基于PageRank的论文引用网络关系挖掘
2019-12-23徐岳皓刘振宇
金 洁,徐岳皓,刘振宇
(1.西安电子科技大学,陕西 西安 710071;2.中国电子科学研究院,北京 100041;3.航天信息股份有限公司,北京 100086)
0 引 言
随着网络信息资源的丰富,数字化文献已经成为学习和日常工作的标配,各个学校都具有网络文献数据库提供查询和下载服务。同时国内外也有许多数字资源库,例如万方拥有12个专门存储数字资源的数据库,上亿篇中外期刊论文,学位论文和会议论文千万以上,以及专利、科技报告等其他文献数据[1]。面对海量的数据文献,知网等文献数据库只是简单的根据引用量和搜索关系进行排序,而未考虑到文献的重要性以及文献在引文网络中的引用关系,因此检索者很难从海量论文中找到对自己有用的高质量论文。同时我国的学术期刊过于注重期刊的影响因子和期刊水平,往往忽略了引用和被引用期刊的水平,也忽视了部分新作者在普通期刊中发表的高水平文章[2]。因此,将重要文献从引文网络中筛选出来是本文的初衷。本文利用传统的PageRank算法,同时结合论文引用及被引用的关系,提出了度数改进的RageRank算法进行引文网络中文献重要性评估方法,实验结果表明,该方法能很好的挖掘出引文网络中的重要文献并进行排序。
1 研究思路及方法
将论文看做是节点,论文的引用看做论文之间的链接边,那么论文引用网络就可以看做是一系列节点与边构成的网络图谱。
1998年Page等人[3]提出了PageRank算法,最早被应用于搜索引擎的网页排序当中。1999 年, Kleinberg[4]提出了 HITS 算法将网页分为两类:中心网页和权威网页,算法通过迭代获得网页的中心值和权威值,但是没有考虑时间信息。在此之后基于PageRank的改进算法被广泛运用于社交、文献引用、搜索引擎排名等方面[5]。Sayyadi等人提出了FutureRank算法[6],考虑到了时间和已有PageRank值,但是未考虑论文引用本身的含义,预测排名相关度较低。刘大有等人提出权威网络,但是权威网络要求论文引用网络全面陈旧,对新加入网络的节点并不适用[7]。李仲谋通过引入ScholarNode建立学术论文影响力评价方法,增大了边缘论文的高质量论文重要度[8]。为了增强运算速率,刘记云等人提出了运用MapReduce进行PageRank值的计算[9],但是MapReduce分布式并行计算本身不适合具有联系性的图数据进行迭代运算。针对以上研究的不足,本文提出一种新的论文重要程度排序算法,能很好的利用同一时间段论文被引量在网络中的比重的改进传统PageRank算法的不足,获得论文在引文网络中的重要性排序。
2 基于同时段被引量优化的PageRank重要度排序算法
2.1 PageRank算法
我们将网络抽象成一个有向图,网络中的网页就是有向图中的点,网络中的超链接就是有向图中的有向边。用有向图1表示一个简单的网络。
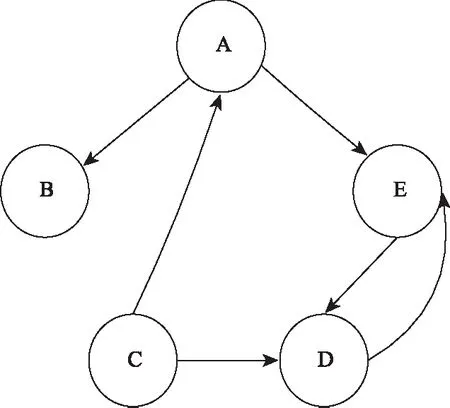
图1 有向图G
图1表示含有五个节点的网络图之间的关系,每个节点将自身的PR值平均分配给它的出链节点,而每个节点收集所有接入的节点传来的PR值形成自己的PageRank值。以网页A为例,A的PR值是网页C平均分配到A点和D点的,而A的PR值又平均分配给节点B和节点E。
把节点Ai的PR值记为PR(Ai),把节点Ai的入链集合记为I(Ai),把节点Aj的出度记为N(Aj),那么PageRank算法的基本思想可以用公式(1)表示:
(1)
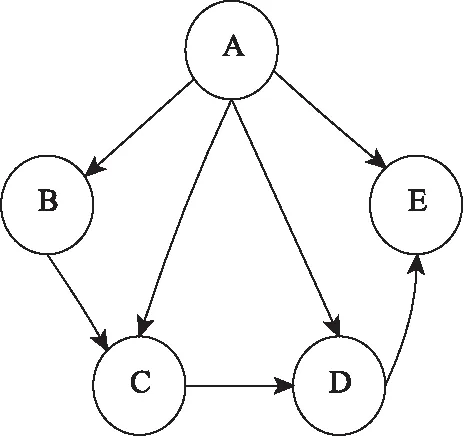
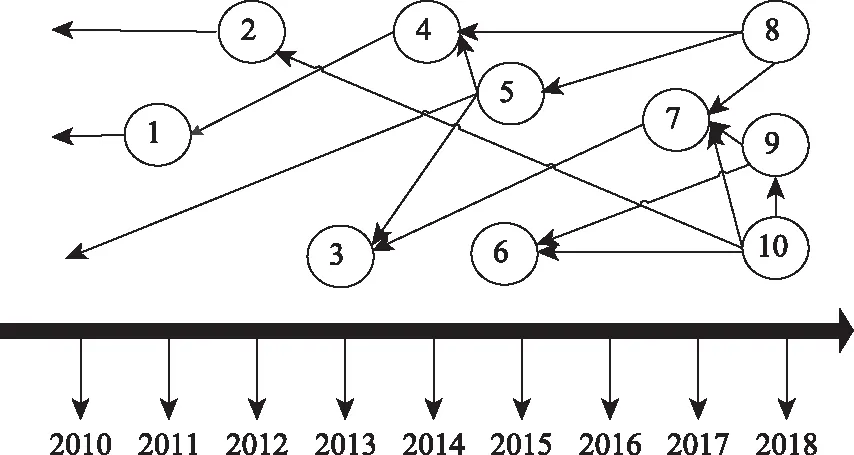
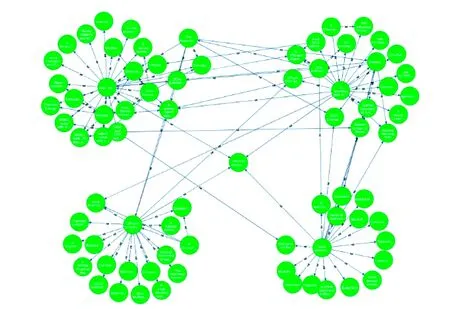
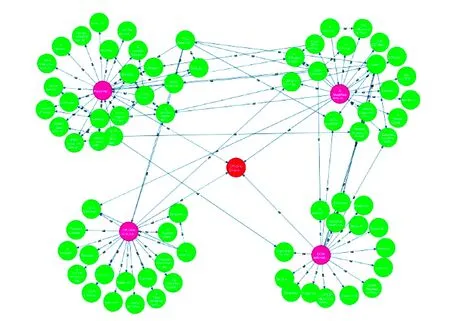
从公式(1)中我们可以看出,每个网页的PR值会根据出度平均分配给它的各个出链网页当中,一个网页被更多高质量的网页指向,那么这个节点就可以获得更高的PR值,在链接网络中的重要性就越高。但是从图1可以看出B点没有出链节点,当访问者到达B点后会停止对外分配,从而形成等级沉积现象。同时,当访问者进入点D、E时,会在由D、E构成的弱连通图中不断循环从而产生等级渗漏现象。为了防止这种等级下沉和等级渗漏的现象,Page在PageRank算法中引入了衰减因子d,衰减因子使得节点停留在某点的概率为d(0 (2) 数字资源中论文的数量极多,论文之间存在复杂的引用关系,由引文及被引用文献之间的引用关系构成的有向无环图称之为引文网络。引文网络中的边表示论文之间的参考、援引关系。如图2所示,用节点代表论文,用有向边代表论文之间的引用关系,如论文A指向论文B表示论文A对论文B有一次引用。 图2 论文链接网络 但是引文网络不同于网页之间的链接网络,网页中存在大量的互链接操作,但是论文的引用关系与时间有很大的关系,越早的论文越会被引用,越晚的论文被引用的次数越少。但是论文都会去引用别人的文章,所以一般情况下越晚发表的论文,引用与被引用的次数差值就会越大。同时,在同一时间段被引用越多的文献,说明该文献在该时间段属于高关注度文献。如图3所示。 图3 论文引用网络 引文网络无法不同于链接网络,由于被引用文献无法回引和自引用,所以很难构成弱连通图从而产生等级下沉的现象。但是引文网络与时间有强相关性,所以选取数据集时容易产生时间靠前的论文找不到参考文献,无法产生出链论文,从而导致等级渗漏现象。此外,链接网络是根据随机冲浪模型演变来的,链接网络之间的具有随意性和跳跃性,相互之间的关系没有引文网络密。引文网络一般属于同一学科领域之间的引用,关系紧密并且不会存在互联网中的恶意链接现象,所以引文网络是一种特殊的链接网络。引文网络与链接网络有很大不同,我们在使用链接网络排序算法PageRank是需要考虑引文网络的特殊性。 引文网络的引用不同于网页链接,它是真实可靠的,引文之间不存在虚假性和恶意链接的情况,因此引文网络的出入度关系比传统链接网络中的出入度关系更具有信息。同时论文引用网络具有稀疏性,根据帕雷托法则可以看出,20%的论文贡献了该领域80%的价值,因此大部分论文的引用量远远小于其被引用量,只有少部分论文才会被大量引用,而这部分论文才是引文网络中的核心。综上所述,我们对论文的出入度数进行挖掘,增大论文被引用次数高的论文在整个引文网络中的重要性。我们规定,一篇论文的入出度数比越高,那么它在参考文献中的重要性就越高,同理若是文献入出比越低,那么说明它对引文的作用很小,重要程度也随之降低。修改后的入度反馈权值如式(3)和式(4)所示: (3) (4) 公式(3)中din(din>0)和dout(dout>0)分别代表引文网络中节点Pi的链入数和链出数即入出度数,式(4)中O(Pj)是网页Pj的出链集合,将Wd加入到PageRank算法中,那么Pi的入链Pj会根据Pi的入度权重为Pi分配PR值,即如果Pi是Pj出链中入度的节点,Pj就会分配给Pi较大的入度权重。这样可以根据论文的被引用情况来判断论文在参考文献中的作用程度,从该改变了传统PageRank平均分配节点权重的不足。 同时引文网络与时间有强关联关系。理论上,时间越早的论文越容易被引用,而时间越晚的论文很难被其他论文引用,但是时间上靠后的论文不一定就是低质量的论文,传统的论文引用网络质量排序方法仅靠改变时间权重对旧论文进行限制,同时提高新论文的时间权重,但是这样会统一提升旧论文或者新论文的PageRank值,无法精确分辨出高质量论文来。所以我们提出同时段被引量的概念,在不同时间节点人们总的关注度是一定的,所以论文质量的好坏要与它同时段的论文进行比较,一篇论文与它同时段相比获得更大的引用量,那么这篇论文就被认为是高质量的论文。基于此,我们可以得到不同时段的高质量论文,从而避免了仅靠时间权重导致的旧论文权重过大或者新论文权重过大的问题。如公式(5)所示: (5) 公式(5)中T是引文Pi、Pj共同的时间段,di(Pi)和di(Pj)分别表示节点Pi和节点Pj的入度个数,因为在引文网络中入度个数代表引文在该时间段被引用的次数。同一时间段中的论文,被引用的次数越多,说明论文在该时间段内吸引了更多的关注度,属于该时期的高质量论文,避免了传统引文计算网络中通过添加时间权重导致新旧论文时间权重补足不均的缺点。 综合节点入出度数比以及同时段关注度的综合加权公式如式(6)所示: (1-d)/N (6) 公式(6)中a、b分别表示入出度权重和时间改进权重的分配大小,影响节点在局部网络和全局网络中的权重分配,实验中分别选取0.7和0.3,衰减因子d一般取0.75,初始PR值取1。 实验采用从2014年到2018年四年内400多篇DOA相关论文,引用网络共3000节点6000条边。从随机论文节点开始发散,链接边数在3以内的3度引用网络如图4所示,可以看出论文网络引用关系十分庞大并且复杂,而真正的引文网络更加复杂多变,引用关系稀疏性更强。 图4 随机节点3度引用网络 通过改进的PageRank算法进行引文网络挖掘,对计算得到的网络节点重要性结果排序取前七名如表1所示。 表1 引文网络改进PageRank挖掘结果排序 对重要度最高节点进行可视化展示,展现论文2-drgee关系图谱如图5所示。 图5 重要节点2度关系图谱 对图5进行重要节点的标记,标记后的论文关系图如图6所示。 图6中深红色节点是计算得到的重要论文,浅红色得到的是引用深红色论文的其他论文如表2所示,从图中可以明显看出浅红色节点与诸多论文有引用关系,属于被经常引用的论文,论文在引文网络中重要性较高,而深红色论文被四篇浅红色论文所引用,说明深红色论文在该时间段内关注度较高,属于高质量论文。 图6 最高节点图数据关系图谱-papername 表2 重要节点名称信息 从实验结果可以看出,挖掘出的重要节点与链入它的其他节点的入度相似,但是重要节点的在引文网络中有很大的入出度比率,论文的入度与出度比越大的文献在引文网络中的重要性越高。同时由于文献数据来源于部分出名期刊,因此导致论文引用网络中的文献不仅存在引用稀疏性还存在文献来源分类。我们认为高质量期刊的论文重要性大于普通期刊,因此部分出名期刊的论文重要程度远大于其他期刊文献,从而使得全局网络最优变为局部(期刊)网络最优,实验中Sensors期刊质量较高并且数据源有较多文献,因此在引文网络中有较高的计算权威性。 本文从论文引用网络的特点出发,针对传统引文网络检索中特征单一的缺点以及传统文献网络重要度排序中未考虑出入度差别和时间差别的不足,对PageRank算法进行改进。根据论文引用网络参考文献中不同论文的出入度比值的比一样,改进PageRank值分配方式,同时根据论文的发表时间不同,提出同时段吸引力的概念,将同一时间段的论文进行差值加权,从而将不同时间段的高质量论文筛选出来。实验结果表明,该方法能很好的找到论文引用网络中的高质量文献,并对网络中的高质量论文进行重要度排序。2.2 引文网络
2.3 基于引用差值的改进PageRank排序算法
3 实验结果
3.1 数据集
3.2 实验结果与展示


3.3 实验结果说明
4 结 语
