融合地点影响力的兴趣点推荐算法
2019-12-23许朝孟凡荣袁冠李月娥刘肖
许朝 孟凡荣 袁冠 李月娥 刘肖


摘 要:為解决兴趣点(POI)推荐不准确和效率低的问题,深入分析社交因素和地理位置因素的影响,提出了一种融合地点影响力的POI推荐算法。首先,为了解决签到数据稀疏的问题,将2度好友引入协同过滤算法中构建了社交影响模型,通过计算经历和好友相似度获取2度好友对用户的社交影响;其次,深入考虑地理位置因素对POI推荐影响,在对社交网络分析的基础上构造了地点影响力模型,通过PageRank算法发现用户影响力,结合POI被签到次数计算地点影响力,获取准确的整体位置偏好,并使用核密度估计方法对用户签到行为建模和获取个性化地理位置特征;最后,融合社交模型和地理位置模型提高推荐准确性,并通过构造POI推荐候选集来提高推荐效率。在Gowalla和Yelp签到数据集上实验,结果表明所提算法能够快速完成POI推荐,在准确率和召回率指标上明显优于融合时间因素的位置推荐(LRT)和融合地理社交因素的个性化位置推荐(iGSLR)算法。
关键词:兴趣点推荐;基于位置的社交网络;协同过滤算法;地点影响力;核密度估计
中图分类号:TP391.1
文献标志码:A
PointofInterest recommendation algorithm combining location influence
XU Chao1,2, MENG Fanrong1, YUAN Guan1*, LI Yuee2, LIU Xiao1
1.College of Computer Science and Technology, China University of Mining and Technology, Xuzhou Jiangsu 221116, China;
2.Archives, China University of Mining and Technology, Xuzhou Jiangsu 221116, China
Abstract:
Focused on the issue that PointOfInterest (POI) recommendation has low recommendation accuracy and efficiency, with deep analysis of the influence of social factors and geographical factors in POI recommendation, a POI recommendation algorithm combining location influence was presented. Firstly, in order to solve the sparseness of signin data, the 2degree friends were introduced into the collaborative filtering algorithm to construct a social influence model, and the social influence of the 2degree friends on the users were obtained by calculating experience and friend similarity. Secondly, by deep consideration of the influence of geographical factors on POI, a location influence model was constructed based on the analysis of social networks. The users influences were discovered through the PageRank algorithm, and the location influences were calculated by the POI signin frequency, obtaining overall geographical preference. Moreover, kernel density estimation method was used to model the users signin behaviors and obtain the personalized geographical features. Finally, the social model and the geographic model were combined to improve the recommendation accuracy, and the recommendation efficiency was improved by constructing the candidate POI recommendation set. Experiments on Gowalla and Yelp signin datasets show that the proposed algorithm can quickly recommend POIs for users, and has high accuracy and recall rate than Location Recommendation with Temporal effects (LRT) algorithm and iGSLR (Personalized GeoSocial Location Recommendation) algorithm.
Key words:
pointofinterest recommendation; locationbased social network; collaborative filtering algorithm; location influence; kernel density estimation
0 引言
随着网络技术和移动对象定位技术的进步,基于位置的社交网络(LocationBased Social Network, LBSN)得到了快速的发展,为人们提供了极其便利的位置服务。典型的LBSN应用有Foursquare、Gowalla和大众点评等,这些应用主要包括位置推荐、位置签到、位置评论和位置共享等功能[1-2]。在LBSN中,为用户推荐可能感兴趣的地理位置的服务被称为兴趣点(PointOfInterest, POI)推荐。POI推荐对促进旅游、商家营销推荐、研究用户的活动模式和生活规律具有重要意义。
协同过滤算法被广泛应用于轨迹聚类[3]和位置预测算法中,大量的兴趣点推荐算法[4-6]在协同过滤算法的基础上,通过考虑社交和地理位置等诸多因素的影响来提升推荐效果, 然而,这些算法普遍存在以下两个问题:
1)推荐不准确。LBSN中兴趣点总数异常庞大,用户访问的兴趣点只占极少一部分,这导致用户兴趣点签到矩阵极为稀疏,使得挖掘用户的偏好具有难度,且由于各算法在考虑社交和地理位置等因素的影响时不够深入全面,进一步造成推荐的不准确。
2)推荐缺乏个性化、推荐效率低。协同过滤算法的基础是相似度计算,算法缺乏个性化的表示方法,导致难以获取用户的个性化偏好。由于算法缺乏简单有效的召回机制,需要针对所有兴趣点计算推荐得分,因此造成大量的时间消耗,导致推荐效率低。
对于问题1),本文探索用户好友及2hop好友的社交影响,缓解数据的稀疏问题。融入从整体签到数据和个人签到数据中深入挖掘的地理位置特征,提升推荐的准确性。对于问题2),本文利用核密度估计方法对用户的个人签到数据进行建模,用以获取用户个性化的地理位置偏好,提高推荐的个性化程度。同时,构造推荐候选集以提高算法的推荐效率。
针对上述问题,本文综合应用协同过滤技术和社交网络分析技术,从理论上研究LBSN中POI推荐问题,从应用上解决数据稀疏和推荐效率低的问题。
1 相关工作
目前大多数兴趣点推荐算法由协同过滤算法发展而来,主要分析社交因素、地理位置因素和时间因素的影响,并将这些影响因素加入模型中进而改善推荐的效果。
1)基于社交因素的推荐。
根据社会同质理论和影响理论,好友间会表现出共同的兴趣爱好和相似行为,用户倾向于接受朋友的推荐。大量的研究利用社交因素来提高兴趣点推荐的质量。其中:文献[1]在协同过滤算法的基础上,综合考虑社交因素和地理位置因素,提出了融合地理社交因素的个性化位置推荐(Personalized GeoSocial Location Recommendation,iGSLR)算法;文献[4]利用矩阵分解(Matrix Factorization,MF)模型,融合用户的社交影响力对模型进行增强;文献[5]将好友类型划分为社交好友、位置好友和邻近好友,系统地考虑了不同好友的社交影响; 文献[6-7]通过对社交因素、地理位置因素和兴趣点类别因素之间相关性的研究,提升推荐效果。
2)融合地理位置因素的推荐。
与音乐、电影等项目推荐不同,地理位置因素是興趣点推荐的一个独特因素,大量的研究利用兴趣点在空间上的聚集现象来提高推荐的准确性[8-11]。主流的地理位置建模方法有以下三类:幂律分布、高斯分布和核密度估计方法。其中:文献[8-9]认为用户签到的分布符合幂律分布,通过幂律分布获取用户签到的距离偏好; Liu等[10]将用户签到分布抽象为高斯分布,结合泊松因子模型进行协同过滤推荐; 与以上方法不同,文献[1,11]利用核密度估计方法从二维角度对用户签到记录进行建模,避免了对所有用户设置公共距离函数的局限性,因此可以获取个性化的地理位置偏好。
3)综合其他因素的推荐。
除了社交因素和地理位置因素,时间、兴趣点流行度等因素也会对用户的签到行为产生影响。其中,Gao等[12]提出的融合时间因素的位置推荐(Location Recommendation with Temporal effects, LRT)算法,按时间(T=24h)将用户兴趣点签到矩阵进行划分,使用矩阵分解方法获取用户签到的时间偏好。文献[13-14]认为兴趣点的流行度体现了兴趣点的服务质量,因此将流行度融入协同过滤算法中,结合社交因素和地理位置因素能够更好地完成推荐。
然而,之前的研究很少考虑用户好友影响力的传播属性,用户的2hop好友也会影响用户行为;同时,在挖掘地理位置特征时不够深入全面,如地点影响力的计算仅考虑兴趣点被签到频率。在推荐效率方面,算法缺乏简单有效的召回机制,推荐效率低。
本文在之前的研究基础上作出以下改进:首先,通过实验验证了用户2hop好友对用户签到行为的影响,并将用户2hop好友加入协同过滤算法的计算中,从而缓解数据稀疏问题,提高推荐的准确性;其次,在对社交网络分析的基础上,构造了地点影响力模型,通过随机游走(PageRank)算法获取用户影响力,并结合地点被签到的频率进一步挖掘地点影响力,深入全面地获取整体地理位置偏好;然后,使用核密度估计方法对个人签到记录进行建模,获取用户个性化的地理位置偏好;最后,综合社交因素和地理位置因素,提高推荐的准确性和个性化程度,并根据地点影响力排名和好友访问兴趣点集合生成推荐候选集,提升推荐效率。
2 问题描述和相关分析
2.1 问题描述
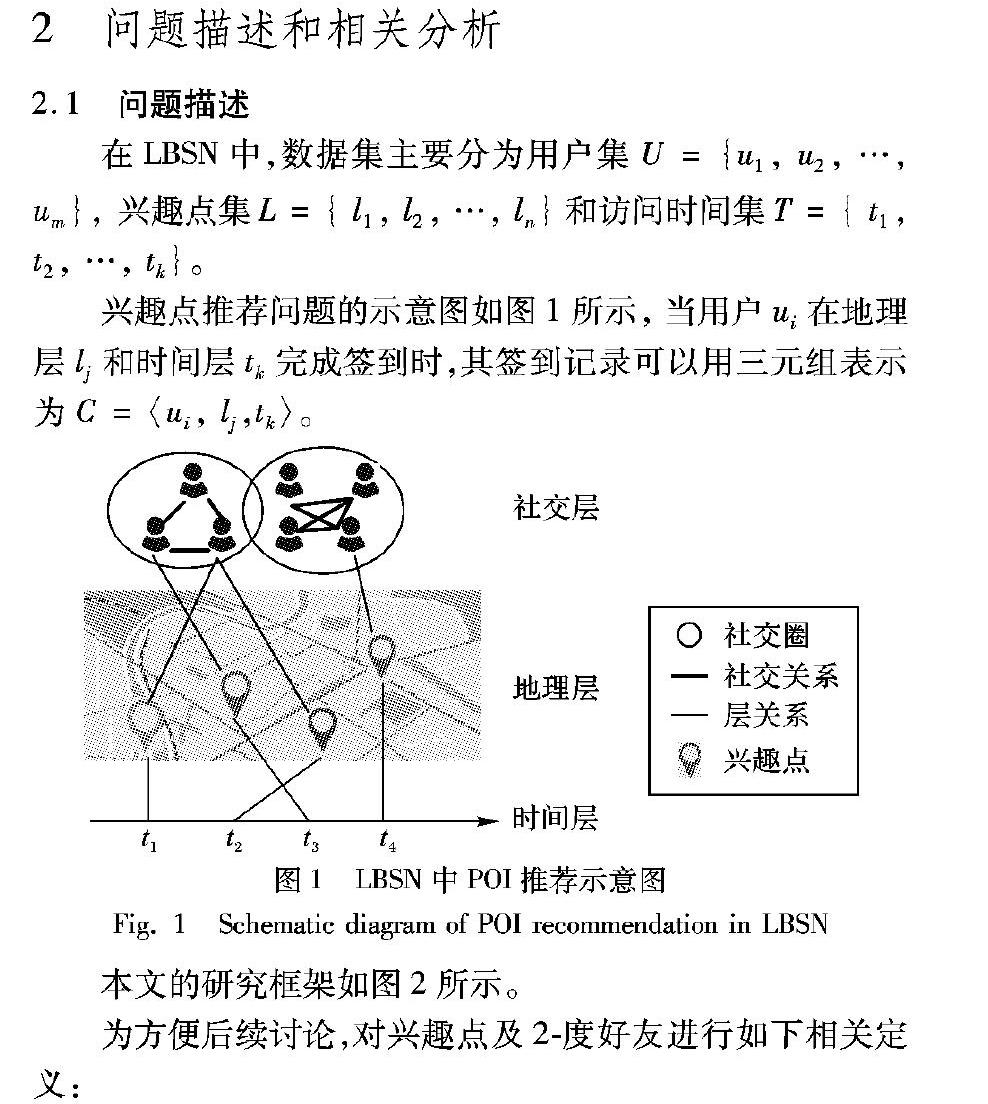
在LBSN中,数据集主要分为用户集U={u1, u2, …, um}, 兴趣点集L={ l1, l2, …, ln }和访问时间集T={ t1, t2, …, tk }。
兴趣点推荐问题的示意图如图1所示,当用户ui在地理层lj和时间层tk完成签到时,其签到记录可以用三元组表示为C=〈ui, lj,tk〉。
本文的研究框架如图2所示。
为方便后续讨论,对兴趣点及2度好友进行如下相关定义:
定义1 POI。POI是指在空间中能够唯一标识的地点(如某个餐厅或影院等)。兴趣点可以表示为〈id, (longitude, latitude)〉,其中id为唯一标识符,(longitude, latitude)为POI的经纬度。
定义2 2度好友。在LBSN中,用户之间的好友关系可以用网络图来表示,用户的直接好友和2hop好友构成了2度好友。
在图3的社交关系图,用户u2的直接好友集合{u1,u4,u7},2hop好友集合为{u3,u8},则用户u2的2度好友集合为F2={u1,u3,u4,u7,u8}。
社交关系的一个实例如图3所示。
在符号描述的基础上,本文给出兴趣点推荐的问题描述。
问题1 POI推荐。给定一个用户ui,其签到记录Ci,兴趣点推荐的目的是为该用户推荐N个可能访问但暂未访问的兴趣点。
2.2 好友影响分析
为验证好友具有相似的访问行为以及好友的影响力,通过实验分析用户好友及2度好友对用户签到行为的真实影响。以Gowalla数据集为例,按照4.1节描述划分训练集和测试集,根据式(1)计算用户签到行为的相似性。
p=∑ f∈Fi∑ ui∈UT(ui)∩Train(f)T(ui)(1)
其中:Fi代表用户ui的2度好友集合,T(ui)代表测试集中成功推荐的兴趣点集合,Train(f)代表训练集中用户2度好友签到历史兴趣点集合。探索用户直接好友影响时,将公式中Fi的替换为fi,实验结果如图4所示。
实验结果表明,在为用户成功推荐的POI中,有超过20%的POI是其直接好友访问过的,而超过60%的POI被其2度好友访问过。由此可以看出,用户的签到行为与其2度好友具有更广泛的相似性,且2度好友的签到行为会对用户产生传递的影响。因此,探索2度好友的社交影响可以缓解数据的稀疏问题,提高推荐准确率。
3 兴趣点推荐模型
本章通过构建社交影响模型、地点影响力模型和个性化地理位置模型来对POI的特征进行表示。给出推荐候选集的生成方法。最后,通过模型融合,从候选集中选取适当的POI对用户进行推荐。
3.1 社交影响模型
本文改进基于好友的协同过滤算法,分别计算用户与其2度好友的经历相似度和好友相似度,并结合用户历史签到记录计算用户访问兴趣点的概率。
本文扩大了基于好友的协同过滤算法相似度计算的用户范围,针对2度好友集合Fi,计算用户相似度,进一步计算访问概率,访问概率如式(2)所示:
ps(i, j)=∑ uk∈FiSIi,k·ck, j∑ uk∈FiSIi,k(2)
其中: Fi为用户ui的2度好友集合,ck, j为用户uk访问兴趣点lj 的状态,SIi,k代表用户ui和用户uk的社交影响因子。SIi,k可通过式(3)表示,其中SIEi,k代表用户ui和用户uk的经历相似度,SIFi,k代表用户ui和用户uk的好友相似度,参数α 表示影响权重。
SIi,k=(1-α)·SIEi,k+α·SIFi,k(3)
当α=1时,社交影响因子完全由好友相似度决定; 当α=0时,社交影响因子完全由经历相似度决定。经历相似度和好友相似度的计算可由式(4)和式(5)来表达。
用户ui和uk的经历相似度SIEi,k基于访问的共现现象,并根据余弦相似度进行计算:
SIEi,k=∑ lj∈Lci, j·ck, j∑ lj∈Lc2i, j·∑ lj∈Lc2k, j(4)
其中: ci, j和ck, j分别为ui和uk访问兴趣点lj的状态。当ui和uj共同访问的比例越大,它们的经历相似度越高。
好友相似度SIFi,k是基于用户ui和uk的共同好友比例进行计算:
SIFi,k=|Fi∩Fk||Fi∪Fk|(5)
其中:Fi和Fj分別为用户ui和用户uj的2度好友,共同好友比例越大,好友相似度越高。
3.2 地点影响力模型
兴趣点的影响力代表兴趣点的受欢迎程度,兴趣点被签到的次数越多影响力越大;然而,LBSN中各用户的影响力存在差异,不同用户的签到行为会产生不同影响,仅考虑POI被签到次数并不准确, 因此,本文构建了地点影响力模型,在获取用户影响力的基础上,全面深入地计算兴趣点的影响力。地点影响力模型的构建分为两步:用户影响力发现和地点影响力发现。
PageRank算法作为一种网页重要性排序算法,是根据网页之间相互链接关系判断网页重要性。该算法具有较高的时间效率,适合大型网络中判断节点的重要性,同样适用于社交网络中用户影响力分析[15],因此,本文使用PageRank算法对LBSN中各用户重要性排序并计算用户影响力。
用户ui的PageRank值PR(ui),如式(6)所示:
PR(ui)=β·∑ v∈fiPR(v)|F(v)|+1-βN(6)
其中:β为阻尼系数, fi表示用户ui的直接好友,N为LBSN中的用户数。
对所有用户的PageRank值排序后可得到用户ui的PageRank排名m,并使用式(7)计算用户ui的影响分数s(ui):
s(ui)=11+logm(7)
从式(7)中可看出,用户的排名越靠前,影响分数越高。在得到用户影响分数后,使用用户影响得分对POI被签到的次数进行加权,使用式(8)进一步计算地点的影响力:
p(lj)=∑ ui∈Us(ui)Nui,lj∑ ui∈Us(ui)Nui(8)
其中:Nui为用户ui访问POI的总次数,Nui,lj为用户ui访问兴趣点lj的次数,s(ui) 表示用户ui的影响分数,用户的影响分数越高,其签到行为对地点影响力的作用越大。
3.3 个性化地理位置模型
为提高推荐的个性化程度,本文使用核密度估计方法建立个性化地理位置模型[1,11],该方法仅从数据本身出发得到用户签到分布,具有推荐相对准确、富有个性化的特点。模型的建立分为三个步骤:距离样本数据的获取、距离分布的估计和个性化地理位置影响力的计算。
用户ui的距离样本数据D是通过计算该用户签入的每一对位置之间的距离来获取的。距离分布估计则依靠核函数和平滑参数完成。根据签到的位置之间的距离样本D,距离为d的分布:
f^(d)=1|D|h∑ d′∈DKd-d′h (9)
其中:K(·)为核函数;h是平滑参数,也被称为带宽或窗口。核函数选择最常用的高斯核函数K(x)=12πe-x22,根据经验[1,11],当选择高斯核核函数时,通过最小化分布的平均积分误差,平滑参数的最佳选择为h=453n15。
对于用户ui,其签到地点集合为Li={ l1, l2, …, lk},对于一个新的签到地点lj,按照式(10)计算每一对地点的距离:
dj,k=distance(lj,lk); lk∈Li(10)
根据式(10)计算每一对兴趣点距离为dj,k之后,根据式(9)分别计算核密度估计 f^(dj,k),用户ui访问新兴趣点lj的概率由每一对 f^(dj,k)共同决定:
pg(i, j)=1n∑n1f^(dj,k)(11)
3.4 模型融合
本节综合社交影响模型、地点影响力模型和个性化地理位置模型完成模型融合,并提出推荐候选集构造方法。根据2.2节的分析,用户访问的兴趣点大多数是其2度好友访问过的,因此利用2度好友访问记录可以快速缩小推荐范围。为增加推荐的范围和覆盖度,在构造候选集时加入高影响力的兴趣点集合。默认选取影响力排名前1%的兴趣点构造候选集,选取比例可根据实际情况调整,当选取比例达到100%时,算法对所有兴趣点访问得分,此时推荐范围最大,其推荐时间也最长。
对于用户ui和推荐候选集P中的兴趣点li∈P,最终的推荐分数由社交影响模型、地点影响力模型和个性化地理位置模型共同决定,其计算公式为:
Score(i, j)=ps(i, j)·p(j)·pg(i, j)(12)
算法的伪代码如算法1所示:
算法1 融合地点影响力的兴趣点推荐算法。
输入 用户集U,用户签到地点集L,用户好友集F;
输出 包含N个兴趣点组成的推荐列表。
程序前
1)
for li∈L each do
2)
由式(7)计算所有兴趣点的影响力P(lj);
3)
end for
4)
对兴趣点排序,选取流行度前1%的兴趣点作为部分推荐候选集Q;
5)
foreach ui∈U do
6)
获取其2度好友签到的兴趣点集合W;
7)
构造推荐候选集P=Q∪W
8)
end for
9)
for each ui∈U do
10)
for each li∈L do
11)
由式(1)计算社交影响ps(i, j);
12)
由式(10)计算地理位置影响pg(i, j);
13)
由式(11)计算最终推荐得分Score(i, j);
14)
end for
15)
根據Score(i, j)选取TopN个POI推荐给用户
16)
end for
程序后
与同类算法相比,本文提出的算法深入考虑了用户2度好友的社交影响,能够更加有效地缓解数据稀疏问题。通过融合地点影响力模型和个性化地理位置模型,深入全面地挖掘地理位置特征;同时,本算法增加了召回机制,通过构建推荐候选集可以大幅度提高推荐效率。
4 实验
4.1 数据集及实验环境描述
本文选择两个典型的LBSN平台Gowalla和Yelp上的真实签到数据集验证算法的有效性,数据集的统计信息如表2所示。
对于两个数据集分别按照时间顺序划分,选取80%作为训练集,剩余20%作为测试集。
实验运行在服务器上,硬件环境为:Intel Xeon CPU E52630 2.5GHz、128GB RAM和1.5TB硬盘。运行系统为ubuntu16.04,实验代码为python3。
4.2 评价指标
本文选用常用的准确率(Pricision)和召回率(Recall)进行TopN(N=5,10,20)来检验算法的有效性,其中N表示为每个用户推荐的兴趣点数量。
准确率和召回率的计算公式分别如式(13)、(14)所示:
Precision@N=∑ui∈U|R(ui)∩T(ui)|∑ui∈U|R(ui)|(13)
Recall@N=∑ui∈U|R(ui)∩T(ui)|∑ui∈U|T(ui)|(14)
其中: R(ui)表示为用户ui推荐的兴趣点列表;T(ui)表示在测试集上用户ui去过的兴趣点列表; |R(ui) ∩T(ui)|表示推荐给ui的并且被其真正访问的区域,其值越大表明推荐结果越准确。同时推荐准确率和召回率还受到推荐规模与实际访问规模的影响。
4.3 参数选择
在计算社交影响因子的式(3)中,参数α的取值决定了经历相似度和好友相似度的影响权重。在计算用户PageRank值的式(6)中,参数β的值决定了信息的转移概率和网络的收敛速度。在并未考虑地点影响力模型的情况下,在Gowalla数据集上选取不同的α的值进行Top5推荐,推荐结果如图5所示。可以看出,当α=0.1时,推荐效果最好,因此在之后的实验中设置α的值为0.1。
在设置的α的值为0.1的情况下,选取不同的β值进行Top5推荐,分别计算推荐的准确率和召回率,推荐结果如图6所示。可以看出,当β=0.4时,推荐效果最好,因此在之后的实验中设置β的值为0.4。
同样,在Yelp数据集上采用相同的方法确定实验的参数,当α=0.2和β=0.5时,推荐效果最好。对比两个数据集的参数可以发现,相比Gowalla数据集,Yelp数据集上好友的联系更加紧密,因此,用户的好友相似度对社交影响因子的作用更大,信息的影响概率也越大。
4.4 算法对比
为验证本文所提出算法的性能,选取了以下算法验证算法的有效性, 其中:融合地点影响力的兴趣点推荐算法(FriendGeo with Location effects,FGL)是本文提出的算法;F1GL是本算法仅考虑直接好友,不考虑2度好友影响的情况。 FGP是本算法在融合地点影响力时,不考虑用户影响力差异的情况,仅考虑了兴趣点被签到次数的情况。iGSLR和LRT算法分别为文献[11]和文献[12]所提出的算法,算法的具体描述如表3所示。
本文对各算法進行了实验对比,其中图7(a)和(b)分别表示各算法在Gowalla数据集上进行TOPN(N=5,10,20)情况下对应的准确率和召回率,图8(a)和(b)同样对应各算法在Yelp数据集上推荐的准确率和召回率。
可以看出,本文算法在两个数据集上准确率和召回率都高于其他算法。其中,LRT算法在这两个数据集上的表现最差,该算法将用户签到矩阵按时间(T=24)划分成多个矩阵,尽管有利于时间感知的POI推荐,但是该方法带来了数据稀疏问题,造成推荐的准确率低。实验结果表明,FGL算法的准确率和召回率都高于LRT算法和F1GL算法,这说明了融合社交因素可以增强用户的相似性提升推荐结果的可信度,同时考虑2度好友影响,体现了社交影响的传播属性,对推荐结果产生了积极作用。与iGSLR算法相比,FGP和FGL算法的准确率和召回率都有所提高,说明了地点影响力对POI推荐结果具有正面影响。对比FGL和FGP算法,也可以发现,在分析用户影响力的基础上进一步挖掘地点影响力,相比于仅使用POI被签到次数衡量地点影响力,可以更加准确地把握用户群体的兴趣特征以及访问规律。
为衡量算法的推荐效率,本文定义平均推荐时间为每位用户进行TopN(N=20)推荐的时间,包括查询和排序时间。其中,本文算法的推荐时间与候选集的构造相关,默认选取高影响力兴趣点比例为1%时,算法的平均推荐时间如表4所示,可以看出,构建推荐候选集可以极大地提高算法的推荐效率。
5 结语
本文提出一种融合地点影响力的兴趣点推荐算法,通过构造候选集提升推荐效率,并综合社交好友因素和地理位置因素完成推荐。通过引入2度好友影响解决数据稀疏问题,通过对地点影响力和个人地理位置建模,分别获取整体位置偏好和个人位置偏好,提高推荐的准确性和个性化。实验表明,该方法相对于其他算法兴趣点推荐算法准确率和召回率均有所提高且推荐效率更高。
参考文献 (References)
[1]YALI S, FUZHI Z, WENYUAN L. An adaptive pointofinterest recommendation method for locationbased social networks based on user activity and spatial features[J]. KnowledgeBased Systems, 2019, 163(1): 267-282.
[2]袁冠.移动对象轨迹数据挖掘方法[D].徐州:中国矿业大学,2012:1-7. (YUAN G. Research on the mining methods of trajectory data for moving objects[D]. Xuzhou: China University of Mining and Technology, 2012: 1-7.)
[3]袁冠,夏士雄,张磊,等.基于结构相似度的轨迹聚类算法[J].通信学报, 2011, 32(9):103-110. (YUAN G, XIA S X, ZHANG L, et al. Trajectory clustering algorithm based on structural similarity[J]. Journal on Communications, 2011, 32(9): 103-110.)
[4]ZHANG Z, LIU Y, ZHANG Z, et al. Fused matrix factorization with multitag, social and geographical influences for POI recommendation[J]. World Wide Web, 2019, 22(3): 1135-1150.
[15]張琛.社交网络用户影响力的评估算法研究[D].武汉:武汉邮电科学研究院, 2018:15-22. (ZHANG C. Research on evaluation algorithms of social network users influence[D]. Wuhan: Wuhan Research Institute of Posts and Telecommunications, 2018: 15-22.)
This work is partially supported by the National Natural Science Foundation of China (71774159), the China Postdoctoral Fund Project (2018M642358), the Think Tank of Green Safety Management and Policy Science (2018WHCC03).
XU Chao, born in 1996, M. S. candidate. His research interests include locationbased social network computing.
MENG Fanrong, born in 1962, Ph. D., professor. Her research interests include database, data mining.
YUAN Guan, born in 1982, Ph. D., associate professor. His research interests include spatiotemporal data mining.
LI Yuee, born in 1983, M. S. Her research interests include information management system.
LIU Xiao, born in 1994, M. S. candidate. His research interests include pattern recognition.
