基于LSTM-A深度学习的专利文本分类研究*
2019-12-11薛金成吴建德
薛金成,姜 迪,吴建德
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学知识产权发展研究院,云南 昆明 650500;3.昆明理工大学计算中心,云南 昆明 650500)
0 引 言
随着国家对知识产权重视程度的加深,近几年我国专利申请数量呈现爆炸式增长趋势。世界知识产权组织研究表明,全世界每10 s钟产生一份专利申请,每20 s出版一份专利文献。面对海量的专利文件,合理的分类显得尤为重要。目前,对专利文件进行分类仍然以人工方式为主,受限于审查员的专业素质,分类结果受人为因素影响较大。在专利申请量日益增长的今天,人工进行分类无法应对海量的专利文件。在此情况下借助自动分类技术对海量的专利文本进行自动且高效的分类,可提高专利文本分类的效率和准确率。
文本分类的关键点在于文本特征提取和分类器构建[1]。传统的机器学习方法在进行文本自动分类时,为了提取文本特征,往往需要依赖复杂而繁琐的特征工程,且提取准确率较差。近年来,深度学习的出现给文本自动分类注入了新的活力。相比于传统的机器学习,深度学习通过提取并组合文本中的低层特征形成更加抽象的高层属性类别,以发现文本的分布式特征表示,取得了优于传统方法的结果[2],因而被广泛应用于自然语言处理领域。
1 相关研究工作
要对文本进行特征提取要将文本进行向量化表示。在传统机器学习中,文本的向量化表示采用one-hot方式,方式为将语料库中所有的不相同词汇集合成一个词典,词典中不相同词汇的个数即为词汇总的向量维度,每个词汇在词典中的索引位置为1,其余位置为0。One-hot方式虽然可以简洁表示词汇,但其词汇向量维度高,且极其稀疏,词汇之间的余弦相似度均为0,无法体现文本特征。为解决这些问题,Mikolov[3-4]提出了word2vec词向量训练模型,采用神经网络结构自动学习词汇之间的相关度,思想为一个词汇的语义应当由其周围词汇决定,经过神经网络训练后网络权重矩阵的每一行即为每个词汇的词向量。由于词向量的维数可以在训练时预先指定,所以该模型可将词汇映射到低维且密集的向量空间中,且经过训练得到的词向量可以反映词与词之间的相似度。
在分类器构建方面,目前自然语言处理领域应用较广的为卷积神经网络(Convolutional Neural Networks,CNN) 与 循 环 神 经 网 络(Recurrent Neural Network,RNN)。 例 如,Yoon Kim[5]提 出的TextCNN分类方法,将卷积神经网络应用到文本分类任务,通过构建不同数量通道及尺寸的提取器(Filters)和最大池化层对文本特征进行提取,取得了较好的效果;Liu P[6]基于循环神经网络提出TextRNN方法对文本进行分类,通过RNN单元捕获文本前后语义,在短文本上取得了比TextCNN更优秀的结果;在RNN的基础上部分,学者如金志刚[7]使用考虑了记忆时长的长短期记忆网络(Long Short-Term Memory,LSTM)对文本进行情感分类,提升了准确率;而赵云山[8]在卷积神经网络的基础上引入注意力机制生成非局部相关度,建立了CNN-A分类模型,发现注意力机制的引入可以较有效地提升CNN模型的分类准确率。
这些工作训练使用语料库及应用时针对的文本多为新闻文本、网络评价等,而专利文本与此类文本区别很大。由于专利分类采用的是IPC分类方法,根据相似度差异按照“部-类-组”进行层次划分,属于层级细分类。越底层的级别文本之间的相似度越大,文本特征也越难以区分。针对专利文本的这一特点,本文构建了一种能够强化区别相似特征的细分类方法。
2 方 法
2.1 长短期记忆网络
长短期记忆网络(LSTM)为循环神经网络(RNN)的一个变种。与全连接神经网络相比,LSTM考虑了文本的时序信息,当前时刻的输出不仅仅与此时刻的输入相关,而是前一时刻输出与当前时刻输入的叠加。为捕获长期与短期的文本特征,LSTM加入了门控结构,包括遗忘门、输入门和输出门,通过训练是否保留前一时刻的状态,从而捕获更详尽的文本特征。结构如图1所示。

图1 LSTM分类模型结构
假设分词后的文本为x=(x1,x2,…,xn)的词向量序列,经过LSTM的隐藏层序列h=(h1,h2,…,hn)后可以得到网络的输出序列y=(y1,y2,…,yn),计算过程为:
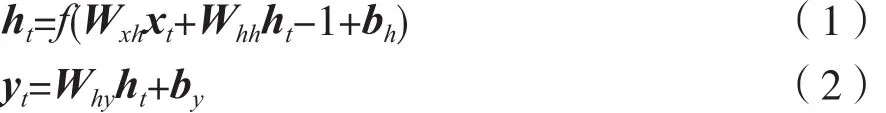
其中,Wxh表示输入层到隐藏层的权重矩阵,Whh表示隐藏层之间的权重矩阵,Why表示隐藏层到输出的权重矩阵,bh、by分别表示隐藏层和输出层的偏置向量。
LSTM独特的门机制控制前后时刻状态更新的方法为:
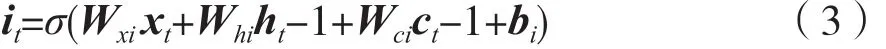
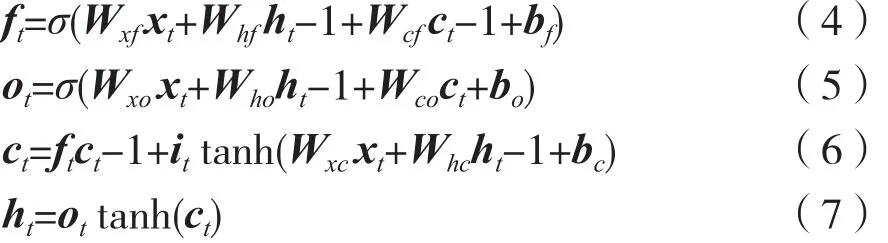
式(3)~式(7)分别表示输入门、遗忘门、输出门、神经元状态以及隐藏层序列更新方式。通过训练遗忘门决定是否保留在前时刻的状态信息,结合神经元状态与输出门控制保留在前时刻状态的多少,达成提取长期与短期文本特征的目的。
网络的优化目标函数通常定义为交叉熵损失函数:

其中,T表示总文本数量,Yi表示类别的实际概率分布值,yi表示预测概率分布值。通过最小化目标函数训练模型。
2.2 LSTM-Attention模型
专利文本记载了最先进的技术信息,其技术专有名词较多,所以文本特征难以区分,在分类任务中需要被重点关注,而注意力机制可以很好地解决这一问题。注意力机制的本质是一种编码-解码结构[9](Encoder-Decoder)。在这一结构中,首先将输入序列通过某些方式计算为一种中间状态,之后通过计算输入序列的注意力概率分布为输入序列分配不同的权重,最后根据任务的不同对中间状态进行解码,整个过程如图2所示。

图2 基于Attention机制的编码-解码
在输入序列为x=(x1,x2,…,xn)的情况下,定义输出为y=(y1,y2,…,yn),则编码过程和加入注意力权重的解码过程分别表示为:

将注意力机制加入LSTM网络,利用注意力机制对输入层不同词汇分配注意力权重,达到区分专利文本中相似的文本特征。引入注意力层的LSTM-A网络结构如图3所示。
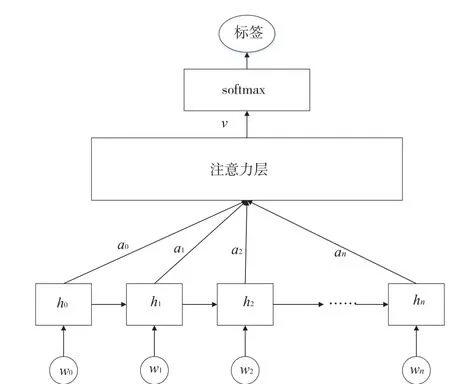
图3 LSTM-A文本分类模型
可以看出,LSTM网络作为编码层,将编码后的隐藏层序列信息hi结合其相应权重ai形成经注意力池化后的文本表示v,最后经过全连接层使用softmax函数进行分类,其计算过程为:
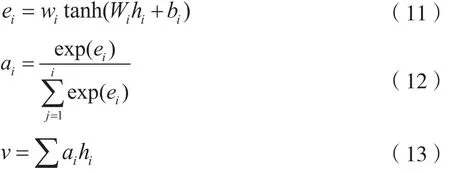
加入了注意力机制后的LSTM-A网络能够通过不断训练得出输入序列的文本特征,并依据特征重要程度为其分配权值,使得在专利文本中具有代表性的特征词汇在最后的分类中起到更大的作用,有助于更好地完成专利细分类任务。
3 实 验
3.1 实验环境
实验操作系统为Windows7操作系统,CPU型号为CORE i3 2.2 GHz,内存大小为4 GB,编程语言使用python3.0版本,使用深度学习框架tensorflow1.5.1。为体现专利文本的层次细分类特性,通过incopat专利数据库获取带有IPC分类号的专利数据。IPC分类号采用“部-类-组”的层次分类方法,层次越低,文本相似度越高。为方便研究,从数据库中获取“部”类别为F的机械领域专利文本2 000篇,“类”类别为H04W、H04K的通信领域专利文本各2 000篇,“组”类别为C05C1/00、C05C3/00的化学领域专利文本各2 000篇共10 000篇专利数据作为语料库,分类号对应代表含义如表1所示。

表1 专利分类号对应含义
其中,分类号为F的文本与其他文本差异最大,H04W、H04K之间差异较小,C05C1/00、C05C3/00之间差异最小,通过观察其分类结果测试模型优劣。
3.2 实验设计
采用对比试验的方式,通过精确率p、召回率r、F1值评价模型分类效果。
实验之前先对数据进行预处理,包括分词和去停用词。由于使用LSTM-A模型时需要以词汇的词向量作为输入,所以必须将专利文本切分成可以被模型处理的一个个单词。使用python的第三方库jieba的精确模式进行分词过程,分词过程之后整个文档将全部由词汇组成。之后去掉表示对整体语义和分类无影响的助词、符号等停用词,如“一种”“的”“!”等,停用词表采用收录较为完整的《哈工大停用词表》。
对预处理之后的文本数据采用word2vec模型训练得到词汇的词向量。word2vec模型在训练词向量时有skip-gram和CBOW两种训练方式:skip-gram思想为通过当前词预测上下文出现的概率;CBOW思想与前者相反,为通过上下文预测当前词出现的概率。两种训练模式相比,CBOW模式的训练速度比skip-gram更快[10],结合试验环境选择CBOW模式训练试验所需的词向量。通过对比不同词向量维数下TextCNN和TextRNN的模型精确度,选择最优的词向量维数。
为突出注意力机制对文本分类的影响,设计5种文本分类模型进行实验对比,分别为TextCNN、TextRNN、LSTM、CNN-A以及LSTM-A分类方法。
3.3 实验评估
先对比不同词向量维数下TextCNN和TextRNN的模型精确度,选择最优的词向量维数,试验结果如图4所示。
词向量的维数包含了词汇之间的相似度信息[11]。维数过低会降低词汇之间的区分度,无法区分专利文本中含义相近的技术词汇;维数过大又会使得向量稀疏,从而无法体现词汇相关性。由图4可知,本次实验中在词向量维数为200时,两种模型精确度都能达到最高,故选取词向量维数为200进行模型分类对比实验。

图4 词向量维数对模型精度影响
4种文本分类模型下对专利文本分类的结果如图5所示。LSTM-A模型分类的各项指标结果如表2所示。

图5 各模型分类准确率
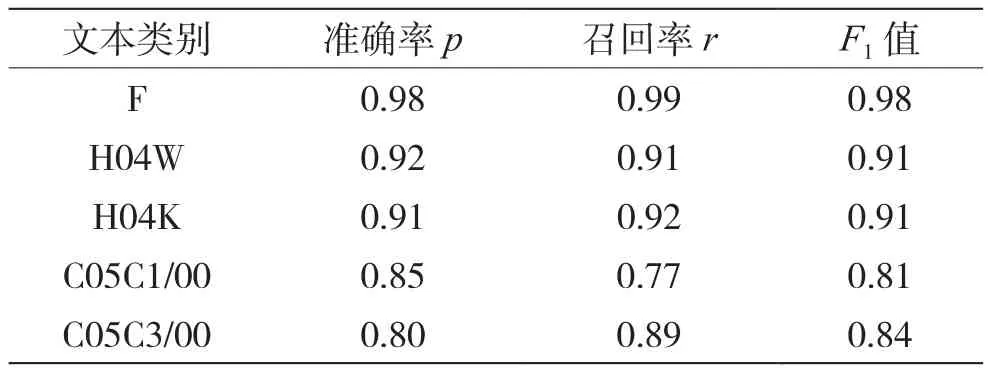
表2 LSTM-A模型分类评价指标结果
从图5可以看出,在对文本差异度较大的F类进行分类时,各模型均表现良好,TextRNN和LSTM效果优于TextCNN和CNN-A。随着文本差异度降低,在H04W与H04K两类专利文本中,TextCNN与TextRNN在分类效果上无明显差异,CNN-A与TextCNN相比分类准确率略有提升,而LSTM不论是否引入注意力机制表现均优于前三者;在文本差异度最小的C05C1/00、C05C3/00两类专利文本中,引入了注意力机制的CNN-A效果明显优于CNN,但与LSTM效果相差不大,而LSTM-A效果最好,结合表2可知,LSTM-A的召回率和F1值也呈现较好的结果。
上述结果表明,在对专利文本进行分类时,LSTM比CNN更有优势,注意力机制的加入对提升分类准确率有一定帮助;LSTM-A模型在文本差异度最小的C05C1/00、C05C3/00两类专利文本中准确率提升了5个百分点左右,说明注意力机制的引入在区分相似度较高的文本特征时可以起到较大作用。
4 结 语
针对专利文本不同于新闻、评论等文本的特点,提出了一种LSTM-A文本分类模型。实验证明,与典型的深度学习文本分类模型TextCNN和TextRNN相比,加入了注意力机制的LSTM-A模型在对相似程度不同的专利文本进行分类时,可以更好地区分相似文本特征,对不同文本特征赋予不同的权重,提高了专利文本的分类准确率。但是,LSTM-A模型属于一种迭代计算模型,时间复杂度较高,在模型训练阶段需要花费较高的成本。同时,虽然在对文本间差异最小的“组”级文本分类时相比传统方法有所提升,但准确率依然没有达到90%以上,是下一步需要研究优化的关键。
