基于慕课的计算机教学分级方法研究
2019-12-17李志
李 志
(中国人民警察大学,河北 廊坊 065000)
0 引言
随着信息技术的迅速发展和互联网技术的广泛应用,移动互联、大数据、云计算等新技术迅速崛起并逐步融入人们的学习、生活和工作。近年来,微课、慕课、私播课、翻转课堂、雨课堂等新的教学形式迅速兴起,掀起了高校在线教育改革的新浪潮。
目前,各高校均已开设计算机类公共基础课程,对该课程的重视程度越来越高。由于全国各地经济文化发展还很不平衡,城乡教育存在不容忽视的差距,对信息技术课程的重视程度不一,致使高校新生的计算机水平参差不齐。学生之间的个体差异,为计算机教学带来很大困难,各高校对计算机分级教学的呼声越来越高,国内许多高校也陆续对计算机分级教学进行了有益尝试。然而,由于传统教学形式的限制,课上授课、讨论,课下练习等一系列学习过程依然需要遵循教师的时间安排进行,无法把时间和学习的自主性真正交还给学生。慕课的兴起,为分级教学提供了更加灵活的空间,为实现真正的“因材施教”提供了可能。
慕课是一种特定的在线课程,其以灵活、独特的方式,为计算机教学尤其是计算机分级教学,注入了新鲜的活力。慕课既解决了教学条件受限的问题,也可以实现学习者的个性化学习,从而摆脱传统课堂教学进度的束缚,便于差异化教学的实施。
分级教学按教学过程分为学生分级、教学目标分级、评价分级等。其中,学生分级的客观性和有效性,是分级教学成功实施的重要前提。慕课平台环境下,问卷、学习过程、测试等数据采集便利,为利用数据挖掘技术进行学生分级提供可能。
1 ID3算法描述
决策树方法是用于分类和预测的重要技术。1986年,J.Ross.Quinlan提出的ID3算法,是最经典的决策树挖掘算法,并为后来许多决策树其他算法的研究和改进打下理论基础[1]。
ID3决策树算法引入了信息论中的一些概念,将信息熵和信息增益作为选择测试属性的标准,通过决策树内部结点各个属性间信息增益的比较,自顶而下,递归建立样本数据集的决策树,以用来对未知的数据集进行分类。
1.1 信息熵
熵是物理学中的一个名词,常用来表示某些物质系统状态的一种度量。信息熵是信息论中的概念,称为平均信息量,指信息的不确定性,是对被传送的信息进行度量所采用的一种平均值。
设S是具有k个样本数据的集合,S中的类别属性共有m个不同的取值,可以将S分为m个不同类,即Ci(i=1,2,…,m)。设si是S中属于类Ci的样本数据数,则对于样本集合S分类所需的信息熵为:
1.2 条件熵
条件熵也叫作期望熵。假设S样本集合中属性X共有n个不同的取值,可以将S分为n个不同的子集,即Cj(j=1,2,…,n)。设sj是S中属性X取值为Xj的样本数据数,则属性A的条件熵为:
1.3 信息增益
信息增益用来度量属性划分样本数据集所带来的信息或者信息熵的有效减少量值,根据它能够确定在什么层次上选择什么样的变量来分类,以此为依据构建树。
S样本集合中属性X的信息增益为:
Gain(X)=I(s1,s2,…,sm)-E(X)
ID3算法选择信息增益最大的属性为决策树的根结点,使得对结果划分中的样本分类所需信息量最小。然后,使用递归的方法确定其他分支,直到构建出整棵决策树。在决策树中每一个非叶子结点对应着一个非类别属性,这个属性不同的值分别为下一级树枝。在下一级再对其他属性进行信息增益的计算,以确定下一级分类结点,最终都到叶子结点结束。一个叶子结点代表一个分类结果,其从根结点到该叶子结点之间的路径记录着所属的类别。
ID3决策树算法的流程如图1所示。
ID3决策树算法通过图1中步骤的不断循环,对决策树逐步求精,直到找到一个完全正确的决策树为止。该算法构造的决策树,整体看起来从顶向下形成一组类似于IF…THEN的规则。ID3算法的原始程序只能区分两个类别的数据,即布尔值真或假。随着算法的完善和发展,目前该算法允许用于多个类别的决策。
1.4 ID3算法的优缺点
ID3算法自诞生以来,作为一种经典算法经久不衰。ID3算法按人们处理事情的常规办法,自顶而下、从简单到复杂建立决策树。该算法从一颗空树开始,递归选择最大信息增益属性构造当前结点,最终搜索到一棵能正确分类数据集的决策树。ID3算法基础理论清晰、方法简单、决策树易于构造、学习能力较强,是获取知识的有用工具,也是数据挖掘和机器学习领域中的一个好的范例[2]。
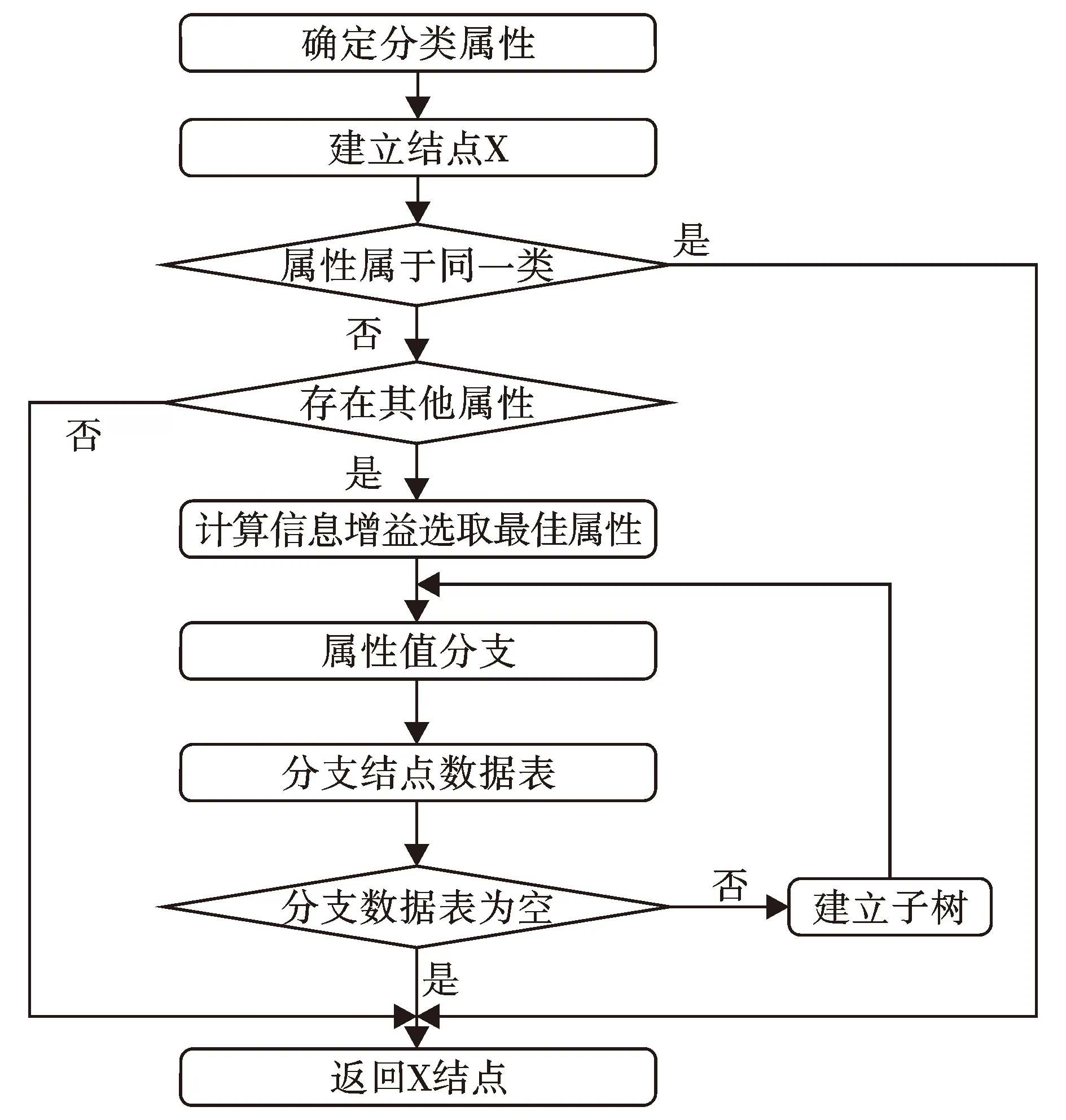
图1 ID3算法流程
但是,ID3算法也有缺陷。首先,由于ID3算法以信息增益作为分裂属性选择标准,偏向于选择取值较多的属性,但是该属性并不一定是最优的属性,某些情况下,这类属性并不能提供太多有价值的信息。其次,ID3算法只能处理离散型的属性,而不适合处理连续型的属性,因此,在分类前必须对连续型的属性进行离散化。再次,ID3算法中用到的训练集中正反例的比例应该与实例中的比例一致。
由于ID3决策树算法存在多值偏向的缺陷,因此,当用于决策树的属性过多时,可能会造成其算法过于繁杂甚至无效。关联规则的应用,可以从样本事务数据库中找出与分类属性关联最为紧密的属性集,同时将这些属性作为待选属性应用到ID3决策树中。这样,可以快速有效地筛选无关属性,尽量避免ID3算法多值偏向造成的复杂性和无效性。
2 ID3算法在学生分级中的应用
2.1 研究对象和目标
以选报“计算机基础应用”慕课课程的普通本科学生172人,成人本科学生303人相关信息为研究对象。其中,将普通本科学生172人、成人本科学生200人相关信息作为样本数据库,成人本科学生103人相关信息留作测试数据库。目标是希望通过对样本数据库中筛选信息完整、分级效果良好学生的摸底成绩、调查问卷进行分析,结合学生自我分级意愿,借助关联规则,选取用于学生分级的关键元素,建立决策树,以指导今后计算机分级教学慕课中的学生分级,并以测试数据库检验该分级模型。
2.2 数据采集
数据的采集来源于5部分:(1)摸底测试,由考试系统直接生成,包含选择、判断、打字、Windows基本操作、Word、Excel、PowerPoint、网络和E-mail几部分。(2)新生计算机水平调查问卷,由慕课平台发布并收集,包括籍贯、家庭情况、计算机学习情况、计算机技能掌握情况、计算机技能拓展情况、上网情况、兴趣判断、入学前工作性质、入学前最高学历、是否大学生入伍、是否计算机相关专业等信息[3]。(3)学生在对自己基础能力认知的前提下提出的分级意愿,同样由慕课平台发布并收集。(4)分级实施后,登记确定的分级结果。(5)最终结课考试,由考试系统直接生成。
2.3 数据预处理
采集到的原始数据往往存在数据不完整、含有噪声、不一致等问题,因此不能直接用于数据挖掘,需要对原始数据进行预处理,以保证用于挖掘的数据准确性,提高数据挖掘的精度。
2.3.1 数据清理
由于成绩数据来源于考试系统,而其他数据多通过慕课平台采集,从一定程度上避免了原始数据的不一致性。因此,数据清理的主要任务是解决数据中空缺值的问题。
某些学生因故未能参加摸底测试或结课考试,此时可以采用忽略元组的方法将成绩表中缺失成绩的记录予以删除。新生计算机水平调查问卷由教师组织,学生自主填写,可能会存在学生对某些项出现理解偏差或者理解不了的情况,也可能出现漏填等情况。缺少多个属性值的记录,在很大程度上失去了挖掘的意义,可以直接予以删除。而对于缺少个别属性值的记录,可以选择该属性中最可能的值进行填充、完善。
2.3.2 数据集成
数据集成的过程是合并多个数据源中的数据并将其置于一个一致的数据存储中。从集成后的数据集中选择与挖掘有关的数据,可以在确保数据语义完整和正确的前提下,适当降低数据量的大小,直接提高挖掘效率。
所有数据表中均有“学号”和“姓名”字段,但这两个字段对挖掘过程没有任何意义,只是起到对记录进行标识的作用。分级教学主要针对总分进行分级,因此在摸底成绩表和结课成绩表中,只对总分进行挖掘分析。
5个数据表中,前4个数据表主要用于决策的生成过程,而最后一个数据表主要用于筛选样本数据集。虽然结构比较相似,但其目的和对象均不完全相同,因此不应在此将多个数据表进行合并,应在去除字段属性的冗余、完成数据离散化后,将其置于一个数据库中,待应用具体算法前再根据需要进行合并。
2.3.3 数据离散化
数据离散化就是将属性值划分为区间,在进行分析时使用区间的标号代替实际数据的处理方法。数据离散化主要是为数据挖掘服务的,通过数据离散化技术可以减少连续属性值的个数[4],简化数据,最终目的是使数据挖掘结果更加简洁和易于理解,减少系统开销。
在摸底成绩表中,将总分以50分和70分为界线分为三段,即[0,50),[50,70),[70,100]。
对入学前工作性质进行汇总整理,根据工作性质与计算机接触几率分析,将入学前工作性质分成“计算机相关”和“计算机无关”。为简化算法,进一步将其抽象为逻辑变量“计算机相关工作”,其值分别取Y或N。
2.4 决策树的应用
为避免ID3算法多值偏向造成的复杂性和无效性,利用关联规则筛选无关属性,提取用于决策树的属性共4个,分别为:计算机相关专业、通过计算机等级考试、自我兴趣判断及计算机相关工作且大学生入伍。部分数据记录如表1所示。
2.4.1 分类属性信息熵
统计得知,分类属性“分级”共200条记录,值为“A”的有45条记录,值为“B”的有110条记录,值为“C”的有45条记录。因此,分类属性“分级”的信息熵为:
2.4.2 各条件熵
2.4.2.1 计算机相关工作且大学生入伍属性的熵
计算机相关工作且大学生入伍属性包括“Y”“N”两种取值。

表1 决策树样本数据集部分数据
计算机相关工作且大学生入伍为“N”的熵为:
计算机相关工作且大学生入伍属性的熵为:
E(计算机相关工作且大学生入伍)
2.4.2.2 计算机相关专业属性的熵
计算机相关专业属性包括“Y”“N”两种取值。
计算机相关专业为“Y”的熵为:
计算机相关专业为“N”的熵为:
计算机相关专业属性的熵为:
当李莉把交了两个月租金的出租屋让给许峰,自己投奔梅子的时候,梅子指着她的脑袋痛心疾首:“世界上最傻的女人就是你,许峰那个白眼狼,一看就是个攀高枝的。他骗你骗得高段啊,你走得那个顺溜啊。”

2.4.2.3 通过计算机等级考试属性的熵
通过计算机等级考试属性包括“Y”“N”两种取值。
通过计算机等级考试为“Y”的熵为:
通过计算机等级考试为“N”的熵为:
通过计算机等级考试属性的熵为:
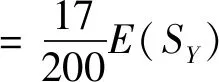
2.4.2.4 自我兴趣判断属性的熵
自我兴趣判断属性包括“A”“B”“C”三种取值。
自我兴趣判断为“A”的熵为:
自我兴趣判断为“B”的熵为:
自我兴趣判断为“C”的熵为:
自我兴趣判断属性的熵为:

2.4.3 各属性信息增益
Gain(计算机相关工作且大学生入伍)=1.4428-1.3904=0.0524
Gain(计算机相关专业)=1.4428-1.4027=0.0401
Gain(通过计算机等级考试)=1.4428-1.3716=0.0712
Gain(自我兴趣判断)=1.4428-1.3353=0.1075
由此可以得出,自我兴趣判断属性的信息增益最大,可选择该属性作为决策树的根结点。
2.4.4 生成决策树
依次进行一级、二级、三级分支结点的计算,得到决策树如图2所示。
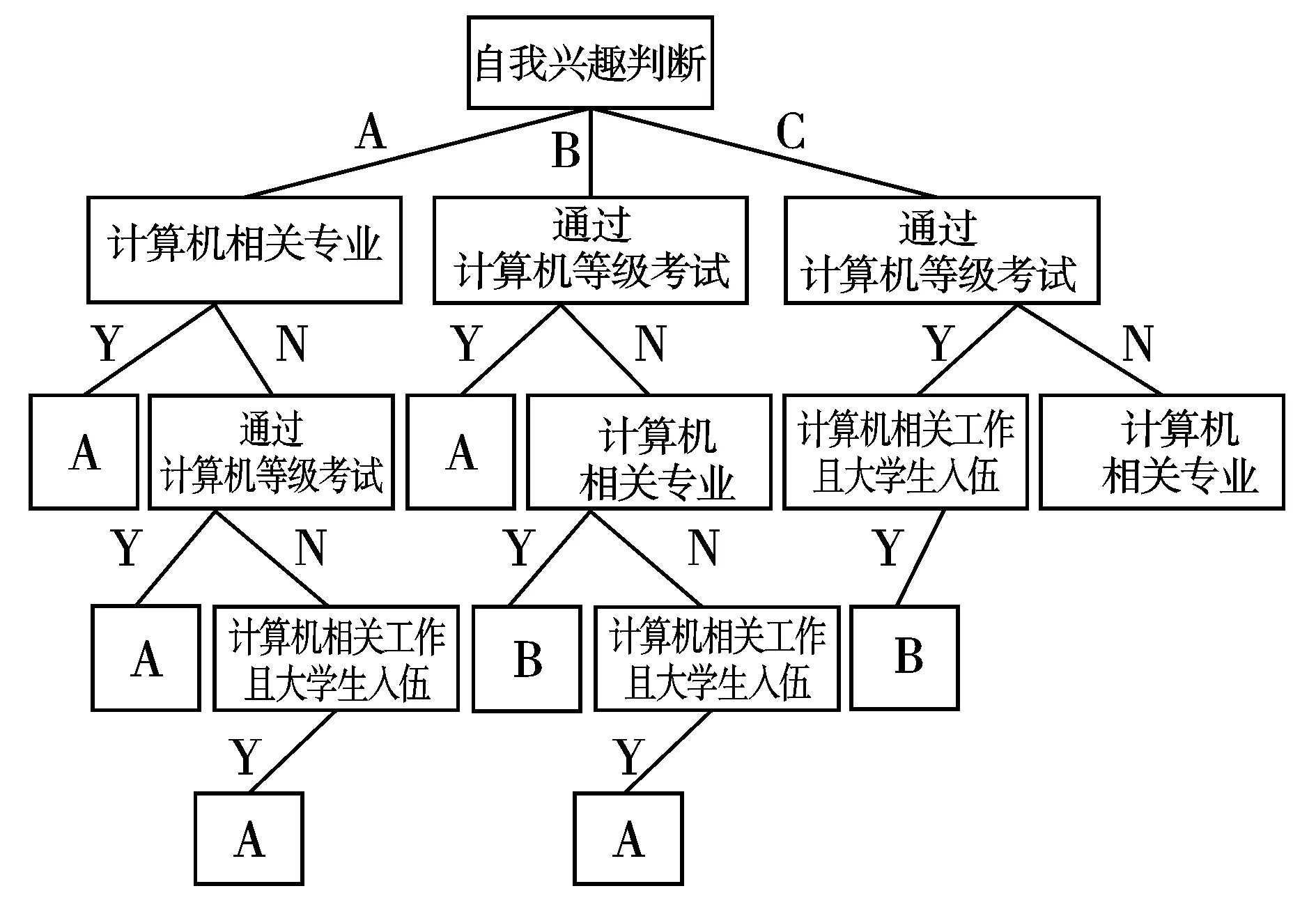
图2 初步生成分级教学决策树
2.4.5 完善决策树
为降低ID3算法多值偏向,计算前对训练数据集中各属性进行了简化,因此,其得出的决策树并未完成对所有记录的分级。此时,需要借助最简单的分数分级方法继续完善得到的决策树。完善后的决策树如图3所示。
3 结束语
慕课的开设,使大规模授课成为可能。随着选报人数的增多,用于学生分级的数据激增,也更具有多样性和复杂性。决策树的应用,可以将教师从大量数据分析工作中解放出来,以更充沛的精力投入教学,同时保证了分级的客观性和有效性。当然,学生的分级仅仅是分级教学的第一步,还涉及到教学模式、教学方法、教学目标、教学评价等的分级。数据挖掘在分级教学中的应用也不仅限于学生的分级,还可以用于教学动态分析、个性化教学策略、教学效果评价等方面。

图3 完善后最终生成决策树
