高维不确定数据的子空间聚类算法
2019-12-23万静郑龙君何云斌李松
万静 郑龙君 何云斌 李松


摘 要:如何降低不确定数据对高维数据聚类的影响是当前的研究难点。针对由不确定数据与维度灾难导致的聚类精度低的问题,采用先将不确定数据确定化,后对确定数据聚类的方法。在将不确定数据确定化的过程中,将不确定数据分为值不确定数据与维度不确定数据,并分别处理以提高算法效率。采用结合期望距离的K近邻(KNN)查询得到对聚类结果影响最小的不确定数据近似值以提高聚类精度。在得到确定数据之后,采用子空间聚类的方式避免维度灾难的影响。实验结果证明,基于Clique的高维不确定数据聚类算法(UClique)在UCI数据集上有较好的表现,有良好的抗噪声能力和伸缩性,在高维数据上能得到较好的聚类结果,在不同的不确定数据集实验中能够得到较高精度的实验结果,体现出算法具有一定的健壮性,能够有效地对高维不确定数据集聚类。
关键词:高维;不确定;Clique算法;K近邻
中图分类号:TP311.13
文献标志码:A
Subspace clustering algorithm for high dimensional uncertain data
WAN Jing*,ZHENG Longjun,HE Yunbin,LI Song
School of Computer Science and Technology, Harbin University of Science and Technology, Harbin Heilongjiang 150080, China
Abstract:
How to reduce the impact of uncertain data on high dimensional data clustering is the difficulty of current research. Aiming at the problem of low clustering accuracy caused by uncertain data and curse of dimensionality, the method of determining the uncertain data and then clustering the certain data was adopted. In the process of determining the uncertain data, uncertain data were divided into value uncertain data and dimension uncertain data, and were processed separately to improve algorithm efficiency.KNearest Neighbor (KNN) query combined with expected distance was used to obtain the approximate value of uncertain data with the least impact on the clustering results, so as to improve the clustering accuracy. After determining the uncertain data, the method of subspace clustering was adopted to avoid the impact of the curse of dimensionality. The experimental results show that highdimensional uncertain data clustering algorithm based on Clique for Uncertain data (UClique) has good performance on UCI datasets, has good antinoise performance and scalability, can obtain better clustering results on high dimensional data, and can achieve the experimental results with higher accuracy on different uncertain datasets, showing that the algorithm is robust and can effectively cluster high dimensional uncertain data.
Key words:
highdimension; uncertain; Clique (Clique for all data) algorithm;KNearest Neighbor (KNN)
0 引言
數据挖掘已经被广泛应用到日常生活与工作中,在诸多领域都扮演着重要的角色,例如交通[1]、医疗[2]、金融[3]、制药[4]等。聚类是数据挖掘中的一种无先验条件的无监督分析方法。将数据集中的数据根据各自的特征分成不同的簇,簇间尽可能相异,簇内尽可能相似。聚类的方法多种多样,经典的聚类方法有基于划分的聚类方法[5]、基于层次的聚类方法[6]、基于网格的聚类方法[7]、基于密度的聚类方法[8],还有基于模型的聚类方法[9]。伴随着学者们的努力研究,新的聚类方法被提出,例如高维数据的聚类方法[10]、图像聚类[11]等。
高维数据的聚类容易受到维度灾难的影响,传统的聚类方法不能有效地对高维数据聚类。经过国内外学者的不断研究,高维数据的聚类方法可以被分为以下3种:基于降维的聚类[12]、基于子空间的聚类和其他的聚类方法[13]。子空间聚类方法是选出部分数据作为高维数据的子空间,在子空间上聚类代替在整个数据集上聚类。子空间聚类在加权方法上分为软子空间聚类算法与硬子空间聚类算法,在搜索方法上可分为自下而上的子空间聚类算法与自上而下的子空间聚类算法。
Liu等[14]提出基于SMDM(Selfadapted Mixture Distance Measure)的聚类算法,解决了不确定数据聚类效率低的问题,算法提出了自适应的混合距离,降低了不确定数据对聚类结果的影响。算法在聚类效果、伸缩性等方面有良好的表现,由于算法中核密度估计的计算量较大,算法在对高维数据聚类时效果不明显。针对高维数据的维度灾难问题,Goyal等[15]提出了ENCLUS(ENtropybased CLUStering)算法,证明了在普通的低秩子空间聚类效果更好,算法采用ORT(Optimal Rigid Transform)得到更适合的子空间集合,但文中大量的对子空间优化步骤影响了算法的效率,导致算法的伸缩性较差。由于高维数据聚类过程精度都难以得到保证,Zhang等[16]提出lLMSC(linear Latent Multiview Subspace Clustering)算法与gMLSC(generalized Latent Multiview Subspace Clustering)算法,采用对多个视图的潜在表示来探索数据点之间的关系,可以有效处理噪声。引入神经网络来探索更广泛的关系,可以有效提高聚类精度。但是针对不同类别的数据,算法的效果不够理想,因为线性模型不足以在任何情况下模拟不同视图之间的相关性,而且无法得到全局最优解,因此算法的普适性较差。随后Zhu等[17]提出CSSub(Clustering by Shared Subspaces)算法,该算法提出新的子空间聚类框架,使相邻的核心点能够根据它们共享的子空间数量聚类,将候选子空间选择和聚类划分为两个独立的过程,算法的普适性得到提高。但是受到了子空间聚类的限制,算法对子空间的质量比较敏感。针对这个问题,Li等[18]提出基于CLF(Cauchy Loss Function)的子空间聚类算法,提出了采用CLF抑制噪声,减小噪声对算法的影响。算法从理论上证明了阻效应,能够保持原始数据的局部结构,提高子空间的质量,但算法对参数c和λ敏感。为了避免算法对参数的敏感问题,Chen等[19]提出SSSC(Structured Sparse Subspace Clustering)算法。算法定义了一个新的分组效应集群(GroupingEffectWithinCluster, GEWC),并结合分割矩阵提出了一种新的惩罚方法,避免参数影响的同时,提高了算法的聚类精度。而范虹等[20]提出基于烟花算法优化的软子空间聚类算法(Soft Subspace Clustering based on Fireworks Optimization Algorithm, FWASSC)算法,设计了新的目标函数,弥补了对噪声敏感的缺点,设计了新的隶属度计算方法,提高了聚类精度。同时傅文进等[21]从全局结构到局部结构的子空间聚类方法(Global structure and Local structure of data for Subspace Clustering, GLSC)算法,利用高斯核函数对l2范数加权,得到了较好的聚类结果。文献[19-21]算法的共同问题是大量迭代计算导致算法耗时较长。
本文采用子空间聚类算法对高维不确定数据聚类。Clique算法是经典的子空间聚类算法,适合对高维数据聚类,但是并不适合对不确定数据聚类。针对高维不确定数据的聚类问题,根据Clique算法提出改进。高维不确定数据分为维度不确定与值不确定两种情况:维度不确定又分为部分数据维度不确定与数据集维度不确定;值不确定分为值模糊与缺失值。针对这4种情况下分别提出算法:在针对高维部分数据不确定的情况下采用结合均值和方差的Clique算法;在针对高维数据集维度不確定的情况下,通过计算维度之间的相关性得到确定的维度集合,结合Clique算法聚类;针对高维数据的值模糊与存在缺失值的情况,提出结合K近邻(KNearest Neighbor,KNN)算法的Clique算法。
本文的贡献主要有4个方面:
1)针对高维不确定数据中,部分数据维度不确定的情况提出了针对维度不确定数据的Clique(Clique for Uncertain Dimension of Partial Data, UDPClique)算法,根据不同维度的维度特点,将不确定数据划分到相应维度。
2)针对数据集维度不确定的高维不确定数据提出针对维度不确定数据集的Clique(Clique for Uncertain Dimensions of Datasets, UDDClique)算法,根据维度之间的关联程度判断不确定维度的确定程度,得到确定的维度。
3)针对空间位置模糊的高维不确定数据提出针对模糊数据的Clique(Clique for Fuzzy Value range, UFVClique)算法,根据不确定数据在确定数据集中的K近邻分布情况判断不确定数据的所属网格,利用网格的邻近性聚类。
4)针对存在缺失值的高维不确定数据提出针对缺失数据的Clique(Clique for Missing Values, UMVClique)算法,根据不确定数据在确定数据集中的K近邻,填补缺失值。
1 基础知识
定理1 反单调性[22]。如果数据集S在k-1维空间是密集的,那么在任意的k维空间中数据集S也是密集的。
定义1 最近邻(Nearest Neighbor,NN)查询[23]。给定数据对象集合P和一个查询点q,最近邻查询就是在集合P中找到一个数据对象子集,满足下面条件:
NN(q)={p∈P|o∈P,
dist(q,p)≤dist(q,o)}(1)
定义2 K近邻查询[23]。给定数据对象集合P和一个查询点 q,K最近邻查询就是在集合P中找到K个数据,这K个数据距离q的距离小于其他数据距离q的距离。
定义3 空间不确定数据[24]。在m维空间Rm中,给定一组不确定空间数据对象O={o1,o2,…,on},距离函数d:R2m→R,对于每个不确定空间数据对象oi,都有一个概率密度函数fi:Rm→R定义不确定对象的分布。根据概率密度函数得到:fi(x)≥0,x∈Rm,∫x∈Rmfi(x)dx=1通过期望距离衡量不确定对象的相似度。
定义4 期望距离[24]。不确定空间对象oi和任意点p的期望距离定义:
ED(oi,p)=∫x∈Aifi(x)Dist(x,p)dx; p∈Rk(2)
假设A={A1,A2,…,Ak}是一个有界、全部有序域的集合,S=A1,A2,…,Ak是一个k维的数值空间,其中A1,A2,…,Ak表示S的k个维。k维数据X=〈x1,x2,…,xk〉表示S上的数据在t时刻的一个点集,其中xi=〈xi1,xi2,…,xik〉表示一个数据点,xij为数据点xi的第j维的值。
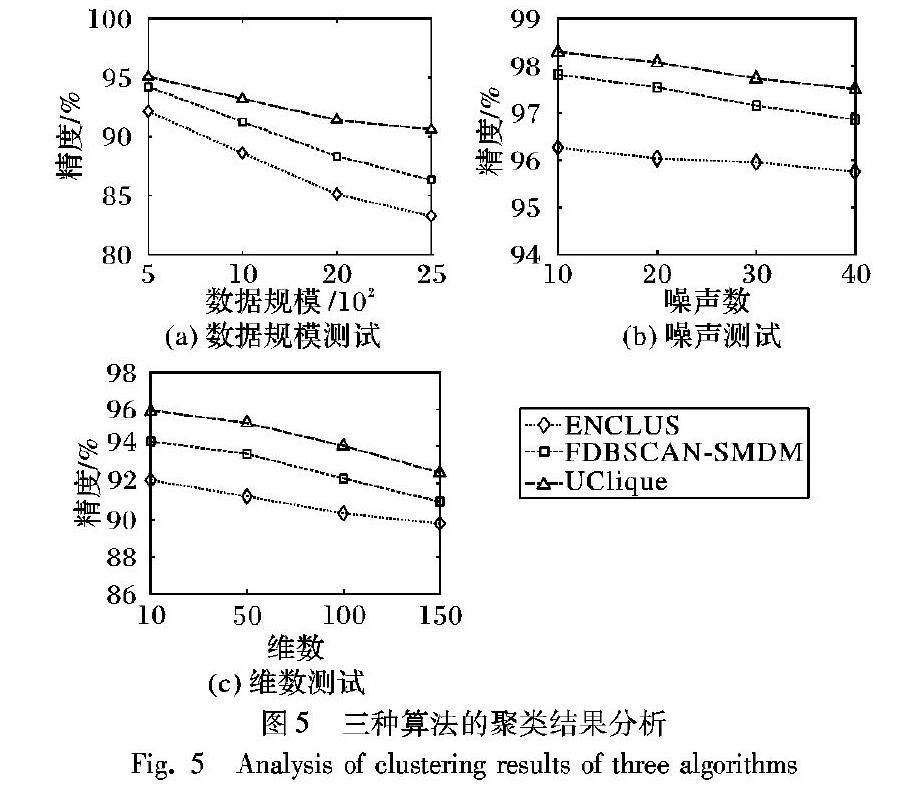
定义5 子空间[25]。数值空间Sub=At1×At2×…×Atg,其中g小于维数k,并且当i 定义6 多维度关联[26]。维度是具有某一相同特征数据的集合,多维度则是从不同层次、不同角度呈现数据,数据之间可以有交叉。 2 维度不确定聚类算法 高维数据的不确定性可以分为值不确定和维度不确定,针对维度不确定的情况采用子空间聚类算法。 2.1 部分数据维度不确定的子空间聚类算法 日常生活中存在一些维度不确定的高维数据,这些数据在数据集中是游离的,在聚类过程中会降低聚类精度。本节针对这种情况提出UDPClique算法。 高维数据中存在部分数据不确定的情况,针对数据的维度不确定导致聚类精度低的问题, 提出UDPClique算法。根据不确定数据在不同维度的差异,可以判断出不确定数据的维度分布,可以将不确定数据确定化。采用Clique算法对确定的数据集聚类。 高维数据集中的数据的特点与维度相关,不同维度中的数据特点不同。针对这一情况,按照维度特点将不确定数据划分到最相似的维度中,可以最大限度地减小不确定数据对聚类精度的影响。虽然存在划分错误的可能,但由于划分是符合维度的数据特点,所以对聚类精度的影响不大。 假设存在不确定数据ui={a1,a2,…,aj},其中i代表不确定数据在数据集中的位置,a1,a2,…,aj代表不确定数据j个维度的值。可以通过计算不确定数据在各个维度与维度均值的差异来判断不确定数据的维度划分。差异的计算公式为: mk(ai)=|ai-k|(3) 其中:mk(ai)代表在第k个维度的差异值,k代表在第k个维度的均值。 将数据集的维度按照方差大小排列,方差计算公式为: Vak=1nk∑nki=1(dk(i)-k)2(4) 其中:Vak为第k个维度的方差,dk(i)表示第k个维度中第i个数据的值,k为第k个维度的均值,nk表示第k个维度的数据总数。 均值和方差可以有效体现一个数据集的数据特征,方差可以反映出数据集的密集程度,方差越小的数据集越密集,方差越大的数据集越稀疏。均值可以在一定程度上体现数据集中数据的分布情况,但会受到数据集的密集程度的影响。方差小的数据集,其均值所体现的数据集的位置分布更准确,方差大的数据集,其均值所体现的数据集位置分布准确性较低。根据这两点,将不确定数据未知维度的值划分到更相似的维度,能够最大限度地保证聚类精度。但首先要按照数据集方差从大到小的顺序依次划分不确定数据的维度。保证密集的维度首先被划分,密集的维度均值的代表性强,对划分的准确度要求高; 而稀疏的维度,对划分的准确度要求低。 算法1的具体步骤为:首先将数据分为确定数据和不确定数据,并将确定数据按维度划分,得到维度集。采用式(4)计算每个维度集方差,并按照方差大小排列维度集,采用式(3)计算每个维度集的均值,根据均值将不确定数据划分维度。得到确定数据集,采用Clique算法对确定数据集聚类。 算法1 UDPClique()。 输入 数据集C={d1,d2,…,dn}; 输出 聚类结果。 程序前 begin 1) 将C中的确定数据存入CE集合,將C中的不确定数据存入UCE集合; 2) 将CE集合中的数据按照维度划分维度集合; 3) 根据距离计算式(4)计算各个维度集合的方差; 4) 将维度集合按照方差从小到大的顺序排列; 5) 根据式(3)按顺序计算不确定数据各个未知维度值与各个维度的差异,并将不确定数据划分到差异最小的维度中; 6) 将不确定数据从UCE集合中删除; 7) 不断重复步骤3)~6),直到UCE集合为空; 8) Clique(CE); end 程序后 由文献[23]可得步骤8)Clique算法的时间复杂度为O(ck+kn),其中k为数据集维数,n为数据集数据总数,c为簇的个数;步骤1)、2)的时间复杂度为O(n);步骤3)~7)的时间复杂度为O(kn+k)。那么算法1的时间复杂度为O((c+1)k+(2k+1)n)。 2.2 数据集维度不确定子空间聚类算法 针对数据集维度不确定的高维数据提出UDDClique聚类算法,利用维度之间的关联性得到数据集的确定维度,并采用Clique算法对数据集聚类。 日常生活中经常会碰到记录散乱的数据,数据中存在缺失值、脏数据等情况。这种情况大量出现在高维数据中的某一维度或多个维度中,数据集的维度确定性降低,聚类质量会受到影响。高维数据具有稀疏性,当数据集的维度不确定时,数据集的稀疏程度会受影响,聚类的难度增加。高维数据的维度之间具有相关性,相关的维度之间存在相应的关联规则,如果某一个维度和多个维度具有强的关联性,那么这个维度存在的可能性就比较高,对于数据集来讲这个维度的信息比较重要,对聚类分析帮助比较大。根据这个特点对数据集维度不确定的数据聚类。 定义7 维度相关度。存在高维数据集C={d1,d2,…,dn},数据集C中拥有维度a与维度b。假设维度a中一共存在n个数据在维度b中也能够找到,那么维度a与维度b的相关度为n。记为: co(a|b)=co(b|a)=n(5) 定义8 维度关联度。存在高维数据集C,数据集C中拥有维度a与其他维度。维度a与其他维度的相关度的和,为维度a与数据集C的关联度。公式为: co(a)=∑ki=1co(a|i); i≠a(6) 其中:a为第a个维度,k为数据集的维数。 采用数据集矩阵计算各个维度的相关度。数据集矩阵的生成方式:以数据作为矩阵横轴,以维度作为竖轴。每一个数据在存在的维度上为1,不存在的维度上为0, 这样矩阵每一列代表一个数据存在于哪些维度,每一行代表每一个维度拥有哪些数据。通过矩阵可以很方便地得到维度密度与维度相关度。维度密度是维度中集合数据的个数,记为da(a代表在第a个维度)。 在针对高维数据的子空间聚类算法中,维度密度是子空间生成的一个标准。在针对高维不确定数据时,维度密度无法体现维度存在的可能性。在维度密度的基础上结合维度相关度,即可以保证数据量足够多,足以保证维度的确定性。可选维度公式为: chi=coi×di(7) 高维数据聚类算法的计算复杂,子空间聚类方法通过在子数据集的聚类来减小计算量,子空间中的数据要在一定程度上能够代替整个数据集。首先子空间中的数据要足够多,才有聚类分析的价值; 其次子空间中的数据要足够重要,无关的数据只会增加聚类的复杂性。在高维不确定数据集中,维度集确定性也是子空间选择数据的标准,不确定数据会增加聚类的时间并降低聚类精度。根据子空间数据的特点选取子空间,将维度密度大而且关联性强的维度用作生成子空间。保证了子空间中有足够多并足够重要的数据,数据的确定性也得到了保证。采用均值作为维度选择阈值,维度关联度是在维度密度的基础上得到的,维度关联度大的维度维度密度必然大,反之则不成立。针对这一点,根据式(7)得到的数据会呈现明显的两极分化,以均值作为阈值可以有效区分维度之间的差异。计算公式为: ε=1k∑ki=1ch(i)(8) 在得到确定维度并生成确定数据集后,采用Clique算法对确定数据集聚类。结合维度相关性将不确定维度确定化可以最大限度地提高聚类精度。根据式(8)将适合聚类的维度选择出来,生成确定数据集,针对确定的高维数据集Clique算法可以有效地聚类。 算法2步骤:首先生成数据矩阵,从矩阵中可以得到每个维度的维度密度,可以得到维度之间的相关度,并计算维度关联度。通过计算维度关联度与维度密度可以得到维度准确性,并依据维度确定性得到确定维度。用Clique算法对确定的数据集聚类。 算法2 UDDClique()。 输入 数据集C={d1,d2,…,dn}; 输出 聚类结果。 程序前 begin 1) 以维度作为竖轴,以数据作为横轴生成数据矩阵; 2) 根据式(5),计算维度相关度; 3) 根据式(6),计算维度关联度; 4) 根据式(7),计算维度确定性; 5) 不断循环步骤2)~4),直到得到所有维度的确定性; 6) 根据式(8),计算确定性阈值,并根据阈值选出确定维度存入集合CE; 7) Clique(CE); end 程序后 由文献[23]可得步骤7)Clique算法的时间复杂度为O(ck+kn),k为数据集维数,n为数据集数据总数,c为簇的个数。假设数据集拥有k个维度,拥有n个数据:步骤1)生成矩阵的时间复杂度为O(n);步骤2)~5)得到每个维度的維度相关度、维度关联度、维度确定性所需要的时间复杂度为O(n);步骤6)计算维度确定性阈值并得到确定维度的时间复杂度为O(k),那么算法2的时间复杂度为O((c+1)k+(k+2)n)。 3 值不确定子空间聚类算法 2.1节、2.2节主要分析了高维不确定数据中的数据集维度不确定和部分数据维度不确定两种情况。本章针对高维不确定数据中的数值模糊和数据值缺失问题,分别提出了相应的聚类算法。 3.1 数据值模糊聚类 在高维数据中的模糊数据会降低聚类精度,增加聚类的难度。本文提出结合KNN算法的子空间算法UFVClique,解决高维数据集中数据模糊的聚类问题。 高维不确定数据中的值模糊问题为主要的研究目标,不确定数据的维数是确定的。不确定数据由一组概率样本数据点定义,概率样本数由随机采样生成。针对高维不确定数据集,采用先划分子空间再将不确定数据确定化的方法,减少计算步骤。针对各个子空间中的不确定数据,采用式(2)计算不确定数据的距离,并结合KNN算法的网格划分方法,将不确定数据确定化。在得到确定数据集后由Clique算法对确定数据集聚类。如图1所示, 图中不确定数据没有确定的位置。 图中不确定数据没有确定的位置,实线标识范围是不确定数据可能出现的范围,点代表确定数据。 根据Clique算法首先划分子空间并对子空间作网格划分处理。由于本节中不确定数据的维度是确定的,子空间划分与网格划分过程并不会受到不确定数据的影响。 采用KNN算法在子空间内查找距离不确定数据最近的K个数据,并根据这K个数据的网格归属情况划分不确定数据。不确定数据与确定数据的距离计算由式(2)给出。根据不确定数据到确定数据的距离,可以得到不确定数据对于确定数据所属网格的网格归属度,公式为: griBl(i,s)=∏k∈gri(s)rd(i,K) (9) 其中:i为不确定数据,s为网格,K为网格内的确定数据,d(i,K)为不确定数据i到确定数据K的距离,r为网格最长边长度。判断一个不确定数据是否属于一个网格的条件有两个:一是,网格中的数据与不确定数据的距离;二是,网格中数据的个数。只有当网格中的数据距离不确定数据足够近而且足够多时,才能判定不确定数据属于这个网格。式(9)根据网格邻近性,以网格边长作为距离比较标准,使不相邻网格的网格归属度小于1。通过Clique算法的密集网格选取过程将稀疏网格排除。在网格密度与网格距离上保证了不确定数据网格划分的准确性。 通过计算不确定数据与K个最近邻数据所属网格的网格归属度得到不确定数据的网格归属度集合: bel(i)= {griBl(i,s1),griBl(i,s2),…,griBl(i,sK)}(10) 其中:griBl(i,sK)为不确定数据在网格sK的网格归属度。根据不确定数据的网格归属度集合,计算Max(griBl(i,sK))是否大于1:如果大于1,那么将不确定数据数据划分到这个网格中;如果小于1,那么不确定数据为孤立数据,不作划分。 采用KNN算法的不确定数据网格划分方法将所有不确定数据划分到相应网格中,生成确定数据集,并采用Clique算法聚类。针对不确定数据采用KNN算法将不确定数据确定化,可以最大限度地避免由不确定数据引起的聚类精度低的问题。根据k个数据的分布情况判断不确定数据的分布,比只根据期望距离判断不确定数据的分布准确性高。Clique算法可以有效地针对确定的高维数据集聚类。 算法3的具体步骤:按照Clique算法选取密集维度生成子空间并在子空间内划分网格。采用KNN算法結合式(9)、(10)计算不确定数据的网格归属,利用网格的邻近性,将不确定数据确定化。当数据集中不存在不确定数据时,采用Clique算法将数据集聚类。 算法3 UFVClique()。 输入 数据集C={d1,d2,…,dn}; 输出 聚类结果。 程序前 begin 1)自下而上地查找密集单元; 2)将子空间内的数据分为确定数据集CE与不确定数据集UCE; 3)根据距离计算公式计算不确定数据的K个最近邻数据; 4)根据式(9)、(10)计算不确定数据的网格归属度以及网格归属度集合; 5)根据网格归属度集合将不确定数据划分到相应网格,并从UCE集合中删除; 6)不断循环3)~5),直到UCE集合为空; 7) Clique(CE); end 程序后 步骤1)的时间复杂度为O(n),n为数据集中数据个数。步骤2:划分数据集的时间复杂度为O(n)。由文献[22]可得,步骤3)KNN的时间复杂度为O(nlogn),n为数据集数据总数。假设数据集的维数为k,数据规模为n,存在m个不确定数据。那么步骤3)~6)查找m个不确定数据的KNN时间复杂度为O(mnlogn),将不确定数据确定化的时间复杂度为O(k)。由文献[23]可得步骤7)Clique算法的时间复杂度为O(ck+kn)。算法3的时间复杂度为O((c+1)k+(k+1)n+mnlogn)。 3.2 数据值模糊聚类 数据在录入时会产生缺失值,导致数据的确定性下降。传统处理数据缺失值的方法有4种:丢弃缺失值、填补缺失值、预测缺失值和直接分析。针对存在缺失值的高维数据集聚类算法,提出UMVClique算法,采用KNN的方式填补缺失值生成确定数据集,采用Clique算法对确定的数据集聚类。 定义9 数据维度缺失度。存在高维缺失值a,a在n个维度存在空值,那么n就是a的数据维度缺失度,简称缺失度。 根据定理1可以推出,k-1维确定数据的最近邻也是k维不确定数据的最近邻,可以根据不确定数据在确定维度的K个最近邻,填补不确定数据的缺失值,保障了数据集的完整,避免了聚类精度的丢失。UMVClique算法主要分为3个步骤:首先根据Clique算法生成子空间,其次将子空间内的缺失值填补,最后采用Clique算法对确定数据集聚类。 首先计算不确定数据的缺失度,并将不确定数据按照缺失度从小到大的顺序排列。缺失度高的数据填补难度高,同理缺失度高的数据填补准确度低,先对缺失度低的不确定数据填补,可以在一定程度上保障填补的准确性并缩短填补时间。 查找距离不确定数据在确定维度的K个最近的数据,m代表密集维度的个数,n代表不确定数据所缺失的维数。由于不确定数据在m-n维中的值是确定的,采用欧氏距离计算在单个维度中两个数据的距离,那么在m-n维中不确定数据与确定数据的距离计算公式为: dm-n(u,c)=∑m-ni=1(ui-ci)2(11) 其中:ui为不确定数据在第i维的值,ci为确定数据在第i维的值。 根据式(11)计算不确定数据在m-n维的K个最近邻数据,并根据这K个数据填补第n维中缺失数据,计算公式为: dj(u)=1K∑m-ni=1ai(12) 其中j为不确定数据所在的存在空值的维度,根据式(12)将缺失值填补。 采用式(11)计算不确定数据在无缺失值的维度的K近邻,并根据式(12)填补不确定数据,生成确定数据集,采用Clique算法将确定数据集聚类,Clique算法可以有效地对高维数据集聚类。 算法4的具体步骤:先将数据集中的缺失部分填补,再将数据集聚类。填补的过程为,先将数据集分为两个部分,一部分为缺失值,另一部分为确定数据。将缺失值按缺失度从小到大的顺序排列,并按顺序将缺失值与确定数据集中的数据比较,将相似度最大的K个确定数据的均值填补到缺失值中,得到确定数据并放入确定数据集中,直到没有缺失值存在时再对数据集聚类。 算法4 UMVClique()。 输入 数据集C={d1,d2,…,dn}; 输出 聚类结果。 程序前 begin 1)将数据集分为两部分一部分是确定数据集CE,另一部分是不确定数据集UCE; 2) 计算UCE集合中所有数据的缺失度; 3) 按缺失度从小到大的顺序对UCE集合中的数据排序; 4) 结合式(11),按顺序找出不确定数据的K个最近邻; 5) 结合式(12)计算K个最近邻在缺失值所在维度的数据均值M。 6) 将M填入缺失值,填补后的缺失值从UCE集合中删除,填入CE集合中; 7) 不断循环步骤4)~6),直到UCE集合为空; 8) Clique(CE); end 程序后 由文献[23]可得,步骤8)Clique算法的时间复杂度为O(ck+kn),k为数据集维数,n为数据集数据总数,c为簇的个数。由文献[22]可得,步骤4)KNN的时间复杂度为O(nlogn),n为数据集数据总数。步骤1)的时间复杂度为O(n)。步骤2)~3)的时间复杂度为O(m)。步骤4)~7)计算不确定数据在k-1维的KNN数据的时间复杂度为O(m(k-1)×(n-1)logn)。填补缺失值的时间复杂度为O(km),那么算法4的时间复杂度为O(m((k-1)(n-1)logn+k+2)+ck+(k+1)n)。 4 基于子空间的复杂高维不确定数据聚类算法 在2.1节与2.2节中,针对部分数据维度不确定與数据集维度不确定的情况,分别采用均值和方差与维度相似的方法将不确定数据确定化,并由Clique算法对确定的数据集聚类。在3.1节、3.2节中,针对数据值模糊与缺失值的情况,采用KNN算法将不确定数据确定化,并采用Clique算法对确定数据集聚类。 针对复杂的高维不确定数据提出UClique算法。算法可以对复杂的高维不确定数据聚类,结合算法1、2、3、4各自的特点对复杂的高维不确定数据聚类。 针对复杂的高维不确定数据,按照先确定维度后确定数据的方式。高维数据中维度是数据值的载体,先对维度确定化有利于减少计算步骤。在将不确定维度确定化的过程中,首先确定数据集的维度再确定部分数据的维度。高维数据集聚类过程中首先要降维,不确定维度确定化过程可以和降维过程同时进行,有利于减小算法的时间复杂度。高维模糊数据的聚类涉及大量的期望距离计算,对缺失值的聚类过程比对模糊数据的聚类要快,而且填补缺失值是在划分子空间之后在网格化分之前,模糊数据确定化是在网格化分之后。所以在将不确定数据值的确定化过程中,先填补缺失值,后将模糊数据网格化。例如在数据集维度不确定而且存在缺失值时,可以首先采用UDDClique算法得到确定的维度,再采用UMVClique算法将缺失值填补得到确定数据集,最后采用Clique算法将确定数据集聚类。同样在其他的情况混合出现时,可以分别采用相应的解决方法对数据聚类。 算法5的具体步骤:首先判断数据集是否存在维度不确定,如果有判断是数据集的维度不确定还是部分数据维度不确定。数据集维度不确定,采用算法2; 部分数据不确定采用算法1。如果只是数据不确定,判断是数据模糊还是有空值,如果是数据模糊,采用算法3; 如果是有缺失值,采用算法4。流程如图2所示。 算法5 UClique()。 输入 数据集C={d1,d2,…,dn}; 输出 聚类结果。 程序前 begin 1) 判断C中是否存在不确定维度,是则执行步骤2),否则执行步骤3); 2) 采用UDDClique算法得到确定维度; 3) 判断C中是否存在维度不确定数据,是则执行步骤4),否则执行步骤5); 4) 采用UDPClique算法得到不确定数据的确定维度; 5) 判断C中是否存在缺失数据,是则执行步骤6),否则执行步骤7); 6) 采用UMVClique算法填补缺失值; 7) 判断C中是否存在模糊数据,是则执行步骤8),否则执行步骤9); 8) 采用UFVClique算法将不确定数据划分到确定网格中; 9) Clique(C); end 程序后 假设数据集的维数为s,数据规模为n,存在m个不确定数据。根据UDPClique算法的时间复杂度,那么步骤4)和步骤9)的时间复杂度为O(cs+sn+mn+km)。根据UDDClique算法的时间复杂度,那么步骤2)和步骤9)的时间复杂度为O(k+n+ck+kn)。根据UFVClique算法的时间复杂度,那么步骤8)和步骤9)的时间复杂度为O((c+1)k+(k+1)n+mnlogn)。根据UMVClique算法的时间复杂度,那么步骤6)和步骤9)的时间复杂度为O(m((k-1)(n-1)logn+k+2)+ck+(k+1)n)。由于步骤1)、3)、5)、7)为判断条件时间复杂度为O(1)。那么算法5的时间复杂度为:O(m((k-1)(n-1)logn+k+2)+ck+(k+1)n)。 5 实验 为了检验本文算法的准确性和效率,本文的实验环境是2.5GHz Intel i5 CPU,内存4GB,操作系统为Window7。實验数据采用的是UCI(University of CaliforniaIrvine)数据库中的数据集Iris、Wine、Seed、Zoo。由于UCI数据集是经典的测试机器学习数据集,具有信息完整、数据种类多的特点,适合根据不同的实验类型测试算法的各方面数据。本文主要考察高维数据集测试算法在高维数据中的表现,还被用于生成不同类型的不确定数据集,测试算法针对存在不确定数据的高维数据集中的表现。数据集的类别数与实例数由表1给出。 本文采用不同的方式生成不同的不确定数据集,以对算法进行多方面的测量。由于ENCLUS算法针对不确定数据能够得到良好的聚类结果,FDBSCANSMDM(Fast DBSCAN algorithmSMDM)算法针对高维数据能够得到良好的聚类结果,实验过程中选取文献[15]中的ENCLUS算法与文献[14]中的FDBSCANSMDM算法作为比较算法。分别测量算法在不同的不确定数据集之下聚类精度、CPU时间、算法的伸缩性以及抗噪声能力。每组实验重复10次取均值作为最终的实验结果,并提供方差作为对算法准确鲁棒性的参考。 表2是UClique算法,FDBSCANSMDM算法与ENCLUS算法在UCI数据集上的比较。由实验结果可以看出,ENCLUS算法、FDBSCANSMDM算法和UClique算法按照准确率由高到低的顺序依次排列,三个算法准确率差距小,从整体上看三个算法的准确率都很高。而且三个算法的准确率方差较小,算法具有较好的鲁棒性。但是在所用时间上,ENCLUS算法、UClique算法和FDBSCANSMDM算法按照所用时间从短到长的顺序排列。UClique算法存在大量将不确定数据确定化步骤,例如针对数据集维度不确定时的维度选择方法等,可以将不确定数据确定化,起到规范数据集的作用。但是在针对少量不确定数据存在的数据集,起到的作用小,效果不明显,大量时间用在不确定数据确定化和距离函数计算上。FDBSCANSMDM采用双加权的方式对不确定数据聚类,对高维数据不敏感,面对高维不确定数数据集,所消耗的时间较长而且聚类效果不明显。 图3是最近邻个数K的取值对UClique算法精度影响的实验结果,可以看出:在K值取5~15时,精度单调递增;在K取20时,精度下降。由此可以推断出K的最佳取值范围在10~15。 采用4种方式生成4种不同的不确定数据集。不确定数据集1为维度不确定数据集,在确定数据集中任取2个维度a,b。将维度a中的数据任意去掉一半生成新的维度a′,将维度b中的任意一半添加到b中生成新的维度b′,将维度a中的任意一半数据与维度b中的任意一半数据混合生成维度c′,并任取(0,1]中任意数值作为维度存在度映射到数据集的所有维度上。不确定数据集2为部分数据维度不确定数据集,在确定数据集中任取k个数据生成不确定数据。k为数据集维数,任取(0,1]中任意数值作为维度存在度映射到每个不确定数据所存在的维度上。不确定数据集3为数值模糊数据集,在每个维度上任取数据集中2%的数据按照文献[24]中不确定数据集生成方法生成数值模糊数据集。不确定数据集4为缺失值数据集,在每个维度上任取1%的数据将其数值定义为缺失值。 图4(a)是三种算法对4种高维不确定数据集的聚类精度实验结果。数据集1是高维维度不确定数据集,数据集2是高维部分数据维度不确定数据集,数据集3是高维值模糊数据集,数据集4是高维缺失值数据集。从图中可以看出,在数据集1~3中算法聚类精度按照Uclique、FDBSCANSMDM和ENCLUS从高到低的顺序排列,而数据集4中稍有不同。4个数据集都是高维不确定数据集,ENCLUS算法适合对高维数据集的聚类,针对不确定数据聚类效果差,而FDBSCANSMDM算法适合针对不确定数据集聚类,针对高维数据聚类效果较差。数据集4是缺失值数据集,FDBSCANSMDM和ENCLUS算法的聚类效果较差。UClique算法针对这4种数据集可以有效地聚类,在聚类精度上UClique算法最高。 图4(b)是三个算法在4个不确定数据集上的时间实验,在所用时间上FDBSCANSMDM、UClique和ENCLUS按照从多到少的顺序排列。UClique算法中计算期望距离和将不确定数据确定化需要大量的计算,占用了较长时间,而FDBSCANSMDM算法中对加权等步骤占用了较长时间,FDBSCANSMDM针对高维数据聚类效果较差。 采用仿真数据集来进行接下来的实验,仿真数据集的特点是用户可以通过输入参数来控制数据集的维度、结构、大小和在各个维度上的取值范围等等。分别测试数据规模、噪声、维数对算法精度的影响,实验结果如图5。 由图5所示,在数据规模不断增加的情况下,三种算法的聚类精度都在不断下降,并逐渐收敛。UClique算法与ENCLUS算法采用子空间聚类的方法,对于大规模数据有一定的免疫能力,FDBSCANSMDM算法也对数据规模不敏感,所以在数据规模达到一定程度之后聚类精度会逐渐平稳, 可以得出UClique算法伸缩性良好。 在数据规模与维数不变的情况下,噪声不断增加,三种算法的精度按UClique、FDBSCANSMDM和ENCLUS从大到小的顺序排列。在噪声不断增加的情况下,三种算法精度都有不同程度的下降但是整体下降幅度小,具有较好的稳定性。可以得出UClique算法对噪声有一定的耐受性。 在数据规模不变的情况下,维数不断增加,三种算法的精度按UClique、FDBSCANSMDM和ENCLUS从大到小的顺序排列。在维数不断增加的情况下,三种算法的精度都有不同程度的下降但是整体下降幅度小,聚类精度一直维持在较高的标准。可以得出UClique算法的维数伸缩性良好。 6 結语 针对高维不确定数据中的不同情况分别提出了解决方法:针对高维数据中部分数据维度不确定的情况,提出了UDPClique算法,采用结合均值和方差将不确定数据确定化;针对数据集维度不确定的高维不确定数据提出了UDDClique算法,采用计算维度相似度的方式得到数据集的确定维度;针对值范围模糊的高维不确定数据提出UFVClique算法,采用KNN算法判断不确定数据的所归属的网格;针对含有缺失值高维不确定数据提出了UMVClique算法,采用KNN算法填补缺失值。最终采用Clique算法对确定数据集聚类。最后提出了UClique算法,针对复杂的高维不确定数据聚类。经理论分析与实验验证,本文算法可以很好地对高维不确定数据聚类,算法的伸缩性与抗噪声能力较好。 参考文献 (References) [1] CRISTBAL T, PADRN G, QUESADAARENCIBIA A, et al. Systematic approach to analyze travel time in roadbased mass transit systems based on data mining[J]. IEEE Access, 2018, 6:32861-32873. [2] JEZEWSKI M, CZABANSKI R, LESKI J M. Fuzzy classifier based on clustering with pairs ofεhyperballs and its application to support fetal state assessment[J]. Expert Systems with Applications, 2019, 118(15):109-126. [3] CHARLES V, TSOLAS I E, GHERMAN T. Satisficing data envelopment analysis: a Bayesian approach for peer mining in the banking sector[J]. Annals of Operations Research, 2018,269(1/2): 81-102. [4] FERRERO E, AGARWAL P. Connecting genetics and gene expression data for target prioritisation and drug repositioning[J]. Biodata Mining, 2018, 11(1):7. [5] FRNTI P, SIERANOJA S.Kmeans properties on six clustering benchmark datasets[J]. Applied Intelligence, 2018, 48(12): 4743-4759. [6] TRIPATHI A, PANWAR K. Modified CURE algorithm with enhancement to identify number of clusters[J]. International Journal of Artificial Intelligence and Soft Computing, 2016,5(3):226-240. [7] ZHENG Z, MA Y, ZHENG H, et al. UGC: realtime, ultrarobust feature correspondence via unilateral gridbased clustering[J]. IEEE Access, 2018, 6: 55501-55508. [8] SEYEDI S A, LOTFI A, MORADI P, et al. Dynamic graphbased label propagation for density peaks clustering[J]. Expert Systems with Applications,2019, 115: 314-328. [9] YANG M S, LAI C Y. A robust EM clustering algorithm for Gaussian mixture models [J]. Pattern Recognition, 2012, 45(11):3950-3961. [10] BRODINOV , ZAHARIEVA M, FILZMOSER P, et al. Clustering of imbalanced highdimensional media data[J]. Advances in Data Analysis & Classification, 2017, 12(2):261-284. [11] ZHU W, YAN Y. Joint linear regression and nonnegative matrix factorization based on selforganized graph for image clustering and classification[J].IEEE Access, 2018, 6: 38820-38834. [12] AAMARI E, LEVRARD C. Stability and minimax optimality of tangential delaunay complexes for manifold reconstruction[J]. Discrete & Computational Geometry, 2018, 59(4): 923-971. [13] WANG Y, DUAN X, LIU X, et al. A spectral clustering method with semantic interpretation based on axiomatic fuzzy set theory[J]. Applied Soft Computing, 2018, 64: 59-74. [14] LIU H, ZHANG X, ZHANG X, et al. Selfadapted mixture distance measure for clustering uncertain data[J]. KnowledgeBased Systems, 2017, 126:33-47. [15] GOYAL P, KUMARI S, SINGH S, et al. A parallel framework for gridbased bottomup subspace clustering[C]// Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics. Piscataway: IEEE, 2016:331-340. [16] ZHANG C,FU H, HU Q, et al. Generalized latent multiview subspace clustering[EB/OL].[2018-03-20]. https://ieeexplore.ieee.org/document/8502831. [17] ZHU Y, TING K M, CARMAN M J . Grouping points by shared subspaces for effective subspace clustering[J]. Pattern Recognition, 2018, 83: 230-244. [18] LI X, LU Q, DONG Y, et al. Robust subspace clustering by cauchy loss function[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 30(7): 2067-2078. [19] CHEN H, WANG W, FENG X. Structured sparse subspace clustering with groupingeffectwithincluster[J]. Pattern Recognition, 2018, 10(83):107-118. [20] 范虹,侯存存,朱艳春,等.烟花算法优化的软子空间MR图像聚类算法[J].软件学报,2017,28(11):3080-3093. (FAN H, HOU C C, ZHU Y C, et al. Soft subspace algorithm for MR image clustering based on fireworks optimization algorithm[J]. Journal of Software, 2017, 28(11): 3080-3093.) [21] 傅文进,吴小俊.基于l_2范数的加权低秩子空间聚类[J].软件学报,2017,28(12):3347-3357.(FU W J, WU X J. Weighted low rank subspace clustering based on l_2 norm[J]. Journal of Software, 2017, 28(12): 3347-3357.) [22] SEIDL T. Nearest neighbor classification[M]// Data Mining in Agriculture. Berlin: Springer, 2009: 83-106. [23] ALTMAN N S. An introduction to kernel and nearestneighbor nonparametric regression[J]. American Statistician, 1992, 46(3):175-185. [24] 肖宇鹏,何云斌,万靜,等.基于模糊C均值的空间不确定数据聚类[J].计算机工程,2015,41(10):47-52.(XIAO Y P, HE Y B, WAN J, et al. Clustering of space uncertain data based on fuzzy Cmeans[J]. Computer Engineering, 2015, 41(10): 47-52.) [25] 周晓云, 孙志挥, 张柏礼, 等. 高维数据流子空间聚类发现及维护算法[J]. 计算机研究与发展, 2006, 43(5):834-840.(ZHOU X Y, SUN Z H, ZHANG B L,et al. An efficient discovering and maintenance algorithm of subspace clustering over high dimensional data streams[J]. Journal of Computer Research and Development, 2006, 43(5): 834-840.)
