基于DBSCAN算法和多源数据的缺失公交到站数据修补
2019-12-23王成崔紫薇杜梓林高悦尔
王成 崔紫薇 杜梓林 高悦尔

摘 要:針对缺失公交到站信息修补方法考虑因素较少、准确度低、鲁棒性差的现状,提出了基于DBSCAN算法和多源数据的缺失公交到站数据修补方法。该方法使用公交全球定位系统(GPS)、公交集成电路卡(IC)等多源数据进行缺失到站信息的修补。对于缺失的到站名称、到站经纬度数据,用已有完整到站数据和静态线路信息关联分析进行修补。对于缺失的到站时刻数据,则按以下步骤进行修补:首先,对每一个缺失数据站点与其最近的未缺失数据站点,将这两站点间历史完整到站数据的行程时间和班次时序进行基于DBSCAN算法的聚类;其次,判断研究班次的两个相邻的数据完整的班次所属簇是否为同一个簇,若为同一个簇则不作改变,否则将两个簇合并;最后,将簇中点对应最大行程时间作为缺失行程时间判断是否有乘客在该站点上车刷卡,若有则由乘客开始刷卡时刻推算到站时刻,若无则将簇中点对应最大、最小行程时间的均值作为缺失行程时间推算到站时刻。以厦门市公交到站数据为例,在缺失到站名称、经纬度修补中,基于GPS数据聚类的方法、基于极大概率估计的方法和所提方法皆可进行100%的修补;在缺失到站时刻修补中,所提方法的平均相对误差比两种对比方法分别低0.030-1%和0.000-4%,相关系数比对比方法分别高0.005和0.007-5。实验结果表明,所提算法在缺失公交到站数据修补中能有效提高修补的准确度,降低缺失站点个数变化对于准确度的影响。
关键词:缺失到站数据修补;DBSCAN算法;到站经纬度;到站时刻;多源数据
中图分类号: TP311
文献标志码:A
Repairing of missing bus arrival data based on DBSCAN algorithm and multisource data
WANG Cheng1*, CUI Ziwei1, DU Zilin1, GAO Yueer2
1.College of Computer Science and Technology, Huaqiao University, Xiamen Fujian 361021, China;
2.School of Architecture, Huaqiao University, Xiamen Fujian 361021, China
Abstract:
In order to solve the problem that the existing repair methods for missing bus arrival information have little factors considered, low accuracy and poor robustness, a method to repair missing bus arrival data based on DBSCAN (DensityBased Spatial Clustering of Applications with Noise) algorithm and multisource data was proposed. Bus GPS (Global Positioning System) data, IC (Integrated Circuit) card data and other source data were used to repair the missing arrival information. For the name, longitude and latitude data of the missing arrival station, the association analysis of complete arrival data and static line information were carried out to repair. For the missing arrival time data, the following steps were taken to repair. Firstly, for every missing data station and its nearest nonmissing data station, the travel time and schedule in the historical complete arrival data between the two stations were clustered based on DBSCAN algorithm. Secondly, whether the two adjacent runs of the studied bus with complete data belonged to the same cluster was judged, and if they belonged to the same cluster, th cluster would not change, otherwise the two clusters would be merged. Finally, the maximum travel time corresponding to the cluster midpoint was used as the missing travel time to determine whether there was a passenger swiping his card to board the bus at this station or not, if so, the arrival time was calculated from the time of swiping cards, and if not, the mean of the maximum and minimum travel time corresponding to the cluster midpoint was used as the missing travel time to calculate the arrival time. Taking Xiamen bus arrival data as examples, in the repair of name, longitude and latitude of the missing arrival station, the clustering method based on GPS data, the maximum probability estimation method and the proposed method can repair the data by 100.00%. In the repair of missing arrival time, the mean relative error of the proposed method is 0.030-1% and 0.000-4% lower than that of two comparison methods respectively, and the correlation coefficient of the proposed method is 0.005 and 0.007-5 higher than that of two comparison methods respectively. The simulation results show that the proposed method can effectively improve the accuracy of repair of missing bus arrival data, and reduce the impact of the number of missing stations on accuracy.
Key words:
bus missing arrival data repair; DensityBased Spatial Clustering of Applications with Noise (DBSCAN) algorithm; longitude and latitude of arrival station; arrival time; multisource data
0 引言
受城市建筑阴影效应等影响,公交到站数据会出现缺失现象,严重影响公交车辆运营特征的分析、乘客上车站点识别等。现有研究表明,3.75%的公交到站数据缺失即可造成超过25%的乘客上车站点匹配失败[1],因此公交缺失到站数据修补是必要的,本文对于公交到站数据的到站名称、经纬度和时刻数据进行修补。
公交到站数据的修補可根据使用数据类型分为仅使用公交全球定位系统(Global Positioning System, GPS)数据和使用多源数据两大类。仅使用公交GPS数据方法分为基于统计分析的填充和基于数据挖掘的填充。基于统计分析的填充通过熟悉数据集的研究者构建拟合模型、估计统计参数实现对缺失数据的填充,常见方法有线性拟合填充法[2]、均值填充法[3]、概率估算法[4]等,但只用于小样本数据集中,难以适应交通大数据分析的需求。基于数据挖掘的填充可充分利用海量数据的特点、不受研究者对数据集熟悉程度的影响进行修补缺失值,常见方法有k最 近 邻 填 充[5-6]、双向循环神经网络[7]、贝叶斯网络[8]、聚类方法填充[9-14]等; 但仅使用公交GPS数据的方法所使用的数据少,获得的信息不够全面,因此修补准确度低。基于多源数据的修补可分为间接修补和直接修补两种:间接修补首先通过对伴随的集成电路(Integrated Circuit, IC)卡刷卡数据中缺失信息进行修补,以此推算缺失的GPS到站数据,但没有乘客上(下)车刷卡的站点无法进行修补,常见的方法有基于行程的网络多模态特性研究方法[15]、基于刷卡数据分离和序列约束站点匹配的方法[16]、基于车辆运营时刻表方法[17]等;直接修补可从根本上对于缺失到站数据进行修补,对于无乘客上下车的缺失到站数据也可进行修补,修补范围更广,可以更好地进行公交运营特征的挖掘,常见的方法有基于车辆运营时刻表、基于极大概率估计的方法[18]等,但这些方法受路段状况等随机因素的影响过大、没有剔除噪声数据的影响,因此缺失值修补的准确度不高。
本文的主要贡献如下:
1)选择获得信息更全面、修补数据范围更广的多源数据进行缺失到站数据的直接修补,使用的数据为GPS数据、IC卡数据和静态线路信息数据;
2)对于现有方法噪声数据影响较大的情况,依赖同类数据对缺失数据进行修补以此降低噪声影响。获取同类数据时,采用聚类的方法,并且结合了站点间行程时间和完整到站班次时序,以此将后者反映的缺失数据班次所在时段内路况、天气等影响因素信息加入考虑,使修补值更接近实际;
3)同类数据常见的聚类方法有基于密度聚类方法[19]和基于划分聚类方法(如Kmeans聚类算法)[20]等,根据本文数据的特点:聚集数量不明确和噪声点影响较大选择了密度聚类中的DBSCAN(DensityBased Spatial Clustering of Applications with Noise)算法对于数据进行聚类;
4)对于现有研究将站点间行程时间取值范围设置为相同数值的情况,本文对任意两站点间的行程时间和完整到站时序进行聚类,使得每一对站点间的行程时间取值范围具有个性化,以此获得更准确的同类数据和修补值,并使得修补数据准确度受缺失站点个数变化的影响程度低、普适性高。
1 问题描述及分析
1.1 公交到站数据介绍
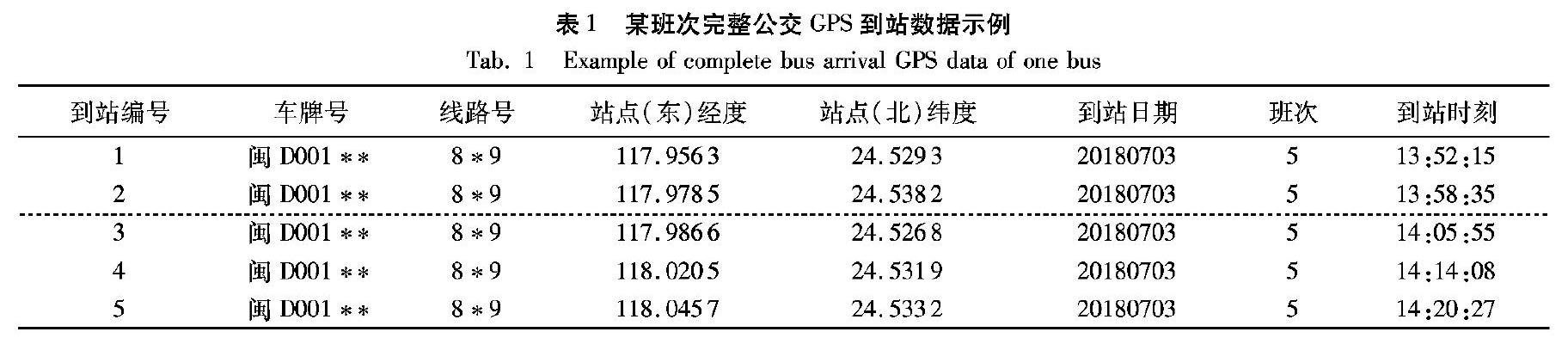
某班次完整公交GPS到站数据包括到站编号(本文中用到站编号代替到站名称说明问题)、车牌号、线路号、站点(东)经度、站点(北)纬度、到站日期、班次和到站时刻(如表1所示);若某班次缺失1号站点和2号站点到站数据,则其原始数据仅包含其余站点的到站数据(如表1点线以下部分所示)。
1.2 刷卡数据及线路数据介绍
目前,大部分城市公交乘客只在上车刷卡、下车不刷卡,因此本文使用乘客上车IC刷卡数据进行分析,则有某班次同一站点乘客上车IC刷卡数据包括卡号、刷卡日期、刷卡时刻、乘坐的线路号和乘坐车辆的车牌号(如表2所示)。
某线路某运营车辆静态线路信息示例包括到站编号、车牌号、线路号、站点(东)经度和站点(北)纬度(如表3所示)。
1.3 公交到站数据的缺失情况
设S1,S2,…,Sk,…,SK为公交某班次运行中连续缺失到站GPS数据的站点,Sbefore为S1之前到达的最后一个数据完整站点,Safter为SK之后到达的第一个数据完整站点。如图1所示,对于某班次,公交到站数据的缺失通常分为三种情况:
缺失前半部分数据 即公交某班次运行中连续经过的站点为S1,S2,…,Sk,…,SK,Safter。
缺失中间部分数据 又分为连续多个缺失和单个缺失,后者可视为前者的一种特例,即公交某班次运行中连续经过的站点为Sbefore,S1,S2,…,Sk,…,SK,Safter。
缺失后半部分数据 即公交某班次运行中连续经过的站点为Sbefore,S1,S2,…,Sk,…,SK。
对于缺失中间部分数据,可由缺失数据站点前(后)最近的完整到站数据站点后推(前推)得到缺失站点相关数据,因此可视为缺失前(后)半部分数据的特例,本质都为由第一条(最后一条)完整到站数据推得未知到站数据。因此,后面仅对连续缺失前半部分到站数据的情况进行叙述。
2 缺失公交到站数据修补
2.1 缺失到站名称、经纬度修补
鉴于公交运营线路固定、停靠站点固定的实际情况,可结合完整到站数据与静态线路信息修补缺失到站名称、经纬度。三者之间进行关联分析修补的方法如图2所示,对于某班次到站数据修补的具体流程为:根据完整到站数据和静态线路信息得到缺失到站数据的站点编号,再以此对于缺失站点编号的缺失名称、经纬度进行修补,直至本班次全部站点的到站名称、经纬度修补完毕(如表4所示),此时,仅有到站时刻数据未进行修补。
2.2 缺失到站时刻修补
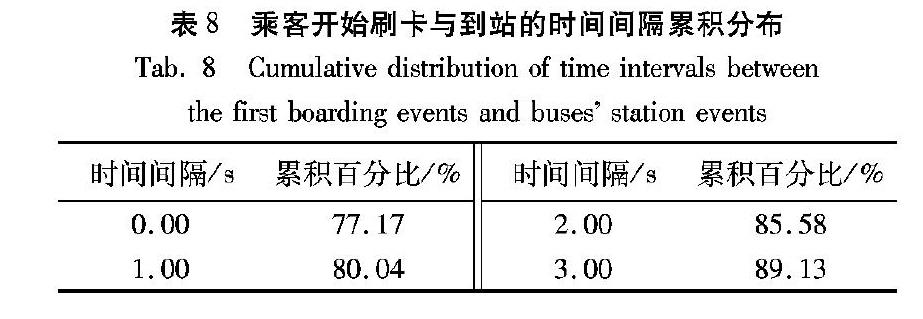
在连续缺失前半部分到站数据的情况下,设到达站点Safter时刻为Tafter,则从站点Sk到Safter的行程时间为tk,after,取值范围为Tk,after。设缺失到站数据班次所在线路同一行驶方向同一天内,有N班次同時在缺失到站数据站点Sk与站点Safter有完整到站数据,将N班次按照到达站点Safter的先后排序即有集合{l1,l2,…,ln,…,lN},对应到达站点Safter的时刻为{Tl1after,Tl2after,…,Tlnafter,…,TlNafter},并且对应从Sk到Safter的行程时间为{tl1k,after,tl2k,after,…,tlnk,after,…,tlNk,after}。某班次在第k个站点Sk的缺失到站时刻Tk修补步骤如下所示:
步骤1 将N趟班次按照到达站点Safter的先后顺序,与对应从Sk到Safter的行程时间,整合成为包含N趟班次的二维空间点集,如下所示:
P={(l1,tl1k,after),…,(ln,tlnk,after),…,(lN,tlNk,after)}(1)
步骤2 给定半径ε,以及最小个数M,对步骤1的空间点集合进行聚类得到Nsum个簇,即为{C1,C2,…,Cnsum,…,CNsum}。
步骤3 N趟班次中,缺少数据班次在Tafter到达站点Safter后第一个到达此站点的班次为:
laftern=argmin{Tlnafter|Tlnafter>Tafter,
ln∈{l1,l2,…,ln,…,lN}}(2)
缺少数据班次在Tafter到达站点Safter前最后一个到达此站点的班次为(如图3所示):
lbeforen=argmax{Tlnafter|Tlnafter ln∈{l1,l2,…,ln,…,lN}}(3) 步骤4 由步骤2可得,第laftern班次属于簇Cone,则有Cone中全部点的纵坐标取值范围,即为行程时间取值范围为TCone;第lbeforen班次属于簇Ctwo,则有Ctwo中全部点的纵坐标取值范围,即为行程时间取值范围为TCtwo。因此从站点Sk到Safter的行程时间取值范围为: Tk,after=TCone∪TCtwo(4) 步骤5 行程时间取值范围Tk,after的最小值为: tmink,after=minTk,after(5) 行程时间取值范围Tk,after的最大值为: tmaxk,after=maxTk,after(6) 则根据已知的到达站点Safter时刻为Tafter,判断在时间段[Tafter-tmaxk,after,Tafter]内是否有乘客刷卡: 如果有,可得第一位刷卡乘客的刷卡时刻为tICk,则有从站点Sk到Safter的行程时间为: tk,after=Tafter-(tICk-Tp)(7) 其中:Tp表示乘客开始刷卡时刻与车辆进站的时间间隔,如图4所示;tICk-Tp即为某班次在第k个缺失到站数据站点的到站时刻;如果没有,则从站点Sk到Safter的行程时间为: tk,after=tmink,after+tmaxk,after2(8) 步骤6 某班次在第k个缺失到站数据站点的到站时刻为: Tk=Tafter-tk,after(9) 2.3 缺失公交到站数据修补流程 实际情况中,缺失到站名称、经纬度与缺失到站时刻同时存在,需要进行基于DBSCAN和多源数据的缺失公交到站数据修补,流程如图5所示。 2.4 算法的理论分析与比较 设置基于GPS数据聚类的方法[9-14]作为对比实验的原因在于改变是否使用IC卡刷卡数据,可以更好地说明使用伴随IC卡刷卡数据对于缺失到站数据修补的影响,因此将对比实验聚类方法选择与本文一致的DBSCAN方法。现有研究表明,多源数据可以将多种环境或对象进行综合,可以获得比单一信息源更高质量、更精确、更完全的信息,因此本文方法理论上修补准确度及普适性优于基于GPS数据聚类的方法。在时、空复杂度方面,本文方法虽对缺失站点行程时间范围内IC卡刷卡数据进行了排序,但此操作远低于聚类算法的时、空复杂度,因此本文方法的时、空复杂度即为对于N班次历史行程时间及顺序进行基于DBSCAN聚类的时、空复杂度,与使用DBSCAN对GPS数据聚类方法的时、空复杂度一样,与其他常见聚类修补数值方法的时、空复杂度比较如表5所示。 极大概率估计方法本文方法GPS、IC卡刷卡 相邻刷卡记录的固定分离阈值O(NIC)O(NIC)中低 ε、MO(N2)O(N)高高 !根据情况左右加 注:基于GPS数据kmeans聚类的参数表示迭代次数、表示聚类类别个数;基于GPS数据DBSCAN聚类和本文方法中的参数ε表示半径、 M表示最小个数;极大概率估计方法的时、空复杂度中NIC表示某缺失数据班次的全部刷卡数据。 极大概率估计方法[18]首先拟合缺失站点对间的历史行程时间分布;其次,根据相邻刷卡记录的固定分离阈值将同一辆车同方向各站的乘客刷卡记录分离;然后,判断若有乘客在缺失站点上车刷卡,则将缺失站点的第一条刷卡数据时刻作为时间戳,选择参考点出站时刻到该时间戳的行程时间内,概率最大的到达站点即为缺失到站站点;最后,对于无乘客上车刷卡的站点,通过高斯分布函数等拟合参考点至站点的历史行程时间集合,选择概率最大的历史行程时间作为缺失行程时间。对于有乘客上车的站点,极大概率估计方法对缺失站点的第一条刷卡数据判断准确度依赖程度较高,此方法相邻刷卡记录的固定分离阈值无法根据不同站点之间的实际情况进行调节,噪声点影响较大;对于无乘客上车刷卡的站点,极大概率估计方法将全部历史行程时间进行拟合分布,但实际中大部分线路早、晚高峰时段的班次总数少于平峰时段的,因此概率最大的历史行程时间最有可能为平峰时段的行程时间,不适用于发生拥堵概率最高的早晚高峰时段缺失数据的修补。 与极大概率估计方法相比,本文对历史行程时间及班次顺序进行了聚类,使得相似的数据同簇,以此发现其内在联系,基于缺失数据班次的相似数据推算行程时间取值范围,随后再判断行程时间取值范围内是否有IC卡刷卡数据,若有则根据第一条刷卡数据确定缺失到站时刻,若无则根据相似行程时间数据确定缺失到站时刻。本文基于聚类后的相似数据对行程时间取值范围个性化设置,比基于全部历史数据的行程时间确定更符合实际,因此本文方法理论上修补准确度及普适性优于极大概率估计方法。在时、空间复杂度方面,由前文叙述已知,本文方法对于N班次历史行程时间及顺序进行了基于DBSCAN的聚类,所以时间复杂度为O(N2)、空间复杂度为O(N),而极大概率方法虽无需进行聚类且拟合用时较少,但需要对于某缺失数据班次的全部NIC条刷卡数据进行判断相邻刷卡的时间间隔大小,因此时、空复杂度皆为O(NIC)。实际情况中一条线路某天某班次的刷卡数据量远大于该天的班次数量,因此本文方法的空间复杂度远低于极大概率方法的空间复杂度,并且在早晚高峰时段缺失数据班次的刷卡数量较多时,本文方法的时间复杂度与极大概率方法的相近。 3 实验与结果 3.1 数据集介绍 本文以厦门市2018年某日为例,对于8*9路上行方向的68个班次2-584条到站数据进行统计(每班次38个到站站点),发现GPS数据缺失情况如表6所示。选取到站数据完整的8*9路上行方向到达第35个站点时刻为19:33:07的班次,以及此班次GPS到站数据的(东)经度、(北)纬度和乘客IC刷卡数据。 3.2 检验方法和评价标准 检验方法 根据第35个站点的到站数据,推得第24~34个站点的到站数据,并与真实到站数据比较进行方法检验。 评价标准 1)使用错误修补的比率(False Classify Rate, FCR)[21]对修补的到站名称、到站经纬度进行检验。2)用平均相对误差指标与相关系数指标对修补的到站时刻进行检验:设平均相对误差指标为δave,其代表修补值可信程度,数值越小越说明修补值与真实值差距越小、修补准确度越高;设相关系数指标为R,其代表修补值与真实值相关性的相关性系数,数值越接近1越说明修补方法准确度受缺失站点个数变化的影响程度越低,即随着缺失数据站点与完整到站数据站点的距离变化、修补准确率变化较小。 3.3 缺失公交到站数据修补结果 首先,确定DBSCAN聚类算法中最小个数M的取值,对于研究的N=56班次假设缺失数据站点34和完整到站数据站点35,随着最小个数的取值不同,簇的数量随着半径的变化如图6所示:大部分情况下,簇的个数与最小个数的大小成反比。由现实情况可知,一天中公交两站点间行程时间,可根据普遍的工作时间与休息时间理论上至少可分为早高峰、上午平峰、午高峰、下午平峰、晚高峰、晚上平峰6种,即为6个簇,则当M=2或M=3时符合此现状。但是簇的个数过多会造成聚类效果差,缺失数据补全时依据的历史数据过少,使得修补效果差的情况,因此本文令M=3。 其次,在确定M=3后,当缺失数据站点与完整数据站点相距不同时,即为站点对不同时,簇的数量随半径的变化呈现不规则变化,如图7所示:当M=3时,缺失数据站点与完整数据站点相距不同所对应的最大簇的数量是可接受的个数,大于理论最小值6且没有过大造成聚类效果差。因此,本文选择最大簇的个数作为行程时间聚类后的簇个数,但此时对应的半径可能为多个值。由于最小個数、簇的数量一定的情况下,半径越大、噪声点的数量越少,可以利用的历史数据量越多,因此本文选择簇个数最大时的最大半径作为缺失站点数据进行行程时间聚类时的半径ε。基于上述分析,本文对于56班次第24~34个站点的到站数据分别进行修补时,得到聚类结果如表7所示。 最后,对于2018年某日厦门市全部线路的已识别上车站点数据,本文进行乘客开始刷卡与到站的时间间隔统计:乘客开始刷卡时刻与到站时刻间隔的均值为1.03s;有80.04%的时间间隔在1s及以内(如表8所示)。因此,本文选择乘客开始刷卡与到站的时间间隔Tp=1.00s。 根据实验参数的设置结果,本文方法与两种对比方法的修补到站时刻如图8所示、检验结果如表9所示,并且不同方法修补到站时刻相对误差如图9所示(时刻皆已转换成为一天00:00:00为参照以秒为单位的数值)。 3.4 结果分析 1)由表9可得,对于FCR指标代表的缺失到站名称、经纬度修补,三种方法皆可以进行100%的正确修补。说明是否使用多源数据和聚类后的历史相似班次数据进行推算,对于缺失到站名称、经纬度修补的影响较小。 2)图8可得,本文方法在三种方法中,大部分站点的修补到站时刻与真实到站时刻相距最近,且由表9可得本文方法平均相对误差δave=0.113-5%是三种方法中最小、修补准确度最高的。同时发现,仅使用单一GPS数据源的基于DBSCAN和多源数据方法的平均相对误差,远大于另外两种基于多源数据的方法,说明使用多源数据对于缺失到站时刻修补的准确度产生了有益的影响;并且与本文同样使用多源数据,但基于全部历史班次数据确定行程时间取值范围的极大概率估计方法平均相对误差比本文方法的大,说明使用聚类后的相似班次数据对于缺失到站时刻修补的准确度产生了有益的影响。 3)图9可得,本文方法的相对误差随缺失站点个数的变化趋势最平稳,且由表9可得本文方法的R值最接近1,因此是三种方法中准确度受缺失站点个数变化的影响程度最低、普适性最高的。同时发现,极大概率估计方法R值最小,说明本文方法使用聚类后的相似班次数据进行推算,对于缺失到站时刻修补的普适性产生了有益的影响,并且得到是否使用多源数据对于缺失到站时刻修补的普适性影响较小的结论。 综上,本文基于DBSCAN和多源数据的缺失公交到站数据修补方法,在缺失到站时刻修补的准确度和普适性方面均优于基于GPS数据聚类的方法和极大概率估计方法。同时得到结论:多源数据对于缺失到站时刻修补的准确度产生了有益的影响、但对于普适性影响较小;使用历史数据聚类后的相似班次数据进行推算,对于缺失到站时刻修补的准确度和普适性都产生了有益的影响。 4 结语 本文提出了一种基于DBSACN和多源数据的缺失到站数据修补方法,可对缺失的公交到站经纬度、到站时刻数据进行修补。实例及检验结果表明,本文方法使用了多源数据和聚类后的相似班次数据进行推算,比现有的基于GPS数据聚类的方法、基于极大概率估计方法,具有更好的修补准确度和普适性。 本方法的缺陷为无法对于整班次的到站时刻丢失数据进行修补,也无法对于缺失的到站时刻数据进行实时预测或修补,且DBSCAN聚类算法中有较多参数需要调整,与其他方法的时、空复杂度可在不同地区不同数据集上进行应用对比,如有条件还可将由乘客经验得到的先验知识加入考虑,未来可对这些情况进行深入研究。 参考文献 (References) [1]LIU Y, WENG X, WAN J, et al. Exploring data validity in transportation systems for smart cities[J]. IEEE Communications Magazine, 2017, 55(5): 26-33. [2]ZHANG H, ZHANG Y, LI Z, et al. Spatialtemporal traffic data analysis based on global data management using MAS[J]. IEEE Transactions on Intelligent Transportation Systems, 2004, 5(4): 267-275. [3]吴昊,唐振军.加权壳近邻填充数学模型[J].华南师范大学学报(自然科学版),2013,45(3):45-48.(WU H, TANG Z J. Weighted shellneighbor imputation models[J]. Journal of South China Normal University (Natural Science Edition), 2013, 45(3): 45-48.) [4]ZHOU Y, YAO L, CHEN Y, et al. Bus arrival time calculation model based on smart card data[J]. Transportation Research Part C: Emerging Technologies, 2017, 74: 81-96. [5]CHEN J, SHAO J. Nearest neighbor imputation for survey data[J]. Journal of Official Statistics, 2000, 16(2): 113-131. [6]郝胜轩,宋宏,周晓锋.基于近邻噪声处理的KNN缺失数据填补算法[J]. 计算机仿真,2014,31(7):264-268. (HAO S X,SONG H,ZHOU X F. Predicting missing values with KNN based on the elimination of neighbor noise[J]. Computer Simulation,2014,31(7):264-268.) [7]陈奔.基于双向递归神经网络的轨迹数据修复[D].济南:山东大学, 2018.(CHEN B. Trajectory data repair based on bidirectional recurrent neural network [D]. Jinan: Shandong University, 2018.) [8]QU L, ZHANG Y, HU J, et al. A BPCA based missing value imputing method for traffic flow volume data[C]// Proceedings of the 2008 IEEE Intelligent Vehicles Symposium. Piscataway: IEEE, 2008: 985-990. [9]趙霞,张勇,尹宝才,等.基于改进k*means 算法的不完整公交到站时间填充[J]. 北京工业大学学报, 2018, 44(1): 135-143. (ZHAO X, ZHANG Y, YIN B C, et al. Imputation of incomplete bus arrival time based on the improvedk*means algorithm [J]. Journal of Beijing University of Technology, 2018, 44(1): 135-143.) [10]王妍,王凤桐,王俊陆,等.基于泛化中心聚类的不完备数据集填补方法[J]. 小型微型计算机系统, 2017, 38(9) :2017-2021. (WANG Y, WANG F T, WANG J L, et al. Missing data imputation approach based on generalized centroids clustering algorithm[J]. Journal of Chinese Computer Systems, 2017, 38(9) :2017-2021.) [11]冷泳林,陳志奎,张清辰,等.不完整大数据的分布式聚类填充算法[J].计算机工程, 2015, 41(5):19-25. (LENG Y L, CHEN Z K, ZHANG Q C, et al. Distributed clustering and filling algorithm of incomplete big data[J]. Computer Engineering, 2015,41(5):19-25.) [12]赵亮,陈志奎,张清辰.基于分布式减法聚类的不完整数据填充算法[J].小型微型计算机系统, 2015, 36(7):1409-1414. (ZHAO L, CHEN Z K, ZHANG Q C. Incomplete data imputation algorithm based on distributed subtractive clustering[J]. Journal of Chinese Computer Systems, 2015, 36(7):1409-1414.) [13]韩飞,沈镇林.基于不完备集双聚类的缺失数据填补算法[J].计算机工程, 2016, 42(4): 20-26. (HAN F, SHEN Z L. Missing data filling algorithm based on incomplete set biclustering[J]. Computer Engineering, 2016, 42(4): 20-26.) [14]刘思谦,陈志奎,蒋昆佑,等.一种混杂的多核估计数据填充方法[J].小型微型计算机系统, 2017, 38(7):1523-1527. (LIU S Q, CHEN Z K,JIANG K Y, et al. Hybrid multikernels estimation method for data imputation[J]. Journal of Chinese Computer Systems, 2017, 38(7):1523-1527.) [15]VIGGIANO C, KOUTSOPOULOS H N, WILSON N H M, et al. Journeybased characterization of multimodal public transportation networks[J]. Public Transport, 2017, 9(1/2): 437-461. [16]LI M, DU B, HUANG J, et al. Public transport smart card data analysis and passenger flow distribution[EB/OL].[2019-05-20].https://ascelibrary.org/doi/abs/10.1061/9780784412442.170。. [17]BARRY J J, FREIMER R, SLAVIN H L. Use of entryonly automatic fare collection data to estimate linked transit trips in New York city[J]. Transportation Research Record Journal of the Transportation Research Board, 2009, 2112:53-61. [18]刘永鑫.基于多源数据融合的城市公交系统乘客出行模式挖掘及其应用研究[D].广州: 华南理工大学,2018.(LIU Y X. Study on key technologies of transit passengers travel pattern mining and applications based on multiple sources of data[D]. Guangzhou: South China University of Technology,2018.) [19]潘冬明,黄德才.基于相对密度的不确定数据聚类算法[J].计算机科学,2015,42(11A): 72-88. (PAN D M, HUANG D C. Relative densitybased clustering algorithm over uncertain data[J]. Computer Science,2015,42(11A): 72-88.) [20]张建民,姚亮,胡学钢.一种面向数据缺失问题的Kmeans 改进算法[J].合肥工业大学学报(自然科学版), 2008, 31(9): 1455-1457. (ZHAN J M, YAO L, HU X G. An improvedKmeans algorithm for the datamissing problem[J]. Journal of Hefei University of Technology (Natural Science), 2008, 31(9): 1455-1457.) [21]應臻奕.基于AP聚类的不完备数据处理方法的研究与实现[D]. 北京:北京邮电大学,2018.(YING Z Y. Research and implementation of incomplete data processing based on AP clustering[D]. Beijing: Beijing University of Posts and Telecommunications,2018.) This work is partially supported by the National Natural Science Foundation of China Youth Fund (51608209), the Project of Natural Science Foundation of Fujian Province (2017J01090), the Project of Guiding Plan of Fujian Province (2019H0017), the Project of Quanzhou Science and Technology Plan (2018Z008), the Project of Postgraduate Research Innovation Ability Cultivation of Huaqiao University (17013083017). WANG Cheng, born in 1984, Ph. D., associate professor. His research interests include traffic big data, data mining, machine learning. CUI Ziwei, born in 1995, M. S. candidate. Her research interests include traffic big data, data mining. DU Zilin, born in 1997. His research interests include traffic big data, data mining. GAO Yueer, born in 1983, Ph. D., associate professor. Her research interests include traffic big data, data mining.
