基于改进的Mask RCNN的行人细粒度检测算法
2019-12-23朱繁王洪元张继
朱繁 王洪元 张继

摘 要:针对复杂场景下行人检测效果差的问题,采用基于深度学习的目标检测中领先的研究成果,提出了一种基于改进Mask RCNN框架的行人檢测算法。首先,采用Kmeans算法对行人数据集的目标框进行聚类得到合适的长宽比,通过增加一组长宽比(2 ∶5)使12种anchors适应图像中行人的尺寸;然后,结合细粒度图像识别技术,实现行人的高定位精度;其次,采用全卷积网络(FCN)分割前景对象,并进行像素预测获得行人的局部掩码(上半身、下半身),实现对行人的细粒度检测; 最后,通过学习行人的局部特征获得行人的整体掩码。为了验证改进算法的有效性,将其与当前具有代表性的目标检测方法(如更快速的区域卷积神经网络(Faster RCNN)、YOLOv2、RFCN)在同数据集上进行对比。实验结果表明,改进的算法提高了行人检测的速度和精度,并且降低了误检率。
关键词:Mask RCNN;行人检测;Kmeans算法;细粒度;全卷积网络
中图分类号:TP391.41
文献标志码:A
Finegrained pedestrian detection algorithm based on improved Mask RCNN
ZHU Fan, WANG Hongyuan*, ZHANG Ji
College of Information Science and Engineering, Changzhou University, Changzhou Jiangsu 213164, China
Abstract:
Aiming at the problem of poor pedestrian detection effect in complex scenes, a pedestrian detection algorithm based on improved Mask RCNNframework was proposed with the use of the leading research results in deep learningbased object detection. Firstly,Kmeans algorithm was used to cluster the object frames of the pedestrian datasets to obtain the appropriate aspect ratio. By adding the set of aspect ratio (2∶5), 12 anchors were able to be adapted to the size of the pedestrian in the image. Secondly, combined with the technology of finegrained image recognition, the high accuracy of pedestrian positioning was realized. Thirdly, the foreground object was segmented by the Full Convolutional Network (FCN), and pixel prediction was performed to obtain the local mask (upper body, lower body) of the pedestrian, so as to achieve the finegrained detection of pedestrians. Finally, the overall mask of the pedestrian was obtained by learning the local features of the pedestrian. In order to verify the effectiveness of the improved algorithm, the proposed algorithm was compared with the current representative object detection methods (such as Faster Regionbased Convolutional Neural Network (Faster RCNN), YOLOv2 and RFCN (Regionbased Fully Convolutional Network)) on the same dataset. The experimental results show that the improved algorithm increases the speed and accuracy of pedestrian detection and reduces the false positive rate.
Key words:
Mask RCNN (Region with Convolutional Neural Network); pedestrian detection;Kmeans algorithm; finegrained; Fully Convolutional Network (FCN)
0 引言
行人检测技术由于应用的广泛性使其在计算机视觉领域成为一个重要的分支,对视频监控、车辆辅助驾驶、智能机器人等多个领域提供了重要的技术支持。它与行人重识别、目标跟踪等领域的联系密切相关,被认为是一个图像检索的子问题。
传统的行人检测方法大多以图像识别为基础,并基于人工设计的特征提取器进行特征的提取。首先, 在图片上使用穷举法选出所有物体可能出现的目标区域框; 然后,对这些区域框提取Haar[1]、方向梯度直方图(Histogram of Oriented Gradient,HOG)[2]、局部二值模式(Local Binary Pattern, LBP)[3]等特征,并使用图像识别方法分类得到所有分类成功的区域;最后,通过非极大值抑制将结果输出。但这种方法不仅复杂度高、鲁棒性差,而且产生了大量的候选区冗余区域。
2014年,Girshick等[4]设计了基于区域的卷积神经网络(Region with Convolutional Neural Network, RCNN),使用候选区域(Region Proposal)和分类卷积神经网络训练模型用于检测。这使得目标检测与识别技术取得了巨大突破,并掀起了基于深度学习的目标检测与识别的热潮。RCNN算法遵循了传统目标检测的思路,同样采用提取框、对每个框提取特征、图像分类、非极大值抑制4个步骤进行目标检测,只不过在提取特征这一步,将传统的特征(如尺度不变特征变换(ScaleInvariant Feature Transform, SIFT)[5-6]、HOG特征[7-9]等)换成了深度卷积网络提取的特征。快速区域卷积神经网络(Fast Regionbased Convolutional Neural Network, Fast RCNN)[10]、更快速的区域卷积神经网络(Faster Regionbased Convolutional Neural Network, Faster RCNN)[11]、Mask RCNN[12]等深度网络框架都是建立在RCNN的基础之上,以及单阶段检测器算法YOLO(You Only Look Once)[13-15]、SSD(Single Shot MultiBoxDetector)[16],均获得了更多研究者的追捧[17-22]。
随着深度网络框架的逐步成熟,对于行人检测技术的要求也进一步地提升。而对于在复杂场景下或者目标较远的行人图像,行人检测的检测问题依旧存在,并且对于检测精度和检测速度有着更高的要求。因此考虑到使用细粒度图像的技术,细粒度图像识别被认为是一个具有挑战性的计算机视觉问题,由于高度相似的从属类别引起的小的类间变化,以及姿势、尺度和旋转的大的类内变化。细粒度识别任务,如识别鸟类[23]、花[24]和汽车[25]等,在计算机视觉和模式识别的应用中很受欢迎。细粒度识别更有利于学习目标的关键部分,这有助于区分不同子类的对象并匹配相同子类的对象[26-30],可以更加准确地学习行人的特征。
因此,本文采用基于深度学习的目标检测中领先的研究成果,提出将Mask RCNN结构用于行人检测,主要工作包含以下几个部分:
1)数据集选取与制作阶段,在已标注好的数据集上,采用水平翻转及加噪的方式对数据集进行扩充,实现数据增强。
2)数据训练阶段,采用Kmeans算法对数据进行聚类获得合适的anchors的长宽比,并采用全卷积网络(Fully Convolutional Network, FCN)构建部位分割模型,分别提取行人的上半身、下半身和整体的特征,将这些特征信息融合完成行人的检测。
3)模型评估阶段,从检测精度、检测速度和误检率3个指标对本文的模型进行评估,并与当前主流的目标检测算法进行实验对比,验证本文算法的可行性和有效性。
1 网络框架
1.1 Mask RCNN算法
本文采用Mask RCNN算法实现对图像中行人的检测,网络结构如图1所示。首先对输入(input)任意尺寸大小的行人图像进行卷积特征提取构成特征图(feature map),之后在区域生成网络(Region Proposal Network, RPN)中,使得区域生成(proposals)、分类(category)、回归(bbox regression)共用卷积层,加快计算速度。与之并行的特征金字塔网络(Feature Pyramid Network, FPN)在实现行人检测的同时把行人目标的像素分割出来,并给出行人在图片中的位置坐标(coordinates)。
Mask RCNN算法采用两阶段检测方法。第一阶段是生成目标候选区域,提出候选对象边界框(与Faster RCNN算法相同);在第二阶段, Mask RCNN为每个感兴趣区域(Region of Interest, RoI)输出二进制掩码,与预测类和边界框偏移并行,其中分类取决于掩码预测(例如文献[31-32])。在训练期间,Mask RCNN算法为每个采样的RoI上的多任务损失函数定义为:
L=Lcls+Lbox+Lmask(1)
其中:Lcls表示分類损失,Lbox表示边界框损失,Lmask表示分割损失。
Mask RCNN算法提出了一个RoIAlign层,采用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,避免对RoI边界或区间进行任何量化(例如,使用x/16而不是[x/16]),从而将整个特征聚集过程转化为一个连续的操作。在具体的算法操作上,RoIAlign并不是简单地补充出候选区域边界上的坐标点进行池化,而是通过:1)遍历每一个候选区域,保持浮点数边界不做量化;2)将候选区域分割成K×K个单元,每个单元的边界也不做量化;3)在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。RoIAlign是在Mask RCNN中区域特征聚集方式,可以很好地解决RoI池化操作中两次量化造成的区域不匹配(misalignment)的问题,进而提升检测模型的准确性。
1.2 改进的Mask RCNN算法
本文在原有Mask RCNN检测框架的基础上,做了一些改进,网络框架如图2所示。同样为两个部分:第一部分是生成候选区域;第二部分是学习全局和局部图像块的特征,主要是借助FCN学习部位分割模型(partbased segmentation model),具体见1.2.3节内容。
1.2.1 区域生成网络
RPN是在最后一层特征图上进行特征提取,采用滑动窗口的方式扫描整张图像,寻找存在的目标区域(anchor)。对于图像上的每一个位置考虑9个可能的候选窗口:3种尺度(1282,2562,5122)和3种长宽比(1∶1,1∶2,2∶1)。在不同的尺寸大小和长宽比下,在该图像上会产生将近20-000个目标区域,并且这些区域相互重叠,尽可能地覆盖在整张图像上。RPN为每个anchor生成两个输出,即anchor类别和边框调整。对于互相重叠的多个anchor,采用非极大值抑制给出目标的粗略结果,保留拥有最高前景分数的anchor,因此,使用RPN预测可以选出最好的包含目标的anchor,并应用边框进行精调。
1.2.2 特征金字塔网络
由于RPN是在得到的最后一层特征图上进行特征提取,在顶层的特征中不能完整地反映目标的信息。因此,结合多层级的特征可以大幅提高多尺度检测的准确性。FPN主要解决目标检测的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,可以大幅度提升目标的检测性能。
1.2.3 图像分割
本文使用FCN用于图像的分割,FCN可以采用任何分辨率的输入图像,并产生相同大小的输出。FCN不仅在细粒度图像中定位目标,而且还将分割预测视为目标掩码。对于有效的训练,所有训练和测试细粒度图像保持其原始图像的分辨率。
FCN掩码学习过程如图3所示。首先将原始图片通过FCN进行像素预测,获得目标的局部掩码,如果像素预测为目标的局部位置(上半身、下半身),则保留掩码的实际值,即对行人进行细粒度检测;否则,如果像素指示区域是背景,则掩码中这些背景区域的值被重置为零值。对于图像中的每一个行人,均会学习到每个人的全局和局部特征,学习的FCN模型也能够返回更准确的目标掩码。同时,这些目标掩码还可以通过找到它们的包围矩形来定位目标位置。本文实验中,采用FCN-8[33]来学习和预测目标掩码。
特征学习如图4所示。
图4中三个流分别对应行人的整体、上半身和下半身图像块,通过卷积、激活、池化、判别器选择等一系列操作,分别学习这三个图像块的特征。为提高图像中行人的检测精度,让不同细粒度的特征参与行人检测,因此,本文结合不同细粒度图像特征,可以增强行人检测的鲁棒性。
2 网络训练
本文采用改进的Mask RCNN结构为模型,训练行人检测器。为加快训练速度并防止过拟合,在训练期间需设置合理的参数,具体参数设置如表1所示。
2.1 数据集选取与制作
基于深度学习的行人检测方法需要大量的数据集, 因此,本文从最具典型的COCO2014数据集中选取具有代表性的图像,主要包括复杂场景下、行人密集、光照变化明显等难检测的行人图像1-500张,以及2018年江苏省研究生计算机视觉创新实践大赛官方给出的205张行人图像。使用labelme软件完成数据集的标注工作,主要标注行人上半身、下半身和全身的标签信息。其中训练集包含正样本图像1-455张,行人数目为4-368个;测试集包含正样本图像250张,行人数目为756个。
针对不同的数据集及不同大小的目标,修改anchor的大小和数量,可以加快收敛速度,提高检测精度。考虑到2018年江苏省研究生计算机视觉创新实践大赛官方给出的数据集中行人姿势、动作的特点,采用1.2.1节中的3种尺度和3种长宽比并不合理,因此本文增加1组长宽比,此时anchor对应长宽比为(1∶1,1∶2,2∶1,2∶5),尺度不变。
2.2 预训练
为减少训练时间,采用MSCOCO预训练模型进行训练。在COCO2014数据集上训练20个循环(epoch)后得预训练参数。选择了ResNet50网络作为特征提取网络,需要检测的物体只有行人,再加上背景则一共有两类。
2.3 聚类选取初始候选框
在网络训练阶段,随着迭代次数的不断增加,网络学习到行人的全局特征,预测框的参数不断调整,最终接近真实框。为了加快收敛速度,提高行人检测的位置精度,本文通过分析图像中行人宽高的特点,采用Kmeans算法进行聚类,本文的Kmeans聚类算法采用欧氏距离来衡量数据对象间的距离,其中Kmeans聚类算法通过给定bounding boxes的anchors数量的中心位置,计算两者之间的欧氏距离,选取距离真实框最近的一个anchor。重复这样的操作,直至满足所给定的anchors数量。最终确定anchor的长宽比为(1∶1,1∶2,2∶1,2∶5)。
預测框和真实框的交并比 (Intersection Over Union,IOU)是反映预测框与真实框差异的重要指标,IOU值越大,则(1-IOU)的值就越小,这表明两者差异越小,“距离”越近。聚类的目标函数为:
min∑N∑M(1-IOU(Box[N],Truth[M]))(2)
其中:N表示聚类的类别,M表示聚类的样本集,Box[N]表示聚类得到预测框的宽高,Truth[M]表示真实框的宽高。
3 实验结果与分析
本文实验环境为:ubuntu18.04,64位操作系统,深度学习框架为TensorFlow,1个GPU,代码运行环境为Python3.6.3。对于行人图像目标检测,本文采用检测精度(Average Precision,AP)、误检率(False Positive Rate,FRP)、检测速度(Detection Rate,DR)3个指标,其中DR表示每张图片的检测时间,单位:秒。
3.1 实验可视化结果
本文实验的可视化结果如图5所示。从数据集中选取了2张典型的图像,包括光照变化明显、行人密集、姿势复杂的图像,用矩形框正确标记出图像中的行人,并利用实例分割将每个行人作为一个实例显现地标记出来。
3.2 数据增强对比实验
由于深度学习需要大量的数据量,为了增加训练集的数据量,本文对现有的数据集采用水平翻转、加噪等方式对数据进行扩充,如图6所示。
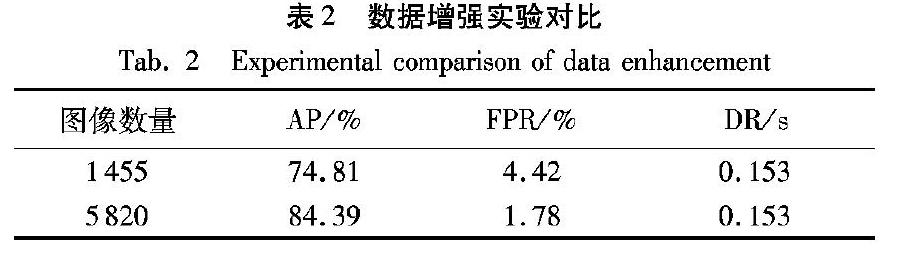
根据表2的实验可知,当训练集从1-455张行人图像扩充至5-820张行人图像后,目标的检测精度提高了9.58%,误检率降低了2.64%。因此,对数据集进行合理的扩充,有利于网络充分学习行人图像的特征,提高目标的检测性能。接下来的实验均是在数据集扩充的基础上进行。
3.3 采用不同策略訓练网络的检测结果对比
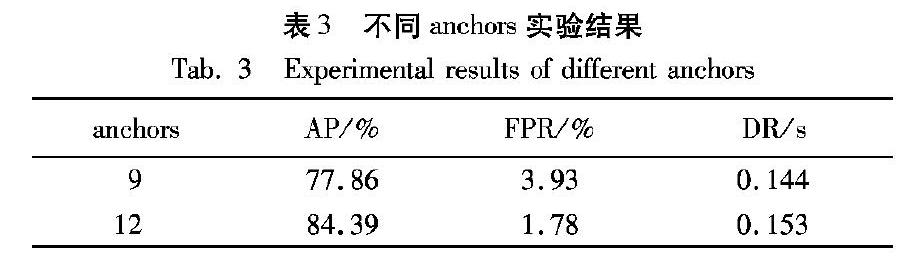
为了验证本文所提出方法的有效性,分别采用不同策略对网络进行训练与测试,具体检测结果如表3所示。原始Mask RCNN算法中anchors的个数为9,即3种长宽比(1∶1,1∶2,2∶1)和3种尺度(1282,2562,5122)。本文根据行人数据集的特点采用Kmeans聚类的方法获得适合本实验数据的长宽比为(1∶1,1∶2,2∶1,2∶5),最终将anchor数量从9增加至12。如表3所示,对比两种策略实验结果可发现:选用合适的anchors的尺度和长宽比,可使平均检测精度提升6.53个百分点,误检率降低2.15个百分点。
3.4 消融实验
为了分析目标的每个部分对于模型的贡献度,本文对数据集进行了消融实验。将在原始整体特征学习的模型的基础上只加入上半身特征学习的模型表示为part-1,只加入下半身特征学习的模型表示为part-2。实验结果如表4所示,根据表4可知,本文只加入上半身特征学习后检测精度提高了2.27个百分点,只加入下半身特征学习后检测精度提高了0.76 个百分点。二者特征学习均加入之后的检测精度整体上提高了3.24个百分点。
3.5 不同目标检测算法结果对比
本文将改进后的算法(即本文算法)同具有代表性的目标检测算法进行比较,包括单阶段检测器(回归系列算法)中的YOLOv2算法、YOLOv3算法和SSD算法;两阶段检测器(区域建议系列算法)中的RFCN算法、Faster RCNN算法和Mask RCNN算法。其中单阶段检测器将目标检测视作单个回归问题,网络结构简单,直接给出最终的检测结果,其检测速度较快,但准确率较低;两阶段检测器首先生成可能包含物体的候选区域,之后对候选区域作进一步的分类和校准,得到最终的检测结果,其准确率较高,但检测速度较慢。
实验对比结果如表5所示,对比几种目标检测算法的实验结果可发现:本文在Mask RCNN基础上考虑细粒度图像的特点,增加anchors的个数,在提高检测精度的同时提高了检测速度。本文算法较回归算法中YOLOv2算法的检测精度提高了9.06个百分点,误检率降低了1.09个百分点;较区域建议系列算法中Faster RCNN算法的检测精度提高了1.90个百分点,误检率降低了0.49个百分点;较Mask RCNN算法的检测精度提高了3.24个百分点,且误检率降低了0.55个百分点,而检测速度略低于单阶段检测器算法,约0.1个百分点;但相较区域建议系列算法有了明显的提高。
3.6 不同数据集实验结果
为了验证本文算法的普适性,将训练出来的模型分别在INRIA数据集、COCO2017数据集上进行测试。
3.6.1 INRIA数据集实验结果
数据集INRIA的测试集有288张正样本(包含2-416个行人),453张负样本(包含1-126个行人)。在INRIA上的实验结果如表6所示,可以发现: 本文算法相较于其他的检测算法在检测精度仍占有一定的优势,检测精度比YOLOv3算法和Mask RCNN算法分别提高了9.56个百分点、2.18个百分点;检测速度相较于Mask RCNN算法仍提高了0.411个百分点,略低于单阶段检测器YOLOv2和YOLOv3算法的检测速度。
3.6.2 COCO2017数据集实验结果
COCO2017数据集的测试集包含40-670张图像,从中随机挑选200张图像进行测试。在挑选出来的200张图像上的实验结果如表7所示。可以发现:本文算法的检测精度较YOLOv2算法、YOLOv3算法、Mask RCNN算法分别提高了11.54个百分点、7.61个百分点、5.48个百分点;检测速度与其他算法十分接近。
4 结语
本文针对复杂场景下的行人图像进行深入研究,在初始Mask RCNN框架的基础上,采用数据增强的方式对数据集进行扩充,针对数据集的特点采用Kmeans算法调整anchor数量和大小,结合ResNet50、FPN、FCN等架构来提升行人的检测能力,并结合了行人细粒度属性,有效地提高了行人的检测精度。由于行人检测与行人重识别、行人跟踪等领域密切相关,因此行人检测技术的提升有利于行人重识别、行人跟踪技术的提升。但本文对于行人的检测速度仍低于单阶段检测器的检测速度,因此,接下来对于检测速度的提升还有待研究。并且近年来,很多研究者致力于提取更多信息辅助检测(如光流信息、运动信息和环境信息等),提高特征表达能力,未来将对其进行更深一步的探讨。
参考文献 (References)
[1]PAPAGEORGIOU C P, OREN M, POGGIO T. A general framework for object detection [C]// Proceedings of the 6th IEEE International Conference on Computer Vision. Piscatway: IEEE, 1998:555-562.
[2]DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2005: 886-893.
[3]WANG X Y, HAN T, YAN S C. An HOGLBP human detector with partial occlusion handling [C]// Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. Piscataway: IEEE, 2009: 32-39.
[4]GIRSHICK R, DONAHUE J, DARRELL T, et al. Regionbased convolutional networks for accurate object detection and segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(1): 142-158.
[5]LOWE D G. Object recognition from local scaleinvariant features [C]// Proceedings of the 1999 International Conference on Computer Vision. Piscataway: IEEE, 1999:1150-1157.
[6]LOWE D G. Distinctive image features from scaleinvariant keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[7]WANG S F, YAN J H, WANG Z G. Improved moving object detection algorithm based on local united feature [J]. Chinese Journal of Scientific Instrument, 2015, 36(10): 2241-2248.
[8]VIOLA P A, JONES M J. Rapid object detection using a boosted cascade of simple features [C]// Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2001:511-518.
[9]DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2005:886-893.
[10]GIRSHICK R. Fast RCNN [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448.
[11]REN S Q, HE K M, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149.
[12]HE K M, GKIOXARI G, GIRSHICK R, et al. Mask RCNN [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 2980-2988.
[13]REDMON J, DIVVALA S K, GIRSHICK R, et al. You only look once: unified, realtime object detection [C]// Proceedings of the 29th IEEE Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:779-788.
[14]REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525.
[15]REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. [2019-03-26]. https://arxiv.org/pdf/1804.02767.pdf.
[16]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of the 14th European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
[17]張中宝, 王洪元, 杨薇. 基于FasterRCNN的遥感图像飞机检测算法[J]. 南京师大学报(自然科学版), 2018, 41(4): 79-86.(ZHANG Z B, WANG H Y, YANG W. Remote sensing image aircraft detection algorithm based on Faster RCNN [J]. Journal of Nanjing Normal University (Natural Science Edition), 2018, 41(4): 79-86.)
[18]YANG W, ZHANG J, ZHANG Z B, et al. Research on realtime vehicle detection algorithm based on deep learning [C]// Proceedings of the 2018 Chinese Conference on Pattern Recognition and Computer Vision. Berlin: Springer, 2018: 126-127.
[19]YANG W, ZHANG J, WANG H Y, et al. A vehicle realtime detection algorithm based on YOLOv2 framework [C]// Proceedings of the 2018 RealTime Image and Video Processing. Bellingham, WA: SPIE, 2018: 106700N.
[20]PHAM M T, LEFEVRE S. Buried object detection from BScan ground penetrating radar data using FasterRCNN [C]// Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium. Piscataway: IEEE, 2018: 6804-6807.
[21]KIM J, BATCHULUUN G, PARK K. Pedestrian detection based on Faster RCNN in nighttime by fusing deep convolutional features of successive images [J]. Expert Systems with Applications, 2018, 114: 15-33.
[22]SCHWEITZER D, AGRAWAL R. Multiclass object detection from aerial images using Mask RCNN [C]// Proceedings of the 2018 IEEE International Conference on Big Data. Piscataway: IEEE, 2018: 3470-3477.
[23]WEI X, XIE C, WU J. MaskCNN: localizing parts and selecting descriptors for finegrained bird species categorization [J]. Pattern Recognition, 2018, 76: 704-714.
[24]ANGELOVA A, ZHU S H, LIN Y Q. Image segmentation for largescale subcategory flower recognition [C]// Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision. Piscataway: IEEE, 2013: 39-45.
[25]KRAUSE J, STARK M, DENG J, et al. 3D object representations for finegrained categorization [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Washington, DC: IEEE Computer Society, 2013:554-561.
[26]HUANG S, XU Z, TAO D, et al. Partstacked CNN for finegrained visual categorization [C]// Proceedings of the 29th IEEE Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1173-1182.
[27]LIN D, SHEN Y, LU C, et al. Deep LAC: deep localization, alignment and classification for finegrained recognition [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1666-1674.
[28]ZHANG Y, WEI X, WU J, et al. Weakly supervised finegrained categorization with partbased image representation [J]. IEEE Transactions on Image Processing, 2016, 25(4): 1713-1725.
[29]XIE G, ZHANG X, YANG W, et al. LGCNN: from local parts to global discrimination for finegrained recognition [J]. Pattern Recognition, 2017, 71: 118-131.
[30]LEE S, CHAN C, MAYO S J, et al. How deep learning extracts and learns leaf features for plant classification [J]. Pattern Recognition, 2017, 71: 1-13.
[31]DAI J, HE K, SUN J. Instanceaware semantic segmentation via multitask network cascades [C]// Proceedings of the 29th IEEE Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3150-3158.
[32]LI Y, QI H Z, DAI J, et al. Fully convolutional instanceaware semantic segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4438-4446.
[33]LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440.
This work is partially supported by the National Natural Science Foundation of China (61572085).
ZHU Fan, born in 1994, M. S. candidate. Her research interests include computer vision.
WANG Hongyuan, born in 1960, Ph. D., professor. His research interests include computer vision.
ZHANG Ji, born in 1981, M. S., lecturer. His research interests include computer vision.
