大数据技术在学生业绩分析中的研究与应用
2019-12-25王肖飞
王肖飞
摘 要:随着大数据技术的不断发展,通过利用大数据技术的海量分析能力能够客观地分析出学生业绩数据的规律,以此为强化学生业绩管理工作提供科学依据。文章设计基于Map Reduce的关联规则算法,以此搭建Hadoop平台挖掘、分析学生真实的成绩。
关键词:大数据技术;学生业绩;分析
随着大数据技术在教育行业中的应用,客观评价学生的业绩是了解学生学习情况,改进教学模式的重要方式。然而由于影响高职学生业绩成绩的因素比较多,尤其是高职海量的教学和管理数据导致教育工作者难以客观的在海量的数据中寻求清晰的关联规则。目前高职所采取的学生业绩数据库系统只是简单地提供系统操作,而不能对数据进行分类分析。因此本文借助大数据技术的优势,构建基于大数据技术的学生业绩分析系统。
1 学生业绩分析概述
学生业绩就是学生在学习方面的学习方法、学习习惯、学习兴趣以及学习成绩的总称,学生业绩分析顾名思义就是对学生学习成效的分析。随着高职教育改革的不断推进,对于学生业绩的分析不能仅凭借其考试成绩,而且还要融入日常表现、人文素质以及实践应用能力等。在高职学习阶段学生业绩所产生的数据非常多,如何在海量的数据中挖掘有用信息并且为教育管理者所应用,成为当前学术业绩分析所必须解决的问题。实践表明在海量的数据中进行分析需要从海量数据中挖掘与提取重要信息,其包括数据清洗、数据选择、数据变换以及数据挖掘等,每个数据分析环节的构成都是数据分析研究的重要内容,因此需要最大程度地保持与还原客观事实。
2 基于大数据技术学生业绩分析系统的设计方案
2.1 系统开发设计的总体目标
基于大数据技术的学生业绩分析系统就是将大数据、数据挖掘等计算机技术应用到高职学生业绩管理系统中,以此通过该平台为学生、教师提供更加准确的数据信息,提高高职教育的精准度。结合高职教育的目标,该系统开发设计的主要目标为:(1)对产生数据的各环节进行精准分析。根据调查学生业绩数据产生不同的环节,例如平时的教学工作、学生实习表现、课堂反馈以及学生自我評价等,不同环节都会产生大量的数据,而这些数据之间有的存在某些关联,有些则存在重复性。海量的数据必然会影响教师对学生业绩情况的客观分析,因此,通过设计大数据学生业绩分析系统对海量数据进行自动分析与精选,以此为教学工作提供准确依据。(2)实现人机交互界面,实现双重查询需求。学生业绩分析系统需要满足学生自我查询和教师查询的功能,系统根据权限对相关使用者授权,以便其可以及时了解自己的学习或教学情况,进而客观地发现自己的缺陷并加以改进[1]。
2.2 系统开发的可行性及数据来源
根据高职学生成绩管理工作的需要,设计了合理的大数据处理与分析平台,以及数据挖掘并行算法处理平台,项目重点为利用Hadoop平台对大数据日志进行存储、分析、处理,对采集的数据进行分析,完成相应日志的入库、处理、分析、实时查询等主要功能。对经过处理后的数据进行数据挖掘,挖掘出有价值的信息,给用户推荐更好的资源。按照实施计划部署相应的大数据系统平台,根据平台的数据处理量,初步规划Hadoop集群的数量为5~10台。
为了客观地反映学生业绩情况,保证大数据学生业绩分析系统的准确性,提高数据的挖掘能力,本次研究的数据全部来源于高职教育不同阶段、部门。例如高职学生信息管理系统、招生就业系统、校园图书管理系统以及教务管理系统等。当然考虑到学生平时表现也是客观评价学生业绩的重要方面,因此,本研究将学生的网络社交媒体、学习者调查等方,载体中关于学生情况的数据也纳入到该系统研究范畴中。
3 架构设计
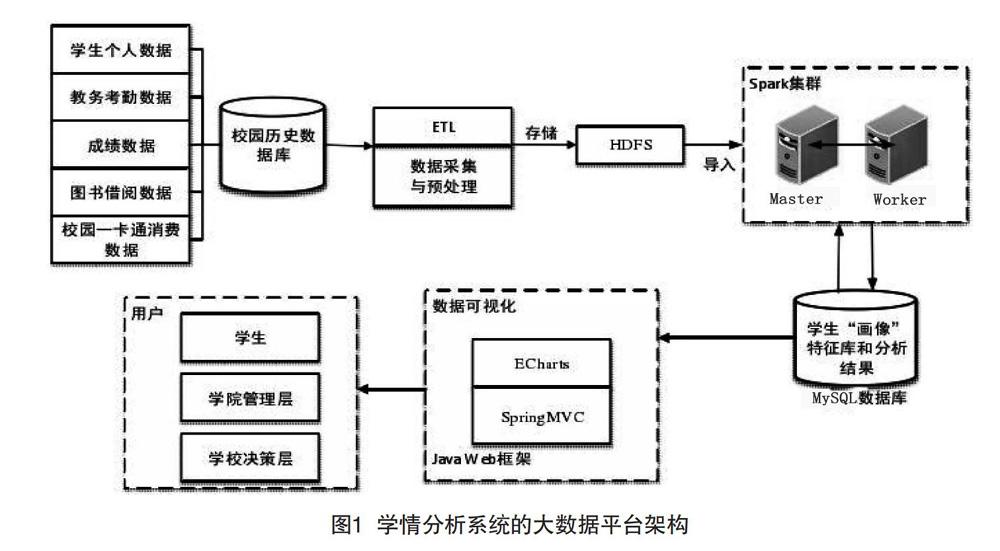
基于大数据的学生业绩分析系统主要包括两个部分:(1)大数据处理与分析平台。(2)数据挖掘并行算法分析平台。大数据处理与分析是对原始数据进行ETL的过程,数据挖掘并行算法则是对经过处理后数据的挖掘,以便可以发现潜在有价值的信息。整体架构如图1所示。
3.1 环境设计
本文研究是在VMwara Workstation10.0.0上建立两台虚拟机,搭建Hadoop集群环境,一台作为NameNode,另一台作为DataNode。(1)搭建Linux系统。本次的Hadoop虽然能够适应不同的系统,但是由于其搭建环境较为复杂,因此可以选择Linux系统,消除其搭建环境复杂的弊端。(2)Hadoop平台搭建。采取完全分布式模式,在搭建前需要安装两个程序:Java语言的软件开发工具包(Java Development Kit,JDK)和安全壳协议(Secure Shell,SSH)。Hadoop运行的过程中需要管理远端Hadoop守护进程,因此在启动后需要通过SSH和DataNode进行交互。
3.2 数据预处理
纳入本次研究的大部分数据来源于相关部门的原始数据,而这些数据难免会存在某些数据记录的缺失。因此,为了保证结果的准确性,需要对学生业绩的原始数据进行清洗,通过清洗提高数据的准确性。根据大数据挖掘技术的要求,原始数据清洗过程为:(1)清洗无效数据。对收集的各种数据分析不难发现,在原始数据中存在带有“一”“、”以及空值等不合法的字符,这些字符的存在没有任何的意义。例如高职院校的选修课并不是所有学生都会选择的,因此对于某些学生而言其选修课的成绩则会用“一”代表,但是在分析系统中没有任何的意义,需要系统将其清理出去。(2)数据转换。数据转换就是将不同的课程或者表现用简单的字符代替,例如不同的数字代表不同的课程成绩。(3)数据规范化。数据规范化就是将数据进行分类,明确不同数据区域的分值,例如可以将90分以上的划定为优秀,将80~90分划定为良好,将70~80分划定为中等,60分以下的划定为不合格[2]。
3.3 数据挖掘
数据经过预处理后,需要考虑如何能让数据发挥作用。这就需要采用数据挖掘平台提供的数据挖掘和分析工具、算法进行有价值信息的抽取,从而实现从数据到信息的高效转化。对受教育者的学习数据、行为数据等进行深入分析和挖掘,查找可能存在的问题等重要信息,并利用这些数据为改善受教育者的成绩或学习行为提供个性化的服务。同时,借助数据中一位受教育者的各个维度数据来综合评判学生表现,利用大數据挖掘技术,针对学生存在的问题提供合理的建议与意见。根据平台需求主要使用以下5种数据挖掘技术从大数据分析后的数据中提取有价值数据信息。
(1)预测(Prediction):基于对历史数据的分析,预测新数据的特征或数据的未来发展趋势。例如,要具备知道一个学生在什么情况下尽管事实上有能力但却有意回答错误的能力。
(2)聚类(Clustering):发现数据的内在结构。这对于把有相同学习兴趣的学生分在一组很有用。
(3)相关性挖掘(Relationship Mining):发现各种变量或因素之间的关系,并对其进行解码以便今后使用它们。这对探知学生在寻求帮助后是否能够正确回答问题的可靠性很有帮助[3]。
(4)升华人的判断(Distillation for Human Judgment):建立可视的机器学习模式。
(5)用模式进行发现(Discovery with Models):使用通过大数据分析开发出的模式进行“元学习”(Meta-Study)。
4 结语
随着大数据技术的发展,构建基于大数据的学生学业分析系统是客观了解学生学业情况,准确分析学生学习成绩,提高海量数据分析效果的重要举措。
[参考文献]
[1]程玉霞.数据挖掘在学习成绩预测中的应用研究—以网络教育本科统考英语为例[D].无锡:江南大学,2016.
[2]赵慧琼,姜强,赵蔚,等.基于大数据学习分析的在线学习绩效预警因素及干预对策的实证研究[J].电化教育研究,2017(1):64-71.
[3]李强,赵晨杰,罗先录.基于大数据应用技术的学情分析系统架构分析与设计[J].软件工程,2018(5):38-41.
