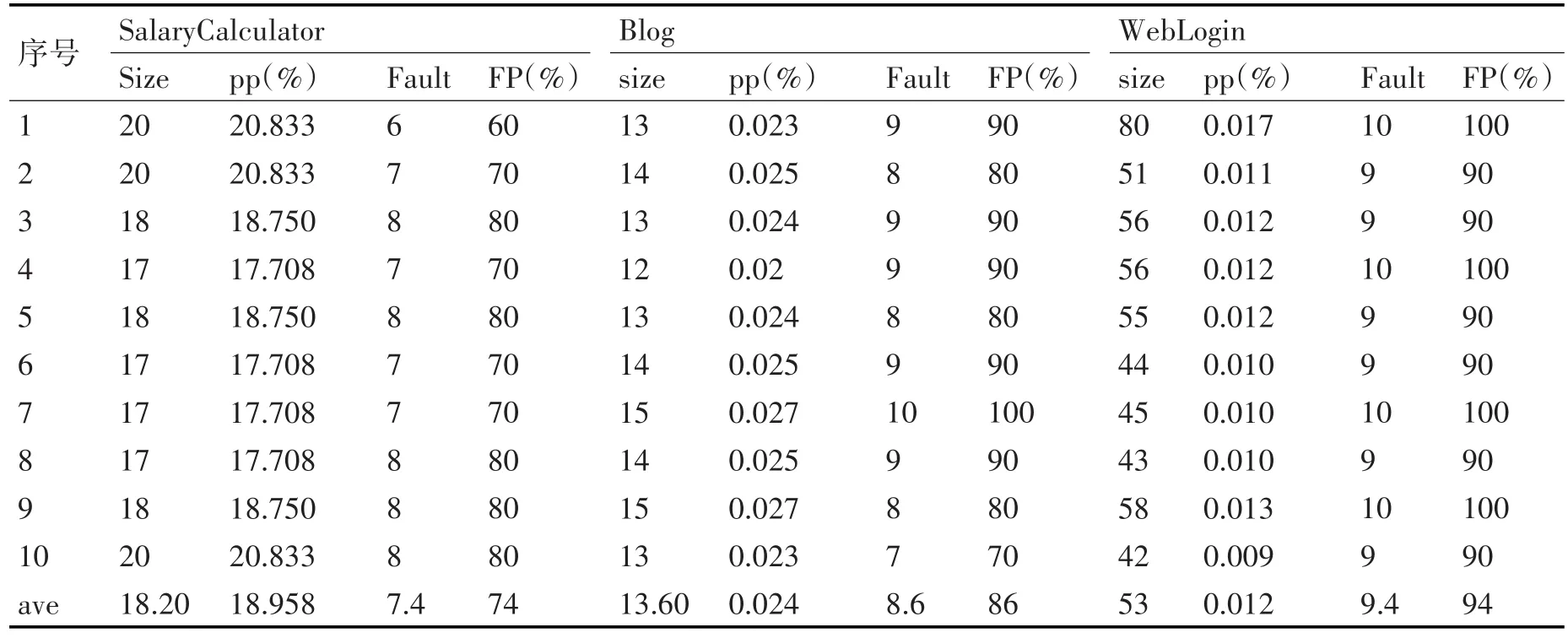
表1 被测系统测试用例生成表
Size为生成的测试用例集大小;pp为测试用例集对全部测试用例的比例。
Fault为发现的错误;FP:检查错误的百分比=发现的错误/注入的总错误。
6 结语
本文提出的基于特征模型的组合测试用例自动生成,结合了当前特征模型测试和组合测试方法的优势,是一种模型简易易用,可靠性强的测试方法。该方法继承了特征模型的分析方法,并在此基础上将特征层次深入到测试数据输入;组合测试和特征模型的结合进一步优化测试空间。在实验中,也验证了该方法能有效降低测试开销,保障测试性能,生成良好的测试用例集。
但是遗传算法随着迭代次数的增加,在后期容易出现收敛速度下降的问题,延长了测试用例生成的时间。当前在已经有很多学者对加快遗传算法收敛速度进行了研究[17],在未来的工作中,可以考虑这些算法改进策略,优化测试用例生成速度。
