基于云计算的智能电网大数据处理技术研究
2019-12-25王建玺
王建玺,岳 圆
(1.平顶山学院计算机学院,河南 平顶山 467000;2.中国人民解放军61267 部队,北京 101114)
1 基于云计算的智能电网大数据处理技术
云计算作为分布式计算的未来发展方向,有效融合了虚拟技术、计算机通信技术,有效实现了任何人在任何时间、地点内借助于计算机最大限度地利用虚拟云计算的资源[[1-3]。
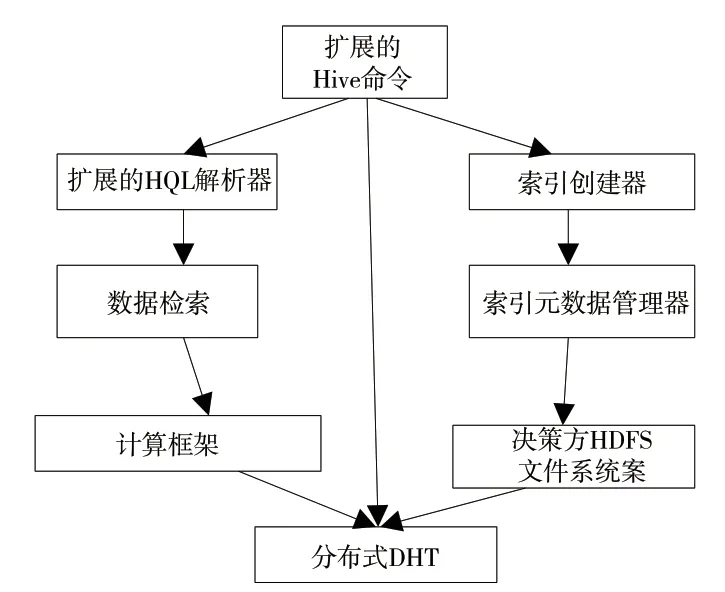
图1 分布式哈希表(DHT)以及网格文件软件结构
1.1 基于网格文件的多维索引
由于Hive 对于索引功能的支持、回复功能比较弱,因此只能利用全表扫描获得需要的大数据信息,浪费了巨额CPU 和IO 数据资源且极大地影响了大数据的分析、整理功能属性[4]。电力大数据具备多维区域查询特点较为清晰、查询维度比较稳定的特征。针对Hive 对索引支持力度比较差的限制性以及电力大数据查询的一系列特征,本文处理技术基于网格文件(GridFile)的分布式多维索引特征,即DG FI (Distributed Grid File Index),主要用于提高多维区域内的查询功能。DG FI(Distributed Grid File Index)基于分布式哈希表(DHT)以及网格文件的重构,其软件结构如图1 所示。
借助于扩展的Hive 命令和HQL 解析器,Hive 分辨并解析出与索引相关的一系列命令。按照查询列表中涉及到的表头、字段、长度以及查询条件等,查找出索引数据的基本结构,在短时间内定位出需要的数据信息,并将检索出来的数据信息交由Hadoop 计算框架处理,执行查询要求的相关计算流程。索引创建器扫描出需要创建索引的表列,利用一致性哈希算法把索引基本结构映射至DHT 节点内进行存储。为了进一步提高功能,索引创建任务就被称之为Map Reduce 任务。
1.2 任务分配与调度模块
对于任务划分的问题,并不是所有电网大数据的处理类应用均可以在云计算平台内完成运行、管理与维护,需要按照应用的具体特征进行细致的划分。智能电网的潮流计算的大数据处理在划分任务时,能够将每个电网预期异常状况的初始参数设计成一个子任务,并将其作为最为基本的工作单元完成操作。任务调度模块的基本功能就是科学、合理地将这些工作单元充分调度到工作机上执行。
调度策略的相关设计必须考虑工作机的配套硬件运行状况和相关软件状况。硬件配置状况包括CPU 的内存空间、主频大小及空余磁盘内存等。软件信息则包括CPU 的利用率、网络宽带运行状况、负载状况及可靠性分析等。容错问题,即云计算的特征。容错策略需自动检测到失效节点信息,并将其逐一排除。
1.3 状态监测数据的存储与管理
相比于以往的互联网应用办法,智能电网实时监测对于数据的可靠性要求更高,所以云计算平台能提供更安全的数据储存和管理手段。本文主要采取Master/Slave 构造把数据拆分为几部分,从而形成多个数据块,分别储存在不同的节点。数据集群由一个Name node 以及一定数量的Data nodes 共同形成。Name node 作为一个中心服务器,主要负责对管理文件的储存空间以及文件的即时性访问进行管理,Data nodes 则负责管理所在数据节点的一系列处理。这种双向节点的设计可以最大化简化系统设计流程。
2 实验与效果分析
为了更加清楚、具体地看出本文提出的基于云计算的智能电网大数据处理技术的实际应用效果,与传统的智能电网大数据处理技术进行对比。
2.1 实验准备
为保证实验的准确性,将两种智能电网大数据处理技术设计置于相同的试验参数下,进行数据处理效率能力的相关实验。试验参数如表1 所示。

表1 试验参数信息
2.2 实验结果分析
实验过程中,将两种不同的智能电网大数据处理技术在相同实验环境中进行对比试验,分析其数据处理能力的变化。实验效果对比如图2 所示。
根据实验结果可知,本文设计的基于云计算的智能电网大数据处理技术在数据处理效率方面要略胜于传统方法,但数据处理效率会有一定波动。
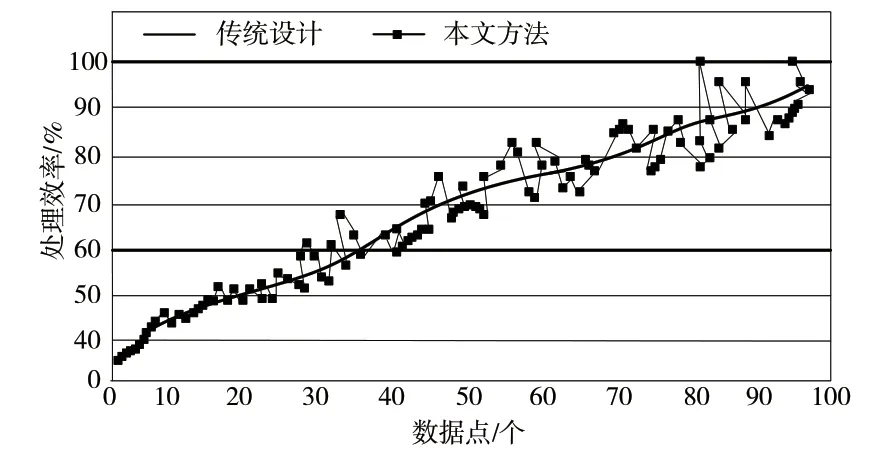
图2 实验对比结果
3 结 论
本文对基于云计算的智能电网大数据处理技术进行了分析。实验论证表明,本文设计的方法具备极高的有效性,以期为基于云计算的智能电网大数据处理技术的研究方法提供理论依据。
