一种基于不平衡类深度森林的异常行为检测算法
2019-12-23杨欣欣李慧波
杨欣欣,李慧波,胡 罡
(中国电子科学研究院,北京 100041)
0 引 言
近年来,随着民用安防设备的普及,视频监控系统在道路、商场、公园等公共场所越来越普遍,成为保障社会安全和秩序的重要手段。在传统的视频监控中,工作人员只能通过观察每帧监控画面获知异常情况,长时间观察容易造成视觉疲劳。传统的视频监控主观性强,人力耗费大,效率低下。基于智能监控视频的异常行为分析成为计算机视觉领域的研究热点,具有重要研究意义和应用价值。
目前国内外学者在视频异常行为检测方面已经开展了一些研究。Hu结合视频事件周围的时空上下文信息提出局部最近邻距离描述模型,具有检测多个异常事件的优点[1]。Li提出混合动态纹理模型,综合考虑纹理和空间特性[2]。Yuan采用固体物理学粒子作用力势能函数直观描述视觉语境,提出群体信息结构语境描述模型[3],在线实时分析局部异常行为。Cui模拟基于社会行为分析的群体活动,提出势能函数来表示物体的当前行为状态[4]。该方法不依赖于目标的检测与分割,而是跟踪时空兴趣点,更具鲁棒性。Adam基于底层统计信息设计针对特定类型异常事件监视器,集成多个监视器检测异常行为[5]。Wu针对相干和非相干场景,提出人群流建模和异常检测方法[6],将混沌动力学引入到群体描述模型中,通过混沌不变特征描述复杂的群体运动。Kim提出时空马尔可夫随机场(MRF)模型来检测视频中的异常行为[7]。MRF节点表示视频帧中的局部区域网格,边表示空间和时间中相邻节点的链接关联。该模型不仅可以在人群中定位局部异常行为,而且还能捕捉全局异常行为。Cong提出通过正常事件的稀疏重建来检测异常事件[8-9],在正常字典上引入稀疏重建成本度量测试样本的正常性。该方法为局部异常事件和全局异常事件的检测提供了统一的解决方案。Zhu针对特征提取过程中的噪声和不确定性,提出一种基于完全无监督的非负稀疏编码的人群异常事件检测方法[10]。该算法将字典学习任务定义为具有稀疏约束的非负矩阵分解问题,以小波距离代替传统的欧几里得距离作为距离度量重构成本函数。Cheng提出一种基于层次特征表示和高斯过程回归的局部和全局异常检测层次框架[11-12]。为了同时检测局部和全局异常,提取训练视频中的关键区域,用于发现邻近稀疏时空兴趣点的几何关系。该算法对轻微的拓扑变形具有鲁棒性。Zhang提出基于位置敏感散列滤波的异常检测方法,将正常行为散列为多个具有位置敏感散列功能的特征组,以过滤异常行为[13]。并采用粒子群优化方法搜索最优散列函数,提高算法效率和准确性。Leyva通过高斯混合模型、马尔可夫链和词袋来评估特征集,提高视频在线检测异常事件效率[14]。文献[15-18]为解决局部空间区域需要使用手工制作特征来识别异常的问题,提出时空自动编码器模型。该模型利用深度神经网络自动学习视频表征,并通过三维卷积从时空两个维度提取特征。
视频异常行为检测模型训练中需要的正常行为负例获取难度较小,而异常行为正例获取难度往往较大。所以训练样本集中负例往往较多,而正例往往较少,具有明显的类别不平衡性。目前已有的异常行为检测方法忽略了这种不平衡类的问题,使得模型倾向于数量较多的负例,容易将部分正例划分到负例类别中,造成异常行为漏检,在实际应用中可能会产生严重后果。为了解决异常检测中类别不平衡问题,本文采用欠采样方法构建类别平衡的训练样本子集。从负例样本中有放回地多次随机采样,每次选取与正例数目相近的样本。将选取的负例和正例样本划分到同一分组。经多次采样后得到多个分组,每个分组包含一个类别平衡的训练样本子集。在每个训练样本子集上训练学习模型,然后集成每个子集的学习模型,最终形成异常行为集成检测模型。深度森林模型是一种天然的决策树集成模型,具有较少的参数,适用于不同规模大小数据集的优点[19]。目前深度森林模型已成功应用于图像分类[20]、自然语言处理[21]等领域,并取得了较好的效果。本文以深度森林为框架,利用欠采样方法构建分组训练子集,每个分组训练一个随机决策树,多个分组共同组成若干随机森林。将随机森林输出结果合并后输入至下一层网络,以此类推,形成级联深度森林异常检测模型。
1 基于深度森林的异常行为检测算法
首先采用欠采样的方法构建不平衡类视频帧训练集。然后训练不平衡类随机森林模型,并将模型融入到深度学习框架中,构建多粒度级联深度森林模型。最后将不平衡类深度森林模型应用于视频异常行为检测中。
1.1 基于欠采样的不平衡类随机森林模型
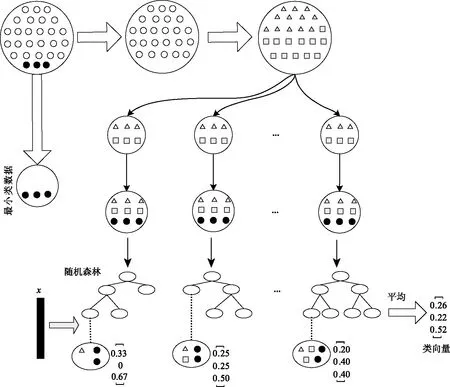
图1 基于欠采样的随机森林模型示意图
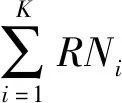
算法1:基于欠采样的不平衡类随机森林算法
1. 从每个负类中有放回地随机采样RNi个样本,与正例合并组成训练子集Si;
2. 利用训练子集Si建立CART决策树;
3.重复以上步骤m次,建立m棵CART决策树;
4.由m个CART决策树构成随机森林集成学习系统;
5. 对于新样本x,输出m个决策树结果的平均值。
将少数正例与数目近似的负例样本合并组合为一个训练子集,在此子集上训练决策树模型。最终,再将多个决策树模型结果合并作为输出结果。可见基于欠采样的不平衡类随机森林算法是一种集成学习方法。与直接采用决策树或决策森林方法相比,该方法不仅避免了多数负例对模型效果的不利影响,同时还能取得更加稳定、有效的预测结果。
1.2 基于多粒度深度森林的异常行为检测
视频帧每幅图像中的像素间存在空间关系,为了表示这种空间关系,可以采用滑动窗口扫描图像原始特征。如图2所示,图像原始特征具有空间关系,比如一个由400个图像像素组成的20×20的面板,那么一个10×10滑动窗口将产生11×11个大小为10×10特征向量。从正/负训练样本中提取的特征向量均视为正/负实例,然后将这些实例用作训练决策树。从相同大小的窗口中提取的实例用于训练完全随机树,集成随机树为随机森林。然后连接随机森林预测的类别分布向量作为新的变换特征输入至下一层网络。如图2所示,假设有3个类,并且使用了一个10×10维的窗口;然后,每个森林产生11×11个三维类向量,产生对应于原始20×20维原始特征向量的20×20×3维变换特征向量。图2只显示了一个大小为10×10的滑动窗口。为了取得更鲁棒的效果,采用多种滑动尺寸窗口,将生成不同粒度的特征向量,如图3所示。
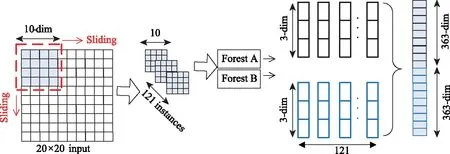
图2 基于滑动窗口的多粒度图像特征选取
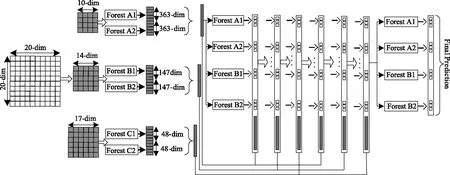
图3 不平衡类深度森林算法过程
深度网络学习模型依赖于图像特征的多层次处理,从不同层级表示语义信息。由此启发,深度森林采用如图3所示的多粒度级联结构,每层级联接收处理层的特征信息,输出处理结果至下一个层级。每个层级是由不平衡类随机森林组成的集合,是决策森林的集成学习系统。为了发挥集成学习系统模型多样性的优势,随机森林采用不同类型的决策树。
图3描述了不平衡类深度森林的整个过程。首先利用不同大小的滑动窗口,扫描不同粒度的特征。利用1.1节基于欠采样的方法构建不平衡随机森林算法。将同一粒度下不同随机森林预测结果组合为类向量。将类向量作为特征向量输入至下一层级的随机森林。预测的类分布形成一个新的类向量,然后与原始特征向量连接以输入到下一层级联。利用前一级生成的类向量扩充变换后形成新的特征向量,分别训练二级和三级森林。迭代此过程直到验证准则达到收敛状态。模型最终是由多层级联组成,每个级联由多个不平衡类随机森林组成。每个级联集成通过多种粒度特征扫描训练的决策树。在视频帧异常行为检测中,如果计算资源充足,可以尝试更多的粒度测试实际效果。给定一个测试实例,需要经过多粒度扫描过程以获得特征表示,然后经过级联直到最后一级。最终通过在最后一级聚集多个类向量,预测结果采取具有最大聚集值的类来获得。
为了减少过拟合的风险,通过k次交叉验证生成每个森林的训练样本和测试样本。具体地说,每个实例将被用作k-1次训练数据,产生k-1类向量,然后对这些类向量进行平均,作为下一级级联的增强特征最终类向量。在扩展一个新的级联之后,可以在验证集上估计整个级联的性能,如果没有显著的性能增益,则训练过程将终止,从而自动确定级联的数量。当涉及训练成本或可用计算资源有限时,也可以使用训练误差而不是交叉验证误差来控制级联增长。与大多数层级固定的深层神经网络模型不同,深度森林在适当的时候终止训练,自适应地确定网络层级数和模型复杂度。IMDF模型能够适用于不同规模的训练数据,而不仅仅局限于大规模的训练数据。
2 实验分析
本文进行实验的硬件环境:CPU为Core i5-5200U(2.20 GHz)、显卡为 NVIDA GeForce 920M、内存为8 GB。软件环境:计算机操作系统为 Windows 8,训练测试平台为 TensorFlow2.2、 Python3.5。
ROC曲线 (Receiver operating characteristic curve)能够反映检测率与误警率之间的关系,采用的 ROC作为评测标准,AUC (Area under curve) 表示 ROC 曲线面积。为了验证IMDF算法的有效性,将IMDF算法与经典异常检测方法稀疏重构误差算法(SRC, sparse reconstruction cost)[8]和自编码深度卷积神经网络算法(CAE, deep convolutional auto-encoder)[22]进行实验对比分析。
UMN 数据库是明尼苏达大学发布的群体异常行为库,包含三个不同场景的视频[12],每个场景都包含群体逃离异常事件,训练样本和测试样本数量如表1所示。UCSD视频集正常样本仅包括行人,异常样本包括:骑自行车、坐轮椅、滑冰、推小车、草地上的行人或车辆。根据场景不同,数据分成两个子集,具体样本数量如表1所示。表1表明UMN和UCSD数据具有明显的类别不平衡的特点。

表1 不同数据的样本数量
IMDF算法滑动窗口大小选取为4×4、8×8、16×16和32×32,每个随机森林包含500棵决策树。在UCSD数据集中为实现人群异常行为的定位,将完整视频画面划分为若干个大小相同的局部子区域,相邻子区域互不重叠。每个子区域设置一个唯一编号,每个编号对应不同的子区域。为实现对每个子区域进行人群异常行为检测,将每个子区域的连续视频帧作为输入,训练得学习模型;在检测人群异常行为时,同样将完整视频划分为局部子区域,再将每个局部子区域输入已训练好的学习模型。若某个子区域被识别为异常,则根据编号确定其在视频画面中的位置,实现群体异常行为的定位。
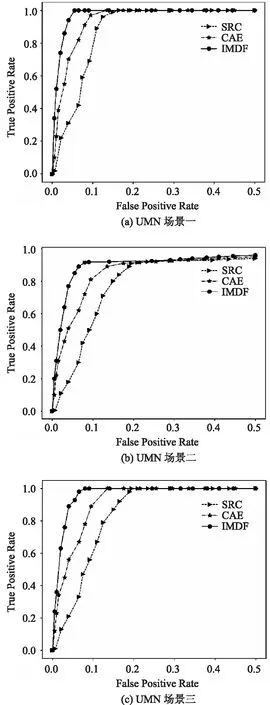
图4 SRC、CAE和IMDF算法在UMN数据集上的实验结果ROC曲线比较
SRC、CAE与IMDF算法在UMN和UCSD数据集上的实验分析结果ROC曲线分别如图4和图5所示。ROC曲线的横坐标为误检率,纵坐标为检测率,随着检测率的提高,误检率也随之提高。ROC曲线下方的面积AUC综合衡量了检测率和误检率。首先,图4和图5结果表明在UMN和CUSD数据集上IMDF实验结果的ROC曲线均明显高于SRC和CAE算法。原因在于,IMDF算法采用欠采样的方法,随机采样与异常类样本数量近似的正常类样本,避免了异常样本太少引起分类器向正常样本倾斜的问题。然后采用随机森林方法,将不同采样样本训练的分类器进行集成,获得总体样本训练结果。由于异常类别训练样本较少,造成CAE算法训练时正常样本发挥的作用较大,异常样本较小,导致异常样本识别的准确率降低。SRC算法适用于仅包含正常类别样本集训练,具有较强的正常样本识别能力。但是SRC算法失去了对异常类别的描述能力,无法充分利用异常样本进一步提高正常类别和异常类别的识别能力。
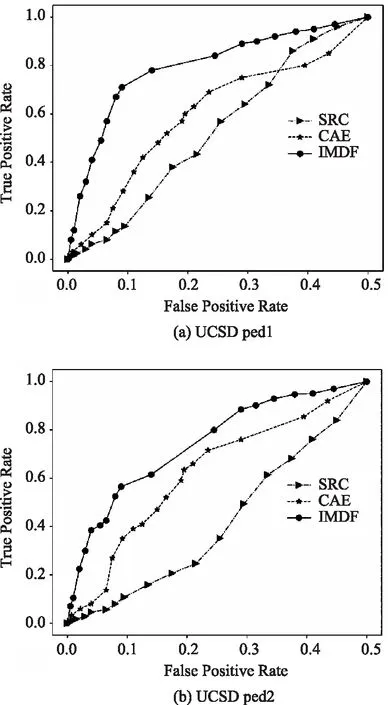
图5 SRC、CAE和IMDF算法在UCSD数据集上的实验结果ROC值比较

图6 SRC、CAE和IMDF算法在UCSD数据集上异常行为检测示例
如图6所示为算法SRC、CAE和IMDF在UCSD数据集上异常行为检测示例。图6(a)中IMDF算法成功检测到视频中3个异常行为,而SRC算法漏检自行车,CAE算法漏检滑板车。图6(b)中IMDF算法成功检测到视频车辆和自行车2个异常行为,而SRC和CAE算法漏检自行车。图6(c)中IMDF算法成功检测到视频车辆和滑板车2个异常行为,而SRC和CAE算法漏检滑板车。图6(d)中IMDF算法成功检测到视频2个自行车异常行为,而SRC和CAE算法漏检了一个自行车。SRC和CAE训练模型中异常样本较少,在训练过程中发挥作用较少,造成异常行为漏检的情况。图7 所示为SRC、CAE和IMDF算法在UMN数据集上3个场景中异常检测结果,黑色横条表示含异常行为的帧,白色横条表示属于正常行为的帧,其中第一行为真实结果,第2-4行分别为SRC、CAE和IMDF算法检测结果。结果表明,与SRC和CAE算法相比,IMDF算法漏检和误检较少,检测结果更接近真实情况。

图7 SRC、CAE和IMDF算法在UMN数据集上异常行为检测结果
3 结 语
针对视频帧的异常行为检测中存在不平衡类问题,提出一种基于欠采样的不平衡类深度森林算法,该算法采用欠采样的方法处理训练样本,能够较好地解决类别不平衡对决策森林模型的不利影响。实验结果表明,与已有的一类支持向量机和卷积神经网络算法方法相比,IMDF算法具有更好的检测效果。然而IMDF模型静态地分析每帧视频,忽略了相邻视频帧之间的联系。下一步主要研究方向是在训练模型中考虑目标行为在相邻视频帧中的时空连续性,引入时空因素检测异常行为,进一步提高检测效果。
