基于兴趣度度量的多类差异数据关联规则挖掘
2019-12-12王桌芳赵会军
王桌芳 赵会军 李 聪 赵 煜 刘 震
(常州大学石油工程学院 江苏 常州 213000)
0 引 言
在数据挖掘领域,关联规则挖掘是一种非常有效的分析手段,对于挖掘数据中本身存在的项集关联属性具有非常好的效果[1~2]。但是,现代社会中数据的容量呈现出爆炸式增长,采用传统的关联规则解决思路对大数据的项集规则进行发掘的效果并不理想,数据的执行效率和实用性上存在明显的弱点。同时,采用置信度方式构建的规则挖掘算法框架对于用户的关注度考虑得并不周全,这对于诸如微博、Web数据挖掘领域应用效果不佳[3]。
对此,很多学者对于数据兴趣发掘提出了很多的解决思路,目的是帮助用户进行兴趣规则的发现,提高数据的挖掘效果。这种算法设计思路主要根据用户的关注领域,对用户规则的兴趣指标进行计算,并按照计算值进行排序提供给决策者进行决策参考[4]。目前的研究瓶颈主要集中在计算方式的高效性、概念定义的模糊性方面。当前,对于关联规则领域的研究主要侧重于以上方面,主观兴趣模型研究是一种有效的研究策略,其采用的是模版分析策略,目的是通过大数据分析获得兴趣度模型的规则模型[5]。同时,模版是一种有效的知识表达手段,对于兴趣度模型的分析具有辅助效果。此外,有学者将Rule Cover分析策略同数据挖掘过程的兴趣度模型进行结合,实现了模型效果的提升,获得了数据挖掘过程的优势互补,但是缺点是融合算法对于规则过滤的规则过于严格,导致规则的保留较少,关联规则的效果不佳,主要原因如下[6~7]:(1) Rule Cover分析策略主要侧重的是规则的普适性,而另一种融合算法则主要侧重的是规则的特殊性保持。(2) Rule Cover分析策略所需的规则数量偏少,而另一种融合算法则主要侧重的是多规则的数据挖掘,两者之间存在典型的互斥性。学术界对于Rule Cover分析策略的研究相对比较成熟,而在兴趣度模型研究上还不够全面,可以提升的余地很大,并且从用户需求角度看,兴趣度模型研究的意义主要体现在下列两个层面[8~9]:(1) 采用排序策略可提高算法的计算效率。因为对于挖掘出的数据特殊规则,如果不加处理地呈现给用户,会增加用户分析的计算复杂度,实际应用效果并不理想。(2) 特别是规则数目巨大时,用户研究目的是能够实现更加快速的知识信息发现,有助于提升数据发掘的目的性和针对性。因此,对于兴趣度模型的研究,获得更加完善的模型形式,对于提升关联规则的发掘效果具有非常重要的意义。
本文针对上述问题,提出了一种有效的Web数据挖掘改进策略。针对Web用户数据挖掘计算不确定性问题,提出了一种具有更佳一致度的兴趣度模型;对兴趣度模型在单模板情形下进行有效添加,实现了对兴趣模型的特殊处理;对于用户模版能够提供有效的支持手段,并且能够更加丰富模型中用户层面的有效性定义。
1 兴趣度模型描述
1.1 问题描述
置信度-支持度模型是关联规则算法常用的评价准则,这是一种强关联形式,其主要关注的是信任度和支持度两项指标的最大化。但是,这种过于苛刻的强关联规则对于用户不一定都有意义,应用效果不佳。例如:
选取Web网上超市数据库作为研究对象,假设数据库记录中,存在2 000组事务数据信息,其中1 600组中含有饼干等商品信息,1 200组含有茶叶等商品信息,960个既含有饼干商品信息又含有茶叶等商品信息。这里取支持度参数的最小值supmin为30%,信任度参数的最小值confmin为40%,由此可得规则形式为:
买饼干⟹买茶叶{Supp=48%,Conf=60%}
(1)
在真实的超市交易过程中,饼干等商品信息和茶叶等商品信息之间可能存在负相关特性。这两种商品信息的关联规则的负相关性可表示为:
买饼干⟹不买茶叶{Supp=32%,Conf=40%}
(2)
分析上述关联规则模型可知,负相关性关联规则形式与真实超市交易情形更加贴切。因此,对于给定阈值,获得的两条关联规则之间存在矛盾性。此外,如果给定阈值参数设定过大,会导致规则信息的遗漏,不利于数据挖掘过程算法性能提升。例如,在真实的超市交易过程中,会保存有客人的年龄、性别等个人信息,对于不同人群特征,可进行相关信息的数据发掘,例如,对于女性客户购买化妆品的相关信息挖掘,设定supmin为50%,confmin为70%,可得如下形式的关联规则模型:
女性⟹化妆品{Supp=55%,Conf=79%}
(3)
为获得更佳准确的用户兴趣度规则模型,有学者提出了基于约束条件设定的数据规则发现方法[10~11]:
(1) 约束模型的维和层次策略,对于数据的维度和层次进行规则约束的设定,实现用户规则的指定;
(2) 用户规则约束的数据分析方法,可以对相关数据进行具体指定,而无需对全部数据进行处理。
(3) 用户数据的规则分析方法,目的是获得所需要的数据类型。常采用的方法是设定模版概念定义,可对用户的规则兴趣进行设定。如果数据规则与模板之间存在匹配关系,则表明数据是感兴趣的。
1.2 兴趣模板模型构建
兴趣模型的主观表达中,常采用的是模版表达方式,可对用户表达含义进行有效的模型表示。参照文献[5]对于模板模型的定义形式,可给出如下定义形式:
定义1Web服务兴趣模型形式为A1,A2,…,AK⟹Ak+1,模型中Ai是数据模型的类名属性,比如,对于表达模型C+、C*,C+是多类模型C的实例表达形式,C*是零类模型C的实例表达形式,可表示为模版。
模板模型一般包含前件和后件两个主要组成部分,模版模型实例规则B1,B2,…,Bh⟹Bh+1表明上述规则与选取的兴趣模版模型是相关联的。因此,采用兴趣模板模型可实现关联规则的有效发掘,获得更加有价值的数据信息。
一般而言,兴趣模型具有多种不同形式,表达的含义也多种多样。为实现模版表达含义的统一,这里选取文献[12]所示形式进行模版形式的改进,具体定义形式为:
定义2如果数据用户之间关系具有不确定性,这种知识模版称为印象模板,表示为gi=[S1,S2,…,Sm],其中参数Sk是用户数据的属性名表达形式。
定义3如果数据用户之间关系具有确定性,这种知识模版称为知识模板,表示为:
rpc=[S1,S2,…,Sm⟹V1,V2,…,Vg]
(4)
式中:Sk与Vk也是用户数据的属性名表达形式。利用这两种模板载体形式,可基于计算机处理形式进行数据规则的挖掘。
1.3 差异概率兴趣规则发掘模型
定义4兴趣度指标常用来对用户数据的兴趣关注度进行量化度量,该指标的主要优势可对知识点的可用性和新颖性进行综合考虑,获得更为理想的模型表示形式。
兴趣度模型主要包含两个方面:客观层面和主观层面。前者模型主要是指关注程度的客观兴趣发掘,该指标的取值主要与规则模型形式的前后件之间的依赖性指标有关。当前对于兴趣度模型的研究主要集中客观兴趣度模型上,
对于1.1节问题描述中给出的饼干和茶叶超市交易商品信息数据库中的饼干和茶叶的交易信息关联情况可知,传统的客观兴趣度模型有可能会产生与真实情况不相符的规则模型。但是具体分析上述商品交易信息可知,饼干和茶叶的相关性交易信任度为60%。该数据指标表明,如果客人在超市中购买了饼干则该客人同时购买茶叶的可能性比较大,在真实情形下,这两者之间并不是存在正相关关联性,对于产生的“买饼干⟹买茶叶”的规则信息,并未真实反映出客人购买茶叶的变化趋势。对此,这里提出一种差异化的数据规则兴趣定义形式,目的是指导数据规则的挖掘过程,规则X⟹Y给出的数据之间的关联规则的准确性取决于两者之间的置信度指标,这里定义X⊇Y情况的置信度计算形式:
(5)
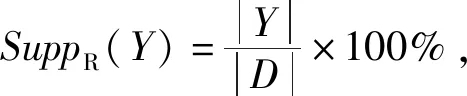
(6)
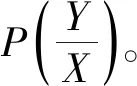
2 差异概率兴趣度关联规则
2.1 算法原理
Web服务模型I={i1,i2,…,im}是m组具有不同形式项目的模型集,参数m是模型集的尺寸参数,如果m=k,则称其为k-项集,且存在1≤k≤m。符号D是研究对象的事项数据块,每一事务选项对应的是其标识TID,并且该标识具有唯一性,形式为D={T1,T2,…,Tm}。对于每个事务T,其为项集I内的子集,也就是满足形式T⊆I。关联规则的形式为R:X⟹Y,其中:参数X⊆I、Y⊆I且存在X∩Y=∅。参数X是关联规则算法的条件,参数Y是关联规则算法的结果输出。关联规则算法的规则R所具有的置信度参数形式是Conf(X⟹Y),支持度参数形式是Supp(X⟹Y)。支持度参数反映的是事项集内同时含有X和Y的事项集比例。置信度参数反映的是事项集内存在X,并且在事项处理过程中产生Y的几率。具体形式为:
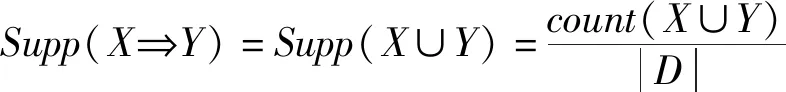
(7)
(8)
式中:频繁项集的定义是高于设定阈值参数Suppmin的支持度项集,若关联规则算法中满足Supp(X⟹Y)≥Suppmin的规则项X⟹Y,且满足Conf(X⟹Y)≥Confmin,则称为关联规则算法的关联规则项是强关联规则。
采用Web服务兴趣度模型建立的Web关联规则访问模型主要包含两个主要步骤:(1) 对于设计的关联规则算法,利用事务集约简算法进行频繁项集的有效约简;(2) 基于兴趣度因子对具有可信度和支持度的参数模型进行优化。具体过程如图1所示。
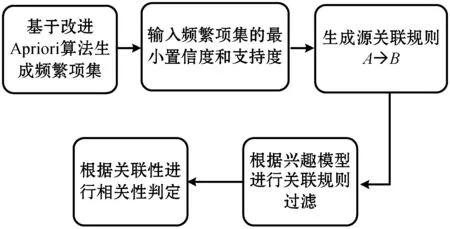
图1 改进算法计算过程
2.2 频繁项集约简
Apriori算法进行关联规则项的处理过程中,需要对D进行多次反复扫描,可构建1-频繁项集L1,通过对1-项频繁项集L1的改进可获得2-频繁项集L2,经过上述反复迭代过程,可得到算法所有的k-频繁项集。但是上述多次反复扫描过程会增加算法的I/O计算复杂度,这会导致算法存在过多的频繁项集,造成算法的计算效率大幅度下降。
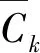
(9)


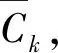
算法1频繁项集约简算法伪代码
(1)L1={large1-itemsets};
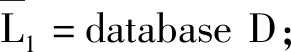
(3) for(k=2;Lk-1≠∅;k++)do begin
(4)Ck=apriori-gen(Lk-1)
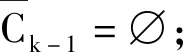

(7)Ct={c∈Ck|(c-c[k])};
(8) for allcandidatesc∈Ctdo begin
(9)c.count++;

(11) end;
(12)Lk={c∈Ck|c.count≥minsupp};
(13) end;
(14)Answer=UkLk;
2.3 兴趣度模型融合
根据上述表述可知,频繁项集约减过程算法得到的频繁项集是置信度和支持度参数均最小的关联规则项。但是实际上,如果仅仅选取置信度和支持度两个参数指标,并不能完全涵盖用户需求,甚至会导致用户做出错误的决策。对此,本文的解决思路是设计了一种差异化概率分析模型,首先给出交易集D,则其上的规则X⟹Y所具有的Web服务兴趣参数指标可计算为:
(10)
情形1:如果参数Interest是正值,表明项集A和B之间的相互作用具有积极效应,是一种正相关性关系属性。如果Interest=1,则存在关系P(AB)=P(A)P(B),表明在事务集中项集A和B之间的出现具有同步性。
情形2:如果参数Interest是负值,表明项集A和B之间的相互作用具有抑制效应,是一种正相关性关系属性。如果Interest=-1,则存在关系P(AB)=P(A),表明在事务集中项集A和B之间的出现具有异步性。
情形3:如果参数Interest是0,表明项集A和B之间的相互作用没有相关性,此时获得的关联规则算法的关联规则具有冗余性。
情形4:如果参数Interest→1,表明项集A和B之间的相互作用越紧密,此时的规则项X⟹Y对于数据的挖掘也越有意义。如果参数Interest→0,表明项集A和B之间的相互作用越稀疏,此时的规则项X⟹Y对于数据的挖掘也越没有关联性,相对于真实应用场景意义不大。差异概率兴趣度关联规则挖掘算法伪代码如算法2所示。
算法2差异概率兴趣度关联规则算法伪代码
输入:生成关联规则算法的频繁集Lk,算法的置信度最小阈值参数Confmin,算法的兴趣度最小阈值参数intmin。
输出:关联规则算法的频繁项集
For 所有k-频繁项集lk,k≥2 do
H1={lk规则后件}
Callap_genrules(lk,H1);
end
Procedureap_genrules(lk,H1)
//Hm是m项目后件
Ifk>m+1 then
Hm+1=apriori-gen(Hm);
For allhm+1∈Hm+1do
c=s(lk)/s(lk-hm+1);
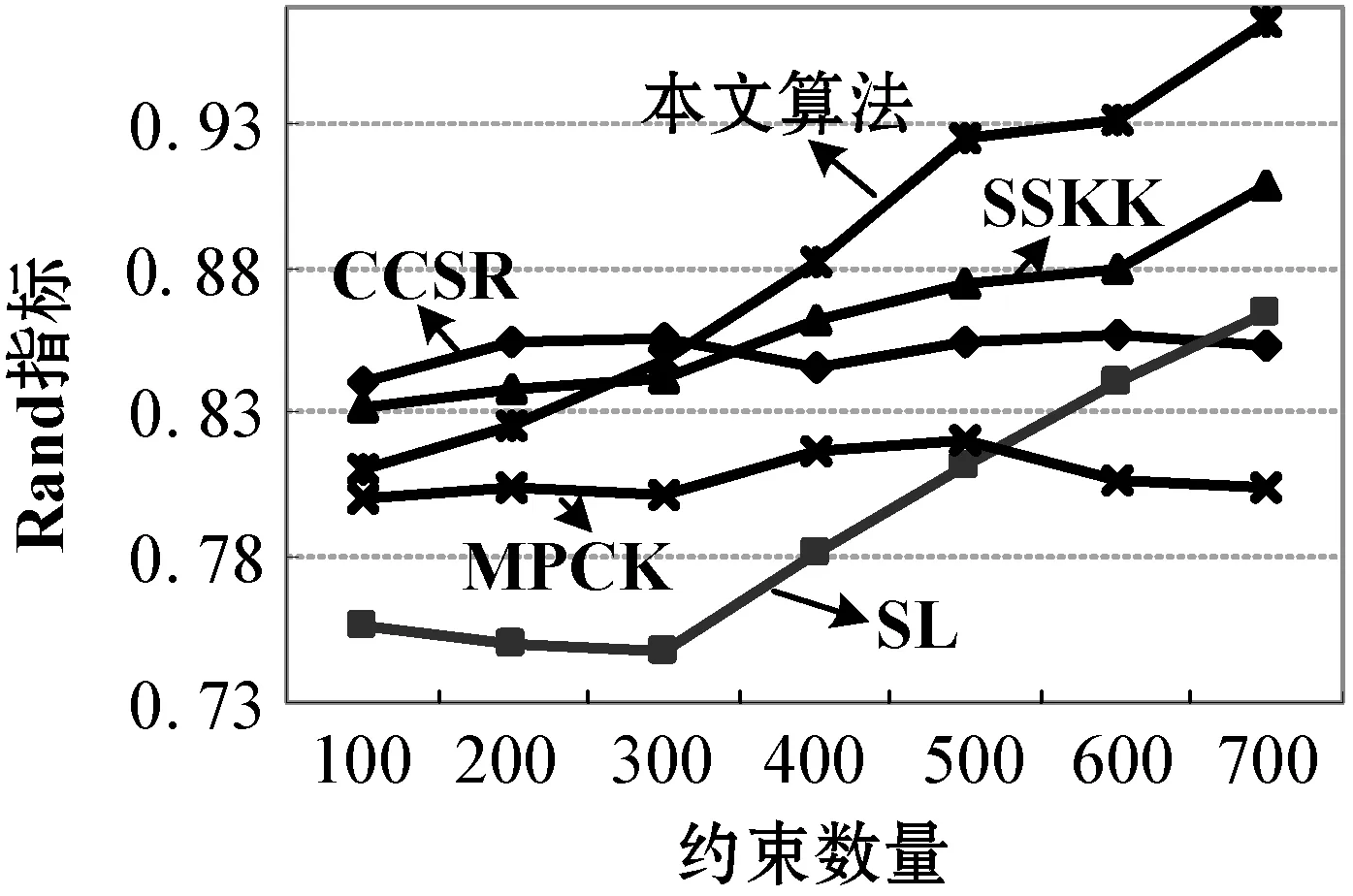
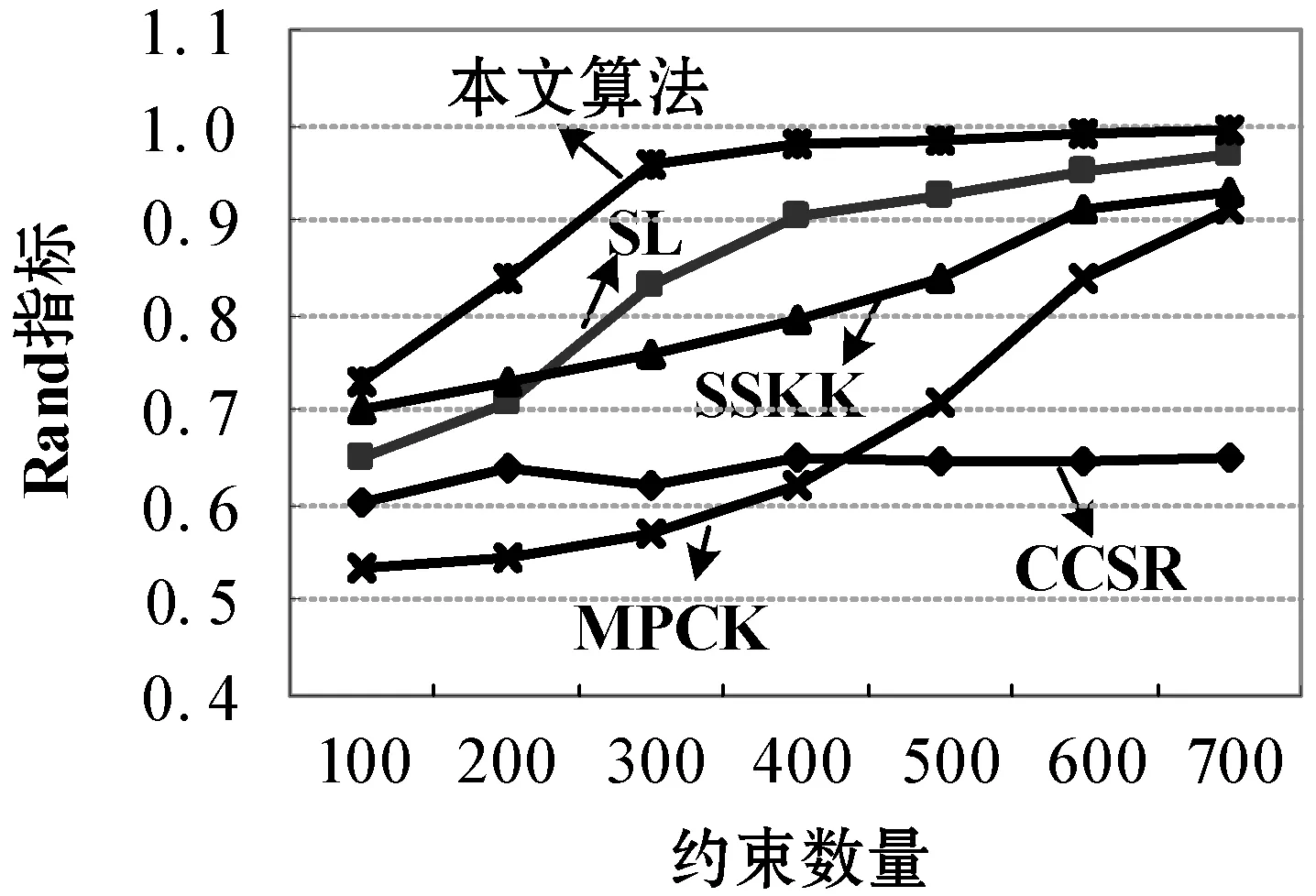
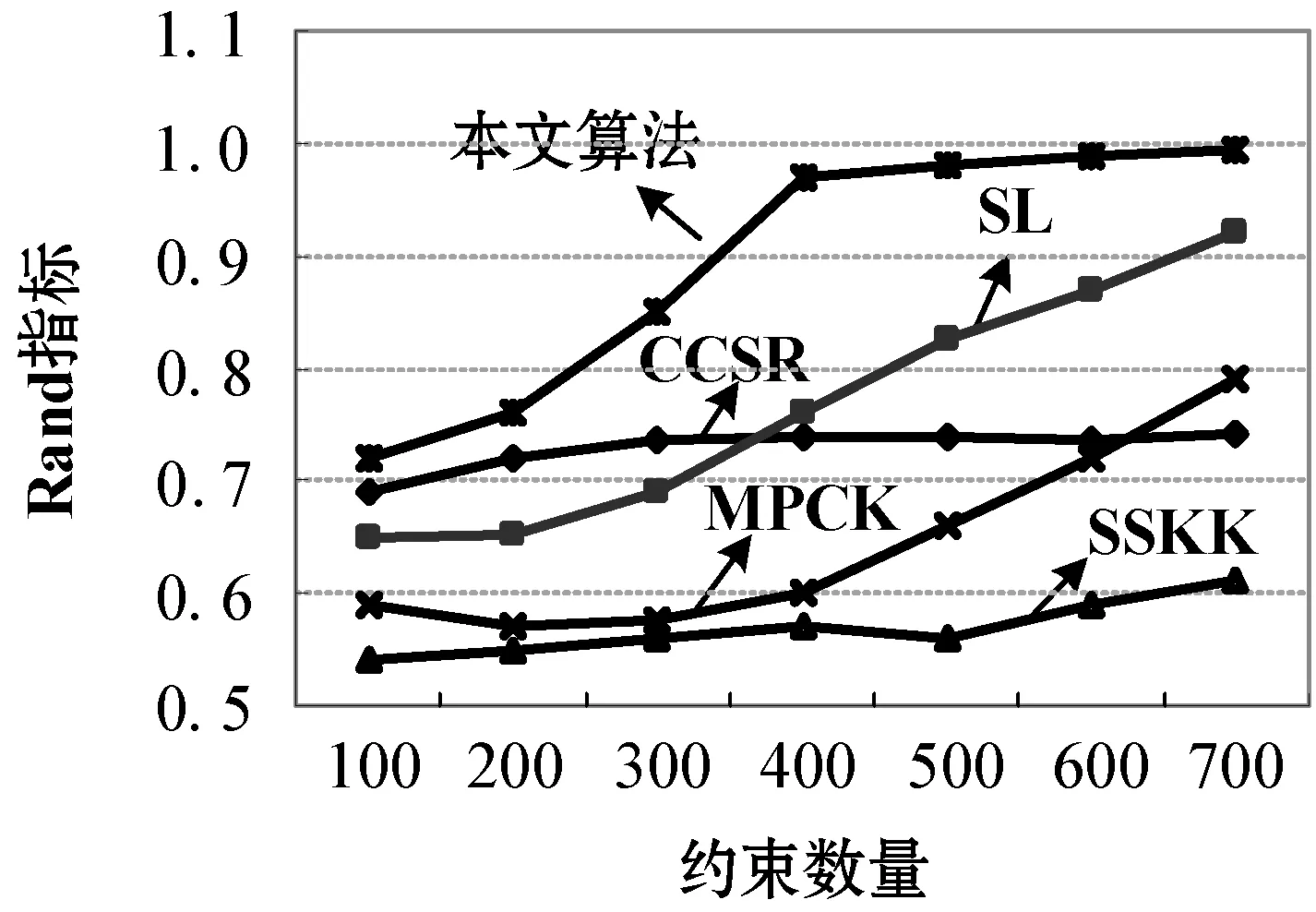
Ifc If |Int|>Intminthen outputrule(lk-hm+1)→hm+1; supp=s(lk),Conf=c,Interest=Int; End Callap_genrules(lk,Hm+1) End 为验证所提算法的有效性,选取四种已有的算法进行对比:文献[12]提出的光谱学习关联规则算法(SL)、文献[13]提出的高斯内核均值关联规则算法(SSKK)、文献[14]提出的谱正则关联规则算法(CCSR)和文献[15]提出的度量约束均值关联规则算法(MPCK)。选取的测试集是UCI测试集,该测试集共有8组数据集用于实验测试,该测试集中各含有4组Web数据集和真实数据集,如表1所示。 表1 实验数据集 表1参数设定中,tissue、parkinsons以及breast三种数据集均为医学研究领域的Web数据集,ionosphere是物理研究领域的Web数据集,TDT2是文本研究领域的Web数据集,MNIST是数字模式识别领域的Web数据集,Letter是英文字母研究领域的Web数据集,CMU PIE是人脸模式识别领域的Web数据集。 算法测试中,选取的测试准则是Rand准则,具体形式为: (11) 式中:TN为正确分类不同类对象的个数,TP为正确分类同类对象的个数。实验过程的硬件参数配置:cpu i7-6400,RAM 8 GB ddr4-2400,实验平台的系统为Windows 10旗舰版。 UCI集测试:4组UCI集上的5种标签数据挖掘算法实验对比结果如图2所示。 (a) tissue集 (b) parkinsons集 (c) breast集 (d) ionosphere集图2 UCI Web集实验结果对比 可以看出,在5种选取的对比算法中,本文算法除了在极少数数据集上因为存在的约束较少造成算法性能稍差于SSKK和CCSR两种对比算法外,在其他情形下均要优于选取的对比算法。具体实验情况分析如下:(1) tissue集测试结果显示,在约束数量为100~300参数设定情况下,本文算法与CCSR和SSKK两种算法相比并无优势,但是当约束数量大于300情况下,本文算法的Rand指标最高。(2)parkinsons集和breast集测试结果显示,在约束数量为100~700参数设定情况下,本文算法Rand指标均高于选取的四种对比算法。(3) ionosphere集测试结果显示,在约束约束数量为100~200参数设定情况下,本文算法与CCSR和SSKK两种算法相比并无优势,但是当约束数量大于200情况下,本文算法的Rand指标最高。上述实验结果显示,本文算法在正确分类不同类对象的个数以及正确分类同类对象的个数两种情形的综合实验指标要优于选取的对比算法。 本文提出一种基于Web服务兴趣度度量函数的多类数据挖掘算法。采取差异概率兴趣度量规则对关联规则算法中的时序事务进行估计和权重的预测;基于用户兴趣度进行约束条件设计,实现数据挖掘关联规则的精简;基于支持度函数和期望函数进行事务项集的提取,结合事务项集的置信度对其规则进行导出。结果显示所提算法可有效提升Web服务数据挖掘算法的性能,对于降低用户Web访问复杂性具有非常好的效果。3 实验分析
3.1 实验设置
3.2 实验结果

4 结 语
