基于知识图嵌入的跨社交网络用户对齐算法
2019-12-23滕磊李苑李智星胡峰
滕磊 李苑 李智星 胡峰


摘 要:针对目前跨社交网络用户对齐算法存在的网络嵌入效果不佳、负采样方法所生成负例质量无法保证等问题,提出一种基于知识图嵌入的跨社交网络用户对齐(KGEUA)算法。在嵌入阶段,利用部分已知的种子锚用户对进行正例扩充,并提出Near_K负采样方法生成负例,最后利用知识图嵌入方法将两个社交网络嵌入到统一的低维向量空间中。在对齐阶段,针对目前的用户相似度度量方法进行改进,将提出的结构相似度与传统的余弦相似度结合共同度量用户相似度,并提出基于自适应阈值的贪心匹配方法对齐用户,最后将新对齐的用户对加入到训练集中以持续优化向量空间。实验结果表明,提出的算法在TwitterFoursquare数据集上的hits@30值达到了67.7%,比用户对齐现有最佳算法的结果高出3.3~34.8个百分点,显著提升用户对齐效果。
关键词:用户对齐;社交网络;网络嵌入;负采样;相似度度量
中图分类号: TP182
文献标志码:A
Crosssocial network user alignment algorithm based on knowledge graph embedding
TENG Lei1,2, LI Yuan1,2, LI Zhixing1,2*, HU Feng1,2
1.College of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing 400065, China;
2.Chongqing Key Laboratory of Computing Intelligence(Chongqing University of Posts and Telecommunications), Chongqing 400065, China
Abstract:
Aiming at the poor network embedding performance of crosssocial network user alignment algorithm and the inability to guarantee the quality of negative samples generated by negative sampling method, a crosssocial network KGEUA (Knowledge Graph Embedding User Alignment) algorithm was proposed. In the embedding stage, some known anchor user pairs were used for the positive sample expansion, and theNear_Knegative sampling method was proposed to generate negative examples. Finally, the two social networks were embedded into a unified lowdimensional vector space with the knowledge graph embedding method. In the alignment stage, the existing user similarity measurement method was improved, the proposed structural similarity was combined with the traditional cosine similarity to measure the user similarity jointly, and an adaptive thresholdbased greedy matching method was proposed to align users. Finally, the newly aligned user pairs were added to the training set to continuously optimize the vector space. The experimental results show that the proposed algorithm has the hits@30 value of 67.7% on the TwitterFoursquare dataset, which is 3.3 to 34.8 percentage points higher than that of the stateoftheart algorithm, improving the user alignment performance effectively.
Key words:
user alignment; social network; network embedding; negative sampling; similarity measure
0 引言
近年來,互联网的快速发展带动了在线社交网络的发展,如Twitter、Foursquare等在线社交网络平台极大地丰富了人们的社交生活。例如,人们会在Twitter上更新每日动态,同时在Instagram上分享照片并在Foursquare上分享他们的位置。人们为了享受各个在线社交网络的不同功能,通常会注册多个社交网络账号[1]。根据2018年的统计数据显示,互联网用户平均每人有8.5个不同的在线社交网络账户[2]。
跨社交网络用户对齐的目标是在不同的在线社交网络中找到属于现实世界中的同一用户的不同账号。这一研究在生活中拥有实际的意义,可以通过对齐用户来为用户提供更好的服务,例如朋友或商品推荐[3-4]。除此之外,通过对齐用户还可以解决一些在单个社交网络中无法解决的问题,如冷启动问题[5]。
目前,跨社交网络用户对齐的研究主要基于用户信息或网络结构。在线社交网络的用户信息存在较大噪声且用户行为等信息获取难度大,加大了用户对齐的难度;而社交网络结构拥有获取难度低、真实性高、很难进行伪造[6]、网络结构中所隐含的信息丰富等特点,能为用户对齐研究带来出色且稳定的对齐性能。
传统的基于网络结构的用户对齐算法通常将两个社交网络孤立看待,无法学习跨网络的隐藏信息;虽然使用了负采样方法提升嵌入空间质量但现有负采样方法存在无法保证负例质量;忽略了用户在网络结构上的相似性,最终导致对齐性能不佳。
本文的主要贡献包含如下几个方面:
1)使用社交网络结构进行跨社交网络用户对齐,提出一种基于知识图嵌入的跨社交网络用户对齐(Knowledge Graph Embedding User Alignment, KGEUA)算法,显著提升了用户对齐的性能。
2)提出Near_K(Nearest topK)负采样方法,解决了传统负采样方法无法保证负例质量的问题。
3)探索用户在网络结构上的相似性并提出结构相似度用于度量用户对之间的相似度。
4)提出基于自适应阈值的贪心匹配方法,克服传统静态阈值方法存在的弊端,并利用迭代对齐的思想将训练过程中新对齐的用户对加入训练集中以持续优化嵌入空间。
1 相关工作
用户对齐问题也被称为锚链接预测[7]、用户身份链接[8]。已有的用户对齐的研究大致可分基于用户信息与基于网络结构两大类。
基于用户信息的方法主要是利用用户信息如用户名[9]、空间位置[10]、文本内容[11-12]等信息进行对齐。例如 Zafarani等[9]认为用户名背后隐藏着用户名命名的行为特征,所以从多个角度建立用户名命名行为特征模型来对齐用户。但是,用户可以在不同社交网络设置不同的用户名且用户名可随时更改,这就加大了用户对齐的难度。用户生成的文本内容也常被用于用户对齐,如 Goga等[11]将用户生成文本内容的时间、位置信息以及写作风格相结合来进行用户对齐。但是由于社交网络用户信息的隐私性,所以这种方法通常存在数据获取困难的问题[6]。
通常,基于网络结构的用户对齐方法采用网络嵌入的方式进行用户对齐[13-18],如: Tan等[13]定义了用户之间的超边,并将两个网络投影到同一个向量空间中,使得超边中的节点在该空间中更接近; Liu等[14]提出IONE(InputOutput Network Embedding)模型来将两个社交网络嵌入到低维向量空间中进行对齐;Liu等[15]提出基于注意力机制的ABNE(Attention Based Network Embedding)模型,在部分已對齐的用户对上利用图注意力机制学习权重再将两个网络分别嵌入低维向量空间中并学习一个对齐方法进行对齐; Chu等[16]最近提出的CrossMNA(Crossnetwork embedding method for MultiNetwork Alignment)模型可用于多个网络的用户对齐和链接预测。
上述方法虽然对用户对齐问题的性能有所提升,但仍然存在以下三个问题:
第一,目前基于网络结构嵌入的方法通常是将两个网络分别嵌入低维向量空间中,这种方法通常会造成网络信息丢失且无法很好地挖掘两个网络间的隐藏信息。第二,传统的负采样方法是将网络关系中的用户随机替换为其他用户,该方法不能保证负例的质量。第三,传统的相似度计算方法可能存在多个用户与一个用户相似度均很高的情况,可能出现无法确定最优对齐用户的情况[19]。除此之外,传统的用户对齐算法在计算用户对相似度时未考虑用户在网络结构上的相似性;同时,用户对的相似度会随训练过程而改变,但相似度度阈值通常为固定值,可能引入噪声或限制过严从而影响对齐性能。
针对以上问题,本文提出了一种基于知识图嵌入的跨社交网络用户对齐方法。该方法利用部分种子锚用户对集合进行正例扩充,并结合Near_K负采样方法生成高质量负例,使用知识图嵌入方法将两个社交网络嵌入到统一的低维向量空间,最后通过基于自适应阈值的贪心匹配算法将新对齐的用户对加入训练集持续优化嵌入空间。
2 跨社交网络用户对齐算法
2.1 相关定义
本文使用大写字母表示集合,对应的小写字母代表该集合中的元素,加粗的小写字母表示该元素的嵌入向量,加粗的大写字母代表矩阵。
定义1 定义社交网络S=(V,E),其中V是社交网络中的用户集合,E={(vi, r, vj)|i, j=1,2,…,n,i≠j}是社交网络中的边集合,r表示社交网络中的关系。
定义2 给定社交网络S1=(V1,E1)、S2=(V2,E2)和部分已知的对齐的种子锚用户对集合A={(a1,a2)|a1∈V1,a2∈V2},其中(a1,a2)称为锚用户对。跨社交网络用户对齐的目标是利用A设计映射函数I(vi1, vj2)→{0,1}使得:
I(vi1,vj2)=1,vi1,vj2属于同一用户
0,vi1,vj2不属于同一用户 (1)
在KGEUA中,将社交网络S1,S2嵌入到统一的低维向量空间Θ。定义用户vi1∈V1, vj2∈V2是锚用户对的概率为:
P(vi1,vj2)=σ(sim(vi1,vj2))(2)
其中:σ(·)是sigmoid函数,sim(·)是相似度度量方法,则KGEUA的优化目标是找到最优的嵌入空间Θ,即:
Θ=argmax∑vi1∈V1vj2∈V2I(vi1,vj2)P(vi1,vj2;
Θ^)(3)
2.2 基于Near_K负采样与正例扩充的网络嵌入
为使得单个社交网络的结构在嵌入空间中仍尽量保存,本文利用TransE(Translating Embeddings)[20]将两个社交网络嵌入到统一的低维向量空间,同时提出Near_K负采样方法提高负例质量。此外,利用种子锚用户对扩充正例使得锚用户对之间的距离尽可能地近,非锚用户对之间的距离尽可能地远。
2.2.1Near_K负采样
考虑如图1的网络结构,为正例(v5, follow,v3)生成负例,传统方法是在v6或v1中随机选择一个用户生成负例,使其滿足(v5, follow,v6or1)E。但是因为follow(v5)∩follow(v1)=, follow(v5)∩follow(v6)={4,3},其中follow(·)代表用户的关注集合,所以在嵌入空间Θ中,sim(v5,v6)>sim(v5,v1),负例b=(v5, follow,v6)比a=(v5, follow,v1)更不容易分辨,对于Θ的学习贡献更大,因此质量更高。
具体的,给定用户vi,将其负采样的候选集C缩小到与其相似度最大的k∈(0,n]个用户组成的集合里,n表示网络中有多少个用户,即:
Cvi={vj|vj∈mink(sim(vi,vj)),
(vi,r,vj)E,k∈(0,n]}(4)
2.2.2 正例扩充
通常,为了使得已知锚用户对在嵌入空间中的距离更近,会利用参数共享的方式将锚用户对在不同网络中的向量标识强制设置为相同,但这种方法并未保留任何非锚用户对的信息,造成信息丢失。本文利用已知的种子锚用户对集合A进行正例扩充克服该缺点。
具体的,给定一组种子锚用户对(a1,a2)∈A,扩充正例如下:
Eg={(a2,r1,vj1)|(a1,r1,vj1)∈E+1}∪
{(vi1,r1,a2)|(vi1,r1,a1)∈E+1}∪
{(a1,r2,vj2)|(a2,r2,vj2)∈E+2}∪
{(vi2,r2,a1)|(vi2,r2,a2)∈E+2}(5)
其中E+1和E+2分别表示S1和S2的正例集合。两个社交网络中的全部的正例集合为E+=E+1+E+2+Eg,紧接着为正例集合E+生成负例集合E-。
入空间学习
TransE是知识图嵌入的流行方法,它将实体和关系映射到低维连续的向量空间并希望h+r≈t成立,其中h、r、t分别是头实体、关系、尾实体的向量。本文将社交关系表示为e=(vi,r,vj),使用TransE将两个网络嵌入到统一的低维向量空间中,并利用如下评分函数来度量嵌入空间中社交关系的正确性:
S(e)=‖vi+r-vj‖22(6)
该评分函数希望正例的分数尽可能地低,而负例的分数尽可能地高。所以,本文通过如下目标函数来优化嵌入空间:
J=∑e+∈E+[S(e+)-λ1]++μ∑e-∈E-[λ2-S(e+)]+(7)
s.t.λ1>0,λ2>0,λ2λ1
其中[x]+=max(0,x)返回0和x中的最大值。λ1和λ2是两个超参数,用于控制正负例的评分,μ是权重系数。本文使用Adagrad(Adaptive gradient algorithm)[21]作为优化方法进行优化。
2.3 基于自适应阈值的用户对齐
得到两个网络的嵌入后,使用基于自适应阈值的贪心匹配方法将训练过程中找到的锚用户对迭代地加入到训练集中以提升性能。除此之外,本文将提出的结构相似度与余弦相似度相结合作为相似度度量方法。
2.3.1 结构相似度
两个用户所共有的朋友数量越多,其成为朋友的概率就越大[22]。类似的,如果两个用户所共享的种子锚用户对越多,其成为锚用户对的可能性就越大。具体的,对于给定的用户对(v1,v2),其共享的种子用户为:
sharedseed={(a1,a2)∈A|(v1,r1,a1)∈E1,
(v2,r2,a2)∈E2}(8)
假设用户v在网络S中关注了种子锚用户a,考虑如下两种情况:
1)用户a在网络中共有2-000个关注者;
2)用户a在网络中只有用户v一个关注者。
很明显,第二种情况下,用户v更有可能加入另一个网络。由此可见,种子锚用户对用户的影响并不相同。
本文定义用户对(v1,v2)的结构相似度(structural similarity, ssim)如下:
ssim(v1,v2)=∑count(sharedseed)i=1im(v1,a1)+im(v2,a2)2(9)
其中:im(v,a)=related(v,a)related(a),related(a)表示与种子用户a存在关系的用户数量,related(v,a)表示种子用户a与用户v存在的关系的数量。
分别计算用户对的余弦相似度与结构相似度得到对应的矩阵M1和M2,进行加权求和得到用户对之间的相似度矩阵:
M=α×M1+(1-α)×Mnorm2(10)
其中:Xnorm=X-min(X)max(X)-min(X),α∈[0,1]是用于调节余弦相似度与结构相似度权重的超参数。
2.3.2 基于自适应阈值的贪心匹配
在第k轮迭代中,相似度矩阵为Mk,候选锚用户对集合为Qk,已配对用户集合为Yk。通过贪心匹配选取候选锚用户对过程如图2所示:依次选择最大相似度所对应的用户对(vi1,vj2),若vi1Ykandvj2Yk,则将(vi1,vj2)加入Qk,否则将其舍弃。
社交网络锚用户对数量很少,上述算法可能会将相似度很低的用户对(如图2中的(v11,v22))选为锚用户对,在后续迭代训练中引入噪声造成错误传递。本文提出通过自适应阈值(adaptive threshold)方法来筛选锚用户对。
假设在第k轮训练中,种子锚用户对集合A的最小相似度βk大于初始设定的阈值β,则将β替换为作为阈值继续进行训练。第k轮迭代时的基于自适应阈值的贪心匹配算法如算法1所示。
算法1 基于自适应阈值的贪心匹配。
输入 用户相似度矩阵Mp×q,初始阈值β,种子锚用户对集合A最大相似度βk;
输出 候选锚用户对集合Qk。
程序前
1)
将Mp×q的相似度按从大到小排序得到集合T={(vi1,vj2,sim(vi1,vj2))},i=1,2,…,p, j=1,2,…,q;
2)
初始化集合Yk
3)
for vi1,vj2,sim(vi1,vj2) inTdo
4)
if sim(vi1,vj2)<β then
5)
end for
6)
if βi>β then
7)
β=βi
8)
if vi1 not in Yk and vj2 not in Yk then
9)
将用户对(vi1,vj2)加入Qk
10)
将用户vi1和vj2加入Yk
11)
end for
12)
return Qk
程序后
2.3.3 迭代对齐
迭代对齐是指将第k轮迭代产生的候选锚用户对集合Qk加入训练集A用于k+1轮训练。迭代对齐能利用新对齐的用户对持续优化嵌入空间,同时每次迭代新对齐锚用户对只会参与下一次迭代,避免引发错误传递导致对齐性能下降。
3 实验与分析
为验证本文所提出的用户对齐算法的性能,在两个真实的社交网络数据集上进行实验,实验数据来自文献[14]的文章。表1是两个数据集的具体信息。
3.1 基准算法
本文共选用如下基准算法作比较:
MAG(Manifold Alignment on traditional Graphs) 是一种基于传统图的流形对齐方法。
MAH(Manifold Alignment on Hypergraph)[13]利用超图来对高阶关系进行建模,通过对用户所有可能的候选用户进行排序找到对齐用户。
IONE[14]在IONE中,用户节点用三个向量表示:节点向量、输入向量和输出向量。利用负采样和约束来获得用户潜在空间,利用梯度下降法进行训练。
ABNE[15]该方法是最新提出的基于注意力机制的用户对齐算法。
CrossMNA[16]该方法是最新提出的基于嵌入的跨多网络用户对齐算法。
3.2 评价指标与参数设置
本文使用常用的hits@N作为评价指标:
hits@N=RightCount@N12+RightCount@N21TestAnchors×2
其中:RightCount@N表示测试集用户预测得到的topN个用户中正确的用户数,下标代表对齐方向。TestAnchors表示测试集的锚用户对数。对于相同的N,hits@N越高代表越好的性能。
本文参数设置如下:负采样的候选集参数K为100;用于控制正负例的间隔的两个参数λ1=0.01、λ2=2;余弦相似度与结构相似度的权重参数α为0.6,自适应阈值的初始阈值β为0.75,嵌入空间维度为120。
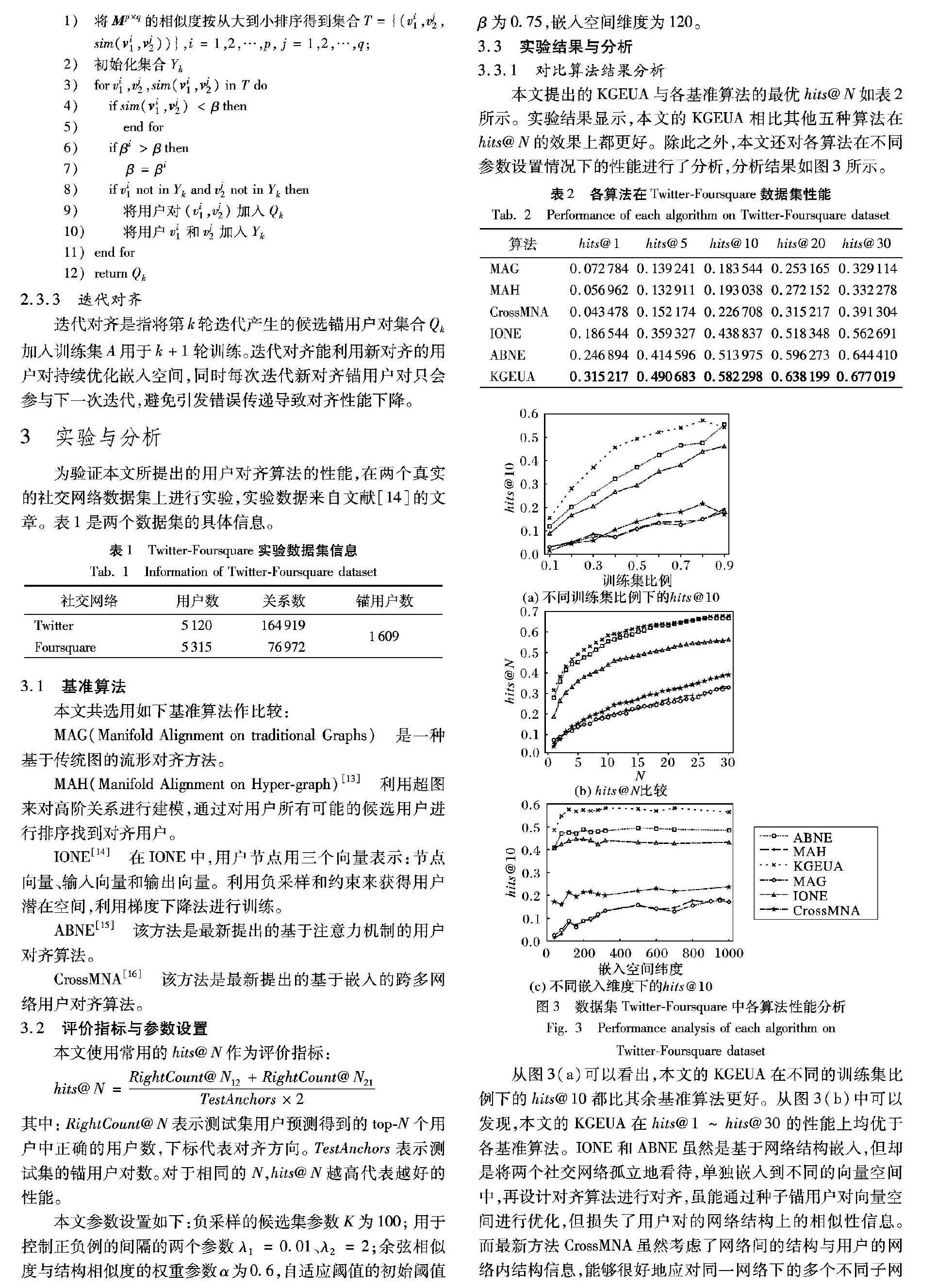
3.3 实验结果与分析
3.3.1 对比算法结果分析
本文提出的KGEUA与各基准算法的最优hits@N如表2所示。实验结果显示,本文的KGEUA相比其他五种算法在hits@N的效果上都更好。除此之外,本文还对各算法在不同参数设置情况下的性能进行了分析,分析结果如图3所示。
从图3(a)可以看出,本文的KGEUA在不同的训练集比例下的hits@10都比其余基准算法更好。从图3(b)中可以发现,本文的KGEUA在hits@1~hits@30的性能上均优于各基准算法。IONE和ABNE虽然是基于网络结构嵌入,但却是将两个社交网络孤立地看待,单独嵌入到不同的向量空间中,再设计对齐算法进行对齐,虽能通过种子锚用户对向量空间进行优化,但损失了用户对的网络结构上的相似性信息。而最新方法CrossMNA虽然考虑了网络间的结构与用户的网络内结构信息,能够很好地应对同一网络下的多个不同子网络的对齐问题,但在不同的社交网络间的效果并不好,且模型在生成负例时并未考虑负例的质量,导致性能差。本文的KGEUA将两个社交网络嵌入到统一的低维空间中,再使用扩充的正例与高质量的负例优化该嵌入空间,能够很好地保持網络结构并学习隐藏信息。从图3(c)中可以看到,本文的KGEUA在各个嵌入维度的效果都更好,且较小的嵌入维度就能很好地兼顾性能与复杂度。
3.3.2 算法有效性分析
為验证本文所提出的方法对用户对齐性能的影响,对各方法的有效性分析如图4所示。
为验证迭代对齐的效果,生成了KGEUA模型的两个变体KGEUAiterative和KGEUAnoiterative分别表示使用迭代对齐和不使用迭代对齐,并绘制了性能对比图如图4(a)所示。通过计算得知,迭代对齐相比非迭代对齐在hits@30上提升了3.3个百分点。因为在每轮迭代中,KGEUA会将新对齐的用户对加入训练集在下一轮训练中优化嵌入空间,既保证了嵌入空间的学习又防止错误选择带来的误差传递。从图4(b)中可以看出,随着候选集的扩大效果对齐性能也相应地受到影响。需要注意的是,图4(b)中,K为0代表此时候选集为全体实体即随机负采样,可以看出本文提出的Near_K负采样方法能有效提升负例的质量从而提升对齐性能。
为验证本文提出的自适应阈值的匹配方法的有效性,生成模型KGEUA的两个变体:KGEUAstatic与KGEUAadaptive。两个变体分别表示使用静态阈值与使用自适应阈值,结果如图4(c)所示。当采用本文所提出的自适应阈值时对齐性能很明显地比固定阈值的对齐性更好,是因为过小的静态阈值对用户对的筛选过于宽松,导致引入噪声过多;过大的静态阈值又过于严苛,导致无法选到更多的锚用户对。本文提出的KGEUA能根据训练的进行自适应的调整阈值,克服了静态阈值选择不当易对性能造成影响的弊端。
最后,由图4(d)的结果看出,本文提出的将结构相似度与余弦相似度相结合的方法确实能学习到用户的结构信息并有效提升用户对齐的性能,其中csim表示使用余弦相似度,ssim表示使用结构相似度,csim+ssim表示将两者结合。
综上所述,本文提出的KGEUA在真实的社交网络数据集TwitterFoursquare上的对齐性能比基准算法有显著提升,验证了本文算法的有效性。
4 结语
本文提出一种基于知识图嵌入的跨社交网络用户对齐算法。该算法利用知识图嵌入方法将两个社交网络嵌入到统一的低维向量空间中,并提出Near_K负采样方法与正例扩充方法提高嵌入质量。除此之外,提出基于自适应阈值的贪心匹配方法减少引入的噪声,同时迭代地将新对齐的用户对加入到训练集中优化向量空间。本文算法在真实社交网络数据集Twitter和Foursquare上实现用户对齐,并取得了很好的效果。本文只针对了社交网络的网络结构信息,并未使用其余属性信息。下一步工作是将网络结构中易获取、真实度高的属性信息加入到匹配过程中,优化向量空间以提升对齐性能。
参考文献 (References)
[1]SUN Y, HAN J, YAN X, et al. Mining knowledge from interconnected data: a heterogeneous information network analysis approach[J]. Proceedings of the VLDB Endowment, 2012, 5(12): 2022-2023.
[2]GlobalWebIndex. GlobalWebIndexs flagship report on the latest trends in social media[EB/OL].[2019-04-11]. https://www.globalwebindex.com/hubfs/Downloads/SocialH22018report.pdf.
[3]CARMAGNOLA F, CENA F. User identification for crosssystem personalisation[J]. Information Sciences, 2009, 179(1/2): 16-32.
[4]DENG Z, SANG J, XU C. Personalized video recommendation based oncrossplatform user modeling[C]// Proceedings of the 2013 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2013: 1-6.
[5]YAN M, SANG J, MEI T, et al. Friend transfer: Coldstart friend recommendation with crossplatform transfer learning of social knowledge[C]// Proceedings of the 2013 IEEE International Conference on Multimedia and Expo. Piscataway: IEEE, 2013: 1-6.
[6]杨奕卓, 于洪涛, 黄瑞阳, 等. 基于融合表示学习的跨社交网络用户身份匹配[J]. 计算机工程, 2018, 44(9): 45-51.(YANG Y Z, YU H T, HUANG R Y, et al. Crosssocial network user identity matching based on fusion representation learning[J]. Computer Engineering, 2018, 44(9): 45-51.)
[7]KONG X, ZHANG J, YU P S. Inferring anchor links across multiple heterogeneous social networks[C]// Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013: 179-188.
[8]SHU K, WANG S, TANG J, et al. User identity linkage across online social networks: a review[J]. ACM SIGKDD Explorations Newsletter, 2017, 18(2): 5-17.
[9]ZAFARANI R, LIU H. Connecting users across social media sites: a behavioralmodeling approach[C]// Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 41-49.
[10]RIEDERER C, KIM Y, CHAINTREAU A, et al. Linking users across domains with location data: Theory and validation[C]// Proceedings of the 25th International Conference on World Wide Web. New York: ACM, 2016: 707-719.
[11]GOGA O, LEI H, PARTHASARATHI S H K, et al. Exploiting innocuous activity for correlating users across sites[C]// Proceedings of the 22nd International Conference on World Wide Web. New York: ACM, 2013: 447-458.
[12]NARAYANAN A, PASKOV H, GONG N Z, et al. On the feasibility of Internetscale author identification[C]// Proceedings of the 2012 IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2012: 300-314.
[13]TAN S, GUAN Z, CAI D, et al. Mapping users across networks by manifold alignment on hypergraph[C]// Proceedings of the 28th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2014: 159-165.
[14]LIU L, CHEUNG W K, LI X, et al. Aligning users across social networks using network embedding[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2016: 1774-1780.
[15]LIU L, ZHANG Y, FU S, et al. ABNE: an attention based network embedding for user alignment across social networks[J]. IEEE Access, 2019, 7: 23595-23605.
[16]CHU X, FAN X, YAO D, et al. Crossnetwork embedding for multinetwork alignment [C]// Proceedings of the 2019 International World Wide Web Conference. New York: ACM, 2019: 273-284.
[17]ZHANG J, PHILIP S Y. Integrated anchor and social link predictions across social networks[C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2015: 2125-2132.
[18]ZHANG J, YU P S. PCT: partial coalignment of social networks[C]// Proceedings of the 25th International Conference on World Wide Web. New York: ACM, 2016:749-759.
[19]吳铮, 于洪涛, 黄瑞阳, 等. 基于信息熵的跨社交网络用户身份识别方法[J]. 计算机应用, 2017, 37(8): 2374-2380.(WU Z, YU H T, HUANG R Y, et al. User identification across multiple social networks based on information entropy[J]. Journal of Computer Applications, 2017, 37(8): 2374-2380.)
[20]BORDES A, USUNIER N, GARCIADURAN A, et al. Translating embeddings for modeling multirelational data[C]// Proceedings of the 27th Annual Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2013: 2787-2795.
[21]DUCHI J, HAZAN E, SINGER Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12: 2121-2159.
[22]ADAMIC L A, ADAR E. Friends and neighbors on the Web[J]. Social Networks, 2003, 25(3): 211-230.
This work is partially supported by National Key Research and Development Program of China (2017YFB0802305).
TENG Lei, born in 1995, M. S. candidate. His research interests include machine learning, data mining.
LI Yuan, born in 1992, M. S.. Her research interests include network security, deep learning.
LI Zhixing, born in 1985, Ph. D., associate professor. His research interests include natural language processing, knowledge graph, data mining, machine learning.
HU Feng, born in 1985, Ph. D., professor. His research interests include data mining, rough set, granular computing.
