基于转换的错误驱动学习的藏语词性标注研究
2019-12-23拉毛杰安见才让
拉毛杰 安见才让
摘 要: 词性标注是自然语言处理的基础研究,应用的领域十分广泛。基于转换的错误驱动学习词性标注是一种基于规则的算法,但由于此算法占用大量的计算机资源进行规则的提取,从而造成算法本身偏慢的问题。文章在原有算法的基础上,跳过那些对语料庫的标注不够明显的规则,寻找应用最好的转换规则,使语料库错误标注降到最低,从而达到标注的目的。
关键词: 词性标注; 基于转换学习; 规则; 自然语言处理
中图分类号:TP391.1 文献标志码:A 文章编号:1006-8228(2019)12-28-02
Research on Tibetan part of speech tagging of conversion-based error-driven learning
La Maojie, Anjian Cairang
(School of Computer, Qinghai University for Nationalities, Xining, Qinghai 810007, China)
Abstract: Part-of-speech tagging is the basic research of natural language processing, and the field of application is very extensive. Conversion-based error-driven learning part-of-speech tagging is a rule-based algorithm, but the algorithm takes up a lot of computer resources to extract rules, the algorithm itself is slow. Based on the original algorithm, this paper skips the rules that are not obvious enough to mark the corpus, and finds the best conversion rules to minimize the corpus error labeling, thus achieving the purpose of labeling.
Key words: part of speech tagging; conversion-based learning; rule; natural language processing
0 引言
随着社会信息化的日益增强,互联网越来越成为人们日常生活中的一部分,人们可以越来越多的用自然语言同计算机交流。但是这有个前提,就是计算机能够理解人类的自然语言,这是一个很富有挑战性的问题。这样的问题称作自然语言处理问题,词性标注作为这一领域浅层处理中最基础最重要的技术对整个语言处理起着至关重要的作用[1]。
目前,不同的高校或科研机构在藏语词性标注领域取得了很好的研究成果,但现阶段还没有公认的,规范的,统一的藏语词性标记集[5-6]。所以,训练集、测试集和初始标注器要基于相同的标记集,才会提高准确率。
1 转换规则
基于调研发现,目前词性标注的主流方法有三种, 分别是统计标注法、规则标注法以及两者融合的综合性标注方法[2]。转换规则是基于转换的错误驱动学习算法中最重要的两部分之一,它的设计对最终的结果有很大的影响。基于转换的错误驱动学习算法尽管由于学习每条规则时对整个语料进行遍历,这样在训练时消耗大量的时间[4]。但是,这些经过学习得到的规则,只要把他们按照排好的序列逐个的应用到测试的语料库中即可,方便快速。
一个转换规则由两部分构成:一个是改写规则,另一个是激活环境。
例如:在藏语词性标注中,一个改写规则为:把词w的词性标注改为量词q。激活环境:它的条件为如果w的左相邻词为名词(nj,nd等名词类),w的右相邻为数词。应用这个规则就把下面句子中???的错误标注nj纠正为q。
????/nj??/ca??/f??/cp???/nd????/nj?????/q???/ve?/w
纠正后:????/nj??/ca??/f??/cp???/nd????/q?????/q???/ve?/w
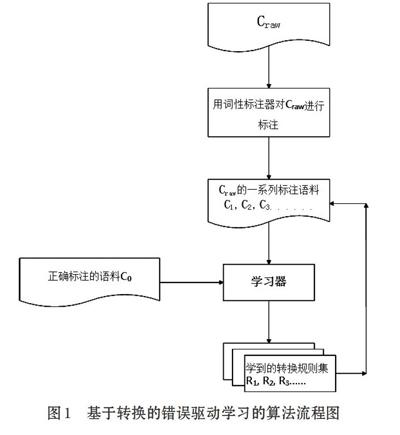
2 基于转换的错误驱动学习的算法描述
(1) 首先用初始标注器对Craw进行标注,得到带有词性标注的语料C1;
(2) 把C1与正确的语料库进行比较和学习,根据标注规则模板得到规则集R1;
(3) 应用R1的每个规则集rj(j=1,…,n)对C1中错误标注进行纠正得到新的语料C1j
(j=1,2,…,n);C1j跟正确的语料标注结果C0比较,可以得到C1j中总的词性标注错误
数Ej(i=1,2,3,…,n);
(4) 选择提高语料标注正确率最高(错误数最小)标注规则r,并加入到规则集R2;
(5) 用r标注语料库C1形成新的标注语料库C2;
(6) C1=C2,重复(2)—(5),直到不能发现新的并能提高语料标注正确率的规则;
当需要标注新的语料库时,首先用一个标注器进行标注,然后按有序的规则集合R2的顺序依次用相应的规则对上一次标注的语料进行标注,形成最后的标注语料库。
标注使用的规则为:
如果W的左相邻的词为量词,W的右相邻词为名词,则把W的动词标注改为形容词标注[3]。
3 实验分析
本文实验的测试集为200k左右的语料,通过运行系统,生成上下文规则集,通过学习和使用每一条规则,使得准确率提高8.51%,错误数降低了1272个。
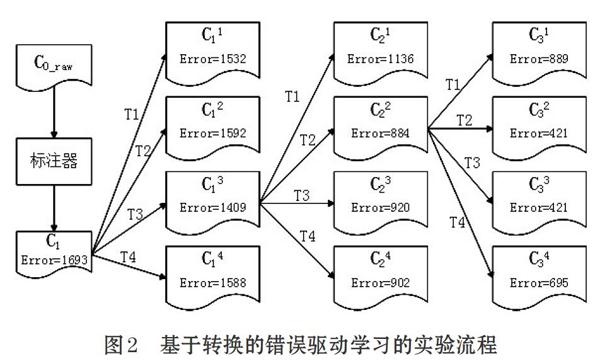
在图2的例子中,一共有四个候选的转换规则(T1,T2,T3,T4)。首先用初始标注器对C0_raw进行词性标注,得到C1,将C1和C0比较,共有2366个错误标注数;然后依次对C1使用转换规则T1,T2,T3,T4,结果是T3使得错误数降得最低。因此,将T3作为学习到的第一条转换规则记录下来。然后对C13依次使用全部候选的转换规则,这次是T2使得错误数降低得最多,因此,将T2作为学习到的第二条转换规则记录下来。然后对C22依次使用全部的转换的候选规则,这次错误数没有再降低,也就是说,没有学到新的转换规则,于是学习过程才停止。
4 结束语
本文在藏语词性结构的深入研究的基础之上,利用转换的错误驱动方法对藏语进行词性标注,使得词性标注准确率不断地提高和错误数不断地降低。这对进一步处理藏语词性标注的研究具有重要的意义。但本文还存在规则提取时间偏长,算法偏慢的问题,对此我们仍需不断地优化和改进算法,不断地突破新技术,使得藏语词性标注进一步研究和完善。
参考文献(References):
[1] 俞士汶.计算语言学概论[M].商务印书馆,2003.
[2] 羊毛卓么.基于HMM藏文词性标注的研究[J].信息系统工程,2017.
[3] 刘颖.计算语言学[M].清华大学出版社,2014.
[4] 安见才让.藏文信息处理原理与技术实现[M].青海民族出版社,2017.
[5] 完么才让.安见才让.藏语词性标注[J].信息与电脑(理论版),2013.
[6] 洛桑嘎登.藏文自动分词与词性标注研究[D].中央民族大学,2016.
