改进的属性约简算法及其在肝癌微血管侵犯预测中的应用
2019-12-23谭永奇樊建聪任延德周晓明
谭永奇 樊建聪 任延德 周晓明


摘 要:基于鄰域粗糙集的属性约简算法在进行属性约简时只考虑单一属性对决策属性的影响,未能考虑各属性间的相关性,针对这个问题,提出了一种基于卡方检验的邻域粗糙集属性约简算法(ChiSNRS)。首先,利用卡方检验计算相关性,在筛选重要属性时考虑相关属性之间的影响,在降低时间复杂度的同时提高了分类准确率; 然后,将改进的算法与梯度提升决策树(GBDT)算法组合以建立分类模型,并在UCI数据集上对模型进行验证; 最后,将该模型应用于预测肝癌微血管侵犯的发生。实验结果表明,与未约简、邻域粗糙集约简等几种约简算法相比,改进算法在一些UCI数据集上的分类准确率最高;在肝癌微血管侵犯预测中,与卷积神经网络(CNN)、支持向量机(SVM)、随机森林(RF)等预测模型相比,提出的模型在测试集上的预测准确率达到了88.13%,其灵敏度、特异度和受试者操作曲线(ROC)的曲线下面积(AUC)分别为87.10%、89.29%和0.90,各指标都达到了最好。因此,所提模型能更好地预测肝癌微血管侵犯的发生,能辅助医生进行更精确的诊断。
关键词:属性约简;卡方检验;梯度提升树;微血管侵犯;邻域粗糙集
中图分类号:TP181
文献标志码:A
Improved attribute reduction algorithm and its application to
prediction of microvascular invasion in hepatocellular carcinoma
TAN Yongqi1, FAN Jiancong1,2*, REN Yande3, ZHOU Xiaoming3
1.College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao Shandong 266590, China;
2.Provincial Key Laboratory for Information Technology of Wisdom Mining of Shandong Province, Qingdao Shandong 266590, China;
3.The Affiliated Hospital of Qingdao University, Qingdao Shandong 266555, China
Abstract:
Focused on the issue that the attribute reduction algorithm based on neighborhood rough set only considers the influence of a single attribute on the decision attribute, and fails to consider the correlation among different attributes, a Neighborhood Rough Set attribute reduction algorithm based on Chisquare test (ChiSNRS) was proposed. Firstly, the Chisquare test was used to calculate the correlation, and the influence between the related attributes was considered when selecting the important attributes, making the time complexity reduced and the classification accuracy improved. Then, the improved algorithm and the Gradient Boosting Decision Tree (GBDT) algorithm were combined to establish a classification model and the model was verified on UCI datasets. Finally, the proposed model was applied to predict the occurrence of microvascular invasion in hepatocellular carcinoma. The experimental results show that the proposed algorithm has the highest classification accuracy on some UCI datasets compared with the reduction algorithm without reduction and neighborhood rough set reduction algorithm. In the prediction of microvascular invasion in hepatocellular carcinoma, compared with Convolution Neural Network (CNN), Support Vector Machine (SVM) and Random Forest (RF) prediction models, the proposed model has the prediction accuracy of 88.13% in test set, the sensitivity, specificity and the Area Under Curve (AUC) of Receiver Operating Curve (ROC) of 88.89%, 87.5% and 0.90 respectively are the best. Therefore, the prediction model proposed can better predict the occurrence of microvascular invasion in hepatocellular carcinoma and assist doctors to make more accurate diagnosis.
Key words:
attribute reduction; Chisquare test; gradient boosting tree; microvascular invasion; neighborhood rough set
0 引言
原发性肝细胞癌(HepatoCellular Carcinoma, HCC)是最常见的恶性肿瘤之一,在我国HCC恶性肿瘤致死率排名第二位[1]。HCC术后复发率高、无瘤生存率低的特点一直是研究者们关注的重点[2]。有研究发现影响HCC术后复发和无瘤生存的因素有很多,其中,微血管侵犯(MicroVascular Invasion, MVI)一直被认为是重要影响因素[3-4]。
近年来,国内外引入一些模型和方法来预测微血管侵犯的发生,用来辅助临床医生进行诊断决策[5-6]:文献[7]采用单因素分析和Logistic多因素回归分析方法,研究证明肿瘤病理学分级是无微血管侵犯的肝细胞癌术后复发和无瘤存活的关键预测因子;文献[8]从影像组学出发探讨MVI发生与影像组学特征之间的关系,经图像分割、特征提取、特征筛选和分类判别,使用支持向量机(Support Vector Machine, SVM)模型进行预测,受试者操作曲线下的面积达到了0.76;文献[9]从肝脏磁共振T2加权成像图像纹理特征出发,对纹理特征进行统计学分析,其受试者操作曲线下的面积达到了0.78。上述方法集中在研究与MVI发生的相关性因素以及利用传统机器学习算法进行建模分析,在特征提取方面,没有充分考虑特征之间的冗余性和相关性,导致效果不理想。
粗糙集理论(Rough Sets)是一种进行数据分析的理论工具,用于处理模糊的、不完全和海量的数据,可对数据进行降维和特征提取,在各个领域都有广泛的应用[10-11]。文献[12]将粗糙集理论与模糊C均值(Fuzzy CMeans, FCM)算法结合,提出一种改进的主分量启发式属性约简算法进行降维,用来对轨道电路故障进行诊断。粗糙集理论限制数据为离散类型,在处理连续型数据时需要进行离散化,这会导致数据信息的丢失。邻域粗糙集是在粗糙集理论的基础上提出的一种可以直接处理连续性数据的理论,避免了信息的丢失,能够更好地对数据进行特征的提取,在医学决策[13]、农业治理[14]、故障检测[15]等方面都有广泛应用。文献[16]将邻域粗糙集和粒子群优化算法进行结合,用来提取肿瘤分类的特征基因。文献[17]提出了在邻域粗糙集框架下的熵测度,设计了一种基于邻域颗粒和熵测度的基因选择算法。从上述文献中可以看出,大多数文献没有考虑属性间的相关性,可能会导致属性约简效果不理想,因此,本文引入卡方检验计算相关性的方法,提出了一种基于卡方检验的邻域粗糙集属性约简算法(Neighborhood Rough Set attribute reduction algorithm based on ChiSquare test, ChiSNRS),充分考虑属性间的相关性,筛选出最主要的属性,并与梯度提升树模型结合来建立肝癌微血管侵犯预测模型,旨在为术前MVI的诊断提供有效的帮助。
1 相关理论
1.1 邻域粗糙集
粗糙集理论是由波兰数学家Pawlak在1982年提出来的,是一种处理分析不确定的知识和有模糊数据的数学工具,其主要思想是将那些不精确的或者不确定的知识用已经存在于知识库中的知识来近似地表达。粗糙集理论的核心内容是属性约简,属性约简是一个剔除冗余属性的过程。
关于邻域粗糙集的相关定义如下:
定义1 在给定的一个M维实数空间Ω中,有Δ=RN×RN→R,则称Δ为RN上的一个度量(距离),若Δ满足以下的3个条件:
1)Δ(x1,x2)≥0,当且仅当x1=x2时等号成立,x1,x2∈RN;
2)Δ(x1,x2)=Δ(x2,x1),x1,x2∈RN;
3)Δ(x1,x3)≤Δ(x1,x2)+Δ(x2,x3),x1,x2,x3∈RN。
则称(Ω,Δ)为度量空间。Δ(xi,xj)为距离函数,用来表示元素xi和元素xj之间的距离。
定义2 存在于给定的实数空间Ω上的一个非空有限集合U={x1,x2,…,xn},对xi的δ邻域定义为:
δ(xi)={x|x∈U,Δ(x,xi)≤δ}(1)
其中δ≥0。
定义3 在给定实数空间Ω上的非空有限集合U={x1,x2,…,xn}及其上的邻域关系N,即二元组NS=(U,N),XU,则X在邻域近似空间NS=(U,N)中的上近似和下近似分别为:
NX={xi|δ(xi)∩X≠,xi∈U}(2)
NX={xi|δ(xi)X,xi∈U}(3)
则可以得出X的近似边界为:
BN(X)=NX-NX(4)
其中X的下近似NX为正域,与X完全无关的区域为负域,即:
Pos(X)=NX(5)
Neg(X)=U-NX(6)
定义4 给定一个邻域决策系统NDS=(U,C∪D),决策属性D将论域U划分为N个等价类(X1,X2,…,XN),BC则决策属性D关于子集B的上、下近似分别为:
NBD=∪Ni=1NBXi(7)
NBD=∪Ni=1NBXi(8)
其中,
NBX={xi|δB(xi)∩X≠,xi∈U}(9)
NBX={xi|δB(xi)X,xi∈U}(10)
同樣可得决策系统的边界为:
BN(D)=NBD-NBD(11)
邻域决策系统的正域和负域分别为:
PosB(D)=NBD(12)
NegB(D)=U-NBD (13)
决策属性D对条件属性B的依赖度为:
kD=γB(D)=|PosB(D)||U| (14)
由式(14)可得依赖度kD是单调的,若B1B2…A,则γB1(D)≤γB2(D)≤…≤γA(D),则条件属性B相对于决策属性D的重要度为:
sigγ(B,C,D)=γC(D)-γC-B(D) (15)
1.2 基于列聯表的独立性卡方检验
卡方检验是一种常用的计算两个变量之间相关性大小的数学工具,它主要包括适合性检验和独立性检验。在独立性检验中,最常用的是统计量,对于二分类问题常用的方法是利用2×2列联表进行相关性的计算,在肝癌微血管侵犯的预测中,肝癌病人只有有微血管侵犯和无微血管侵犯两种,因此选择使用2×2列联表进行相关性的计算。2×2列联表的形式如表1所示。
一般地,对于两个研究变量X和Y,X有两个取值X1和X2,Y有两个取值Y1和Y2,于是得到表1所示的统计数据。要推断两个变量X和Y是否具有相关性以及相关性的大小,可按照下列步骤进行:
1)提出假设H0: X和Y没有关系,则假设H1:X和Y有关系。
2)根据2×2列联表和式(16)计算卡方值:
χ2=n(ad-bc)2(a+b)+(c+d)+(a+c)+(b+d)(16)
其中n=a+b+c+d。
3)查对临界值,根据临界值检验卡方检验是否具有统计学意义。若结果表明有统计学意义,则统计量的值越大,两个变量的相关性越强, 即拒绝假设H0,接受假设H1,得出结论,X和Y有关系。
1.3 梯度提升决策树
梯度提升决策树(Gradient Boosting Decision Tree, GBDT)是基于一种梯度提升框架的决策树分类算法,“梯度提升”指的是在每一次迭代的过程中,都需要减少上一次迭代中的残差,而在残差减少的梯度方向上建立一个新的模型。决策树是依据特定的分裂原则将特征空间划分为多个区域,每个区域返回一个值作为决策树的决策值。
将梯度提升的思想与决策树分类算法相结合,即在每一次迭代中,在上一次迭代产生的模型的残差减少的梯度方向上建立一棵新的决策树模型,若迭代次数为N次,则会得到N个决策树模型,这N个模型又称为弱分类器,通过对N个弱分类器的加权处理或者投票选择而构成一个最终的GBDT分类器模型。其训练过程如下所示。
1)初始化弱分类器
2)对于迭代轮数m=1,2,…,M,执行:
①对每个训练样本i=1,2,…,N,计算负梯度,即残差:
rim=-L(yi, f(xi))f(xi)f(x)=fm-1(x)(17)
②将①中得到的残差作为样本新的真实值,并将数据(xi,rim)(i=1,2,…,N)作为下一棵决策树训练数据,得到一棵新的回归树fm(x),其对应的叶子节点区域为Rjm(j=1,2,…,J),其中J为回归树t的叶子节点的个数。
③对叶子节点所在的区域j=1,2,…,J计算最佳的拟合值:
γjm=argminγ∑xi∈RjmL(yi, fm-1(xi)+γ)(18)
④更新强分类器:
fm(x)=fm-1(x)+∑Jj=1γjmI; x∈Rjm(19)
3)得到强分类器:
f(x)=fM(x)+∑Mm=1∑Jj=1γjmI; x∈Rjm(20)
2 基于卡方检验的邻域粗糙集属性约简算法
2.1 算法主要思想描述
从式(15)中可以看到属性重要度的计算公式为sigγ(B,C,D)=γc(D)-γC-B(D),这意味着某个属性B的重要度等于从条件属性C中剔除属性B后对分类决策属性的影响程度。当某个属性的重要度数值为0时,表明该属性对分类决策属性没有任何影响,可以进行约简删除。
从上述描述中可以看出邻域粗糙集属性约简算法在利用依赖度计算重要度时,仅仅考虑了某个单一属性对决策属性的直接影响,没有考虑到多个属性之间的相互作用,这可能会使某些重要的属性被误删除,导致约简效果的不理想,影响最终的分类效果。
文献[18]提出了一种改进的邻域粗糙集属性约简算法,该算法在计算某一属性重要度时考虑了除该属性外的所有其他的属性,实验效果较为理想,但该算法没有考虑到某一属性与其他属性之间的相关性的大小,因此本文提出了一种基于卡方检验的邻域粗糙集属性约简算法(ChiSNRS)。卡方检验是一种计算属性之间相关性的假设检验方法,通过与邻域粗糙集属性约简算法相结合,既考虑单一条件属性的重要度,又考虑与该属性相关性大的属性的影响,从而对冗余属性进行约简。
定义5 给定一个邻域决策系统NDS=(U,C∪D),决策属性D将论域U划分为N个等价类(X1,X2,…,XN),BC,若biB,由卡方检验计算出与属性bi最为相关的m个属性k1,k2,…,km组成相关属性集合Km,即k1,k2,…,kmKm,则对任意单个属性bi在条件属性集C相对于决策属性D的重要度为:
sigγ(bi,C,D)=sigγ(bi,C,D)+
1m∑mj=1[sigγ(kj,C-bi,D)-sigγ(kj,C,D)]=
γC(D)-γC-bi(D)+
1m∑mj=1[γC-bi(D)-γC-bi-kj(D)-
(γC(D)-γC-kj(D))](21)
其中:sigγ(bi,C,D)为原始的bi对决策属性D的重要度,即条件属性集C对决策属性D的依赖度与去除bi后的条件属性集对决策属性D的依赖度之差。
sigγ(kj,C-bi,D)可看作条件属性bi的相关属性集合Km中的某个相关属性kj在条件属性集C除bi后的集合对决策属性D的重要度,其计算公式等同于:sigγ(kj,C-bi,D)=γC-bi(D)-γC-bi-kj(D),可以解释为除bi后的条件属性集对决策属性D的依赖度与除bi和bi的相关属性kj后的条件属性集对决策属性D的依赖度之差。
sigγ(kj,C,D)指的是bi的相關属性kj在条件属性集C相对于决策属性D的重要度。
sigγ(kj,C-bi,D)-sigγ(kj,C,D)指bi的相关属性kj在条件属性集C除bi后的集合相对于决策属性D的重要度与bi的相关属性kj在条件属性集C相对于决策属性D的重要度之差,即为属性bi在其相关属性kj影响下对决策属性的影响所起到的作用。
1m∑mj=1[sigγ(kj,C-bi,D)-sigγ(kj,C,D)]指bi的相关属性集中每一个属性在除bi后的条件属性集相对于决策属性的重要度与bi的相关属性集中每一个属性在条件属性集相对于决策属性的重要度的差值的和然后取其平均,即bi在其相关属性对决策属性的影响所起到的平均作用。
以上理论均可以解释得通,因此定义的邻域粗糙集属性重要度的计算公式是可行的,即属性bi对于决策属性的D的重要度由两部分组成:一部分是删除属性bi后,决策属性D直接依赖于条件属性bi降低的幅度;另一部分是删除属性bi和其相关属性kj后,其他条件属性对决策属性的影响所起到的作用。
2.2 UCI数据集验证
为了验证本文提出的基于卡方检验的邻域粗糙集属性约简算法的有效性,运用基于邻域粗糙集的属性约简算法和本文改进的算法分别对UCI上的数据集进行属性约简实验,并运用梯度提升决策树分类器模型计算两种算法属性约简前后的分类准确率,最后根据分类准确率评估两种属性约简算法的效果。本文选择的UCI数据集的属性信息如表2所示。
本文将改进的算法与基于邻域粗糙集的属性约简算法应用于4个UCI数据集中,对数据集进行属性约简后,获得了对应的约简后的属性个数如表3所示。
运用GBDT分类器模型对约简前后的属性进行分类识别,得到两种算法属性约简后的识别准确率如表4所示。从表4中可以得出,基于邻域粗糙集的属性约简算法在进行约简时,会导致一些重要属性被剔除,影响分类的识别准确率。然而,本文改进的基于卡方检验的邻域粗糙集属性约简算法,在计算属性重要度时考虑了多个相关属性间的影响,保留了一些重要属性,在适当降低特征维数的同时,提高了最终的分类识别准确率。
3 肝癌微血管侵犯预测实验
3.1 属性约简效果评估
本文选取的数据集来源于放射科医师收集的已进行肝癌手术的206例病人的医学影像,经图像分割和特征提取之后,共得到了64个影像组学特征用于微血管侵犯的预测研究,而且每个肝癌病人微血管侵犯的有无已准确诊断。
属性约简的算法多种多样,本文选择未属性约简(unreduction)、基于邻域粗糙集的属性约简(NRS reduction)和基于卡方检验的属性约简(ChiS reduction)与本文改进的邻域粗糙集属性约简(ChisNRS reduction)算法进行对比,将约简后的属性放到梯度提升树分类模型中建立肝癌微血管侵犯预测模型,并将肝癌数据中的75%作为训练集用来训练预测模型,剩余25%作为测试集用来测试模型效果。从约简后的属性和约简后分类准确率两方面评估,结果如图1所示。
图片
通过实验发现,邻域粗糙集属性约简后的个数最少,但最终的分类准确率却高于基于卡方检验的属性约简算法,这是因为基于卡方检验的属性约简算法在采用列联表计算属性相关性时,需要对数据进行离散化处理,可能会影响分类准确率,而基于邻域粗糙集的属性约简可以直接对连续数据进行处理,知识约简更准确。本文改进的基于卡方检验的邻域粗糙集属性约简算法约简后的属性相对多了几个,但准确率却高于其他几种算法,这是因为本文算法考虑到了属性间互相影响的作用,提取了更多的重要属性,在最终的对比实验上也取得了最优的效果。
3.2 分类器模型效果评估
本文将改进的属性约简算法分别与卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)、支持向量机(SVM)、随机森林(Random Forest, RF)等常用分类模型结合建立肝癌微血管侵犯预测模型,与基于GBDT的肝癌微血管侵犯预测模型进行比较,使用混淆矩阵来评估每个模型分类准确率、灵敏度和特异度,并使用受试者操作曲线(Receiver Operating Curve, ROC)及曲线下的面积(Area Under Curve, AUC)评估模型的好坏。
在本文提出的基于卡方检验的属性约简算法和梯度提升树结合的肝癌微血管侵犯预测模型中,在实验参数设计上,选择的相关性变量个数m的值是5。
肝癌微血管侵犯预测属于二分类问题,而混淆矩阵是一个基于二分类的二维矩阵。对于预测微血管侵犯的有无,可以产生实际有MVI预测为有MVI(TP(True Positive))、实际有MVI预测为无MVI(FP(False Positive))、实际无MVI预测为有MVI(FN(False Negative))、实际无MVI预测为无MVI(TN(True Negative))四种情况构成混淆矩阵。如表5所示的肝癌微血管侵犯预测的混淆矩阵。根据混淆矩阵,使用式(22)~(24)计算每个模型的准确率(Accuracy)、灵敏度(Sensitivity)和特异度(Specificity)。分类准确率是指模型对有无MVI预测正确的比例,灵敏度指的是所有患MVI的病人中模型预测正确的比例,特异度指的是所有未患MVI的健康人中模型预测正确的比例。
受试者操作曲线(ROC)是评价医学分类模型的通用指标,ROC曲线表示了模型的真正例率和假正例率之间的关系,主要与模型评价中的灵敏度和特异度指标有关。
Accuracy=TP+TNTP+FP+FN+TN(22)
Sensitivity=TPTP+FN (23)
Specificity=TNTN+FP(24)
将本文模型和其余模型的二维混淆矩阵中的值代入公式计算每个模型在测试集上的灵敏度和特异度,如表6所示。
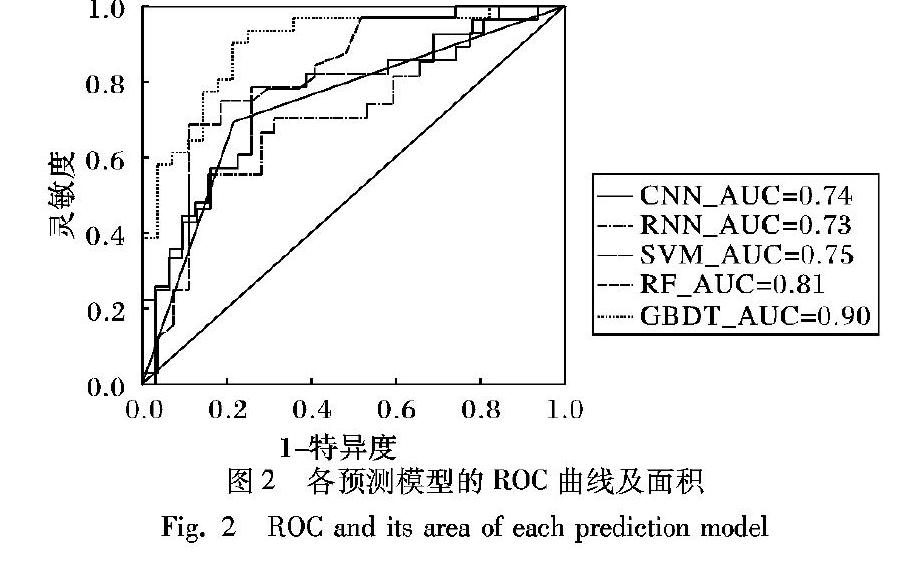
将灵敏度作为坐标轴的纵轴,1-特异度作为横轴,得到各个肝癌微血管侵犯预测模型在测试集上的ROC曲线及曲线下的面积(AUC)如图2所示。
从表6可知,在处理医学数据中较新的模型CNN和RNN的效果不好,分析原因得出深度学习模型要求的数据量是巨大的,而对于本文的肝癌微血管侵犯的数据量只有200多个,深度模型无法从较少的数据中学到更多的知识。而在处理医学数据中常用的SVM和RF两种模型较深度模型效果有所提高。本文改进的肝癌微血管侵犯预测模型在测试集上的准确率、灵敏度和特异度分别达到了88.13%、87.10%和89.29%,相较于其他模型效果提升明显。图2表示各个预测模型的ROC曲线以及曲线下的面积AUC的值,可以看出,本文模型与其他分类器模型相比较,ROC曲线下的面积AUC值达到了0.90,表明本文模型在肝癌微血管侵犯预测上准确率最高,效果最好,能为术前肝癌病人的微血管侵犯的有无提供有效的预测和精确的诊断。
4 结语
在当今人工智能迅猛发展的时代,智能医疗诊断已经成为医学发展的重要趋势,机器学习算法以及疾病预测模型的研究已经成为医学数据挖掘的值得深入探讨的课题。本文提出的算法在对肝癌微血管侵犯预测上进行了相关的研究,为了验证本文算法的有效性,分别从属性约简效果和分类器模型效果进行比较,验证了本文改进的基于卡方检验的邻域粗糙集属性约简算法在对肝癌病人特征约简上的有效性,并从该算法与梯度提升决策树分类模型结合的分类准确率、敏感度和特异度上来看,该预测模型在术前预测肝癌病人有无微血管侵犯上都有很好的效果,能够在医学肝癌微血管侵犯诊断上发挥积极作用。
但本文只针对于属性约简算法作了改进,在将该算法与分类算法融合时未能对分类算法提出改进,而且本文的应用范围只局限在肝癌微血管侵犯数据,未来在其他数据上验证效果。因此在下一步工作中,可以从分类模型和应用范围两个方面作一些改进,可能会有更好的结果。
参考文献 (References)
[1]FERLAY J, SOERJOMATARAM I, DIKSHIT R, et al. Cancer incidence and mortality worldwide: sources, methods and major patterns in GLOBOCAN 2012[J]. International Journal of Cancer, 2015, 136(5): E359-E386.
[2]BRUIX J, GORES G J, MAZZAFERRO V. Hepatocellular carcinoma: clinical frontiers and perspectives[J]. Gut, 2014, 63(5): 844-855.
[3]CHENG Z, YANG P, QU S, et al. Risk factors and management for early and late intrahepatic recurrence of solitary hepatocellular carcinoma after curative resection[J]. HPB, 2015, 17(5): 422-427.
[4]ZHAO H, HUA Y, DAI T, et al. Development and validation of a novel predictive scoring model for microvascular invasion in patients with hepatocellular carcinoma[J]. European Journal of Radiology, 2017, 88: 32-40.
[5]YANG P, SI A, YANG J, et al. A widemargin liver resection improves longterm outcomes for patients with HBVrelated hepatocellular carcinoma with microvascular invasion[J]. Surgery, 2019, 165(4): 721-730.
[6]馬海, 王宇, 杨红春,等. 预测肝癌微血管侵犯及早期复发的临床研究[J]. 中华临床医师杂志(电子版), 2012, 6(20): 58-60.(MA H, WANG Y, YANG H C, et al. Clinical study on predicting microvascular invasion and early recurrence of hepatocellular carcinoma[J]. Chinese Journal of Clinical Physicians (Electronic Edition), 2012, 6(20): 58-60.)
[7]ZHOU L, RUI J, ZHOU W, et al. EdmondsonSteiner grade: a crucial predictor of recurrence and survival in hepatocellular carcinoma without microvascular invasion[J]. Pathology Research and Practice, 2017, 213(7): 824-830.
[8]劉桐桐, 董怡, 韩红,等. 基于影像组学方法的原发性肝细胞癌微血管侵犯和肿瘤分化等级预测[J]. 中国医学计算机成像杂志, 2018, 24(1): 83-87.(LIU T T, DONG Y, HAN H, et al. Prediction of microvascular invasion and tumor differentiation grade in hepatocellular carcinoma based on radiomics[J]. Chinese Journal of Medical Computer Imaging, 2018, 24(1): 83-87.)
[9]武明辉, 谭红娜, 吴青霞,等. 肝脏磁共振T2WI图像纹理特征预测肝细胞癌患者微血管侵犯的价值[J]. 中国癌症杂志, 2018, 28(3): 191-196.(WU M H, TAN H N, WU Q X, et al. Value of MRI T2weighted image texture analysis in evaluating the microvascular invasion for hepatocellular carcinoma[J]. Chinese Journal of Cancer, 2018, 28(3): 191-196.)
[10]VELAYUTHAM C, THANGAVEL K. Detection and elimination of pectoral muscle in mammogram images using rough set theory[C]// Proceedings of the 2012 IEEE International Conference on Advances in Engineering, Science and Management. Piscataway: IEEE, 2012: 48-54.
[11]XIE Q, ZENG H, RUAN L, et al. Transformer fault diagnosis based on Bayesian network and rough set reduction theory[C]// Proceedings of the 2013 IEEE TENCON Spring Conference. Piscataway: IEEE, 2013: 262-266.
[12]李林霄, 董昱. 基于粗糙集理论和FCM的轨道电路故障诊断模型[J]. 铁道标准设计,2018(12): 169-173.(LI L X, DONG Y. Track circuit fault diagnosis model based on principal component heuristic algorithm[J]. Railway Standard Design, 2018(12): 169-173.)
[13]WANG S, LI X, ZHANG S, et al. Tumor classification by combining PNN classifier ensemble with neighborhood rough set based gene reduction[J]. Computers in Biology and Medicine, 2010, 40(2):179-189.
[14]LIU Y, XIE H, CHEN Y, et al. Neighborhood mutual information and its application on hyperspectral band selection for classification[J]. Chemometrics and Intelligent Laboratory Systems, 2016, 157: 140-151.
[15]LI N, ZHOU R, HU Q, et al. Mechanical fault diagnosis based on redundant second generation wavelet packet transform, neighborhood rough set and support vector machine[J]. Mechanical Systems and Signal Processing, 2012,28: 608-621.
[16]徐久成, 徐天贺, 孙林,等. 基于邻域粗糙集和粒子群优化的肿瘤分类特征基因选取[J]. 小型微型计算机系统, 2014, 35(11): 2528-2532.(XU J C, XU T H, SUN L, et al. Feature selection for cancer classification based on neighborhood rough set and particle swarm optimization[J]. Journal of Chinese Computer Systems, 2014, 35(11): 2528-2532.)
[17]CHEN Y, ZHANG Z, ZHENG J, et al. Gene selection for tumor classification using neighborhood rough sets and entropy measures[J]. Journal of Biomedical Informatics, 2017, 67: 59-68.
[18]胡玮. 基于改进邻域粗糙集和随机森林算法的糖尿病预测研究[D].北京: 首都经济贸易大学, 2018: 14-16.(HU W. Research on prediction of diabetes based on improved neighborhood rough set and random forest algorithm[D]. Beijing: Capital University of Business and Economics, 2018: 14-16.)
This work is partially supported by the National Key Research and Development Program of China (2017YFC0804406), the Shandong Natural Science Foundation (ZR2018MF009), the “Taishan Scholar” Climbing Plan in Shandong Province.
TAN Yongqi, born in 1994, M. S. candidate. His research interests include data mining, machine learning.
FAN Jiancong, born in 1977, Ph. D., professor. His research interests include data mining, machine learning.
REN Yande, born in 1973, Ph. D., deputy chief physician. His research interests include neuroimaging study.
ZHOU Xiaoming, born in 1977, M. S., deputy chief physician. His research interests include abdominal imaging diagnosis.
