基于云综合方法的三支群决策模型
2019-12-23李帅王国胤杨洁
李帅 王国胤 杨洁

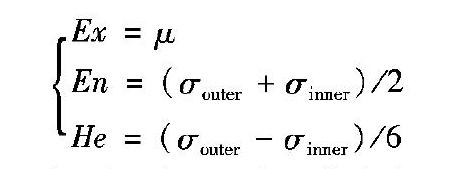
摘 要:在三支决策问题中,领域专家群决策是一种确定损失函数的最直接方法。相较于体现单一不确定性的语言变量模型和模糊集模型,云模型描述的专家评价更能够反映认知过程中复杂的不确定性形式,并能通过云综合的方法获得综合评价函数。但当前的云综合方法仅对数字特征进行简单的线性组合,缺乏对概念语义差异上的描述,难以获得令人信服的结果。因此首先证明了在云模型的距离空间中赋权距离和是一个凸函数,并将综合云模型定义为此函数的最小值点。然后,将该定义推广到多个云模型的场景下,提出了一种新的云综合方法——基于密度中心的云综合方法。群决策过程中,该方法在保证综合评价与基础评价之间的相似度最高的同时获得最精确的综合评价,为损失函数的确定提供了一种新的语义解释。实验结果表明,在与简单线性组合和合理粒度方法对比中,该方法所确定的损失函数使得三支决策中的误分类率最低。
关键词:云综合;云模型;群决策;三支决策
中图分类号:TP391.1;TP181
文献标志码:A
Threeway group decisions model based on cloud aggregation
LI Shuai1,2, WANG Guoyin1*, YANG Jie1
1.Chongqing Key Laboratory of Computational Intelligence(Chongqing University of Posts and Telecommunications), Chongqing 400065, China;
2.School of Mathematics and Information Science, Nanchang Hangkong University, Nanchang Jiangxi 330063, China
Abstract:
Group decision making of domain experts is the most direct approach to determine loss function in threeway decision problems. Different from linguistic variable model and fuzzy set model with single uncertainty, expert evaluations described by cloud model can reflect the complex uncertainty form in cognitive process, and the synthetic evaluation function can be obtained by cloud aggregation. However, numerical characteristics only are performed simple linear combination in current cloud aggregation methods, leading the lack of the description of concept semantic differences and the difficulty to obtain convincing results. Therefore firstly, the weighted distance sum was proved to be a convex function in the distance space of cloud model. And the aggregational cloud model was defined as the minimum point of that function. Then, this definition was generalized to the multicloud model scenario, and a cloud aggregation method namely density center based cloud aggregation method was proposed. In group decision making, the proposed method obtains the most accurate synthetic evaluations with the highest similarity between synthetic evaluation and basic evaluation, providing a novel semantic interpretation of the determination of loss function. The experimental results show that the misclassification rate of the threeway decision with loss function determined by the proposed method is the lowest compared with simple linear combination and rational granularity methods.
Key words:
cloud aggregation; cloud model; group decision making; threeway decisions
0 引言
在实际问题中,通常会遇到三支决策的问题。与一般的决策问题不同,它将结果分为接受、延迟和拒绝三种决策方案,被广泛地应用在垃圾邮件分类[1]、推荐系统[2]、风险投资[3-4]等领域。决策粗糙集作为Pawlak粗糙集的推廣形式为三支决策奠定了理论基础,借鉴了贝叶斯决策理论,通过引入损失函数,为三支决策提供了决策规则。损失函数的确定是三支决策过程的一个关键步骤,许多研究者在这方面做了大量的工作[5-8], 其中,最直接有效的方法就是由领域专家直接给出损失函数,但该过程中的不确定性又给决策带来了新问题。
第一个问题是如何量化或描述专家评价的不确定性。当前,处理知识的不确定性仍然是人工智能领域的一大挑战。不确定性是人类认知的固有属性,同时也是知识表达的一大障碍。这包含了两个原因:一是由于个人的阅历不同,对同样概念的理解不同;另一方面,由于思考的方式不同,对同一概念的表达方式不同。例如,当被问到“年轻人”这个概念时,20岁的小王认为18~25岁是年轻人,而34岁的小李则认为35岁以下是年轻人;反过来,当被问到谁是年轻人时,小李会说自己和小王,但小王可能只会说自己。这两个方面的认知过程分别体现为从外延到内涵的抽象和从内涵到外延的具象,并被合称为双向认知过程。从例子中可以看出,双向认知过程中的不确定性现象更为复杂。作为一种重要的认知计算模型,云模型[9-11]可以通过正向云变换(Forward Cloud Transformation, FCT)与逆向云变换(Backward Cloud Transformation, BCT)对双向认知过程中的不确定性进行描述,它不仅体现了人类认知过程中的随机性和模糊性,还反映了二者之间的联系,被广泛地应用在人工智能的各个领域[12-16]。
第二个问题是如何获得客观或有说服力的专家评价。专家基于领域的熟悉程度进行评价,受个人感官及心理素质影响较大,在实际应用中往往缺乏说服力。一般采用两种办法解决这一问题: 第一,使用语言变量或模糊集进行评价[17]。在基于语言变量的决策中,专家只需提供对对象的语言描述而不是一个精确数值,这让评价更贴近现实,便于操作。第二,对多个专家评价进行融合。使用逼近理想点排序法 (Technique for Order Preference by Similarity to an Ideal Solution, TOPSIS)、層次分析法(Analytic Hierarchy Process, AHP)以及聚合函数等方法对专家的评价进行融合。由于语言变量只能描述评价中的模糊性,不能描述随机性。因此,文献[17-18]将语言评价模型转化为云模型进行决策。云模型可以方便地实现双向认知过程,并通过双向云变换反映这一过程的随机性和模糊性。在基于云模型的群决策中,云综合是融合专家知识的关键步骤,但当前的云综合普遍缺乏具体的意义。在群决策中,一方面我们希望得到的综合评价是所有基础评价中的一种“折中”方案,即综合评价到所有基础评价的加权距离和最小;另一方面,从粒认知计算的角度来看,群决策又是一个数据粒化的过程。按照合理粒化特异性(specificity)原则[19],希望得到的综合评价越精确越好。因此,需要设计一种满足上述需求的融合方法。
本文在云模型表达的专家评价基础之上,从概念的相似性度量出发,通过最小化综合评价与基本评价之间的赋权距离,定义了一种新的云综合方法——基于密度中心的云综合方法。该方法在通过优化目标函数保证综合评价与基本评价之间的相似度最高的同时,使得综合评价最精确,并为损失函数提供了一种新的语义解释。实验证明,该方法所确定的损失函数在三支决策中能得到更好的效果。
1 相关工作
1.1 决策粗糙集
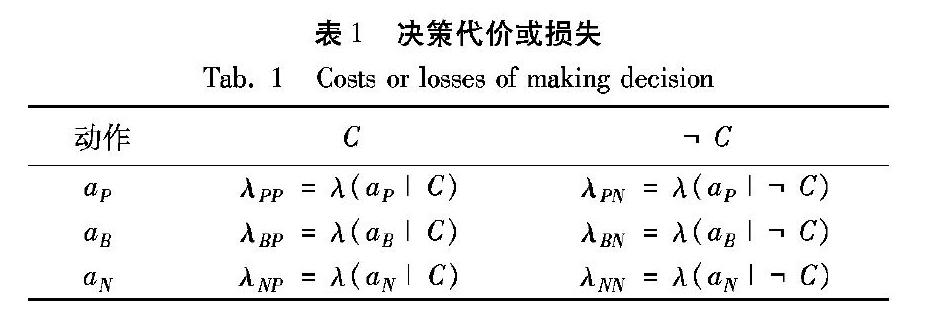
首先简要介绍决策粗糙集。针对经典决策粗糙集模型缺乏容错能力的问题,Yao[20-22]结合贝叶斯决策理论[23]和Pawlak粗糙集建立了基于决策粗糙集的三支决策模型。从粗糙集角度上看,模型由状态集和决策动作集组成, 其中,状态集Ω={C,C}表示对象属于集合C或不属于集合C;决策动作集A={aP,aB,aN}分别表示将目标对象x分类到正域POS(C)、边界域BND(C)和负域NEG(C)的决策动作。在三支决策理论中,也将这三种决策动作分别称为接受、延迟和拒绝[22,24-25]。从贝叶斯决策角度上看,对于不同状态进行不同决策动作会带来6种相应的决策代价或损失,如表1所示。
表1中λPP,λBP,λNP分别表示目标概念C中对象采取aP,aB,aN三种决策动作产生的决策代价或损失;λPN,λBN,λNN分别表示目标概念C以外的对象采取aP,aB,aN三种决策动作产生的决策代价或损失。6个决策代价或损失满足下列不等式:
λPP≤λBP<λNP(1)
λNN≤λBN<λPN(2)
式(1)表示对一个属于目标概念C的对象x作出接受决策的损失小于或等于对其作出延迟决策的损失,而这两种损失又小于对其作出拒绝的损失;反之,式(2)表示对不属于目标概念的对象x作出拒绝决策的损失小于等于对其作出延迟决策的损失,而这两种损失又小于对其作出接受决策的损失。
条件概率Pr(C|[x])定义为将对象x划分到目标概念C的概率,[x]表示对象x所属等价类。对对象x作出不同决策动作所产生的损失表示如下:
R(aP|[x])=λPPPr(C|[x])+
λPNPr(C|[x])
R(aB|[x])=λBPPr(C|[x])+
λBNPr(C|[x])
R(aN|[x])=λNPPr(C|[x])+
λNNPr(C|[x])(3)
Yao[22,24]依据贝叶斯决策理论中的风险最小规则,比较式(3)中三种决策的损失,对对象x作出损失最小的决策:
(P) 若R(aP|[x])≤R(aB|[x])且R(aP|[x])≤R(aN|[x]),则作出接受决策,即x∈POS(C);
(B) 若R(aB|[x])≤R(aP|[x])且R(aB|[x])≤R(aN|[x]),则作出延迟决策,即x∈BND(C);
(N) 若R(aN|[x])≤R(aP|[x])且R(aN|[x])≤R(aB|[x]),则作出拒绝决策,即x∈NEG(C)。
上述(P)~(N)的决策规则被称为正规则、边界规则和负规则,分别作为对对象x接受、延迟和拒绝的判断标准。因为Pr(C|[x])+Pr(C|[x])=1,可以将上述决策规则中的Pr(C|[x])用1-Pr(C|[x])代换,决策规则(P)~(N)可以改写成如下形式:
(P′) 若Pr(C|[x])≥α且Pr(C|[x])≥γ,则作出接受决策,即x∈POS(C);
(B′) 若Pr(C|[x])≤α且Pr(C|[x])≤β,则作出延迟决策,即x∈BND(C);
(N′) 若Pr(C|[x])≤β且Pr(C|[x])≤γ,则作出拒绝决策,即x∈NEG(C)。
以上决策中,阈值α、 β和γ值定义如下:
α=λPN-λBN(λPN-λBN)+(λBP-λPP)
β=λBN-λNN(λBN-λNN)+(λNP-λBP)
γ=λPN-λNN(λPN-λNN)+(λNP-λPP)(4)
决策规则(P′)~(N′)将决策规则(P)~(N)中的对决策损失间的比较转化为条件概率值Pr(C|[x])与阈值(α, β,γ)间的比较,将贝叶斯决策模型转化为概率粗糙集模型。
1.2 云模型
定义1[9]设定性概念C为定量论域U上的概念,若x∈U为概念C的一次随机实现,x对C的确定度μ∈[0,1]为有稳定分布的随机数:
μ(x):U→[0,1];x∈U
则x在论域U上的分布成为云模型。定量数值x体现表示概念的定量值的随机性,μ(x)反映定量数值x隶属于定性概念C的确定程度。
上述定义中,云模型的隶屬度函数μ(x)不仅描述了概念的模糊性,而且将隶属度函数μ(x)定义为具有稳定分布的随机数。将概念内涵的模糊性和外延的随机性有机地结合起来。下面,给出正态云模型的定义:
定义2[9]设定性概念C为定量论域U上的概念,C包含3个数字特征(Ex,En,He),若x∈U为概念C的一次随机实现,x对C的确定度μ∈[0,1]为有稳定分布的随机数:
μ(x):U→[0,1],x∈U
满足:
x~RN(Ex,|y|)
y~RN(En,He)
且隶属度函数满足指数形式:
μ(x)=exp-(x-Ex)22y2
那么所有云滴构成的随机变量X的分布成为正态云模型。
正态云模型与正态分布之间有着紧密的联系[26]。当超熵He=0时,正态云模型退化为正态分布,称为云模型的期望曲线:
y=exp-(x-Ex)22En2
0 y1=exp-(x-Ex)22(En+3He)2 y2=exp-(x-Ex)22(En-3He)2 之间,且当正态云模型的特征参数发生变化时,包络曲线始终存在; 因此,可以用包络曲线刻画云模型的分布特征。由于正态分布的普遍性,本文仅讨论正态云模型。图1展示了正态云模型的形状、三条特征曲线以及雾化情形。 2 针对群决策的云模型粒化机制 粒认知计算认为,人类是从不同侧面和层次对客观世界进行表示、理解和分析。为实现这一过程,研究者提出了模糊集、粗糙集、商空间[28]、区间集和云模型等一系列的粒计算模型。目前,粒计算的思想已经存在于人工智能的各领域的研究中,在此基础上,Yao将粒计算总结为一种哲学、方法和认知的统一机制[29]。 2.1 云模型的粒化机制 云模型对原始数据粒化的优势表现在对定性概念的描述中,同时保留了随机和模糊这两种不确定性。此外,正向和逆向云算法还实现了知识内涵和外延的双向认知。云模型的粒化机制包括自适应高斯云变换[30]和云综合[31],自适应高斯云变换是基于概念的稳定性,将低粒度层若干个不稳定的云模型合并成一个粗粒度层上较为稳定的云模型。从粒认知计算的角度来看,群决策也是一种粒化手段,它将若干离散的基础评价转换为一个综合评价,在基于云模型的评价方法中,通常通过云综合的方式实现这一过程。 云综合是基于概念内涵,将细粒度层若干个云模型综合成一个粗粒度层的云模型的过程,其中低粒度层上的云概念称为基础云,综合后的云概念称为综合云。“软或云”“积分云”和“幅度云”综合方法在图像分割、检索以及协同过滤等方面取得了很好的效果。这些方法往往从统计特征、几何特性和不确定性等方面考虑对云模型进行综合, 但对于结果(特别是综合云超熵He)的形成往往缺乏理论解释。 当前,在群决策中,云综合方法通常被定义为概念内涵的线性组合形式。 定义3[17]设两个云模型C1(Ex1,En1,He1)和C2(Ex2,En2,He2),则对于任意λ∈R,云模型的线性运算如下: C1+C2=(Ex1+Ex2,En12+En22,He12+He22) C1-C2=(Ex1-Ex2,En12+En22,He12+He22) λC1=(λEx1,λEn1,λHe1) 从上述定义可以看出,综合云的数学期望是基础云数学期望的线性组合。 此外,自适应高斯云变换可以实现低粒度层概念向高粒度层概念转换,本质上来说,也是将相近的概念进行综合,形成更为笼统的概念; 但在具体的应用背景下,二者都缺乏针对性。因此,需要设计一种既有理论依据又能够符合群决策语义的云模型粒化机制。 2.2 概念漂移引导的云综合方法 大部分的决策融合都采用加权求和的方式,它蕴含了一种“折中”的决策语义,即找出一种与所有基础评价都接近的评价作为融合结果。然而,这种语义接近程度往往要通过特殊的度量形式来表达。在群决策中,云综合方法不应是数字特征的简单线性组合,而应充分体现这种“折中”的语义。用云模型表示概念时,语义的接近程度通常用相似性度量进行描述。当前,存在许多云模型的相似性度量方法,这些方法大致可以分为两类:一类是基于云滴随机分布来计算相似性度量[32],这类方法度量云模型的相似性上,体现了云模型的不确定性,但是计算过程依赖于云滴的数量和采样次数,结果不稳定; 另一类方法是基于云模型的数字特征[33]或特征曲线[34-35]计算云模型相似度,稳定性较强,时間复杂度低。此外,许昌林等[36]从相似性的反面入手,提出漂移性度量概念,通过计算两个云模型最大外包络曲线的KL散度(KullbackLeibler divergence)定义云模型的概念漂移度。由于KL散度可以很好地刻画分布间的差异性,因此,该方法计算的云模型相似度更具有普遍性。 定义4[36]设U是用精确数值表示的定量论域,C1(Ex1,En1,He1)和C2(Ex2,En2,He2)是U上的两个正态云模型,那么C1和C2的外包络曲线分别为: μ1=exp-(x-Ex1)22(En1+3He1)2 μ2=exp-(x-Ex2)22(En2+3He2)2 外包络曲线对应的分布函数为: p(x)=12πEn1exp-(x-Ex1)22(En1+3He1)2 q(x)=12πEn2exp-(x-Ex2)22(En2+3He2)2 则基于对称KL散度的云模型漂移性度量为: DJ(C1‖C2)=DKL(C1‖C2)+DKL(C2‖C1)= 12[(Ex1-Ex2)2+σ21+σ22]1σ21+1σ22-2 其中σ1=En1+3He1,σ2=En2+3He2。 从定义中可以看出,概念的漂移性度量是用云模型的外包络曲线所对应的正态分布函数进行计算,从形式上来说,概念的漂移性度量就是一个关于正态分布的KL散度度量。根据上文的分析,按照群决策中的“折中”语义内涵,对基础云模型融合的过程就是在概念漂移度量空间中寻找一个云模型,使得该云模型到两个基础云模型的概念漂移性之和最小,形式化定义如下: 定义5 设U是用精确数值表示的定量论域,C1(Ex1,En1,He1)和C2(Ex2,En2,He2)是U上的两个基础云概念,若M满足: M=argmin[D(C‖C1)+D(C‖C2)] 则M是基础云C1与C2基于漂移性度量D的综合云模型。 如上述分析,若用对称KL散度作为漂移性度量,则问题转化为关于一个关于正态分布的优化问题。下面的定理保证了这个优化问题有全局最优解。 定理1 设N1(μ1,σ21)和N2(μ2,σ22)是正态分布函数,则存在唯一的正态分布N0(μ0,σ20),使得目标函数 G(N)=KL(N‖N1)+KL(N‖N2)(5) 取得最小值,KL(·)表示对称KL散度。 证明 设正态分布N(x,y2),定义函数f(x,y2)为N到N1的对称KL散度距离KL(N‖N1)。 f(x,y2)=KL(N‖N1)= 12[(x-μ)2+(y2+σ2)]1y2+1σ2-2 对x和y2求偏导数: fx=(x-μ)1y2+1σ2 fy2=12σ2-12y4[(x-μ)2+σ2] f(x,y2)的Hessian矩阵满足 H(f)=1y2+1σ2-1y4(x-μ)-1y4(x-μ)1y6[(x-μ)2+σ2]= 1y6σ2y2+(x-μ)2σ2+1>0 则f(x,y2)=KL(N‖N1)在定义域内是凸函数; 同理KL(N‖N2)也是凸函数。由于凸函数的和函数仍是凸函数,所以目标函数G(N)是凸函数,有全局最小值。 求目标函数(5)的最小值,只需求目标函数的梯度为0的值,即求解下列方程组: (x-μ1)1y2+1σ21+(x-μ2)1y2+1σ22=01σ21+1σ22-1y6[(x-μ1)2+ (x-μ2)2+σ21+σ22]=0 (6) 可以看出,上述方程组解无解析形式,并且σ1和σ2比较小时y的方向导数非常大,用梯度下降法求解很难搜索到最优解,因此采用牛顿法搜索最优解。可以看到定理1是关于正态分布的优化问题,无法直接用于求解云模型。 在云模型的3个数字特征中,期望Ex代表概念中最具代表性或最典型样本, 熵En定性概念一种不确定性度量, 超熵He描述的是熵En的不确定性。相应地,云模型的期望曲线表达了最具代表性的概念隶属度;内包络曲线和外包络曲线则分别描述了最严谨的概念隶属度和最宽泛的概念隶属度。三条特征曲线描述了概念的完整信息,因此本文分别针对三条特征曲线求式(5)的最优解,以此来定义综合云模型。 定义6 设U是用精确数值表示的定量论域,C1和C2是U上的两个基础云概念。若正态分布N(μ,σ2)、N1(μ1,σ21)和N2(μ2,σ22)分别是C1和C2的期望曲线、外包络曲线和内包络曲线对应的正态分布关于式(5)的最优解,则C1和C2基于对称KL散度形成的综合云模型M(Ex,En,He)满足: Ex=μ En=(σ1+σ2)/2 He=(σ1-σ2)/6 由定义6可知,在对称KL定义的云模型漂移性度量空间中,基础云模型的期望曲线反映了概念隶属度函数的平均值,因此用这一特征曲线确定综合概念的平均隶属度;基础云模型外包络曲线和内包络曲线反映了概念的最大隶属度函数和最小隶属度函数,二者分别描述了综合云模型表达的最乐观评价和最悲观评价。因此,用它们来确定综合云模型的不确定性——熵En和超熵He。 尽管定义6的形式复杂,但对于一些特殊的基础云模型,可以求出综合云模型的解析表达形式。 定理2 设U是用精确数值表示的定量论域,C1(Ex1,En1,He1)和C2(Ex2,En2,He2)是U上的两个基础云概念,满足Ex1=Ex2=μ,若M(Ex,En,He)是基础云C1与C2基于对称KL散度形成的综合云模型,那么M滿足: Ex=μEn=En1En2+He1He2He=(En1He2+En2He1)/3 证明 由于Ex1=Ex2=μ,方程组(6)化简为: (x-μ)2y2+1σ12+1σ22=01σ12+1σ22-1y4(σ12+σ22)=0 解得: x=μ y=σ1σ2。 分别将基础云模型的三条特征曲线代入,由定义6可得综合云M(Ex,En,He)。 如图2中实心和空心散点图分别表示基础云模型C1(50,10,2)和C2(10,3,0.5),三角形和星型的散点图分别表示由定义3和定义6方法得到的综合云模型。表2是两种综合方法的比较。可以看出定义6得到的综合云与基础云模型的距离比定义3的要小,这说明综合评价与基础的评价间的概念漂移小,兼顾了基础云概念。此外,通过对比可以看到,定义6方法得到的综合云模型位置靠近更加清晰的概念(C2(10,3,0.5)),说明越清晰的概念对综合云模型的贡献越大,这一过程也符合人类认知。 2.3 基于密度中心的云综合方法 在群决策过程中,不同决策者所做决策结果的重要程度不尽相同, 这与决策者业务水平、心理状态以及对决策领域熟悉程度等因素密切相关。因此,通常对于决策者的决策结果赋予权重。对于云综合方法来说,这就需要在目标函数中考虑各基础云模型所对应的权重。由于定理1证明了两个正态分布的对称KL散度距离是关于期望和方差的凸函数,因此,它们的凸组合仍然是凸函数。于是有下面推论: 推论1 设正态分布簇A={N1(μ1,σ12)i=1,2,…,n},其对应的权重集合W={ωii=1,2,…,n},则存在唯一的正态分布N(μ0,σ02),使得目标函数: G(A)=∑ni=1ωi KL(N‖Ni)(7) 取得最小值,KL(·)表示对称KL散度。 从粒认知计算的角度来看,群决策又是一个数据粒化的过程。按照合理粒化的特异性原则[19],综合云应该越精确越好,因此,在优化过程中,对云模型的不确定性设定范围。从上面的分析可以看到,云模型的内外包络曲线分别是云模型不确定的上下界,因此,需要考虑基础云在内外包络曲线间变化时,综合云模性不确定性的变化范围。相较于定义6,受不同权重的影响,带先验信息的云综合方法更为复杂。将基础云的外包络曲线代入式(7),并不能得到综合云的最大不确定性; 同理,基础云的内包络曲线代入式(7),也不能得到最小不确定性。因此,需要在各基础云模型的内外包络曲线间找到一组合适的正态分布曲线,使综合云的内外包络曲线分别取到最小和最大值。设云模型簇C={Ci(Exi,Eni,Hei)i=1,2,…,n},正态分布簇A={Ni(Exi,(Eni+3θiHei)2)θi∈[-1,1],i=1,2,…,n},则综合云模型的内外包络曲线的方差分别满足下列优化问题: σouter= max(argminσ∑ni=1ωi KL(N(μ,σ2)| Ni(Exi,(Eni+3θiHei)2)))(8) s.t.θi∈[-1,1] σinner= min(argminσ∑ni=1ωi KL(N(μ,σ2)| Ni(Exi,(Eni+3θiHei)2)))(9) s.t.θi∈[-1,1] 式(8)、(9)是多变量最优化问题,即在自变量θi的定义域内找到一组θi,在满足式(7)最小的所有σ中,找到最大的σ作为综合云模型的外包络曲线所对应正态分布的方差σouter;在满足式(7)最小的所有σ中,找到最小的σ作为综合云模型的内包络曲线所对应正态分布的方差σinner。式(8)、(9)中的优化目标无法用显式函数表示,为解决这一问题,本文采用粒子群优化(Particle Swarm Optimization, PSO)算法求最优解。下面给出带先验信息的云综合定义。 定义7 设U是用精确数值表示的定量论域,C={Ci(Exi,Eni,Hei)i=1,2,…,n}是U上的n个基础云概念,其对应的权重集合W={ωii=1,2,…,n}。若N(μ,σ2)是云模型簇C期望曲线对应的正态分布关于式(7)的最优解,Nouter(μouter,σ2outer)和Ninner(μinner,σ2inner)是云模型簇C关于式(8)和式(9)的最优解,则云模型簇C基于对称KL散度形成的综合云模型M(Ex,En,He)满足: Ex=μ En=(σouter+σinner)/2 He=(σouter-σinner)/6 相对于定义3的云综合方法,定义7除了给出了综合云方法的语义解释,还给出了概念的漂移性度量空间中的几何解释,即在概念的漂移性度量空间中,综合评价到各基础评价距离的赋权和最小,如果将权重看成质点的质量,则综合云模型就是所有基础云模型的密度中心。因此,定义7被称为基于密度中心的云综合方法。此外,定义7还最大化了综合云模型的内外包络曲线的差异,满足合理粒化中特异性原则,综合云模型最精确。 3 基于云综合的三支群决策 如第1章所述,确定6个代价函数是三支决策中的关键步骤。一般来说,代价函数由领域专家凭经验主观给定。为了使得该结果更加客观,采用群决策的方案给出代价函数。然而,由于决策环境中的不确定性以及人类认知的主观不确定性,决策者往往很难给出一个精确的实值评价,于是,许多研究者围绕损失函数的不确定评价形式,以三角模糊数、区间数[37-39]、语言变量[40]等不确定模型对其开展研究。云模型能够很好地刻画人类认知过程中的模糊性和随机性,并能反映二者之间的联系,能够方便地实现知识内涵与外延之间的转换。作为一种重要的认知计算模型,文献[18]将其引入三支群决策,对损失函数的不确定性进行描述,并对数字特征进行简单的加权平均得到综合云模型,确定全局损失函数。这种综合云忽略了云模型相似性度量与综合方法的内在联系,在决策过程中缺乏说服力。本文将采取基于密度中心的云综合方法确定损失函数。 3.1 决策过程 如图3三支群决策过程主要分为公式化决策问题和决策分析两个部分,具体分为以下5个步骤: 步骤1 根据具体的决策问题背景,确定评估专家以及他们对应的权重。专家集为E={e1,e2,…,et},权重集为W={ω1,ω2,…,ωt}T。 步骤2 所有专家按照表1的形式对所有损失函数作出评价,并用云模型表示,记为:λkPP(ExkPP,EnkPP,HekPP)、λkBP(ExkBP,EnkBP,HekBP)、λkNP(ExkNP,EnkNP,HekNP)、λkPN(ExkPN,EnkPN,HekPN)、λkBN(ExkBN,EnkBN,HekBN)和λkNN(ExkNN,EnkNN,HekNN),其中1≤k≤t。 步骤3 为减少专家意见的不一致性,将云模型所表示的损失函数按照定义7进行综合,得到损失函数的综合评价云模型。 步骤4 考虑到云模型的期望反映了最典型的概念外延,因此,将损失函数的综合评价云模型的期望代入式(4),求出三支决策的各项阈值α、 β和γ。 步骤5 根据(P′)~(N′)的决策规则,对对象作出决策。 3.2 应用案例 为了更好地说明基于云模型的三支群决策过程,本节采用文献[38]中战略供应商的选择问题对这一过程进行详细介绍。供应管理是制造企业的关键问题之一,直接影响到生产的准时性。在风险环境下,选择合适供应商会考虑一些可能决策结果中存在的损失。为了客观地评价战略供应商,需要邀请多个专家进行群决策。真实的决策中,对供应商除了选择和非选择的决策外,还加入了延迟,这非常符合三支群决策的应用场景。 步骤1 为了作出合理的决策,请相关专家对损失函数进行评估。专家集为E={e1,e2,…,e11},对应的权重集W={ω1,ω2,…,ω11}T={0.05,0.05,0.05,0.05,0.05,0.05,0.1,0.1,0.1,0.2,0.2}T。 步骤2 将所有专家对损失函数作出的不确定性评价转换为云模型,如表3。 步骤3 为消除不一致性,将表3中云模型表示的损失函数按定义7进行综合,得到损失函数的综合评价云模型,如表4。 步骤4 将损失函数的综合评价云模型的期望代入式(4),求得α=0.611-8, β=0.243-5,γ=0.417-3。 步骤5 对决策问题给出判断标准: (P′) 若Pr(C|[x])≥0.611-8,则作出接受决策,即x∈POS(C); (B′) 若Pr(C|[x])≤0.611-8且Pr(C|[x])≥0.243-5,则作出延迟决策,即x∈BND(C); (N′) 若Pr(C|[x])≤0.243-5,则作出拒绝决策,即x∈NEG(C)。 4 实验分析 为了验证本文方法的有效性,对专家在6个损失函数上的评价,分别用定义3和定义6计算综合云模型,并且比较二者与基础云模型的赋权距离(表5)和以及综合云的不确定性(表6)。赋权距离指的是综合云到各基础云距离的加权和,云模型的不确定性定义为熵和超熵的平方和:En2+He2。从表中可以看出,本文方法在赋权距离上都要小于定义3的方法,另外,得到的综合云模型也更为精确。 群决策的问题中,对不一致信息表的决策反映了群决策的效果。为了验证方法的有效性,本文比较本文所提的群决策方法和基于定义3群决策方法在不一致信息表上决策的效果。效果的优劣由错误率判断,错误率[38]的定义如下: e=nC→NEG(C)+nC→NEG(C)Q×100% 其中:Q是信息表中所有对象个数,C→NEG(C)是概念C中的元素被分类到NEG(C)的情况,即拒绝真实对象的情况,nC→NEG(C)表示这一现象的对象个数。C→POS(C)是非概念C中的元素被分类到POS(C)的情況,即取到非真实对象的情况,nC→NEG(C)表示这一现象的对象个数。错误率e越小说明决策效果越好。 为了验证结果,本文选取了6个UCI上的数据集进行群三支决策。因为这6个数据集(表7)是一致性的信息表,并且是多标签数据,所以,需要删除一些属性使之不一致,合并一些标签使之成为三支决策问题。这一过程具体描述如表8。 表格(有表名) 对于每一个数据集,本文将其平均划分成5个等份,连续合并成5个数据集,并在每个数据集上计算错误率。为了评价群决策方法的好坏,事实上只需要比较两种云综合方法在融合损失函数时的差异。方便起见,本文仍使用表3作为专家给出的损失函数评价矩阵,权重集仍为W={ω1,ω2,…,ω11}T={0.05,0.05,0.05,0.05,0.05,0.05,0.1,0.1,0.1,0.2,0.2}T。 从定义3中可以看出,基于此方法的群决策只是将概念的内涵進行简单的线性组合,并没有反映出概念与概念之间的联系。而本文方法以概念的相似度为目标函数,用最优化的方法求出基础云模型的密度中心,使综合云到各基础云之间的距离加权最小。这一过程保持了基础云之间的相似性特征,在错误率上的表现优于之前的综合方法。 图4中原始方法1是指基于定义3的三支群决策。为了说明本文方法的优势,除了使用云综合确定损失函数外,本文还与文献[38]中合理粒度方法进行比较(原始方法2)。可以看到,本文方法的错误率并不是在每一个数据集上都比原始方法低,但就整体而言,本方法的效果要优于原始方法,这说明在三支群决策中基于密度中心的云综合方法比之前方法更加有效。 5 结语 本文在决策粗糙集模型的三支决策基础之上,考虑了群决策模型来确定损失函数。利用云模型能充分刻画认知过程中复杂不确定形式的优势,将多个专家评价信息转化为云模型,并借鉴合理粒化思想,提出了一种云综合方法。该方法以云模型相似性度量为基础,通过优化综合评价结果与各专家评价信息间语义的近似程度,来获得综合评价结果。该方法成功地解决了群决策中的信息聚合问题。此外,相较于一般的云综合方法,该方法提供了一种新的语义解释。通过应用案例和实验分析,验证了该方法的有效性。值得注意的是,本方法中的云模型相似性度量可以具有多种形式,今后的工作中,将借鉴机器学习的方法,研究不同形式的相似性度量对群决策的影响。 参考文献 (References) [1]JIA X, ZHENG K, LI W, et al. Threeway decisions solution to filter spam email: an empirical study[C]// Proceedings of the 8th International Conference on Rough Sets and Current Trends in Computing. Heidelberg: Springer, 2012: 287-296. [2]ZHANG H, MIN F. Threeway recommender systems based on random forests[J]. KnowledgeBased Systems, 2015, 91(C):275-286. [3]LIANG D, LIU D. A novel risk decisionmaking based on decisiontheoretic rough sets under hesitant fuzzy information[J]. IEEE Transactions on Fuzzy Systems, 2015, 23(2):237-247. [4]LIU D, YAO Y, LI T. Threeway investment decisions with decisiontheoretic rough sets[J]. International Journal of Computational Intelligence Systems, 2011, 4(1):66-74. [5]LIANG D, LIU D, PEDRYCZ W, et al. Triangular fuzzy decisiontheoretic rough sets[J]. International Journal of Approximate Reasoning, 2013, 54(8):1087-1106. [6]SUN B, MA W. Rough approximation of a preference relation by multidecision dominance for a multiAgent conflict analysis problem[J]. Information Sciences, 2015, 315: 39-53. [7]XU Z. An automatic approach to reaching consensus in multiple attribute group decision making[J]. Computers & Industrial Engineering, 2009, 56(4):1369-1374. [8]YANG X, YAO J. Modelling multiAgent threeway decisions with decisiontheoretic rough sets[J]. Fundamenta Informaticae, 2012, 115(2/3): 157-171. [9]李德毅,孟海军,史雪梅. 隶属云和隶属云发生器[J]. 计算机研究与发展, 1995, 32(3):15-20. (LI D Y, MENG H J, SHI X M. Membership clouds and membership cloud generators[J]. Journal of Computer Research and Development, 1995, 32(3):15-20.) [10]LI D, CHEUNG D, SHI X M, el al. Uncertainty reasoning based on cloud models in controllers[J]. Computers and Mathematics with Applications, 1998, 35(8): 99-123. [11]李德毅,杜鹢. 不确定性人工智能[M]. 北京:国防工业出版社, 2005: 50-75. (LI D Y, DU Y. Artificial Intelligence with Uncertainty[M]. Beijing: National Defense Industry Press, 2005:50-75.) [12]BUDANITSKY A, HIRST G. Evaluating WordNetbased measures of lexical semantic relatedness[J]. Computational Linguistics, 2006, 32(1): 13-47. [13]NGUYEN H A, AlMUBAID H. New ontologybased semantic similarity measure for the biomedical domain[C]// Proceedings of the 2006 IEEE International Conference on Granular Computing. Piscataway: IEEE, 2006: 623-628. [14]SIM K M, WONG P T. Toward agency and ontology for Webbased information retrieval[J]. IEEE Transactions on Systems, Man and Cybernetics, Part C: Applications and Reviews, 2004, 34(3): 257-269. [15]RUS V, NIRAULA N, BANJADE R. Similarity measures based on latent Dirichlet allocation[C]// Proceedings of the 14th International Conference on Computational Linguistics and Intelligent Text Processing. Berlin: SpringerVerlag, 2013: 459-470. [16]LAZA R, PAVON R, REBOIROJATO M, et al. Assessing the suitability of MeSH ontology for classifying Medline documents[C]// Proceedings of the 5th International Conference on Practical Applications of Computational Biology & Bioinformatics. Berlin: SpringerVerlag, 2011: 337-344. [17]WANG J, PENG L, ZHANG H, et al. Method of multicriteria group decisionmaking based on cloud aggregation operators with linguistic information[J]. Information Sciences, 2014, 274:177-191. [18]HU J, YANG Y, CHEN X. Threeway linguistic group decisions model based on cloud for medical care product investment[J]. Journal of Intelligent and Fuzzy Systems, 2017, 33(6):3405-3417. [19]PEDRYCZ W. Allocation of information granularity in optimization and decisionmaking models: towards building the foundations of granular computing[J]. European Journal of Operational Research, 2014, 232(1):137-145. [20]YAO Y Y. Decisiontheoretic rough set models[C]// Proceedings of the 2nd International Conference on Rough Sets and Knowledge Technology. Berlin: SpringerVerlag, 2007: 1-12. [21]YAO Y Y, WONG S K M. A decision theoretic framework for approximating concepts[J]. International Journal of ManMachine Studies, 1992, 37(6): 793-809. [22]YAO Y. Threeway decisions with probabilistic rough sets [J]. Information Sciences, 2010, 180: 341–353. [23]DUDA R O, HART P E. Pattern Classification and Scene Analysis[M]. New York: Wiley, 1973:10-13. [24]YAO Y. The superiority of threeway decision in probabilistic rough set models[J]. Information Sciences, 2011, 181(6): 1080-1096. [25]ZHANG X, MIAO D. Reduction target structurebased hierarchical attribute reduction for twocategory decisiontheoretic rough sets[J]. Information Sciences, 2014, 277: 755-776. [26]WANG G Y, XU C L, LI D Y. Generic normal cloud model[J]. Information Sciences, 2014, 280:1-15. [27]李德毅,刘常昱,淦文燕. 正态云模型的重尾性质证明[J]. 中国工程科学, 2011, 13(4): 20-23. (LI D Y, LIU Y C, GAN W Y. Proof of the heavytailed property of normal cloud model[J]. Engineering Science, 2011, 13(4): 20-23.) [28]ZHANG B, ZHANG L. Theory and Applications of Problem Solving[M]. Amsterdam: Elsevier Science Inc., 1992: 1-2. [29]YAO Y. A triarchic theory of granular computing[J]. Granular Computing, 2016, 1(2):145-157. [30]LIU Y, LI D, HE W, et al. Granular computing based on Gaussian cloud transformation[J]. Fundamenta Informaticae, 2013, 127(1/2/3/4): 385-398. [31]许昌林.基于云模型的双向认知计算方法研究[D]. 成都: 西南交通大学, 2014. (XU C L. Method of bidirectional cognitive computing based on cloud model[D]. Chengdu: Southwest Jiaotong University, 2014.) [32]张仕斌,许春香.基于云模型的信任评估方法研究[J].计算机学报, 2013, 36(2): 422-431. (ZHANG S B, XU C X. Study on the trust evaluation approach based on cloud model[J]. Chinese Journal of Computers, 2013, 36(2):422-431.) [33]张光卫, 李德毅, 李鹏, 等. 基于云模型的协同过滤推荐算法[J]. 软件学报, 2007, 18(10): 2403-2411. (ZHANG G W, LI D Y, LI P, et al. A collaborative filtering recommendation algorithm based on cloud model[J]. Journal of Software, 2007, 18(10): 2403-2411.) [34]李海林,郭崇慧,邱望仁. 正态云模型相似度计算方法[J]. 电子学报, 2011, 39(11): 2561-2567. (LI H L, GUO C H, QIU W R. Similarity measurement between normal cloud models[J]. Acta Electronica Sinica, 2011, 39(11): 2561-2567.) [35]查翔,倪世宏,谢川,等. 云相似度的概念跃升间接计算方法[J].系统工程与电子技术, 2015, 37(7): 1676-1682. (ZHA X, NI S H, XIE C, et al. Indirect computation approach of cloud model similarity based on conception skipping[J]. Systems Engineering and Electronics, 2015, 37(7): 1676-1682.) [36]許昌林,王国胤. 正态云概念的漂移性度量及分析[J]. 计算机科学, 2014, 41(7): 9-14, 51. (XU C L, WANG G Y. Excursive measurement and analysis of normal cloud concept[J]. Computer Science, 2014, 41(7): 9-14,51.) [37]LIANG D, LIU D. Systematic studies on threeway decisions with intervalvalued decisiontheoretic rough sets[J]. Information Sciences, 2014, 276(C):186-203. [38]LIANG D, LIU D, KOBINA A. Threeway group decisions with decisiontheoretic rough sets[J]. Information Sciences, 2016, 345: 46-64. [39]LIU D, LIANG D, WANG C. A novel threeway decision model based on incomplete information system[J]. KnowledgeBased Systems, 2016, 91: 32-45. [40]LIANG D, PEDRYCZ W, LIU D, et al. Threeway decisions based on decisiontheoretic rough sets under linguistic assessment with the aid of group decision making[J]. Applied Soft Computing, 2015, 29(C):256-269. [41]UCI Machine Learning Repository[DB/OL].[2018-11-20]. http://archive.ics.uci.edu/ml/datasets.html. This work is partially supported by the National Natural Science Foundation of China (61572091, 61772096), the Science and Technology Talents Development Project of Guizhou Education Department (KY[2018]318), the Highlevel Innovative Talents of Guizhou Province (ZKG 2018[15]), the New Talent Cultivation Innovation and Exploration Project of Guizhou Province (QKHPTRC [2017]5727-06). LI Shuai, born in 1986, Ph. D. candidate, lecturer. His research interests include granular computing, rough set, cloud model. WANG Guoyin, born in 1970, Ph. D., professor. His research interests include granular computing, knowledge acquisition, cognitive computing, intelligent information processing, big data intelligence. YANG Jie, born in 1987, Ph. D., associate professor. His research interests include cloud model, granular computing, rough set, machine learning.
