基于语义词向量的自媒体短文本主题建模
2019-12-23黄婵
黄婵

摘 要: 短文本建模的稀疏问题是短文本主题建模的主要问题,文章提出基于詞向量的短文本主题建模模型—语义词向量模型(Semantics Word Embedding Modeling,SWEM)。采用半自动的方法对短文本信息进行扩充,对短文本相应词语进行同义词林处理,增加短文本集合中词共现信息,丰富文档内容,推理出较高质量的文本主题结构,解决短文本的词共现信息不足的问题。实验表明,SWEM模型优于LDA、BTM等传统模型。
关键词: 短文本; 主题建模; 同义词; SWEM
中图分类号:TP311 文献标志码:A 文章编号:1006-8228(2019)12-57-04
Topic modeling of self-media short text based on semantic word vector
Huang Chan
(Ganzhou teachers college, Ganzhou, Jiangxi 341000, China)
Abstract: The sparse problem of short text modeling is the main problem of short text topic modeling. This paper proposes a word-vector based short text topic modeling model SWEM (Semantics word embedding modeling). It uses semi-automatic method to expand short text information, the word in short text is processed with corresponding synonyms of the word, to increase word co-occurrence information in short text set, to enrich document content, so as to infer a high quality text topic structure and to solve the problem of insufficient co-occurrence of words in decisive texts. Experiments show that SWEM model is superior to traditional models such as LDA and BTM.
Key words: short text; topic modeling; synonym; SWEM
0 引言
自媒体是指以现代化、电子化的手段,向不特定的大多数或者特定的单个人传递规范性及非规范性信息的新媒体的总称。通常以短文本的形式活跃于视野中。其特点主要有文本长度较短,内容表达随意常出现一些错别字、同音字词,甚至出现流行网络用语。因此,在海量的短文本数据内挖掘有价值的信息是一项极具挑战的任务。
1 相关研究
主题模型(topic model)是指以非监督学习的方式对文集的隐含语义结构进行聚类的统计模型[1],而主题建模能够从一个文本对象中自动识别它的主题,且发现隐藏的模式,有助于作出更好的决策。自媒体作为短文本的一种常见特性,挖掘其主题具有较强的实用价值,已经得到了科研工作者的关注与研究。
Malone[2]等人在1987年就发表了具有影响力的论文,提出了最早的协同过滤。2003年,Blei等学者提出了隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)[3]模型。晏小辉[4]等的学者提出了一个双词主题模型(Biterm Topic Model,BTM),对双词来建模,构成了双词-主题-单词的三层结构。唐晓波等[5]人建立了基于主题图的用户兴趣模型,运用无尺度图K-中心点算法对主题图进行更深层次的聚类挖掘。邓智龙[6]则提出了用户兴趣关联规则的兴趣发现方法,发现各个兴趣之间的关联规则。赵捧未等[7]提出的用户兴趣模型构建方法是利用了本地节点资源和知识地图的构建。胡吉明等[8]从模块度改进的角度,针对用户兴趣多元化和关系社区的交叉性特点对社区发现算法进行了改进。
从上述的研究成果中可以看出,其核心部分都是建立主题模型,但建模过程中都面临了短文本的稀疏问题,遗憾的是多数作者并没有提出快速而简易的方法。
本文结合其他研究者思路对解决短文本的稀疏问题进行分析与研究。提出语义词向量模型(Semanticswordembedding modeling,SWEM),对词向量进行建模,对海量短文本自媒体信息构建结构化主题,发现社团和意见领袖。
2 一种基于语义词向量的自媒体短文本主题建模
2.1 自媒体短文本主题建模分析
传统的主题模型是对文档产生过程建模,认为存在文档、主题、词三层结构,文档包含多个主题,词由每个词产生,隐式地利用文档级别的词共现信息推理主题结构,这类模型较适应于长文本。然而,短文本文档经过去停用词等手段处理之后,每个文本包含的词数通常非常少,当传统模型应用在短文本时,词频信息和词共现信息严重不足,导致稀疏问题。在使用推理算法时,难以准确地推理出文档中主题分布参数与主题和词的分布参数,大大影响短文本主题建模的效果。因此,解决短文本的稀疏问题是重点。
2.2 语义词向量模型
哈工大同义词词林能针对不同的词语的语义进行不同角度的词汇扩充。面对同义词林的优势,不难想到利用哈工大同义词词林,采用半自动的方法对短文本信息进行扩充,缓解短文本信息量少的问题。将所有的短文本相应词语进行同义词林处理,使文档组成一个语料集合,在短文本语料集合内词共现信息就会明显增加,丰富文档级别的词共现信息,能够推理较高质量的主题结构,解决短文本的词共现信息不足的问题。基于此,提出基于词向量的短文本主题建模模型—语义词向量模型(Semantics Word Embedding Modeling,SWEM)。
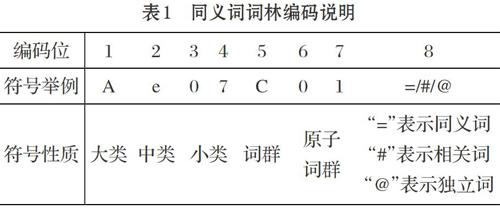
⑴ 同义词词林简介
《同义词词林》[9]是80年代出版的一部對汉语词汇按语义全面分类的词典,收录词语近7万。
同义词词林共提供3层编码,随着级别的递增,词义刻画越来越细,到了第五层,每个分类里词语数量已经不大,常常是只有一个词语,已经不可再分,可以称为原子词群、原子类或原子节点。其中第一级用大写英文字母表示大类;第二级用小写英文字母表示中类;第三级用二位十进制整数表示小类;新增的第四级和第五级的编码与原有的三级编码并构成一个完整的编码,唯一代表词典中出现的词语。具体编码如表1所示。
⑵ SWEM模型
语义词向量模型(Semantics Word Embedding Modeling,SWEM)将假设整个短文本数据集合服从一个主题分布,主题服从高斯分布,对全局内的词向量,包括原来集合内可观察到的词向量和对应词的同义词向量进行建模。
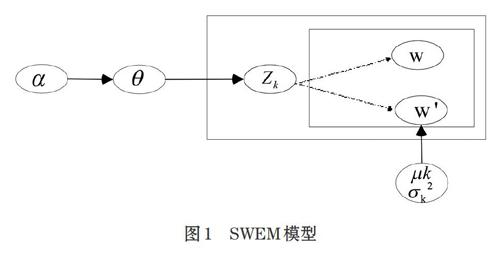
对于短文本来说,文档级的词频信息和词共现信息不足,SWEM模型摒弃了文档级的主题分布,假设整个语料集合服从同一个主题分布,其具体描述表述如下:首先,根据超参数[α]生成语料集合的主题分布[θ],然后,在该主题分部下选择一个主题[Zk],通过参数[μk]和[σk2]生成主题词向量的高斯分布,最后,在这个高斯分布中生成每个词向量。SWEM模型的概率图模型如图1所示。
模型含义:给定一个短文本语料D{d1, d2, ...,dn},每篇文档对应的词向量是[W= w1,w2,...,wn,w'n+1,w'n+2,...,w'n+i],其中w1代表原本文档中的词项,[w1']等代表的是文档中词向量的同义词向量。取zk∈[1,k]当做主题的标量,[θ]表示短文本语料集合的主题分布,其中[θ]采用狄利克雷先验,其超参[α],主题跟词向量之间采用高斯混合分布,[α]代表第k个高斯模型权重,[μk]代表的是第k个高斯模型的均值,[σ2k]代表的是第k个高斯模型的协方差。
⑶ 基于SWEM主题模型描述
① 对每篇文档内词向量进行同义词林泛化,求得隐含词向量[w'] ,加入原来的短文本文档中。
② 对整个短文本语料集合采样一个主题分布:[θ~ Dirichlet(α)]。
③ 对每个主题[Zk],k∈[1,k],采样一个主题词向量分布[ψk~ Gaussian(μk,σ2k)]。
④ 对于每个词向量w∈W,包括原文档的词向量和生成的同义词向量:
(a) 采样一个主题[Zk~Multinomial(θ)];
(b) 采样一个词向量[W~Multinomial(ψk)]。
根据以上的产生式可知:词向量集合W是观测变量,包括原来文本中的词向量和对应生成的同义词向量,主题分布[θ]和主题词向量分布[μk]主题z是隐含变量,[α]为模型超参,[μk],[σ2k]是第k个分部高斯模型的均值和协方差。
给定观测数据词向量集合[W= w1,w2,...,wn,w'n+1,w'n+2,...,w'n+i],其中w1等代表原本文档中的词项,[w'n+1]等代表对应生成的同义词向量。模型是包含 K个高斯分布的高斯混合分布,假设词向量W来自如下的高斯混合分布的似然函数为:
[p(W|p)=i=1N+N'k=1kλkf(wi|uk,σ2k)] ⑴
对式⑴取对数,似然函数变换为:
[log(p(W|p))=i=1N+N'log(k=1kλkf(wi|uk,σ2k))] ⑵
从式⑵中可以看出目标函数难以对其进行求偏导处理。于是采用无EM算法[10]估计参数[λk], [μk], [σ2k]的值。
3 实验
3.1 实验数据
为验证模型的主题建模能力。本文选择近期搜集Twitter自媒体数据165360条数据。在对这些数据进行去噪过滤基础上分词处理,去除停用词等及舍弃在文档集合内出现低于10次数的词。如表2展示了每个数据集的文档数目、词典大小、平均文档的长度。
在词向量的选择上,使用谷歌新闻语料训练的词向量,词向量维数为200。在除停用词等无意义的词后,选择Skip-gram算法训练,其他参数为模型默认值,最终生成数据集。同时在数据集中本文采用Twitter提供的主题标签(Hashtag)功能对数据集进行分类(工具采用线性SVM分类器),并提取其中的内容。抽取20个高频的Hashtag作为分类数据的标签。如表3所示。
从表3中可以看到Twitter数据集的主题种类繁多,能为检验模型分类性能试验提供支持。
3.2 模型对比
实验中首先根据不同模型对文档进行主题建模之后,分别得出文档的主题概率分布,用主题概率分布将文档表示成主题向量,维数为主题的个数,每一维用其包含主题的概率表示。得到文档d的主题向量表示为D=[P(z=1|d),(z=2|d),…,(z=K|d)],然后,随机的在数据集合中选出70%作为训练数据集,其余30%作为测试分类性能的数据集。
为更清晰的对比,本文将选择LDA模型、BTM模型及本文提出的SWEM模型进行对比,验证各种模型在同一短文本数据集上学习主题的能力,并用PMI Score[11]方法进行测评,一般来说,PMI越大表示的是这两个单词主题相关性强。
在各模型的超参数的设置上,为能更好的解决短文本的稀疏问题,分别对LDA模型超参数设置为[α]=0.05,[β]=0.01;BTM模型超参数设置为[α]=50/K,[β]=0.01,并同本文提出的SWEM模型对不同的主题数量下的分类性能PMI Score对比,如图2所示。
4.3 结果分析
从图2中Twitter数据集上模型分类性能实验中可以看出,SWEM模型分类性能优于BTM模型及LDA模型。在主题数为80左右的时候,发现SWEM模型表现达到最好。但是随着主题数增大,分类性能出现下降,可能的原因是某些额外生成的词向量质量降低,随着主题数的增大,干扰了主题的学习的质量。
5 结束语
短文本建模的稀疏问题是短文本主题建模的短板,文章采用半自动的方法对短文本信息进行扩充,缓解短文本信息量少的问题。将所有的短文本相应词语进行同义词林处理,使文档组成一个语料集合,在短文本语料集合内词共现信息就会明显增加,丰富文档级别的词共现信息,能够推理较高质量的主题结构,解决短文本的词共现信息不足的问题。實验表明SWEM模型优于BTM、LDA模型,说明通过同义词向量建模可以解决稀疏问题。
参考文献(References):
[1] Papadimitriou,C.H.,Raghavan,P.,Tamaki,H.and Vempala,S.,2000.Latent semantic indexing:A probabilistic analysis.Journal of Computer and System Sciences,61(2),pp.217-235
[2] Malone,T W,Grant,K R,Turbak,F A,et al. Intelligent information-sharing systems.Communications of the ACM,1987.
[3] Blei D M,Ng A Y,Jordan M I. Latent dirichletallocation[J].Journal of Machine Learning Research,2003.3:993-1022
[4] Yan X,Guo J,Lan Y,et al. A biterm topic model for short texts[C]// Proceedings of the 22nd international conference on World Wide Web.ACM,2013.1445-1456
[5] 唐晓波,张昭.基于混合图的在线社交网络个性化推荐系统研究[J].情报理论与实践,2013.2:91-95
[6] 邓智龙,淦文燕.复杂网络中社团结构发现算法[J].计算机科学,2012.6.
[7] 赵捧未,李春燕,窦永香.语义对等网环境下基于节点知识地图的用户模型构建[J].情报理论与实践,2012.35(2):104-108
[8] 胡吉明,胡昌平.基于关系社区发现改进的用户兴趣建模[J].情报学报,2013.7,32(7):763-768
[9] Mei Jiaju,Zhu Yiming,GaoYunqi,et al.,TongyiciCilin [M]. Shanghai:Shanghai Lexicographical Publishing House,1993.106-108
[10] Moon T K.The expectation-maximization algorithm[J]. IEEE Signal Processing Magazine,1996.13(6):47-60
[11] Newman D,Lau J H,Grieser K,et al.Automatic evaluation of topic coherence[C]//Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2010.100-108
