一种基于本体的数据共享服务模型
2019-12-12牟宇超刘瑞
牟宇超 刘瑞

摘 要:数据共享服务在信息化时代作用凸显,它可以将彼此孤立的信息进行整合并实现其应有价值。对数据共享服务进行研究,提出一种本体模型及其应用架构。详细阐述了模型中的几种对象及其相互转换方式,以及如何利用语义关系组织数据;将PageRank算法与CF算法思想移植到数据服务中,提出一种新的算法用于筛选最优数据;创建一种相对完备的本体体系,将数据共享过程分层细化,可应用于海量数据共享服务。
关键词:数据共享;本体模型;数据对象价值;共享服务
0 引言
随着信息化建设的不断推进,各行各业对信息交流服务的需求也与日俱增,人类社会正逐渐步入数据时代。世界著名咨询公司麦肯锡曾提到,“当今世界的数据量已呈现爆炸式增长态势”[1]。在面对如此大量的多样数据时,如何对数据进行有效处理,提高数据的价值与可用性尤为关键。
目前,多数数据以“信息孤岛”的形式存在,如果对这些数据进行有效融合,那么这些海量的碎片信息将变得更加具有利用价值。数据共享可以使人类对客观世界产生更深层次的认识[2],本文着重对数据共享方法进行探究,以解决当前信息不能充分共享的问题。
1 研究综述
1.1 关于本体
“本体”一词起源于哲学领域,该词由德国哲学家Goclenius[3]首先提出,许多其他学者也曾给出过“本体”这一概念的详细定义。1991年,Neches[4]最先给出了本体的定义:本体是构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成词汇外延的规则;1993年,Gruber[5]给出了本体的定义:本体是概念模型的明确的规范说明;1997年,Borst[6]给出了本体的定义:本体是共享概念模型的形式化规范说明;1998年,Studer[7]将前人思想进行融合,又重新提出了本体的定义:本体是共享概念模型的明确的形式化规范说明。如今,Studer提出的这一概念被广泛认同。
1.2 关于数据共享
国外数据共享相关研究中,部分学者提出具体算法用于解决数据冲突等各类问题,也有许多可用于数据共享的数据交换平台。哈佛大学和麻省理工学院共同研发的Dataverse可以发布、引用、存储和在线分析研究数据;麻省理工学院与惠普公司合作的DSpace可以实现数字资源的收集、保存、发布等;斯坦福大学的SDR同样可以实现数据的保存、引用、访问、管理和共享等功能[8]。比较流行的还有康奈尔大学与维吉尼亚大学合作开发的Fedora[9],挪威社会科学数据服务中心的Nesstar等[10]。
Brouwer等[11]提出了一種新的基于多矩阵分解方法的贝叶斯混合矩阵分解模型,该模型可融合多种类型的数据集;Tosin等[12]提出了一种方法,通过对Web应用程序中的信息进行推断和关联实现数据融合;Gubanov[13]认为传统的数据融合方法难以处理大规模数据,由此提出了一种大规模数据集成系统并阐述了其体系结构。
国内关于数据共享的研究也有一定进展,但并不多见。北京航空航天大学的张义等[14]提出了一种名为MICROS的多模式互联生长模型,较为详细地阐述了整个体系如何将多源异构的海量数据融合起来;复旦大学[15]研发了一款科学数据共享平台,该平台主要包含数据管理、数据服务、数据交换、数据监护等功能,旨在为研究人员提供一个便于相互交流的环境;北京航空航天大学的陈真勇等[16]提出了一种名为SCLDF的智慧城市数据融合与共享框架,给出了该框架的四层架构设计,并指出该框架可以结合具体的数据信息提供相应的智慧服务;谌裕勇[17]提出了一种基于关联规则挖掘的云存储中心多源文本主题融合模型,该模型可以对多源文本主题进行信息融合;刘铮等[18]提出了一种基于多源数据的多特征融合方法,主要解决弱小目标关联难题;路辉等[19]提出了一种基于HTTP协议的网页数据融合方法,旨在实现业务系统间的数据集成与数据共享;梁玉英[20]提出了一种基于概率犹豫模糊Frank加权平均算子的信息集成方法,并将其运用于数据产品选择。在国内外相关研究中,虽然数据共享方法多种多样,但基于本体模型实现数据融合与数据共享过程的研究十分罕见,并且也很少有研究论述如何利用语义关系完成数据的组织与推送。对此,本文提出一种数据服务的本体模型。
2 面向主题的数据共享本体模型
2.1 数据共享服务流程
在提供完整数据服务的平台体系中,需要完成数据的转换、清洗与融合等工作。对于异构数据,需要实现数据结构的转变;对于错误数据和重复数据,要及时完成清理;对于缺失数据,需要采取合适方法进行补全。在面对大量多源异构数据时,仅仅进行简单的转换只能满足最基本的数据交换功能,无法提供真正意义上的数据共享服务。因此,还需要根据主题领域内的知识对这些离散的数据进行融合,并在数据之间建立相应的语义关系形成主题数据库。在主题数据库中提取数据时,平台可以自动地为数据需求者提供更多有价值的信息,使他们不必浪费时间亲自寻找所有数据,为使用者带来十分便捷的数据服务。
图1展示了数据服务的完整流程。从数据源中获取原始数据后,首先要对其进行预处理,完成数据清洗工作。清洗过程除了过滤掉错误数据和重复数据外,有时可能还需要一些简单的转换工作,保证数据全部转变为统一的可用于后续处理的格式。数据源中的原始数据经过预处理后得到松散数据集,此时的数据集只经过初步加工,并不一定具备完整的结构。为实现最后的数据共享服务,需要对初步处理过的数据集进行再次加工,即融合过程。数据融合过程需要专家参与,在确定数据服务所要面向的主题领域后,该领域相关专家制定相应的融合策略,用以指导数据融合过程。松散数据集经过融合过程后形成面向主题的数据集,面向主题的数据具有特定的结构,便于提供数据服务。为形成所需的主题数据库,还需要定义数据间的语义关系,用语义关系将各类数据相互关联起来,即关联过程。关联过程同样需要领域专家参与,专家要确定各数据类型间的语义关系,形成新的数据网络,使各类数据不再孤立。
在形成主题数据库后,可向数据需求者提供全部数据服务。当数据需求者发出查询请求后,数据服务平台在主题库中查找相应信息,提供尽可能准确的数据信息。数据服务平台除提供数据共享服务外,还提供数据迁移服务与数据交换服务。数据迁移服务是指将一个库中的数据信息迁移到另一个库中,该项服务不对数据进行加工,要求保留数据的完整信息,但可能有一些简单的转换。数据交换服务是指从松散数据集中抽取数据提供给数据需求者,这些数据只经过初步加工,并不具备完整的语义,但去除了无用信息,除清洗过程外还可能需要一些简单的合并与转换。
2.2 本体模型中的对象及相互关系
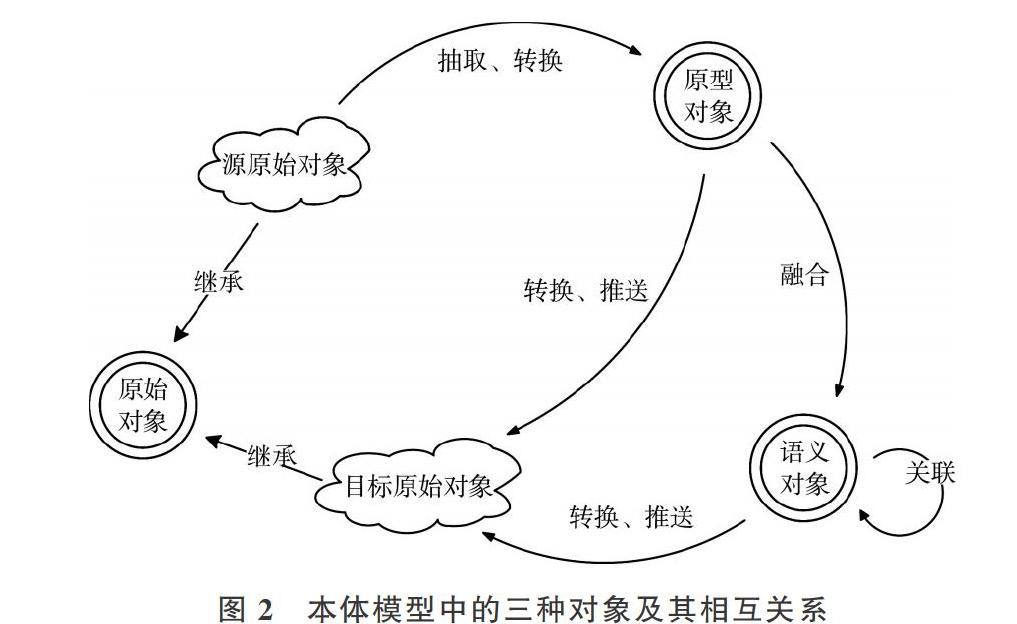
为实现上述功能,本文提出了一种基于本体的数据服务模型,模型中总共含有3类对象,分别为原始对象(Original Object)、原型对象(Prototype Object)和语义对象(Semantic Object)。其中,原始对象指平台系统外的数据集。原始对象又可以进一步划分为源原始对象与目标原始对象:源原始对象指平台系统的数据源,即数据提供方;目标原始对象指平台系统的数据输出端,即数据需求方。源原始对象与目标原始对象均继承自原始对象。原型对象指平台系统中经过初步加工后的数据对象,这类对象已经可以被利用,但还不具备特定的结构,也不具备语义关系。语义对象指具有完整语义关系的数据对象,所有语义对象在一起共同形成主题数据库,平台系统依靠主题数据库提供完整的数据服务。
图2详细表述了3种对象间的相互关系。系统运作时,源原始对象中的数据经过抽取和转换过程形成新的原型对象中的数据。若只完成简单交换,则原型对象中的数据经过转换后直接被推送给目标原始对象;若需要进行更多的数据分析,则原型对象中的数据经过融合过程转变为新的语义对象中的数据。不同的语义对象之间需要相互关联,建立一定的语义关系,语义对象中的数据在经过转换后最终被推送给目标原始对象。
其中,任意两个语义对象之间都可以存在关联联系,这种关系是有向的,并且具有特定的语义。对于任意两个语义对象A和语义对象B,用A→B表示A对象关联到B对象的语义关系,A对象与B对象之间既可以是A→B,也可以是B→A,还可以是A→B与B→A同时存在,要求A→B与B→A语义不相同。
这种关联关系本质上描述了两个对象在语义层面的联系,有了这种关系网络后,数据共享阶段将获得更为完整的数据信息。在数据共享服务过程中,当任何一个语义对象将要被提取时,其指向的语义对象也有可能成为反馈信息中的一部分被推送出去,关联的语义对象被推送时,应采用合适的方法。
語义对象还可以拥有主子结构,但只有结构的主部分具备全局性的唯一标识。此外,内部语义对象(子语义对象)将被定义为非公开的,即对数据利用环节不可见。因此,对主子结构语义对象的访问需逐层进行。
2.3 本体模型应用架构
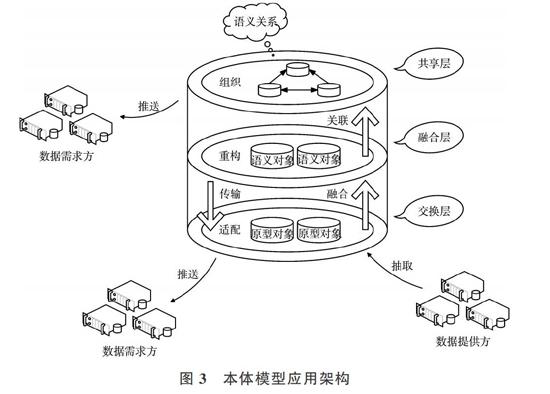
本体模型的应用架构可分为3层:交换层、融合层、共享层。图3展示了该架构的层次,其中交换层为最底层,融合层为中间层,共享层为最顶层。这3层的功能分别为:①交换层负责完成数据适配工作,对数据源中的数据进行抽取、转换,将处理好的数据存放在原型对象中;②融合层负责完成数据重构工作,将原型对象中的数据进行融合后存放在相应的语义对象中,构建好所有语义对象;③共享层负责完成数据组织工作,将所有的语义对象进行关联,组织好所有语义对象间的语义关系。
3 原始对象提炼
本文所定义的本体模型中,原始对象即是对数据服务平台外部的数据源中数据的一种抽象。原始对象有一个基本类型,将其命名为OriginalObject,原始对象中所有的类均继承自OriginalObject。从数据源中抽取数据时,需要定义一些新的类,它们都是基本类型OriginalObject的衍生类(子类)。这些类可以被实例化,而每一个实例则是对相应数据的一种映射。
事实上,原始对象的创建主要是为了解决实际工作中数据源的异构问题。每从一种类型的数据源中抽取数据时,都要定义一种新的类。由于在提供数据服务的过程中,要处理的数据可能是结构化的,也可能是非结构化的,或是半结构化的,因此需要将它们转变为统一的可处理的形式。类中所具有的各种属性即是相应数据源中数据结构的一种呈现,例如对于XML文件,类中的属性可能映射为其中的子节点。对于平台外部的数据源,需要进行处理的不只有二维表形式的数据,还可能有HTML格式的网页,以及其它格式的各类文件与图片等。
理论上,原始对象中应该保留数据源中的全部数据信息,其存在的意义主要是方便在后续工作中对抽取到的数据进行处理。也可以将原始对象看作是数据源中的数据,其本质就是将数据源中的数据转移到数据服务平台中,以便对其进行操作。
4 本体对象间的转变方式
在原始对象向原型对象转变的过程中,有抽取和转换两个关键步骤。抽取可以是将原始对象中的数据信息直接复制,也可以是经过清洗后保存一部分数据信息,而转换则是将数据转变为统一的可用于后续处理的格式。在原型对象向语义对象转变的过程中,需要对原型对象进行融合。
图4为无过滤的平行扩展方式。在这种方式中,原始对象中的数据信息均完好无损地存入新的原型对象中,原型对象中的数据信息在被合并后存入新的语义对象中。原始对象[O1]与原始对象[O2]经过抽取、转换过程生成原型对象[P1]与原型对象[P2],所有属性全部被保留,原型对象[P1]与原型对象[P2]经过融合过程生成语义对象[S1],依然保留了全部属性。
图5为有过滤的平行扩展方式。在这种方式中,原始对象中的数据信息可能被清洗后存入新的原型对象中,原型对象中的数据信息在被合并后存入新的语义对象中。原始对象[O1]与原始对象[O2]经过抽取、转换过程生成原型对象[P1]与原型对象[P2],其中部分属性被去掉,原型对象[P1]与原型对象[P2]经过融合过程生成语义对象[S1],但也只保留了部分属性。
图6为主子结构扩展方式。在这种方式中,原始对象中的数据在抽取过程中同样有可能被清洗后存入新的原型对象中,或是不经过清洗全部被保留,此处不再全部列举,而原型对象在经过融合过程后形成新的具有主子结构的语义对象。原型对象[P1]与原型对象[P2]经过融合后生成新的语义对象[S1],语义对象[S1]除保留原型对象[P1]中的信息外,还新增了属性[g],该属性用来指向一个内部语义对象[I1],语义对象[I1]即是语义对象[S1]的子语义对象,该对象中存储了原型对象[P2]中的信息。
5 语义关系构建
在语义对象之间要建立语义关系。语义关系采用四元组表示,如语义对象A到语义对象B的语义关系记为(A, relationship, B, weight)。每一个四元组都用来记录一个语义关系,该四元组表示了语义关系的方向为从A指向B,四元组中第二个元素relationship用来记录语义关系的名称,最后一个元素weight表示语义对象B对语义对象A的影响程度。
语义对象有一个基本类型,这里将其命名为SemanticObject,本文语义对象的所有其它类都是该类的衍生类(子类),它们均继承自SemanticObject。假设现在有两个语义对象类ClassA与ClassB均继承自SemanticObject基类,如果定义了一种语义关系(ClassA, r1,ClassB,w1),那么每个ClassA类型的实例都可能会具有一个指向ClassB类型实例的语义关系。当然,并不一定所有ClassA类型的实例都会发出这种语义关系,可能有些ClassA类型的实例还没有找到与自身对应的ClassB类型的实例。
在定义两个类间的语义关系时,并未建立具体实例间的语义关系。语义对象实例间的语义关系,可以通过两种途径建立。第一种方法即是在创建某个具体实例时,也直接生成从该实例对象发出的语义关系,在这种方式中,语义关系伴随着两个实例对象的出现也直接出现。第二种方法需要建立语义关系的生成规则,这个规则很重要,它用于生成第一种方法中未能创建的那些语义关系。在创建主题数据库时,需要在初始化过程中将全部语义关系生成规则加载一遍,然后对库中的所有实例对象进行扫描,根据已有规则为所有满足条件的语义对象创建语义关系。当然,在使用第二种方法后,可能依然存在一些对象实例没有创建完对应的语义关系,因为它们并不满足生成规则中的条件。
利用生成规则建立语义关系的方法可用一个简单示例说明。假设有若干个库房与若干个机器人,现在主题数据库中并未记录每个机器人服务于哪个库房,为确定各库房与各机器人之间的关系,可定义一个语义关系生成规则。
6 共享服务中最优数据筛选
随着可利用的数据源逐渐增多,在主题库中形成的数据网络体系也会越来越庞大。尤其是当数据服务平台应用于智慧城市建设时,主题库内部需存储海量数据。有时,数据需求者可能并不知道现实中还存在一些数据同样是他们想要的,此时数据服务平台应能够为其提供这些有价值的数据。在面对纷繁杂乱的数据网络时,如何筛选出相对准确的数据信息推送给数据需求者尤为关键。
关于如何在数据共享服务中合理推送数据的问题,本文借鉴了PageRank算法与推荐系统中CF算法思想。PageRank算法堪称十分天才的算法,它只利用了很简单的数学原理但效果非常显著。该算法是曾经就读于美国斯坦福大学的Larry Page和Sergey Brin在参考了学术界评判论文的方法后共同提出的。此二人亦是Google公司的创始人,凭借发明的PageRank专利创造了全球最大的搜索引擎——Google。CF算法全称为协同过滤算法(Collaborative Filtering),本文主要采用基于物品的CF算法(Item-based Collaborative Filtering),该算法由Amazon公司的工程师提出,同样是一种简单易用的算法。Amazon是推荐系统领域最为著名的公司,在业界更是享有“推荐系统之王”的称号。
6.1 语义对象价值计算
在数据共享服务中,当用户提取数据时,有时很难鉴别哪些数据对用户将是有价值的,只凭借查询条件或许很难筛选。然而,数据推送原理很简单:任何数据如果被提取得十分频繁,那么其价值一定是相对较高的。一般地,可以认为数据被提取的次数越多,其价值就越高。因此,本文假设每条数据的价值与其被提取次数成正相关。
但在主题数据库中,各语义对象间相互关联,在访问一个数据对象时也会访问其关联的数据对象。于是,有些数据对象在被数据需求方提取时,很有可能是因为其关联了价值很高的其它数据对象,在这种情况下,该数据对象能被利用要部分归功于它所关联到的数据对象。因此,每个数据对象的价值还与关联到该对象的其它数据对象有关。
6.2 语义对象相似度計算
在提供数据共享服务过程中,除计算数据价值外,还需要利用基于物品的协同过滤算法。采用该算法的目的是找出所有与被提取对象相似的其它语义对象。
利用每个语义对象被所有用户提取的次数,可以计算出任何两个语义对象间的相似度。当用户提取某个数据对象时,可以将与其相似度最高的几个对象一并推送给用户。在计算两个语义对象间的相似度时,需要用一个二维矩阵记录每一个语义对象被所有用户提取的次数。
如图8所示,虽然不能直接判断出哪些语义对象是真正意义上的相似,但依据所有数据需求者的提取行为可以看出,语义对象[S1]与语义对象[S3]很可能是相似的。于是,采用这种方法可以近似求出最相关的一类对象。
由于这种方法找出的相似语义对象并不一定真的对用户十分有价值,因此在最终进行推送时,需要完成两个步骤:①找出与被提取数据对象最相似的一部分语义对象;②在这些语义对象中,按[V]值排序筛选出价值最高的一些对象推送给数据需求者。
关于步骤①中筛选相似语义对象的策略,可以有两种方案:一是预先指定一个具体的数量,以限制要提取相似语义对象的多少;二是预先指定一个阈值,相似度在阈值范围内的语义对象将被提取出来。
6.3 冷启动问题
上述方案虽然能够找出与用户需求相适应的数据对象,但依然无法解决冷启动(Cold Start)问题,那些新加入主题数据库而价值又很高的数据,并不能得到其应有的[V]值,该算法对于这类语义对象并不十分友好。
为解决数据服务中的冷启动问题,可以考虑利用元数据对每个数据对象进行分析。元数据即为描述数据的数据,在创建语义对象时,也应为每个对象添加相应的元数据,这相当于为所有对象打上了“标签”。当两个语义对象元数据中的信息相似时,可以认为这两个语义对象在领域内是相似的。
此外,还可以让领域专家为新引入主题数据库中的语义对象定义临时价值[Vtemp],在一定时间[t]内,将[Vtemp]作为其价值使用,这就避免了有些语义对象价值很高但其[V]值为[0]的问题。等到时间[t]结束时,再按照上述方法重新计算该语义对象应有的[V]值,[Vtemp]将不再起任何作用。
7 结语
本文构建了一个相对完整的本体体系,即先將各类数据抽象成为3种对象,然后利用构建好的模型,定义各类术语及其相互关系。在构建好的本体体系下,各类数据对象间的关系将变得更加直观,各层所要执行的任务将变得更加明确,这有利于对海量的多源异构数据进行后续处理与分析。
此外,本文还提出了一种新的算法计算数据对象的价值,同时计算数据对象间的相似度。在推送数据的过程中可以更加容易地判断哪些数据应该优先被选取,这使得在共享数据时不再只是简单地提供原始数据,而是提供主题数据库中更加丰富的数据。
本文基于本体的模型为数据共享服务提供了新的思路,在构建任何一种数据服务平台,尤其是处理海量数据时,可以将该模型作为框架进行各模块的搭建。
参考文献:
[1] NATURE.Big data[EB/OL]. [2013-06-17]. http://www.nature.com/news/specials/bigdata/index.html.
[2] 孟小峰,杜治娟. 大数据融合研究:问题与挑战[J]. 计算机研究与发展,2016,53(2):231-246.
[3] 高建波. 本体模型及其在信息安全评估领域的应用研究[D]. 上海:上海交通大学,2015.
[4] NECHES R. Enabling technology for knowledge sharing[J]. AI Magazing,1991,12(3):36-56.
[5] GRUBER T R. A translation approach to portable ontology specification[J]. knowledge Acquisition,1993,5(2):199-220.
[6] BORST W N. Construction of engineering ontologies for knowledge sharing and reuse[J]. Universiteit Twente,1997,18(1):44-57.
[7] STUDER R,BENJAMINS V R,FENSEL D. Knowledge engineering: principles and methods[J]. Data & Knowledge Engineering,1998,25(1-2):161-197.
[8] Collections in the SDR [EB/OL]. [2016-12-26]. https://lib.stanford.edu/sdr/aboutsdr.
[9] Fedora commons proposal to the gordon and betty moore foundation[EB/OL]. [2016-12-07]. https://duraspace.org/fedora/about/.
[10] 张闪闪,王铮. 海外基于开源软件的典型科研数据共享服务平台案例研究[J]. 图书情报工作,2017,61(6):79-86.
[11] BROUWER T,LIó,PIETRO. Bayesian Hybrid Matrix Factorisation for Data Integration[C]. AISTATS,2017.
[12] TOSIN T, RIGO S J, BARBOSA J L V, et al. A model for data integration in open and linked databases with the use of ontologies[C]. Chile:2016 35th International Conference of the Chilean Computer Science Society(SCCC),2016.
[13] GUBANOV M. PolyFuse:a large-scale hybrid data fusion system[C]. San Diego:2017 IEEE 33rd International Conference on Data Engineering (ICDE),2017.
[14] 张义,陈虞君,杜博文,等. 智慧城市多模式数据融合模型[J]. 北京航空航天大学学报,2016,42(12):2683-2690.
[15] 张计龙,殷沈琴,张用,等. 社会科学数据的共享与服务——以复旦大学社会科学数据共享平台为例[J]. 大学图书馆学报,2015,33(1):74-79.
[16] 陈真勇,徐州川,李清广,等. 一种新的智慧城市数据共享和融合框架——SCLDF[J]. 计算机研究与发展,2014,51(2):290-301.
[17] 谌裕勇. 云存储中心多源文本主题融合模型研究[J]. 智能计算机与应用,2019,9(2):148-151.
[18] 刘铮,毛宏霞,戴聪明,等. 基于多源数据多特征融合的弱小目标关联研究[J]. 红外与激光工程,2019(2):1-7.
[19] 路辉,高尚飞,李少龙. 基于HTTP协议的业务系统网页数据采集应用集成[J]. 电子技术与软件工程,2019(2):1-3.
[20] 梁玉英. 基于概率犹豫模糊信息集成算法的数据产品选择[J]. 计算机工程与应用,2019(3):219-224.
(责任编辑:孙 娟)
