基于GR-CNN算法的网络入侵检测模型设计与实现
2019-12-12池亚平杨垠坦李格菲王志强
池亚平 杨垠坦 李格菲 王志强 许 萍
1(西安电子科技大学通信工程学院 陕西 西安 710071)2(北京电子科技学院通信工程系 北京 100070)
0 引 言
近年来计算机网络技术发展迅速,对社会发展做出了巨大贡献,人类活动也越来越依赖网络。云计算技术的出现使网络规模迅速增长,网络面临的安全威胁也日益严峻,这些威胁可能是灾难性的,例如,拒绝服务式攻击(DoS),会通过引入不必要的流量拒绝或阻止合法用户访问网络资源,从而导致网络瘫痪[1]。这也吸引了很多研究人员展开相关研究。国内外相关学者指出网络入侵检测系统(NIDS)是保障网络安全的重要一环,可以主动并及时地检测到云平台中系统、应用程序和网络中存在的异常行为,对于提升云平台的安全性有很大的帮助[2-3]。
通常来讲网络入侵检测系统可以分为基于特征检测和基于异常检测两类。基于特征的NIDS最大的问题就是无法识别未知的攻击,显然这并不适用于如今复杂异构网络环境[4]。基于机器学习(ML)或深度学习(DL)的网络入侵检测模型通过学习已有正常和异常的网络行为实现对未知网络行为的分类和预测。目前国内外相关研究人员已成功将基于ML/DL的方法应用于网络入侵检测领域。文献[5]提出了CANN算法,选取KDD-Cup99数据集中的六维数据特征进行训练并测试了Prob、Dos、R2L、U2R四种攻击,其入侵检测算法具有较高的准确率。文献[6]提出了一种基于细菌觅食优化算法(BFOA)和K-means算法复合的入侵检测算法,优化了K-means算法聚类不稳定的问题,采用KDD-Cup99数据集进行验证,入侵检测准确率可达98.33%。文献[7]提出一种二次训练入侵检测模型,分别将决策树、朴素贝叶斯和K最邻近算法(KNN)算法应用于该模型,在KDD-Cup99数据集上取得了较好的效果。文献[8]提出了基于人工神经网络(ANN)的入侵检测算法,并对该模型进行了DDoS/DoS攻击测试,准确率可达99.4%。文献[9]提出了一种基于深度信念网络(DBN)和极限学习机(ELM)结合的深度学习混合模型(DBN-ELM),采用KDD-Cup99数据集作为实验数据集,其入侵检测模型准确率可达97.5%。文献[10]提出了基于卷积神经网络(CNN)的入侵检测算法,与传统算法相比具有较高的准确率。
经研究文献发现,在基于ML/DL的网络入侵检测算法中,为了提高入侵检测效率,一般采用多种算法结合的方式建立模型。可将这种网络入侵检测方法分为两过程,即先通过一种算法筛选数据集的数据特征,再采用另一种算法对筛选后的特征数据进行分类,这种方式在提升准确率的同时有效减少了运算量[11]。文献[12]指出卷积神经网络具有强大的分类和泛化能力,但是因为卷积神经网络在处理高维度数据时,存在计算量过大和输入转化的问题,因此很少被应用于网络入侵检测领域。文献[10]虽用到了卷积神经网络但并没解决计算量较大的问题。鉴于此,本文提出一种基于增益率算法和卷积神经网络算法(GR-CNN)的入侵检测模型。通过计算输入特征的增益率,筛选出对结果影响较大的数据特征。CNN通过挖掘数据特征间的关联特征提取特征向量,再根据特征向量实现对正常和异常行为识别和分类。最后使用入侵检测领域常用的KDD-Cup99数据集进行对比实验。
1 相关技术研究
1.1 网络入侵检测技术
网络入侵检测技术是一种主动防止网络攻击的安全手段,通过对计算机网络中的网络数据进行提取和分类,来判断网络中是否存在异常行为[4]。网络入侵检测是一种积极主动的安全防护技术,通过搜集网络关键节点中的原始数据包作为数据源并对这些数据从流量等方面进行分析,检测网络中是否含有违反安全策略的行为或系统存在被非法攻击的迹象。入侵检测系统具有实时性、主动性和动态性等优点,能有效弥补其他静态防御工具的不足。图1为网络入侵检测模型,其原理是通过在网络节点上进行侦听并分析数据包来检测是否发生入侵行为,其中数据分析过程是整个入侵检测模型的核心。

图1 网络入侵检测模型
根据入侵检测所使用的分类技术来区分,入侵检测主要可分为特征检测和异常检测[12]。特征检测通过建立特定类型的数据库,把网络中收集到的相关数据与已知类型的网络入侵的数据库进行匹配操作,如果匹配成功,则认为发生入侵。特征检测只能检测到已知的入侵,无法识别新的入侵方式。异常检测是根据用户的行为或资源的使用情况分析是否发生入侵事件,是基于行为的检测。基于机器学习的入侵检测通常属于异常检测[4]。
1.2 卷积神经网络技术
卷积神经网络是一种前馈神经网络,目前已成为众多科学领域研究的热点之一,特别是在模式分类领域。图2为卷积神经网络模型图,通常包括数据输入、特征提取和分类输出三个过程。卷积神经网络的核心是经过多次卷积采样生成特征向量,最终根据特征向量完成分类。
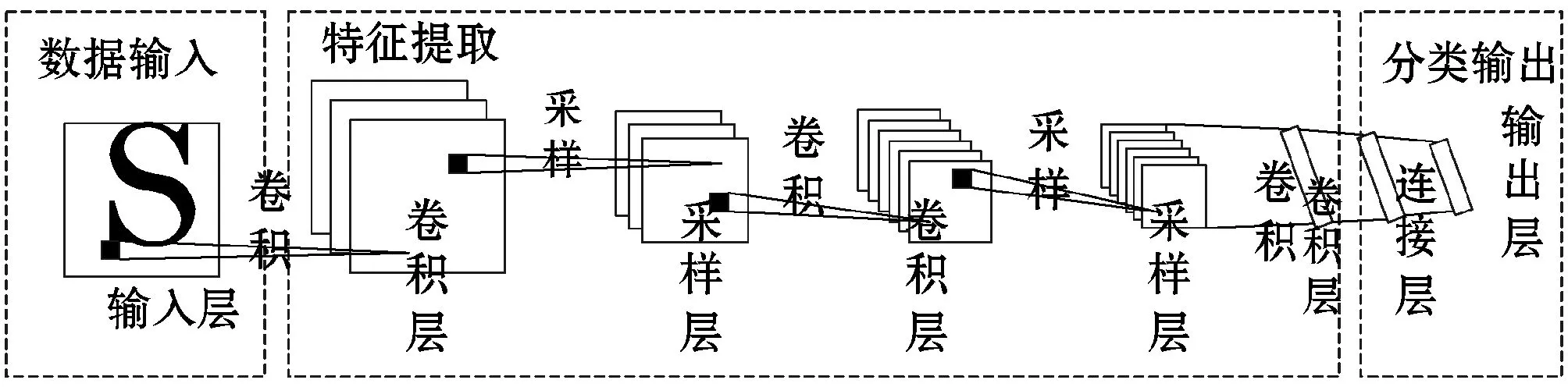
图2 卷积神经网络模型图
2 基于RG-CNN的入侵检测模型
2.1 模型设计
入侵检测模型的关键是数据分析过程,因此本文在数据分析过程中设计入侵检测算法。图3为本文设计入侵检测算法总体架构图,可分为三个模块:数据预处理模块、特征选择模块、CNN入侵检测模块。在数据预处理模块负责对数据集进行数字化、标准化、归一化处理;在特征选择模块,通过计算数据集增益率筛选特征数据;CNN入侵检测模块,要先对输入的向量数据进行类图像化处理,然后采用训练数据集训练神经网络模型,最后通过测试数据集检测入侵检测结果。

图3 入侵检测算法总架构图
2.2 特征选择模块设计
CNN模型训练过程中,因为要进行大量的卷积运算,因此会产生大量中间数据,从而导致模型训练速度较慢。减少卷积神经网络模型的中间参数量是提升CNN模型训练速度的关键,而输入数据的维度直接影响中间参数量,因此如何选择出数据集中最优数据特征非常重要。在机器学习中常用纯度来选取特征。纯度的衡量一般用信息增益和增益率,增益率是信息增益的优化,解决了信息增益对取值数目较多的属性的偏好性。本文所用数据集的不同数据特征的属性数目差异较大,因此更适合用增益率进行特征选择。增益率定义为:
(1)
其中:
(2)
式中:IG(D,a)表示“信息增益”,D为样本集合,假设属性a有V个可能的取值{a1,a2,…,aV},采用属性a对样本取值,会产生V个不同的种类,假设其中第v个种类包含了D中所有在a上取值为av的样本记为Dv,IV(a)称为属性a的“固有值”,属性a的种类越多,IV(a)值就会越大[13]。
本文根据不同特征数据的增益率进行特征筛选,测试了不同维度的特征对入侵检测识别率的影响以及在这种选择下对卷积神经网络模型训练时间的影响。
2.3 基于CNN的入侵检测模块设计
入侵检测模型中的CNN入侵检测模块是实现入侵检测核心。CNN模型的训练包括正向传递和误差逆向传播两个阶段,在分类输出过程和特征提取过程都有所体现。图4为CNN入侵检测模块训练流程图,先通过正向传输得到预测结果,然后计算误差,最后经过误差逆向传播更新模型参数,经过迭代得到最终的CNN入侵检测模型。
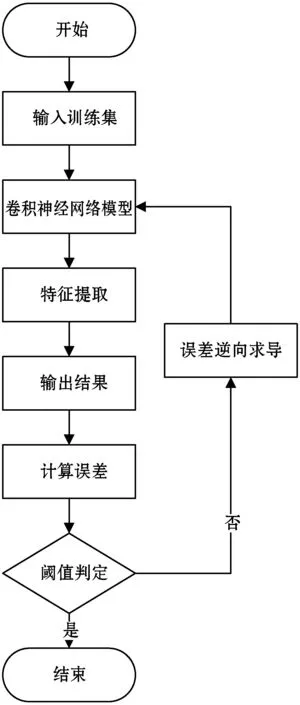
图4 CNN入侵检测模块训练流程图
(1) 分类输出过程 分类输出过程本质上是采用全连接神经网络将特征提取层输出的一维特征向量分类学习,它的前向传导可表示为:
c(l+1)=w(l+1)a(l)+b(l+1)
(3)
a(l+1)=f(c(l+1))
(4)
式中:l=1,2,…,L,L是输出层神经网络总层数,a(l+1)表示l+1层输出,c(l+1)表示l+1层输入加权和向量,f(x)是激励函数,w(l+1)是l+1层权重,b(l+1)是l+1层偏置。
神经网络参数更新的本质是误差逆向传播,假设误差函数为J(w,b)。在全连接神经网络中,参数更新的向量表达式为:
(5)
(6)
式中:α是学习率。由链式求导法则可得:
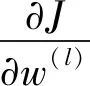
(7)
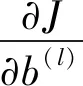
(8)
式中:
(9)
式中:δ()被称为能量函数,根据式(5)-式(9)经过L次迭代计算最终可得到输出层所有参数更新。
(2) 特征提取过程 在特征提取的正向传递阶段,特征提取过程中输入数据分别与不同的卷积核做卷积运算,得到特征矩阵。因为每层卷积运算,输入特征图都会与不同的卷积核做卷积运算,定义⊗为卷积运算,那么卷积过程可以表示为:
(10)
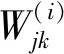
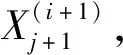
(11)
式中:subsampling(x)是采样函数,通常取窗口区域的最大值或均值,采样过程中本文所用乘性偏置量为1,加性偏置量为0。经过多次卷积、采样操作,最终生成一个一维的特征向量。
在误差逆向传播阶段,也通过误差函数的逆向求导更新神经元参数。相比于特征提取阶段的不同之处在于,因存在采样层使得矩阵维度减少,因此δ(i+1)需要上采样为卷积层的矩阵维度,引入上采样函数up():
δ(i)=f′(c(i+1))°up(δ(i+1))
(12)
式中:“°”表示每个元素相乘。类似于分类输出过程可以求得参数更新公式如下:
(13)
(14)
式中:(*)st表示遍历*所有元素;α是学习率。
3 实 验
3.1 数据预处理
本文所采用的数据集是KDD-Cup99数据集,是美国国防部高级规划署通过收集90 000个网络连接和系统审计数据,形成KDD-Cup99数据集,是入侵检测领域经典的数据集。由训练集和测试集两部分组成。训练集中的每个向量都是42维,其中前41维是特征,后1维是标记位。训练集由22种异常(attack)样本和正常(normal)样本构成。测试集中每个向量都有41维特征,由39种异常(attack)样本和正常(normal)样本构成,其中包括17种未知异常样本。这39种异常样本可以分为4大类:DoS(拒绝服务式攻击);U2L(来自远程主机的未授权访问),U2R(未授权的本地超级用户特权访问);Probe(扫描攻击)。本文使用10%的数据集训练模型,其数据分布如表1所示。
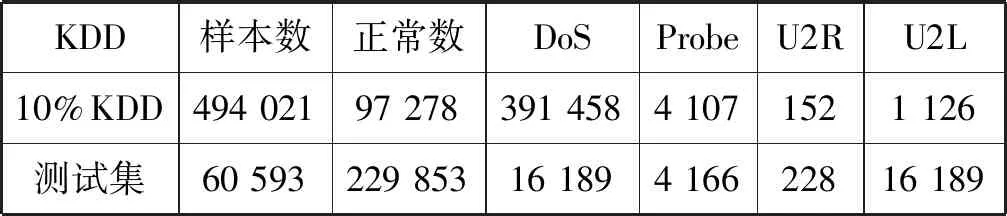
表1 数据集数据分布表
在数据集的41维特征中有38个数值型特征和3个符号型特征,因此首先将符号型特征数字化。考虑到数据特征可按离散和连续划分,因此需要针对卷积神经网络的输入数据的预处理,又因为激活函数输入数据靠近零点时收敛较快,最好让输入数据是靠近原点的浮点数据,因此需要先对连续型数据特征标准化处理再对离散型特征做归一化处理。
(1) 符号特征数字化 需要数字化的特征包括3个符号型特征和标记,3个符号型特征分别是:protocol_type特征、flag特征、service特征。protocol_type特征包括三种符号:TCP、UDP、ICMP,本文分别用数字1、2、3表示。同理,service特征有70种符号,因此分别用1~70的正整数表示。flag特征有11种符号,可分别用1~11的正整数表示。标记位有23种,可分为五类:Normal、DoS、Prob、U2L、U2R,分别用0、1、2、3、4来表示。
(2) 连续数据标准化 数据集41维特征中有22个是连续型的特征,而这22个不同连续属性不仅取值范围不同而且取值方式也不同。同时因卷积神经网络的激活函数采用tanh()函数,tanh()函数其分布以零点为中心左右皆有分布,因此针对连续型属性可采用,使数据取值在零点附近,这样既规范了数据集取值范围,而且因激活函数取值在零点附近斜率的绝对值较大,故可加速卷积神经网络模型收敛速率。标准化公式如下:
(15)
式中:x是原始数据;μ是样本均值;σ是样本的标准差;x*是标准化后的数据,服从均值为0方差为1的正太分布。
(3) 离散数据特征归一化 为了提高算法效率,特征选择过程中将所有离散数据特征归一化。同样,为了提升卷积神经网络收敛速度且消除量纲差异带来的影响,对其他19个离散特征做归一化处理。归一化公式如下:
(16)
式中:x是特征的原始数据,xmin是每个特征的最小值;xmax是每个特征的最大值,x*是归一化输出,最终每个特征的取值都在[0,1]。
3.2 实验环境及评估方法
本文在Linux环境下采用Tensorflow深度学习框架,Tensorflow是谷歌研发的人工智能系统,采用基于数据流图的计算,广泛地应用于机器学习或深度学习领域,Tensorflow支持英伟达图形显卡加速,故本文采用Python语言编写算法。本文所用硬件型号如表2所示。
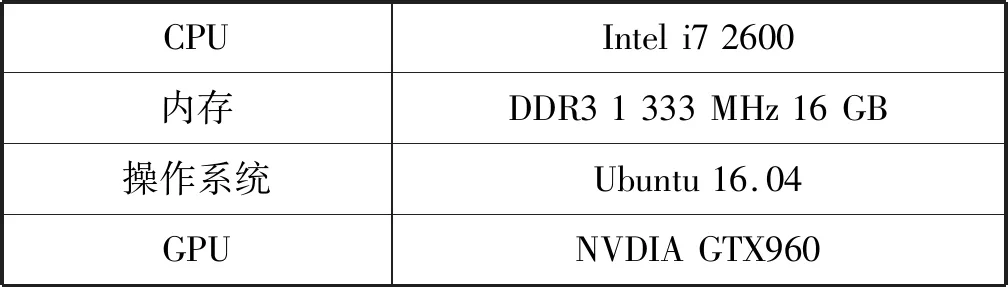
表2 实验硬件配置
本文所用入侵检评估标准为准确率(AC)、误报率(FP)、召回率(Recall)。
(17)
(18)
(19)
式中:TN表示被正确分类的正常行为样本数量;TP表示被正确分类的异常行为样本数量;FP表示被错误分类的正常行为样本数量;FN表示被错误分类的异常行为样本数量。表3展示了各种分类情况。

表3 实验结果分类
3.3 实验结果与分析
本文采用10%的KDD-Cup99数据集作为数据集,首先通过计算数据集中不同特征的增益率筛选特征,截取增益率最高25个特征如表4所示。
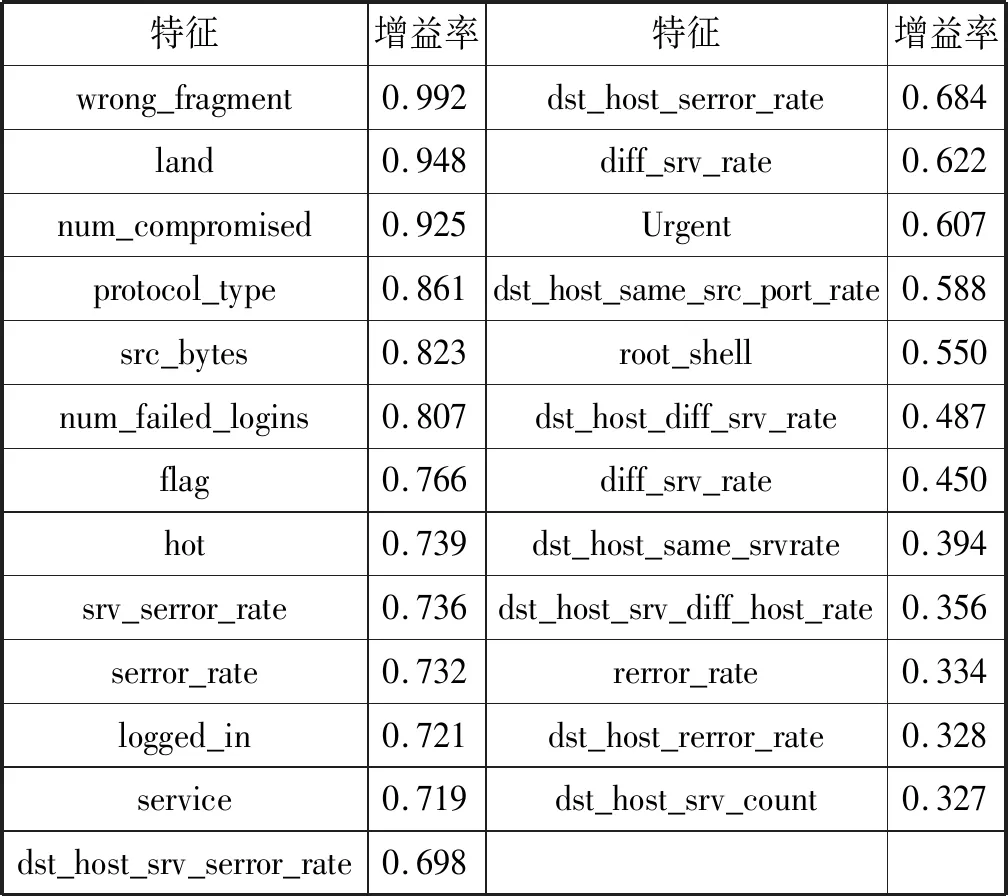
表4 不同数据特征的增益率
表5所示为本文搭建神经网络参数项,其中n表示输入数据类图像化处理后的宽度。本卷积神经网络模型中有两个卷积层一个采样层,卷积核大小为3×3,步长设置为1,池化层的长和宽都设置为2,步长为2,采样函数为Max_pool(),激活函数为tanh(),采用Adam()算法优化误差逆向传播,采用softmax算法作为输出。
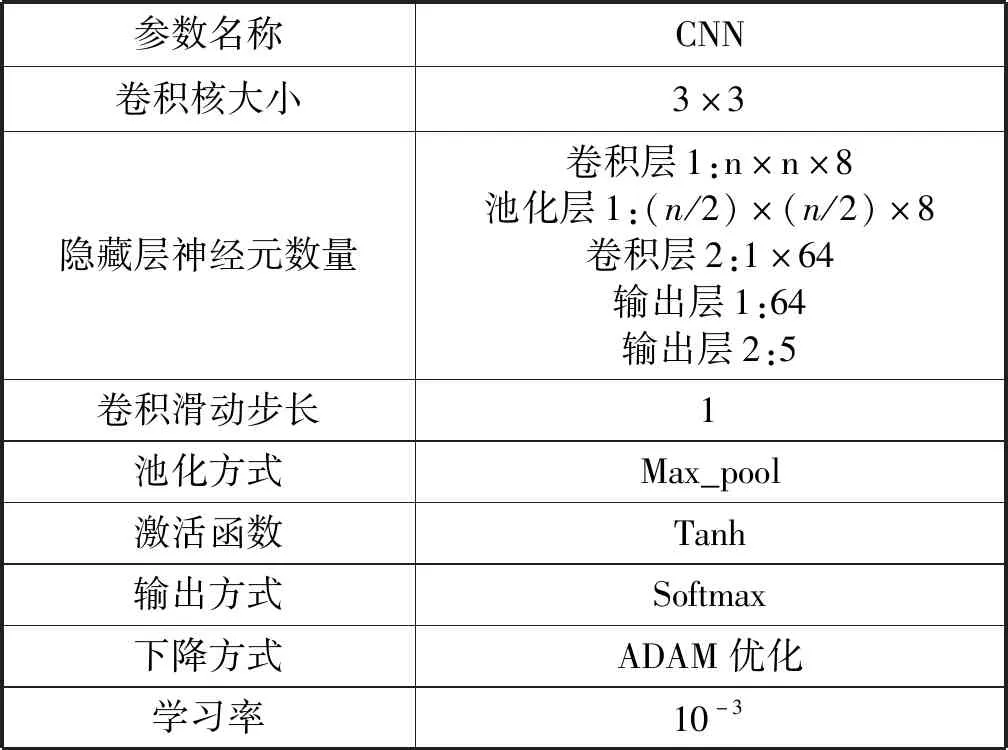
表5 神经网络参数
本文根据输入数据不同特征的增益率来选择输入数据,用训练数据集训练得到四种不同的攻击方式对应准确率如表6所示,准确率随输入数据的维度变化趋势图如图5所示。可以看出,当输入数据维数大于等于25维时,四种攻击的准确率变化不大,其中,DoS攻击准确率在99.3%~99.8%之间,Probe攻击准确率在99.1%~99.7%之间,U2R攻击准确率在98.4%~98.8%之间,R2L攻击准确率在97.1%~97.9%之间。因此可以选择输入向量的维数为25维。图6所示是25维输入数据准确率和训练过程的损失值,准确率和损失值分别震荡上升和下降,最终都趋近于较稳定的值。
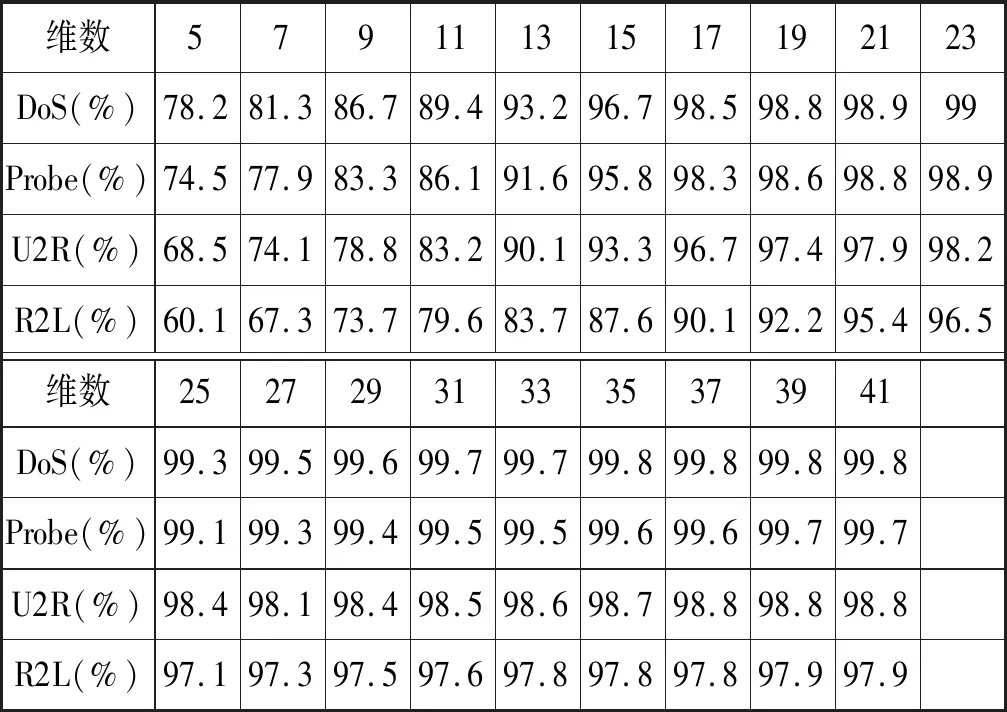
表6 四种攻击在不同维数下的准确率

图5 不同维数输入数据入侵检测准确率
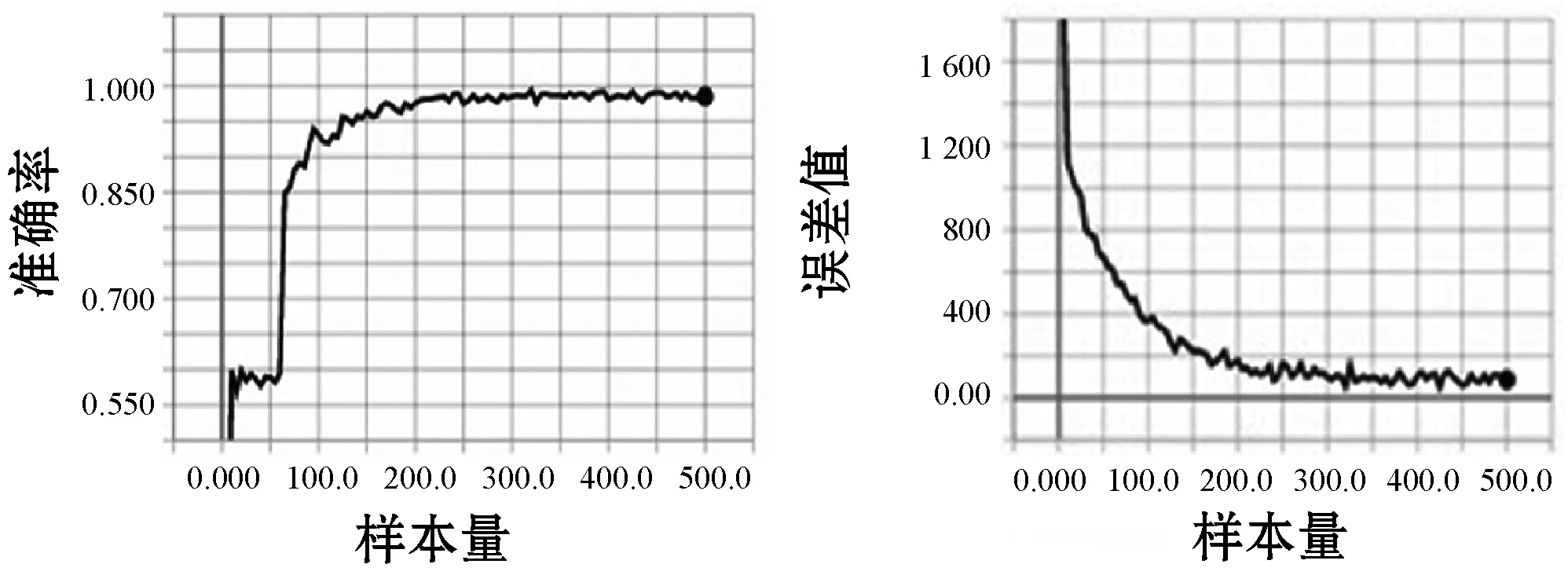
图6 25维数输入数据的准确率和损失值
为了研究本文所提神经网络训练加速效果,与文献[10]所用未处理输入数据的卷积神经网络入侵检测方案进行对比。由于文献[10]中只研究了二分类问题,因此将四种攻击统一用异常行为代替,将多分类转换为二分类问题。结果显示,在输入数据是25维时,准确率为99.2%;输入数据不处理时,准确率为99.7%。表7所示是不同输入数据维度下模型平均训练时长,相比于文献[10]中方法,本文所用优化方法使训练时间减少207.03 s,降低了77%。

表7 卷积神经网络模型训练时间
本文算法与其他文献算法的对比结果如表8所示。其中,AC1、FP1、Recall1、AC2、FP2、Recall2分别表示在训练集和测试集下的准确率、误报率、召回率。由于在测试集中有17种未知攻击类型,因此测试集和训练集下的准确率、误报率、召回率的差异反映了模型的泛化能力,对应项相差越小说明模型的泛化能力更强。测试平均时长是指处理1万条测试数据的平均时长,测试平均时长越小说明模型处理数据的速度越快。文献[10]中所提方法前文已进行过对比,相比之下,虽然准确率略有下降,但模型训练时间大幅降低,同时由于模型中间参数量较少,本文所用方法测试平均时间更少。对比文献[5]中提出的CANN模型,本文所提模型在处理测试数据集时泛化能力更强,且处理U2R和R2L攻击的效果更好,平均检测时长明显优于CANN算法。对比文献[6]提出的基于BFOA和K-means的算法,本文所提模型准确率、误报率、召回率、更优,平均测试时长有明显优势;对比文献[7]中效果最好的PCA_DT_C4算法,本文所提算法在处理DoS、Probe、U2L攻击时效果略优,且在处理U2R攻击时明显占优,PCA_DT_C4算法在处理二分类问题中由于Normal类型识别率较低,导致其准确率只有96.3%;对比文献[9]中DBN-ELM算法,本文所提模型具有更高的准确率和更低的误报率,泛化性能更好,测试平均时长较低。
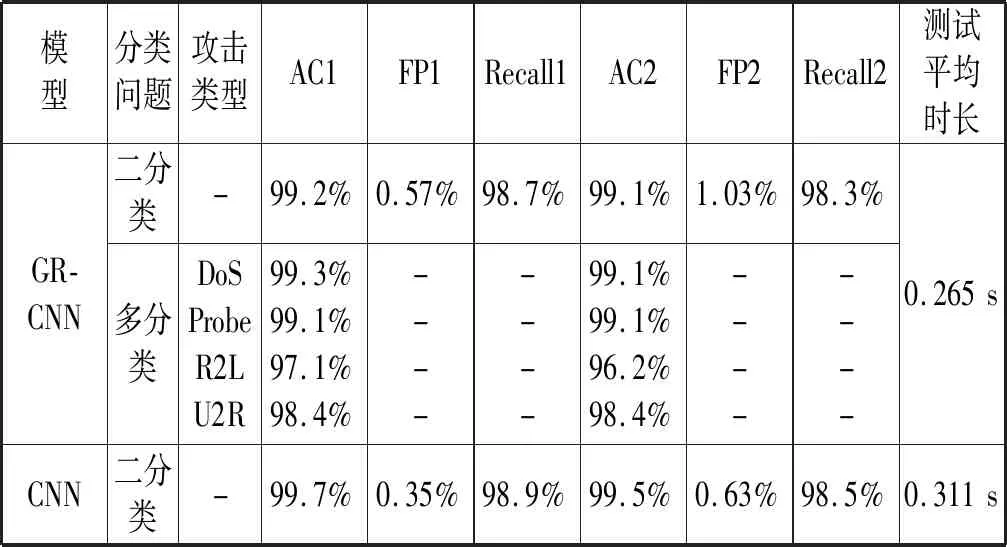
表8 不同模型实验对比
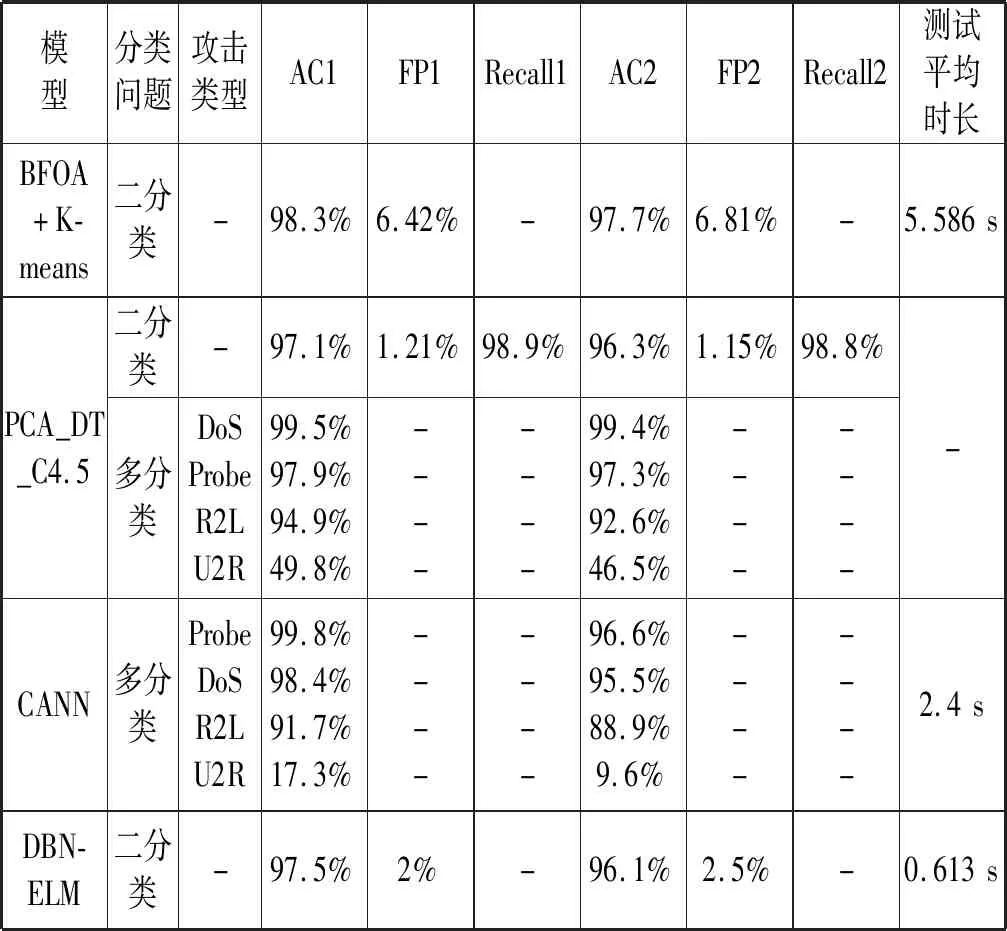
续表8
4 结 语
本文将卷积神经网络算法应用于网络入侵检测领域,采用增益率算法与卷积神经网络算法结合的方式,优化了卷积神经网络入侵检测模型。该模型可适用于二分类和多分类,有较高的准确率,泛化能力较强,识别速度较快。但由于仅在数据集上进行试验,未在大规模实际网络环境下验证,因此下一步需要模型应用到实际网络环境中。同时在数据特征筛选方面仍有优化空间,能进一步提升模型学习速度。
