多层次结构生成对抗网络的文本生成图像方法
2019-12-23孙钰李林燕叶子寒胡伏原奚雪峰
孙钰 李林燕 叶子寒 胡伏原 奚雪峰
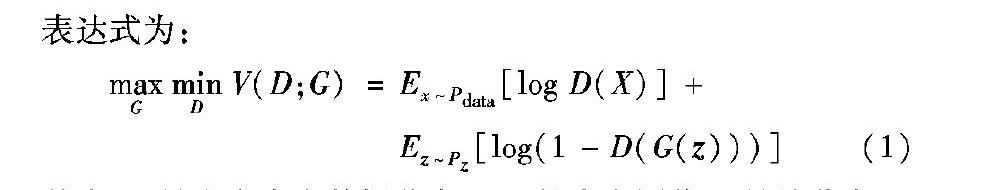


摘 要:近年來,生成对抗网络(GAN)在从文本描述到图像的生成中已经取得了显著成功,但仍然存在图像边缘模糊、局部纹理不清晰以及生成样本方差小等问题。针对上述不足,在叠加生成对抗网络模型(StackGAN++)基础上,提出了一种多层次结构生成对抗网络(MLGAN)模型,该网络模型由多个生成器和判别器以层次结构并列组成。首先,引入层次结构编码方法和词向量约束来改变网络中各层次生成器的条件向量,使图像的边缘细节和局部纹理更加清晰生动;然后,联合训练生成器和判别器,借助多个层次的生成图像分布共同逼近真实图像分布,使生成样本方差变大,增加生成样本的多样性;最后,从不同层次的生成器生成对应文本的不同尺度图像。实验结果表明,在CUB和Oxford102数据集上MLGAN模型的Inception score分别达到了4.22和3.88,与StackGAN++相比,分别提高了4.45%和3.74%。MLGAN模型在解决生成图像的边缘模糊和局部纹理不清晰方面有了一定提升,其生成的图像更接近真实图像。
关键词:生成对抗网络;文本生成图像;多层次结构生成对抗网络;多层次图像分布;层次结构编码
中图分类号:TP391
文献标志码:A
Texttoimage synthesis method based on
multilevel structure generative adversarial networks
SUN Yu1,2, LI Linyan3, YE Zihan1,4, HU Fuyuan1*, XI Xuefeng1,5
1.College of Electronic and Information Engineering, Suzhou University of Science and Technology, Suzhou Jiangsu 215009, China;
2.Suzhou Key Laboratory for Big Data and Information Service, Suzhou Jiangsu 215009, China;
3.Suzhou Institute of Trade and Commerce, Suzhou Jiangsu 215009, China;
4.Jiangsu Key Laboratory of Intelligent Building Energy Efficiency, Suzhou Jiangsu 215009, China;
5.Virtual Reality Key Laboratory of Intelligent Interaction and Application Technology of Suzhou, Suzhou Jiangsu 215009, China
Abstract:
In recent years, the Generative Adversarial Network (GAN) has achieved remarkable success in texttoimage synthesis, but there are still problems such as edge blurring of images, unclear local textures, small sample variance. In view of the above shortcomings, based on Stack Generative Adversarial Network model (StackGAN++), a MultiLevel structure Generative Adversarial Networks (MLGAN) model was proposed, which is composed of multiple generators and discriminators in a hierarchical structure. Firstly, hierarchical structure coding method and word vector constraint were introduced to change the condition vector of generator of each level in the network, so that the edge details and local textures of the image were clearer and more vivid. Then, the generator and the discriminator were jointed by trained to approximate the real image distribution by using the generated image distribution of multiple levels, so that the variance of the generated sample became larger, and the diversity of the generated sample was increased. Finally, different scale images of the corresponding text were generated by generators of different levels. The experimental results show that the Inception scores of the MLGAN model reached 4.22 and 3.88 respectively on CUB and Oxford102 datasets, which were respectively 4.45% and 3.74% higher than that of StackGAN++. The MLGAN model has improvement in solving edge blurring and unclear local textures of the generated image, and the image generated by the model is closer to the real image.
Key words:
Generative Adversarial Network (GAN); texttoimage synthesis; MultiLevel structure Generative Adversarial Networks (MLGAN); multilevel image distribution; hierarchical coding
0 引言
生成图像建模是计算机视觉中的一个基本问题,在图像和视觉计算、图像和语言处理、信息安全、人机交互等领域已有广泛应用。最近几年,随着深度学习的发展,生成图像方法取得了显著进展:Dosovitskiy等[1]训练反卷积神经网络(Convolutional Neural Network, CNN)来生成3D椅子、桌子和汽车;Ehsani等[2]用视觉数据构建狗的行为模型;郭雨潇等[3]提出了一种基于单张图像的环境光遮蔽估计算法;赵树阳等[4]提出一种非监督式的由图像生成图像的低秩纹理生成对抗网络模型,用于生成低秩图像;何新宇等[5]提出了一种基于深度卷积神经网络(Deep Convolutional Neural Network, DCNN)的肺炎图像识别模型用于肺炎图像的识别;Rematas等[6]使用足球比赛视频数据训练网络,从而提取3D网格信息,进行动态3D重建。此外,利用神经网络来模拟像素空间的条件分布的自回归模型(例如,像素递归神经网络(Pixel Recurrent Neural Network, PixelRNN))[7]也已经产生了清晰的合成图像。最近,生成对抗网络(Generative Adversarial Network, GAN)[8]已经显示出其具有强大的性能和潜力来生成更清晰和质量更高的样本图像。
自Goodfellow等[8]于2014年提出生成对抗网络后,该网络模型得到了学术界和工业界的广泛关注。与传统机器学习方法不同,生成对抗网络最大的特点在于引入了对抗机制,能够利用少量标签数据和大量无标签数据建模,直接生成与目标数据一致的生成数据,如图像、视频以及音乐[9-10]等。在最初的设计中,GAN由一个生成器和一个判别器组成,生成器和判别器以相互交替的方式进行对抗训练。训练生成器以产生符合真实数据分布的样本来欺骗判别器,同时优化判别器用以区分真实样本和生成器产生的假样本。
随着生成模型的不断提出,生成对抗网络已经在复杂的多模态数据建模和合成真實世界图像方面展示了其强大的效果: Wang等[11]利用提出的样式结构生成对抗网络(Style and Structure Generative Adversarial Networks, S2GAN)模型以结构生成和样式生成两部分相结合的方法实现室内场景图像的生成; Denton等[12]在拉普拉斯金字塔框架内建立了多个GAN模型,以前一层级的输出为条件生成残差图像,然后作为下一层级的输入,最后生成图像; Durugkar等[13]使用多个判别器和一个生成器来增加生成器接收的有效反馈,增强生成的图像效果; Reed等[14]提出了GANINTCLS模型,首次利用GAN有效地生成以文本描述为条件的64×64图像。然而,在许多情况下,他们合成的图像缺少逼真的细节和生动的物体部分,例如鸟的喙、眼睛和翅膀; 此外,他们无法合成更高分辨率的图像(例如128×128或256×256)。Reed等[15]为了更好地根据文本描述控制图像中物体的具体位置,提出了GAWWN(Generative Adversarial WhatWhere Network)模型,把额外的位置信息与文本一起作为约束条件加入到生成器和判别器的训练中。Zhang等[16]在网络层次结构中引入了层次嵌套对抗性目标,提出了高清晰生成对抗网络(HighDefinition Generative Adversarial Network, HDGAN)模型,规范了中间层的表示,并帮助生成器捕获复杂的图像统计信息。Zhang等[17]提出了一种叠加生成对抗网络(Stacked Generative Adversarial Network, StackGAN++)模型,把生成高质量图像的复杂问题分解成一些更好控制的子问题。在第一阶段利用文本描述粗略勾画物体的主要形状和颜色,生成低分辨率图像;在第二阶段,将第一阶段的结果和文本描述作为输入,生成256×256的高分辨率图像。然而,生成图像的局部纹理相对模糊。
为了进一步增强生成图像的边缘和局部纹理细节,提高生成图像的质量,本文在叠加生成对抗网络模型的基础上提出了一种多层次结构生成对抗网络(MultiLevel structure Generative Adversarial Network, MLGAN)模型。该模型引入了层次结构编码(hierarchical coding)方法[18],对文本进行预处理,改变各层次生成器的条件变量,侧重关注生成图像的边缘和局部纹理。另外,基于多层次结构,网络联合训练生成器和判别器以近似多层次分布,在每一层生成器处捕获图像分布,根据多个图像分布共同逼近真实图像分布,提高生成样本的多样性。
1 多层次结构生成对抗网络
1.1 生成对抗网络
生成对抗网络采用了对抗的思想,其核心来自博弈论中的纳什均衡。对抗的双方分别由生成器G(Generator)和判别器D(Discriminator)组成,其中生成器的目的是尽量学习真实的数据分布,判别器D的目的在于尽量正确判断输入数据是来自真实数据还是生成器生成的数据。两个模型交替训练并且相互竞争。在训练中,优化生成器G捕捉样本数据的分布,用服从某一分布(均匀分布、高斯分布等)的噪声z生成一个类似真实训练样本的数据Pdata;判别器D是一个二分类器,优化判别器D以估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D输出大概率,否则,D输出小概率。生成器G和判别器D交替训练的表达式为:
maxGminD V(D;G)=Ex~Pdata[logD(X)]+
Ez~Pz[log(1-D(G(z)))](1)
其中:x是来自真实数据分布Pdata的真实图像,z是从分布Pz采样的噪声矢量(例如均匀或者高斯分布)。
1.2 多层次结构生成对抗网络模型
为了进一步增强生成图像的边缘和局部纹理细节,提高样本多样性和生成图像的质量,本文提出了一种多层次结构生成对抗网络模型,该模型由多个生成器(Gs)和判别器(Ds)以层次结构并列组成。如图1所示,整个网络可以分为三个层次,在第一层次生成低分辨率图像,侧重关注图像整体的形状和颜色;在第二和第三层次生成高分辨率图像,借助整个网络联合训练,以近似多层次图像分布,提升图像的边缘和局部纹理细节。每个层次网络由上采样层、生成器、卷积层、残差层以及判别器组成。上采样层将输入的向量转换为不同层次对应的张量,通过生成器以及卷积层生成具有3×3卷积的对应比例图像。
1.2.1 多层次图像分布
与叠加生成对抗网络不同的是,本文的网络具有多层次结构,采用噪声向量z~Pnoice和不同的条件变量c作为生成器的输入。生成网络中包含3个生成器来生成不同分辨率的图像。Pnoice是高斯分布,通常选择为标准正态分布。条件变量c由句子向量以及词向量组成。潜变量(z,ci)逐层转换为隐藏特征hi。本文首先通过非线性变换计算每个生成器Gi的隐藏特征hi:
h0=F0(z,F′(cs))(2)
hi=Fi(hi-1,F′(cw,hi-1)); i=1,2,…,m-1(3)
其中:hi代表第i分支的隐藏特征;F′为调节增强[17],将句子向量和词向量转化为条件向量;m是层次的总数;cs为句子向量;cw为词向量;Fi为神经网络模型(参见图1)。
然后基于不同层次的隐藏特征(h0,h1,…,hm-1),将其作为对应层次的生成器(G0,G1,…,Gm-1)的输入,生成不同分辨率的图像。如式(4)所示:
si=Gi(hi); i=0,1,…,m-1(4)
其中:Gi是第i分支的生成器,si是第i分支的生成图像。
在每个生成器Gi生成样本之后,将真实的图像xi和生成器生成的假样本si作为输入,输入到对应的判别器Di中进行训练,通过最小化交叉熵损失(见式(5)),将输入的图像分为两大类,分别是真实图像和生成图像。
LD=-12Exi~Pdatai[logDi(xi)]-
12Esi~PGi[log(1-Di(si))](5)
其中:xi来自第i尺度的真实图像分布Pdatai,si来自相同尺度的生成模型分布PGi。3个判别器并行训练,并且每个判别器都专注于自己对应的单个尺度图像。
接着通过训练判别器,引导最小化损失函数(见式(6))来优化生成器,以共同逼近多尺度图像分布(Pdata0,Pdata1,…,Pdatam-1)。
LG=∑mi=1LGi; LGi=12Esi~PGi[log(1-Di(si))](6)
其中LGi是近似第i尺度的图像分布的损失函数。在训练中,生成器Gi最大化log(Di(si)),而不是最小化log(1-Di(si)),這样可以减轻梯度消失问题[8]; 并且在训练过程中,生成器Gi和判别器Di交替优化直到最终收敛。
1.2.2 有条件和无条件图像生成
如图2所示,对于无条件图像生成,判别器被训练成区分真实图像和伪造图像。对于条件图像生成,将图像及调节变量输入到判别器以确定图像与条件是否匹配,引导生成器近似条件图像分布。
对于模型中的判别器Di,现在由两部分组成,即无条件损失和条件损失。
LD=-12Exi~Pdatai[logDi(xi)]-
12Esi~PGi[log(1-Di(si))]+
-12Exi~Pdatai[logDi(xi,cs)]+
-12Esi~PGi[log(1-Di(si,cs))](7)
无条件损失确定图像是真实还是伪造,而条件损失确定图像和条件是否匹配。 因此,每个生成器Gi的损失函数转换为:
LGi=12Esi~PGi[log(1-Di(si))]+12Esi~PGi[log(1-Di(si,cs))](8)
因此,每个层次的生成器Gi的最终损失函数通过把式(8)代入到式(6)来计算。
1.3 层次结构编码
在已有的生成模型中,都是将整个文本描述转化成条件变量作为生成器的输入,这样虽然可以使生成的图像大致符合文本的描述,但是图像边缘和局部纹理细节比较模糊,同时还会产生很多不符合文本描述的样本。基于这个问题,本文引入了层次结构编码,更加注重生成图像的边缘和局部纹理细节。
如图3所示,该层次结构编码模型包含4个层次,文本描述经过文本嵌入、卷积层、最大池化和LSTM(Long ShortTerm Memory)特征提取,最终得到需要的短语向量和单词向量。在卷积层,使用三种大小的卷积核进行卷积;在池化层,对输出的三种卷积结果进行一次最大池化。
层次结构编码的具体步骤如下:
1)首先给出单词的编码S={q1,q2,…,qk},同时将文本描述映射到一个向量空间以得到Sw={qw1,qw2,…,qwk}。
2)然后利用1维DCNN(1DCNN)作用于Sw,对其中每一个单词嵌入向量进行卷积操作,计算单词向量和卷积核的内积,使用三种大小的卷积核,以此来计算短语特征。对于第k个字,卷积后的输出为:
qps,k=tanh(Wscqwk:k+s-1); s∈{1,2,3}(9)
其中:Wsc是重量参数,s为卷积核的大小。
3)将特征Sw送入剩下两个卷积核进行卷积操作,在卷积之前需要适当地进行填充,以在卷积之后序列的长度保持不变。
4)接着在3个卷积核卷积之后,本文对卷积的结果做一次最大池化,以获得短语的特征,结果如下:
qpk=max(qp1,k,qp2,k,qp3,k); k∈{1,2,…,K}(10)
5)最后将得到的最大池化结果送入到LSTM中,使用LSTM对qpk进行编码,提取特征。
这样的合并方法与文献[19]方法不同之处在于它在每个时间步长自适应地选择不同的特征,同时保留原始序列长度和顺序。
2 实验及结果分析
2.1 实验环境和数据集
本文算法采用深度学习框架Tensorflow[20],实验环境为ubantu14.04操作系统,使用4块NVIDIA 1080Ti图形处理器(GPU)加速运算。同时,在CUB[21]和Oxford102[22]数据集上训练所有模型。对于所有数据集,本文设置Ng=32,Nd=64并在每个生成器之间使用两个残差块,同时使用学习率为0.000-2的ADAM求解器。如表1所示,CUB数据集包含200种鸟类,共有11-788种图片。本文将8-855张图片作为训练数据集和2-933张图片作为测试数据集。由于该数据集中80%的鸟类图像的目标所占区域比例小于0.5[21],所以在训练之前先对所有图像进行预处理,确保鸟类目标所占区域的比例大于图像尺寸的0.75。Oxford102数据集包含102种花的类别,共有8-189种图像。本文将7-034张图片作为训练数据集和1-155张图片作为测试数据集。
2.2 评价标准
对于GAN模型的评估通常都选用定性评估,即需要借助人工检验生成图像的视觉保真度来进行。这种方法耗时长,且主观性较强,具备一定的误导性。因此,本文主要使用2种评价标准对生成图像的质量和多样性进行评价。
1)数值评估方法Inception score[23]进行定量评估。数值评估方法表达式如下:
I=exp(ExDKL(p(y|x)‖p(y)))(11)
其中:x表示一个生成的样本,y表示与样本对应的文本标签,p(y)是边缘分布,p(y|x)是条件分布。边缘分布p(y)和条件分布p(y|x)之间的KL散度(KullbackLeibler divergence)要大,这样能够生成多样的高质量图像。在本文的实验中,给CUB和Oxford102数据集一个inception模型,对每个模型的样本进行评估。
2)Human rank进行定性评估。在CUB和Oxford102测试集中随机选择50个文本描述,对于每个句子,生成模型生成5个图像。将5个图像和对应的文本描述给不同的人按不同的方法进行图像质量的排名,最后计算平均排名来评价生成图像的质量和多样性。
2.3 实验结果
表1为MLGAN与StackGAN++模型在CUB数据集上每一层次的Inception score对比。从表中第一行数据可以看出,在第一层次,两个模型的生成图像的Inception score相同;在第二层,MLGAN模型的約束条件中加入了词向量,与StackGAN++相比,Inception score从3.35增加到了3.47;在第三层,MLGAN模型的约束条件中加入了词向量,与StackGAN++相比,Inception score从4.04增加到了4.22。因此,根据第二和第三层次的Inception score增加,MLGAN模型在分辨率为128×128和256×256的生成图像上的效果要优于StackGAN++模型,也进一步验证了MLGAN模型的可行性。
表2为各种模型在CUB和Oxford102数据集上的Inception score和Human rank结果对比。与StackGAN++相比,MLGAN在CUB数据集上的Inception score提高了4.45%(从4.04到4.22),在Oxford102数据集上的Human rank提高了3.74%(从3.74到3.88)。通过实验结果分析,MLGAN在Inception score的评分上高于其他GAN模型[14-17];从直观的视觉角度Human rank的评分低于其他GAN模型。表明本文的模型所生成的样本图像质量和多样性有所增强,更接近真实图像。
图4为四种GAN模型在CUB数据集上的生成结果。图5为四种GAN模型在CUB数据集上的生成结果的细节(喙、翅膀)对比。从图4中可以看出,GANINTCLS生成的64×64图像只能反映鸟类的一般形状和颜色。缺乏生动的部分(例如喙和腿)和清晰的边缘细节,这使得图像既不够逼真也不具有足够高的分辨率。通过使用额外的条件变量,GAWWN在CUB数据集上获得了更高的Inception score,生成的128×128图像分辨率更高,但在边缘细节和局部纹理上没有大的改善。相比之下,StackGAN++生成了256×256图像,在边缘细节和局部纹理上有了一定的改善,但仍然无法与正常拍出的图像相比。而本文的模型在生成256×256图像的同时,增强了图像的边缘细节和局部纹理特征,使生成的图像更接近于真实的图像。
图6为三种GAN模型在Oxford102数据集上的生成结果。从图中可以看出,本文模型生成的图像中鸟的喙、翅膀以及脚部更加清晰,边缘和细节更加逼真,与其他模型相比取得了较优的效果。
图7为三种GAN模型在Oxford102数据集上的生成结果的细节(花瓣)对比。从图中可以看出,本文模型生成的图像中的花更加清晰,花瓣的边缘和细节更加逼真,与其他模型相比取得了较优的效果。
3 结语
本文基于叠加生成对抗网络模型的基础上,引入了层次结构编码,通过条件变量的转换和多层次生成图像,从整体到部分改善生成图像质量。实验结果表明,在相同的数据集上,多层次结构生成对抗网络生成的图像具有更清晰的边缘细节和局部纹理,使生成的图像更接近真实图像。该方法虽然在生成图像方面已经得到不错的效果,但是对于生活中的复杂场景依然很难建模,如何处理这一问题有待进一步研究。同时,生成的图像与训练数据相似,缺乏多样性,因此打算将零样本学习和生成对抗网络结合,合成新类别图像,这也将是下一步研究的重点。
参考文献 (References)
[1]DOSOVITSKIY A, SPRINGENBERG J T, BROX T. Learning to generate chairs with convolutional neural networks[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1538-1546.
[2]EHSANI K, BAGHERINEZHAD H, REDMON J, et al. Who let the dogs out? modeling dog behavior from visual data[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 4051-4060.
[3]郭雨瀟, 陈雷霆, 董悦. 单帧图像下的环境光遮蔽估计[J]. 计算机研究与发展, 2019, 56(2): 385-393. (GUO Y X, CHEN L T, DONG Y. Inferring ambient occlusion from a single image[J]. Journal of Computer Research and Development, 2019, 56(2): 385-393.)
[4]赵树阳, 李建武.基于生成对抗网络的低秩图像生成方法[J]. 自动化学报, 2018, 44(5): 829-839. (ZHAO S Y, LI J W. Generative adversarial network for generating lowrank images[J]. Acta Automatica Sinica, 2018, 44(5): 829-839.)
[5]何新宇,张晓龙.基于深度神经网络的肺炎图像识别模型[J]. 计算机应用,2019,39(6): 1680-1684. (HE X Y, ZHANG X L. Pneumonia image recognition model based on deep neural network[J]. Journal of Computer Applications, 2019, 39(6): 1680-1684.)
[6]REMATAS K, KEMELMACHERSHLIZERMAN I, CURLESS B, et al. Soccer on your tabletop[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 4738-4747.
[7]van DEN OORD A, KALCHBRENNER N, KAVUKCUOGLU K. Pixel recurrent neural networks[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016:1747-1756.
[8]GOODFELLOW I J, POUGETABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014:2672-2680.
[9]PAN Z, YU W, YI X, et al. Recent progress on Generative Adversarial Networks (GANs): a survey[J]. IEEE Access, 2019, 7: 36322-36333.
[10]CAO Y J, JIA L L, CHEN Y X, et al. Recent advances of generative adversarial networks in computer vision[J]. IEEE Access, 2019, 7:14985-15006.
[11]WANG X, GUPTA A. Generative image modeling using style and structure adversarial networks[C]// Proceedings of the 2016 European Conference on Computer Vision. Cham: Springer, 2016: 318-335.
[12]DENTON E L, CHINTALA S, SZLAM A, et al. Deep generative image models using a Laplacian pyramid of adversarial networks[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. New York: ACM, 2015:1486-1494.
[13]DURUGKAR I, GEMP I, MAHADEVAN S. Generative multiadversarial networks[EB/OL].[2018-06-20].https://www.taodocs.com/p110588603.html.
[14]REED S, AKATA Z, YAN X, et al. Generative adversarial texttoimage synthesis[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1060-1069.
[15]REED S, AKATA Z, MOHAN S, et al. Learning what and where to draw[C]// Proceedings of International Conference on Neural Information Processing Systems. New York: ACM, 2016: 217-225.
[16]ZHANG Z, XIE Y, YANG L. Photographic texttoimage synthesis with a hierarchicallynested adversarial network[C]// Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 6199-6208.
[17]ZHANG H, XU T, LI H, et al. StackGAN++: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(8): 1947-1962.
[18]LU J, YANG J, BATRA D, et al. Hierarchical questionimage coattention for visual question answering[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016:289-297.
[19]HU B, LU Z, LI H, et al. Convolutional neural network architectures for matching natural language sentences[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. New York: ACM, 2014: 2042-2050.
[20]ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for largescale machine learning[C]// Proceedings of the 2016 Conference on Operating Systems Design and Implementation. Piscataway: IEEE, 2016: 265-283.
[21]WAH C, BRANSON S, WELINDER P, et al. The CaltechUCSD Birds2002011 dataset: computation & neural systems technical report [R]. Pasadena, CA, USA: California Institute of Technology, 2011.
[22]NILSBACK M E, ZISSERMAN A. Automated flower classification over a large number of classes[C]// Proceedings of the 6th Indian Conference on Computer Vision, Graphics & Image Processing. Piscataway: IEEE, 2008: 722-729.
[23]SALIMANS T, GOODFELLOW I J, ZAREMBA W, et al. Improved techniques for training GANs[C]// Proceedings of International Conference on Neural Information Processing Systems. New York: ACM, 2016:2234-2242.
This work is partially supported by the National Natural Science Foundation of China (61876121,61472267), the Primary Research & Development Plan of Jiangsu Province (BE2017663), the Foundation of Key Laboratory in Science and Technology Development Project of Suzhou (SZS201609), the Graduate Research and Innovation Plan of Jiangsu Province (KYCX18_2549).
SUN Yu, born in 1995, M. S. candidate. His research interests include image processing, deep learning, generative adversarial networks.
LI Linyan, born in 1983, M. S., senior engineer. Her research interests include geographic information processing.
YE Zihan, born in 1996. His research interests include image processing, deep learning, generative adversarial networks.
HU Fuyuan, born in 1978, Ph. D., professor. His research interests include image processing, pattern recognition, information security.
XI Xuefeng, born in 1978, Ph. D., associate professor. His research interests include natural language processing, machine learning, big data processing.
