应用强化学习算法求解置换流水车间调度问题①
2019-12-20张东阳叶春明
张东阳,叶春明
(上海理工大学 管理学院,上海 200093)
1 引言
排序问题是生产系统和服务系统中的一类典型问题,它作为传统问题和热点问题,至今一直有众多学者研究.根据工件的不同加工特点,排序问题可分为流水作业排序(flow-shop scheduling)、自由作业排序(openshop scheduling)和异序作业排序(job-shop scheduling)[1],其中Flow-shop排序又可分为同顺序和任意序两大类,同顺序Flow-shop排序问题又称置换流水车间调度问题(Permutation Flow Shop Problem,PFSP).相关理论证明,3台机器以上的PFSP即为NP难题[2],至今还未发现具有多项式时间的优化算法.
目前,解决这类问题有效方法主要包括:精确算法,启发式算法,智能优化算法.如枚举法、分支定界法等精确算法只对小规模问题的求解有着很好的效果.如Gupta法、RA法和NEH法等启发式算法可以求解快速构造问题的解,但是解的质量较差[3].近年来,遗传算法[4]、人工神经网络[5]、蚁群算法[6]、粒子群算法[7],烟花算法[8]、进化算法[9]等智能优化算法因能在合理的时间内获得较优解,受到了众多学者的广泛研究,并已经成为解决该类问题的重要方法.
近年来,随着技术的进步,机器学习领域里一个古老又崭新的理论——强化学习[10,11],又得到了科研人员的广泛重视.但目前强化学习主要应用在游戏比赛、控制系统和机器人等领域[12-14],应用在生产调度中的并不多.Wang等学者将Q-学习算法应用到单机作业排序问题上,发现智能体经过学习能够从给定的规则中选出较好的规则,证明了将强化学习应用到生产调度的可能性和有效性[15,16].Zhang等学者利用多智能协作机制解决了非置换流水车间调度问题[17],国内的潘燕春等学者将Q-学习算法与遗传算法有机的结合起来,在作业车间调度取得较好的效果[18,19].王超等学者提出了改进的Q-学习算法运用于动态车间调度,构建了一系列符合强化学习标准的规则[20].可以看到,过往的文献里面强化学习应用在调度上大部分是多智能体协作,或者与其它算法结合去解决调度问题.因此,本文用单智能体的强化学习来解决置换流水车间调度问题,合理的将状态定义为作业序列,将动作定义为机器前可选加工的工件,来适应强化学习方法.智能体通过与环境不断交互,学习一个动作值函数,该函数给出智能体在每个状态下执行不同动作带来的奖赏,伴随函数值更新,进而影响到行为选择策略,从而找到最小化最大完工时的状态序列.最后用该算法对OR-Library提供Flow-shop国际标准算例进行仿真实验分析,最终的实验结果验证了算法的有效性.
2 置换流水车间调度问题描述
置换流水车间调度可以描述为[21,22]:n个工件要在m个机器上加工,每个工件的加工顺序相同,每一台机器加工的工件的顺序也相同,各工件在各机器上的加工时间已知,要求找到一个加工方案使得调度的目标最优.本文选取最小化最大加工时间为目标的调度问题.对该问题常作出以下假设:
1)一个工件在同一时刻只能在一台机器上工;
2)一台机器在同一时刻智能加工一个工件;
3)工件一旦在机器上加工就不能停止;
4)每台机器上的工件加工顺序相同.
问题的数学描述如下,假设各工件按机器1到m的顺序加工,令 π ={π1,π2,···,πn}为所有工件的一个排序.pij为工件i在机器上j的加工时间,不考虑所有工件准备时间,C(πi,j)为工件 πi在机器j上加工完成时间.

其中,式(1)中的i=2,···,n;j=2,···,n,式(2)为最大完工时间.
3 强化学习理论
强化学习是人工智能领域中机器学习的关键技术,不同于监督学习和无监督学习,主要特点在于与环境交互,具有很强的自适应能力,具有实时学习的能力.强化学习的目标是在与环境的试探性交互中学习行为策略,来获取最大的长期奖赏[23].图1描述了强化学习的过程,强化学习最主要的是两个主体,分别为智能体和智能体所处的环境,环境意味着多样的复杂状态,所有的状态可以看成一个集合S.当智能体接受到t时刻的状态st(st∈S)以及从上一个状态st-1转变成st所得到的瞬时奖励rt,智能体从可选的行为集合A中选取一个动作at来执行,这样环境状态就转移为st+1,同时智能体接受来自于环境状态改变瞬时奖励rt+1和t+ 1时刻的状态st+1,根据从中学习到的经验,来决策t+ 1时刻的动作at+1.按此循环,智能通过不断与环境交互,根据学习到的策略,不断尝试并调整自身的行为,来获取最大的长期奖赏.

图1 强化学习模型
强化学习的算法可以分为2类,一类是基于模型已知的动态规划法,一类是基于模型未知的算法如蒙特卡洛算法、Q-Learning算法、TD算法等.本文采用的Q-Learning算法来解决问题.算法的核心是一个简单的值迭代更新,每个状态动作对都有一个Q值关联,当智能体处在t时刻的状态st选择操作at时,该状态动作对的Q值将根据选择该操作时收到的奖励和后续状态的最佳Q值进行更新.状态操作对的更新规则如下:

式(3)中,表示学习率,学习率越大,表明立即奖赏和未来奖赏对当前的影响较大,智能体越能看到未来的结果,但收敛速度会比较慢,表示折扣因子,代表决策者对得到的奖赏的偏好,折扣因子越大,智能体越有远见,即考虑当前的选择对未来的结果造成的影响.已经证明,在马尔科夫决策过程中,在某些限制条件下,QL能够收敛到最优值[24].QL算法更新过程如算法1所示.

算法1.QL算法初始化Q值for each episode:初始化状态s for each episode step:在t时刻下状态 的所有可能行为中选取一个行为images/BZ_201_511_1487_536_1512.png images/BZ_201_1002_1487_1027_1512.png执行动作,得到下一状态images/BZ_201_660_1531_710_1565.png和奖赏值更新Q值:[()]images/BZ_201_418_1540_443_1565.png images/BZ_201_843_1540_864_1565.pngimages/BZ_201_366_1649_1108_1699.pngimages/BZ_201_285_1720_385_1745.pngend for end for
算法中的智能体有2种不同动作选择策略:探索和利用,而 ε-贪心行动值法是智能体选择动作的常用的策略,以较大概率(1 -ε)选择完全贪婪行动,以较小概率(贪婪率)ε随机选择行动[10].ε越小越重于利用,即利用现有的学习成果来选取行动,ε越大越重于探索,即随机选取行动.
4 Q-Learning在PFSP上的应用
利用强化学习解决PFSP问题,最重要是如何将问题映射到强化学习模型中,并利用相关算法来得到优化的策略结果.本文构建了环境中的状态集,动作和反馈函数,并采用QL算法来进行优化.
定义1.状态集.将n×m的PFSP问题中m个机器中的第一个机器当作智能体,将第一台机器前的未加工的工件作为环(境状)态.根据文献[25],智能体的状态可以设定为Si=Ari,每个智能体(i)都有|Si|=2n(n表示工件数)状态.在我们的案例中只有一个智能体,因此,所有状态的集合为 |S|=2n,表示为S={s1,s2,···,sn2}.
定义2.动作集.将智能体前可以选择加工的工件作为可选的动作.因此,在我们的案例中可选择的动作集为A={a1,a2,···,an}.
定义3.反馈函数.我们选取最小化最大完工时间作为奖励信号,最小化最大完工时间越小,奖励值越大,意味着选取的动作也好,函数表示如下:

根据上述的定义,将PFSP问题映射到QL算法中,具体描述如算法2所示.

算法2.QL解决PFSP问题算法初始化:Q(s,a)={}Best={}for each episode step:初始化状态s={}while not finished(所有工件):初始化所有动作值根据状态s利用贪心行动值法来选择动作执行动作,得到下一个状态st+1和奖赏值r(1/makespan)更新Q(s,a)[()]images/BZ_201_1439_1684_2180_1734.pngimages/BZ_201_1365_1755_1457_1780.pngimages/BZ_201_1357_1909_1457_1934.pngend while if makespan(s)< makespan(Best):end for
5 实验结果分析
为验证QL算法解决置换流水车间问题的性能,选择OR-Library中Carl类例题,21个Reeves例题来进行测试,将实验结果与一些算法进行比较.算法程序用Python3.0编写,运行环境为Windows 7 64位系统,处理器为2.60 GHz,4 GB内存.经过初步实验,分析了不同学习参数对学习的影响,最后确定了相关参数,迭代次数为5000,学习率为0.1,折扣因子为0.8,贪婪率为0.2.以相对误差率RE=(C-C*)/C*×100%,平均误差率ARE=(Ca-C*)/C*×100%和最优误差率BRE=(Cbest-C*)/C*×100%为比较标准,每个例题运行20次.其中C为算法运行的结果,C*为算列的最优值.Ca,Cbest分别为所求解的平均值和最优值.
选择Car类例题与文献[25]提到的萤火虫算法(FA)、粒子群算法(PSO)、启发式算法NEH来进行比较.从表1和图2中我们可以看出,QL算法在Car类算例中基本能找到最优值,与PSO,FA等智能算法寻优效果上相差不大,而启发式算法NEH求解算例最优的效果一般,只适用于对精度要求不高的场合.在算例的平均误差上,QL算法求解质量优于PSO算法,和FA算法不相上下,展现了QL算法的良好稳定性.说明QL算法对置换流水车间调度问题有较好的寻优能力.
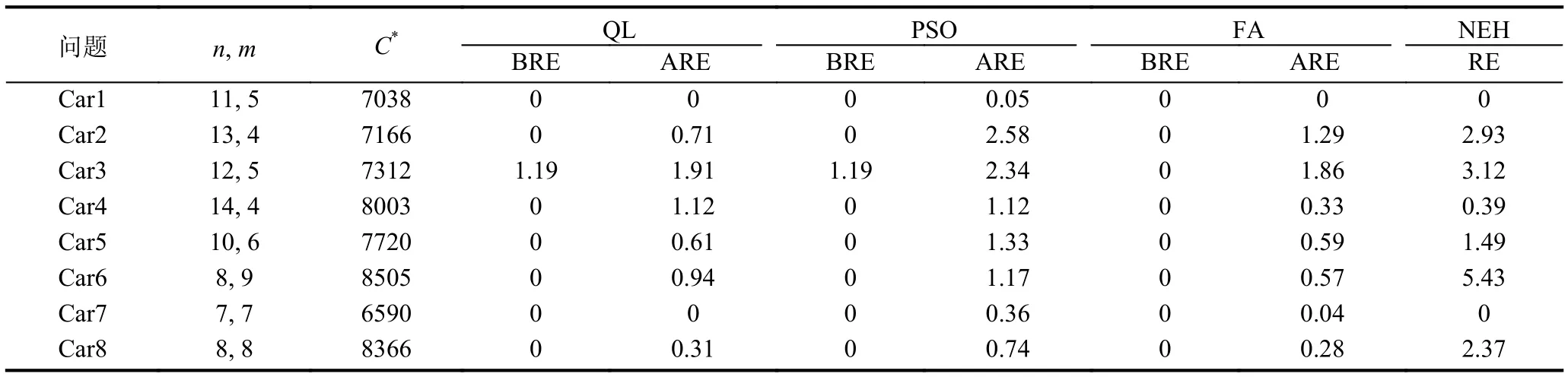
表1 Car类问题测试结果

图2 平均值比较
选取算例Car4算例来分析QL算法的收敛能力,从图3中发现QL算法刚开始下降较快,在中间一段时间内虽然两次陷入了局部最优值,但最后都成功跳出了局部最优,达到最优值.

图3 算例Car4最优值下降曲线图
表2给出了QL算法对Reeves例题(Rec37、Rec39、Rec41 3个算例的值不是最优值,而是最优上界).测试结果,并与PSO[25],GA[26]等知名算法比较,QL算法的平均最优值最小,表明整体上QL算法的寻优能力比GA和PSO算法都好.

表2 Reeves例题BRE测试结果
6 结束语
面对日益增长的大规模调度问题,开发新型算法越来越重要.本文提出了基于QL算法解决置换流水车间调度问题的算法,通过对Car算例和Reeves算例等基准问题进行测试并与已有的算法进行比较,评价了该算法的有效性.结果表明,该方法是解决置换流水车间调度问题的一种有效的方法.
