基于动态分类的隐喻识别方法∗
2019-12-11郑发魁陈怡疆
苏 畅 , 付 泽 , 郑发魁 , 陈怡疆
1(厦门大学 信息学院 人工智能系,福建 厦门 361005)
2(厦门大学 信息学院 计算机科学系,福建 厦门 361005)
在自然语言处理研究领域中,隐喻是一个不可回避的问题.一些研究[1,2]表明,中文和英文的语料中存在着大量隐喻表达.因此,机器翻译、文本处理、信息检索等若局限于获取字面意义,而无法理解隐喻等“言外之意”是远远不够的[3].若能在这些领域中引入隐喻计算系统,则有希望进一步提高机器翻译质量,改善搜索引擎反馈,提高人工智能系统的水平.
“同从异出”是隐喻的语义特征和本质属性之一.这里的同和异指的是相似性和差异性.差异性创造了表达中的语义矛盾,隐喻识别归根结底就是发现不同个体之间的差异性.
隐喻识别是现代隐喻学的中心问题之一[4].目前,多数隐喻识别研究工作[5-15]只从某一个角度来判断两个事物是否构成语义矛盾.这种静态的方法具有片面性,因为人往往从多个角度考虑两个概念之间的差异性,并且两个事物可能从一个角度看是相似的,而从另一个角度看却是相异的.一系列的隐喻研究表明,人是动态地处理隐喻的.束定芳[4]指出,隐喻的重要特点就是说明了某类事物某方面特征的同时,却掩盖了其他方面的特征.Black[16,17]提出了隐喻的过滤作用,即概念有多个意义,在隐喻中,概念突显出显著的意义并且过滤掉不显著的意义.Fauconnier 等人[18]的概念整合理论认为,概念之间的映射过程在隐喻中是动态的.王小潞[19]通过分析人脑在处理隐喻时的ERP 神经成像,发现隐喻处理牵涉到与隐喻内容相关的大脑皮层的各个认知模块,这说明人处理隐喻是一个多种认知功能共同处理的复杂过程.基于上述理论,本文提出了一种动态分类的思想,从多个分类角度来度量事物之间的差异性,以模仿人脑在处理隐喻时综合考虑概念的多个意义和角度的复杂过程.本文的动态分类思想基于以下3 个原则.
(1)人类可以从多个角度对事物进行分类.分类可依据客观上的物理特征,如形状、颜色、功能、状态等,也可依据分类者主观上对事物的感觉产生的特征,如性格、美丑、善恶等.
(2)两个事物间的差异性可从一个或多个角度进行度量,差异性在不同角度下可能不同.
(3)基于某个分类角度度量事物间的差异性时,事物在这个角度下的性质会突显,在其他角度下的性质会消隐.
本文的动态分类系统从概念的语义类别、整体部件、客观属性值和认知属性这4 个角度入手,分别计算概念在不同角度下的差异性,从而实现隐喻识别的功能.在语义类别角度上,系统通过计算概念之间的上下位关系和“is 关系”判断概念的差异性;在整体部件角度上,系统通过计算概念间的共同部件来判断概念的差异性;在客观属性值角度上,系统从WordNet 中名词概念的释义文本中抽取属性和关系知识,通过基于反义关系的属性值差异性计算方法判断概念的差异性;在认知属性角度上,系统通过构建图模型计算显著认知属性的差异性.系统输入可能构成隐喻本体和喻体的英文名词词对,如〈person,machine〉,输出为metaphor 或literal,分别代表系统判断二者构成隐喻,或构成常规表达.在英文名词性隐喻识别的实验中,本文提出的算法对隐喻、常规表达的识别准确率达到85.4%.此外,本文的方法在识别出隐喻或常规表达结果的同时,可以给出在不同角度下的识别依据,因此具有可解释性的特点.在进一步的实验中,本文的多角度隐喻识别算法与部分角度的识别算法相比,在准确率上有所提升.实验结果表明,本文算法是有效的.
本文主要做出了以下贡献.
(1)我们实现了基于动态分类的隐喻识别方法.该方法能够根据事物的多种特征选取对应的分类角度,并在多个角度下判断事物的差异性.
(2)我们的隐喻识别方法是可解释的.该方法在计算出隐喻识别结果的同时提供了动态分类角度和判断依据,可以通过角度和依据解释隐喻识别的结果.
(3)我们的隐喻识别方法体现了在隐喻处理过程中,概念的某一部分特征被突显而另一部分特征被掩盖的过程[4].
本文第1 节简要介绍隐喻识别和属性及关系抽取的相关工作.第2 节介绍动态分类使用的各个角度.第3节说明使用动态分类进行隐喻识别的算法,对算法进行实验并分析结果.第4 节对全文的内容进行总结.
1 相关工作
目前,隐喻识别方法大体上可以分为基于知识库规则的方法、基于有监督的机器学习方法和基于无监督的机器学习方法.
在基于知识库规则的隐喻识别方法上,Fass[20]基于选择限制理论,通过对比输入表达与人工定义的语义规则是否匹配来识别动词的常规表达、转喻、隐喻和异常表达.Krishnakumaran 等人[5]使用WordNet 中名词间的上下位关系来识别IS-A 型名词性隐喻,利用词语在语料库中的共现频率来识别动词和形容词性隐喻.杨芸[6]使用HowNet 和《同义词词林》,通过语义路径和共有信息计算两个中文名词的相似性来判断是否构成隐喻表达.贾玉祥等人[7]利用《同义词词林》的语义距离和HowNet 的语义关系来进行隐喻表达的识别.贾玉祥等人[8]使用知识迁移的方法把英文的抽象度知识迁移到中文中,再基于抽象性知识识别隐喻.Kesarwani 等人[9]使用诗歌作为语料进行隐喻识别.冯帅等人[10]使用网络百科资源作为隐喻识别的知识库,通过计算两个概念在网络百科中知识的重合度进行隐喻识别.
在使用有监督的机器学习方法上,隐喻识别被看作一个分类问题.不同的研究使用概念的不同特征训练隐喻识别的分类器,概念的特征可以粗略地分为概念的属性特征和概念的语义特征.此外,也有使用概念的多种特征训练分类器的识别方法.在使用概念的属性特征的方法上,Gedigian 等人[11]将隐喻识别问题转化为一个二值分类问题,训练了一个最大熵模型分类器.Bulat 等人[12]使用概念的属性特征为概念进行语义建模进而训练可解释的隐喻识别分类器.Dunn 等人[21]基于本体论对SUMO 数据库中的概念进行属性特征抽取,使用回归方法进行隐喻识别.在使用概念的语义特征的方法上,Gutiérrez 等人[13]使用成分分布式语义模型获取“形容词-名词”短语的向量表示,进而对隐喻和常规表达进行分类.Mason[14]通过网页文本提取名词概念域的特征动词来构建源域到目标域之间的映射以及名词性隐喻实例.Shutova 等人[2]通过谱聚类实现了动词源域和名词目标域的自动扩展,来生成动词性隐喻实例.Strzalkowski 等人[22]结合句子的话题结构和抽象性分析实现隐喻的识别.Hovy 等人[23]使用支持向量机的Tree Kernels,让机器学习模型通过学习句子的语义解析树来进行隐喻的识别.Tekiroglu等人[15]使用人的知觉信息作为特征进行隐喻识别.在使用概念的多种特征的方法上,Shutova 等人[24]提出了跨模态的隐喻识别方法,结合文字和图像对隐喻进行识别.黄孝喜等人[25]通过计算概念的抽象度,结合概念的相似度使用支持向量机对隐喻识别进行分类.Rai 等人[26]则使用条件随机场模型,综合了句法、概念、情感和词嵌入的特征,训练了一个隐喻识别的分类器.
在基于无监督的学习方法上,Shutova 等人[27]使用多层次的图分解模型为名词进行聚类,进而实现隐喻识别算法.
此外,还有利用上下文信息进行隐喻识别的方法.Klebanov 等人[28]使用一元语言模型,以上下文作为特征,用监督学习的方法对连续文本中的词语进行隐喻识别.Schulder 等人[29]同样利用上下文,通过标记句中非常规词汇作为特征进行隐喻识别.
现有的方法大多是基于概念的单一特征进行隐喻识别.有的方法虽然结合了概念的两个或多个特征[24-26],但并没有对概念的不同特征进行不同角度上的分析.本文实现了一种基于动态分类的隐喻识别方法.该方法与现有方法相比,结合了概念的语义信息、属性信息、部件等多种特征,并对不同特征的不同角度进行了分析.该方法把概念的多种特征动态地结合到了一起,能够根据概念的不同情况选择适用的特征进行隐喻识别.
2 动态分类
2.1 分类依据的选取
2.1.1 特征的类别
Miller[30]认为,刻画一个名词概念并使其能与其他概念区分,需要考虑概念的属性(attributes)、部件(parts)和功能(function)这3 个方面的特征.基于该理论,HowNet(HowNet,http://www.keenage.com/)认为,事物之间的异同是由属性决定的.受到这些思想的启发,我们认为,人在对隐喻进行识别过程中会考虑事物的不止一种特征.本文选择概念的语义类别、客观属性值、认知属性、部件这4 类特征作为动态分类的分类依据,并讨论每类特征的获取途径和获取对应分类角度的具体方法.
2.1.2 属性和属性值
本文的研究区分概念的属性和属性值.在对属性和属性值的定义上,本文沿用了HowNet 的观点.即:概念的特征类别组成了概念的属性,概念之间的异同是由属性决定的.而概念在某一类特征的具体信息由属性值体现,例如“苹果的颜色是红色的”,对于概念“苹果”它具有属性“颜色”.一个属性可以有多个属性值进行描述,而在本例中,“苹果”的“颜色”对应的属性值是“红色”.本文区分概念的属性和属性值,是因为我们认为,只有在同一个属性类别下的属性值对比才具有意义.
2.1.3 客观属性值和认知属性值
Veale 等人[31]根据属性值获取的来源不同,把从 WordNet 释义中抽取的属性值称为一种客观的描述(objective description),把通过 Google 等搜索引擎从网络文本中抽取的属性值称为一种典型的描述(stereotypical description).Veale 认为,它们对概念的描述起到互补的作用.我们认为,这两种属性值的差异在于人类对概念的认知体验上.从WordNet 等语义知识库中获取的属性值多是专家从生物学分类等客观角度对概念进行的归纳和总结,具有客观性,不会因人类的主观因素而改变,体现了人们的一种共识[31].相反地,另一种属性值则反映了人类认知上的主观性.例如,“pig”这个概念在英语和汉语中所体现的显著属性值不同[32].不同的文化背景会导致人们在日常认知知识中的差异[33].李斌等人[34]强调,这种属性值是在特定的语言中,语言使用者对词语所代表的概念或实体的认知体验凝结到词义中的体现.
2.2 客观属性和客观属性值的获取
2.2.1 客观属性值的获取
基于第2.1.2 节的理论,本文使用基于依存关系的方法对WordNet(WordNet,https://wordnet.princeton.edu/)释义文本中的客观属性值进行抽取.在依存关系识别中,本文修改了ReVerb[35]识别模式,使其更适合进行对WordNet 的释义文本进行客观属性值抽取.修改部分如下.
(1)为了解决无法识别非连续动词短语结构的问题,如“he turned the light off”,对具有依存关系compound:prt(verb,prep)的“动词+介词”短语进行预处理,改为“turned off the light”的连续结构.
(2)对具有依存关系compound(noun,noun)的名词进行预处理,使它们连接成单个名词短语,如“sodium aluminum silicate”.
(3)对相邻的关系短语只取最后一个关系短语.例如在“monkeys like to eat bananas”中,识别关系短语是“eat”,而不是“like to eat”.
(4)使用在线英文词典Dict(Dict,http://dict.cn/)作为前置知识对关系短语进行检验,如果短语在词典中出现则识别正确,否则降低识别粒度.这样可以使关系短语符合人类的分析标准,避免出现过长或不正确的关系.
(5)为区分属性知识与关系知识,使用HowNet 对句子中潜在的名词属性进行标注,并将句子中所有的形容词都视为潜在的属性值.
我们使用算法1 对关系进行抽取及属性标注.
算法1.关系抽取和属性标注.
输入:一个句子S.
输出:关系短语集合R.
初始化R=∅
1.对S中的任意动词vi和介词pj,若满足compound:prt(vi,pj),则将pj移动至vi的后面.
2.对S中的任意两个名词wi和wj,若满足compound(wi,wj),则将wi和wj合并为一个名词短语.
3.对S中的任意名词wi,若其在HowNet 中为属性,则标记为prop;对S中的任意形容词ai标记为value.
4.以S中的任意动词vi作为起点识别关系短语ri,若ri不能在前置知识中验证,则ri的长度-1.重复进行,直到ri被验证.将ri添加入R.
我们首先使用算法1 获得关系短语集合R,再使用表1 的抽取方式获得关系的谓词表示,最后按公式(1)和公式(2)对客观属性值的关系进行扩展,从而获得WordNet 中概念的释义文本的客观属性值.

WordNet 中,一个概念的属性值并不仅仅来源于其本身的释义,还可以继承自它的上位概念.WordNet 中的名词概念之间的上下位关系具有传递性和不对称性,是一个具有继承性的层级体系[36].下位概念会继承它每一个上位概念的所有特征,并至少增加一种特征来与它的上位进行区别.例如,“warm-blooded(温血的)”是所有“mammal(哺乳动物)”的共同特征,所以,“wolf(狼)”“bear(熊)”等会从它们的上位“mammal”中继承这个属性值,而不用在自己的释义中重复定义.

Table 1 Relation extraction of objective properties表1 客观属性值的关系抽取
2.2.2 隐藏属性补充算法
人们在对事物的属性值进行描述时,往往隐藏了对属性的描述,如“苹果是红的”隐藏了苹果的属性“颜色”.本文提取出的属性谓词表示Prop(cpt,prop,value)容易缺失第2 项的属性信息.本文把缺失的属性信息称为隐藏属性.我们提出一种基于HowNet 的隐藏属性补充算法,为属性值补充其隐藏属性.隐藏属性补充算法如下.
算法2.隐藏属性补充算法.
输入:一个名词概念n与形容词属性值v.
输出:最合适的隐藏属性集合Pbest.
初始化Pbest=∅
1.选取n在HowNet 中的第一义原c.
2.通过概念-属性关系找到c关联的属性集合Pc,通过属性值-属性关系找到v关联的属性集合Pv;则输入概念和属性值之间的关联属性集合Pcv=Pv∪Pc.
3.若Pcv≠∅,则执行步骤4;否则,取得c的上位义原c′,若c≠c′,则使c=c′,执行步骤2,否则算法结束.
4.若Pcv存在pi的第二义原等于v,则将pi添加入Pbest.
5.若Pbest=∅,则使Pbest=Pcv.
2.2.3 分类角度(客观属性)的获取
我们通过WordNet 中形容词间的反义关系获取每个属性值所对应的分类角度.两个具有反义关系的属性值可以看作是它们所代表的属性的相反两个极值[37].例如,属性“height”的两个属性值为“high”和“low”.WordNet 中几乎所有的属性都具有双极性,个别属性甚至包含多个属性值.我们把这种属性值组成的集合称为反义关系集合.若一个客观属性值具有反义词,则它所对应的反义关系集合就能构成一个分类角度.基于客观属性值获取分类角度的过程如下.
过程1.基于客观属性值获取分类角度.
步骤1.给定一个概念c,使用属性抽取算法从WordNet 中抽取c的客观属性值集合Vc.
步骤2.对于c的每个上位概念hi,抽取其的客观属性值集合Vi,使Vc←Vc∪Vi.最终得到的集合Vc就是概念c所有客观属性值的集合.
步骤3.对Vc中的每个属性值vi,从WordNet 获取对应的反义关系集合Ai,若Ai≠∅,则Ai可以作为一个分类角度,vi为c在Ai下的分类依据.
表2 展示了部分分类角度和依据.

Table 2 Part of angles and foundations of classification based on objective properties表2 部分基于客观属性值的分类角度和依据
2.3 认知属性和认知属性值的获取
2.3.1 认知属性值的显著度
在语言学研究方面,显著度是语言理解的重要机制.以色列语言学家Giora[38]提出的梯度显著假说(graded salience hypothesis)认为,在话语处理中(尤其是隐喻、惯用语、反语和幽默语言),显著的意义总是首先通达.理论认为,显著度与规约性、熟悉度、使用频率等因素都呈正相关关系.我们认为,人类对事物进行分类时也遵循梯度显著假说,人类往往优先使用较为显著的特征作为分类依据.认知属性值来源于网络文本,显著度很大程度上体现在人们的使用频率上,即一个认知属性值与其宿主概念共现的频率越高,说明这个认知属性值越显著.
2.3.2 认知属性值的获取
本文通过两个在线知识库The Lex-Ecologist(The Lex-Ecologist,http://afflatus.ucd.ie/lexeco/)(简称LexEco)和CogBank(CogBank,http://www.cognitivebase.com/ecb_nju.php)获取认知属性值.LexEco 语料来源是英文维基百科,CogBank 的英文[34]语料来源是Google.两个知识库都统计了每个属性值出现的频数信息.表3 给出了3 个名词概念的部分认知属性值,按照每个属性值在两个资源库中出现的总频数从大到小排序.在获得概念的认知属性值之后,我们同样使用第2.2.2 节中的隐藏属性补充算法对概念的认知属性值进行隐藏属性的补充.

Table 3 Data samples of LexEco and CogBank表3 LexEco 和CogBank 数据样例
2.3.3 分类角度(认知属性)的获取
本文从两个途径获取认知属性值的分类角度.
•第一,与客观属性值一样,可以通过反义关系寻找认知属性值的分类角度.由于主观性因素,许多认知属性值并不会在WordNet 相对客观的释义文本中出现,所以这是对客观属性值的一个很好的补充.
•第二,认知属性值的显著度差异直接影响了对应属性的显著度差异,人们在描述一个概念时总是会突出显著度高的属性,所以概念的属性可以作为一种分类角度.
由于一个属性通常具有不止一个属性值,所以需要考虑多个显著的属性值.我们选取概念的某个属性作为其分类角度,将其对应的属性值组成一个特征向量作为该属性下的分类依据,具体步骤如下.
过程2.基于认知属性值获取分类角度.
步骤1.给定一个概念c,从LexEco 中获取c的认知属性值集合Vlex以及每个属性值对应的频数,从CogBank 中获取c的认知属性值集合Vcog以及每个属性值对应的频数.概念c的全部认知属性集合为Vc←Vlex∪Vcog.
步骤2.对Vc中的每一个认知属性值vi,获取其对应的反义关系集合Ai,若Ai≠∅,则Ai可以作为一个分类角度,vi为c在Ai下的分类依据.
步骤3.利用隐藏属性补充算法,对Vc中的每个认知属性值进行属性补充,得到概念c的属性集合Pc.
步骤4.对Vc中的每个属性值vi,使用公式(3)计算其对概念c的显著度Sig(c,vi).

其中,Ix(vi)表示属性值vi在知识库x中的频数,其中,lex表示LexEco,cog表示CogBank.系数α和β是两个可调节的参数,取值范围为[0,1],用来权衡两个知识库中数据的可信度.参数取值越高,表示相应的数据来源越可信.根据Giles[39]的观点,我们认为,维基百科的可信度相比普通网络文本要高,根据经验取α=0.6,β=0.4.
步骤5.对Pc中的每个属性pi,设对应的认知属性值为vij,显著度为sij=Sig(c,vij),可得pi的属性值向量wi=其中,Ni表示pi所对应的属性值总数.wi即为分类角度pi下c的分类依据.最后,使用公式(4)计算pi在概念c中的显著度Sig(c,pi).

表4 展示了”pig”的部分属性显著度信息.
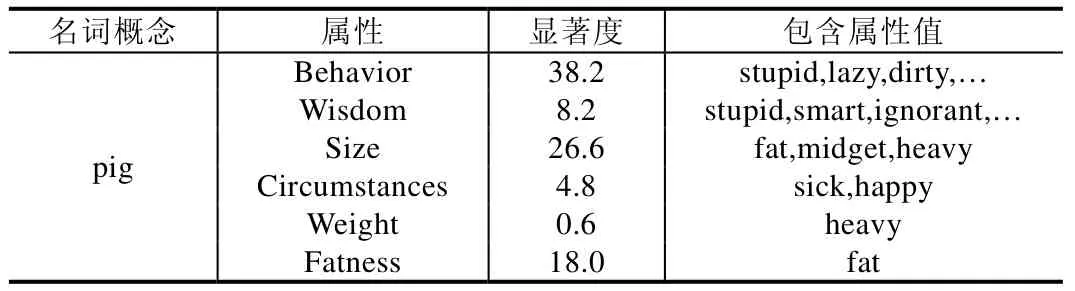
Table 4 Significance of properties of the word“pig”表4 “pig”的属性显著度
2.4 部件的获取
本文通过WordNet 中名词概念之间的部分-整体关系来获取一个概念的部件.和客观属性值一样,概念的部件也受到继承性的影响.基于部分-整体关系的传递性,一个概念还可以从它的部件中获得部件.然而,并不是所有的部分-整体关系都具有传递性.例如,“limb”是“tree”的部分,“tree”又是“forest”的部分,但并不能说“the limb is a part of the forest”,因为“limb/tree”与“tree/forest”之间的部分-整体关系在语义上并不相同[40].WordNet 中定义了组成部分(constituent part)、组成物质(substance)、组成成员(member)这3 种不同语义的部分-整体关系类型.本文规定,传递性只适用于同种类型的部分-整体关系中.
2.4.1 分类角度(部件)的获取
人类区分事物很重要的一个依据就是事物具有什么部件,通常有两种情况:(1)判断两个事物是否都具有单个指定的部件;(2)从整体上衡量两个事物具有多少共同的部件或不同的部件.基于部件获取分类角度的步骤如下.
过程3.基于部件获取分类角度.
步骤1.给定一个概念c,通过WordNet 中的部分-整体关系获取c的部件集合Mc.
步骤2.对于c的每一个上位概念hi,获取其部件集合Mi,并使Mc←Mc∪Mi.
步骤3.对Mc中的每个概念mj,若能得到mj的非空部件集合Mj,且Mj⊄Mc,则使Mc←Mc∪Mj.循环此步,直到对任意mj,均满足Mj⊂Mc.最终得到的集合Mc就是概念c所有部件的集合.
步骤4.当以单个部件为分类角度时,Mc中的每个元素都能作为c的分类依据;以整体部件作为分类角度时,分类依据则为整个Mc.
表5 展示了部分概念的部件特征.

Table 5 Component characteristics of concepts表5 概念的部件特征
3 基于动态分类的名词性隐喻识别
3.1 隐喻识别的本质
隐喻的一个本质是“同从异出”,用与本体相异的事物作为喻体来描述本体,在表层语义上构成了语义矛盾.隐喻识别的本质,就是判断一个表达中的两个事物之间是否构成了语义矛盾.究其根本,就是去发现这两个事物之间因何而异、异在何处.通常,两个事物之间的相似性和差异性可以用一个数值来表示,数值越大时相似性越大,差异性越小;反之,相似性越小,差异性越大.
3.2 整体部件的差异性
以整体部件作为分类角度时,两个概念之间的相似性由它们共有的部件及独有的部件决定.我们通过公式(5)计算两个概念c1和c2之间的相似性,取值范围是[0,1],其中,P1和P2分别为概念a和b的部件集合.

从信息量的角度来看,如果两个概念具有的部件数量越多,则上述公式越有意义;如果部件数量太少,则会造成准确性上的不足.因此,本文约定概念c1和c2之间的部件数之和不得小于5.给定一个阈值γ∈[0,1],当Sim(c1,c2,part)<γ时,我们认为c1和c2在整体部件的角度上具有差异性.
3.3 基于反义关系的客观属性值差异性
一个形容词与其本身相似性最大,与其反义词的相似性最小,如公式(6)所示.

给定两个名词概念c1和c2及其客观属性集合V1和V2,对于V1中的每个属性值vi,如果ai具有反义词,则找到对应的分类角度Ai,根据公式(5),如果ai有一个反义词属于V2,那么在分类角度Ai下,c1和c2的相似性Sim(c1,c2,Ai)=0,即c1和c2的差异性达到最大.通常情况下,一个概念的客观属性值中不会存在一对具有反义关系的形容词,所以在客观属性值的角度下,两个概念不会既相似又相异.
3.4 基于图模型的形容词差异性
语义差别法(semantic differential)[41]是美国心理学家Osgood 提出的一种以形容词的正反意义对词语所表示的概念进行语义测量的方法.该方法在每一对反义词之间设置区间值作为量表,以反映人们对客观对象的各个特征的心理感觉强度.参考语义差别法,本文利用WordNet 中形容词间的同义关系和近似关系构建图模型,以反义形容词对在图中的最短路径作为相似性的度量标准.该方法可以度量不具有反义关系的两个形容词之间的相似性.
3.4.1 基于WordNet 的形容词图模型构建
基于图论的观点,Kamps 等人[42]尝试利用WordNet 中的同义关系对名词、动词、形容词和副词进行图模型的构建.在无向图G(W,Synonymy)中,W是由WordNet 中所有单词组成的顶集,Synonymy是由所有同义关系组成的边集.研究发现,G中各词性子图都是非连通图,其中,形容词子图的极大连通子图的阶数为5 427,约占整个形容词子图的25%,而第二大的形容词连通子图的阶数仅为30.这说明基于同义关系的形容词模型构建方法基本上是可行的.
但是我们发现,在这种方法构建的图模型中,有许多反义词之间并不连通,例如“ugly/beautiful”“pleasant/unpleasant”“optimistic/pessimistic”等.为了增强图模型中反义词之间的连通性,我们在Kamps 等人[42]的基础上,为无向图增加了形容词之间的近似关系,更改后的图模型为G′(A,Synonymy+Similarity),其中,A是由WordNet 中所有形容词组成的顶集,Synonymy+Similarity是所有形容词之间的同义关系和近似关系组成的边集,边值权重和显著性阈值依据经验设置.G′的极大连通子图的阶数为16 852,约占整体的78%,是G的3 倍多.原来在图G中不连通的反义词,也在图G′中变为连通.
3.4.2 基于图模型的形容词相似性
Kamps 等人[42]曾使用语义差别法的“语义空间”中最主要的3 对反义词在图模型中的最短距离来度量形容词的倾向性.基于Osgood 的理论,所有反义形容词对都可以用来度量形容词的某一方面特征.如公式(7)所示,形容词a和b之间的相似性可以用其中一个形容词a与它的反义形容词a′在图中的最短距离来度量.

公式相似性的取值范围是[-1,1],取值越接近1,表示b与a差异性越小;越接近-1,表示b与a差异性越大.显然,Sim(a,b)和Sim(b,a)所表示的意义是不一样的.我们认为,形容词之间的同义关系比近似关系在语义上的距离更近.所以取同义关系表示的边权值为1,近似关系表示的边权值为1.5.表6 展示了该算法下部分形容词之间的相似性.给定判断形容词差异性的阈值θ1∈(0,1),θ2∈(-1,0),当Sim(a,b)≥θ1时,认为形容词a与b的差异性不显著,当Sim(a,b)≤θ2时,则认为形容词a与b的差异性显著.

Table 6 Adjective similarity based on graph model表6 基于图模型的形容词相似性
3.4.3 显著属性差异性
度量两个概念之间属性值相似性的同时,也是在度量它们属性的相似性.本文提出的属性相似性计算方法基于以下假设.
(1)在属性的分类角度下,两个事物之间的相似性可以表现为它们共有的某一属性的认知属性值之间的相似性.
(2)把事物A与B相比,通常是把A与B最显著的某些属性值特征相比,而忽略不显著的属性值.
(3)越显著的属性值,越能代表其属性的本质.
两个概念的相似性越低,代表它们的差异性越明显.
给定两个概念c1,c2及它们共有的一个属性p,Sim(c1,c2,p)表示在属性p的角度下,c2与c1比较的相似性.根据假设,Sim(c1,c2,p)表示为显著相似的属性值和差异显著的属性值的累加,当相似大于差异时表现为相似,当差异大于相似时则表现为不相似,相等时表示无法判断.设在属性p下,c1的认知属性值向量为V1={v11,v12,…,v1n},对应的显著度向量为S1={s11,s12,…,s1n};c2的认知属性值向量为V2={v21,v22,…,v2m},对应的显著度向量为S2={s21,s22,…,s2m},fij表示用公式(7)得到的属性值v1i和v2j之间的相似性.公式8 展示了Sim(c1,c2,p)的计算方法.为了保证认知属性值的显著性,我们规定每个属性值的显著度必须大于等于1.

3.5 名词性隐喻识别算法流程
人类识别隐喻时的思考过程是一个层次性的动态过程,在每个层次人类都从某个角度进行分析.由于主观性,层次体系可能因人而异.本文按照“语义类别”→“关系”→“整体部件”→“客观属性值”→“认知属性”进行识别,算法步骤如下.
算法3.基于动态分类的名词性隐喻识别.
输入:名词概念A和B.
输出:隐喻表达/常规表达.
1.获取A和B的整体部件、客观属性值以及认知属性值的分类角度.
2.基于WordNet 中的上下位关系,若A是B的上位或下位,则输出常规表达,算法结束.
3.通过算法1 的关系抽取,若R中存在关系is(A,B)或is(B,A),则输出常规表达,算法结束.
4.计算A和B在整体部件角度下的相似性Sim(A,B,part):若小于阈值γ,则输出隐喻表达,算法结束;若大等于γ,则输出常规表达,算法结束;若无法判断(部件太少),则进行下一步.
5.计算A和B在客观属性值角度下的相似性.若存在一个客观属性值使A和B的相似性为0,则输出隐喻表达,否则进行下一步.
6.计算A和B之间认知属性的相似性,若存在一个显著属性p使得Sim(A,B,p)<0,或不存在任何显著属性p′,使得Sim(A,B,p′)>0,则输出隐喻表达;否则输出常规表达,算法结束.
图1 所示为本识别算法的主要流程图.

Fig.1 Algorithm procedure of nominal metaphor recognition based on dynamic categorization图1 基于动态分类的名词性隐喻识别算法流程
3.6 实验与分析
3.6.1 数据集
本文从Master Metaphor List 语料库(Master Metaphor List,http://araw.mede.uic.edu/~alansz/metaphor/)、Collins Cobuild[43]语料库以及采用人工标注的方法,从网络、新闻等资源中标注出580 个英文名词词对作为实验的数据集.数据集中包含290 个隐喻表达和290 个常规表达.我们使用随机划分的方法,将数据分为一个大小为80 的训练集(40 个隐喻表达和40 个常规表达)和一个大小为500 的测试集(250 个隐喻表达和250 个常规表达).特别地,对于测试数据中出现的人称代词如“I”“he”“she”等,我们一律将其转换为名词“person”.
3.6.2 参数训练
本文的模型需要通过训练集训练两类参数.
•其一是整体部件的判断阈值,记作γ.当整体部件的相似度Sim(c1,c2,part)<γ时,判断为隐喻,否则为常规表达.
•其二是形容词差异性的判断阈值,记作θ1和θ2.当认知属性的形容词相似性Sim(a,b)≥θ1时,认为相似性显著;当Sim(a,b)≤θ2时,认为相似性不显著.我们在训练集上分别对这两组参数进行训练.
在训练γ时,我们仅使用上下位及整体部件的隐喻识别方法,以此排除模型的其他部分对训练参数的影响.我们采用最大化准确率的方法进行训练.我们发现,当γ=0.3 时,该参数的训练效果准确率最高,为67.3%.
训练(θ1,θ2)与训练γ的方法类似,为了排除模型的其他部分对训练参数的影响,我们仅使用上下位及形容词差异性进行隐喻识别.算法3 的第6 步给出了使用形容词差异性进行隐喻识别的方法.我们同样采用最大化准确率的方法寻训练θ1和θ2.我们发现,当θ1=0.9,θ2=-0.3 时,该组参数达到最好的训练效果,准确率是62.5%.
3.6.3 结果分析
我们使用Su 等人[44]的方法作为本文方法的对比实验.Su 等人[44]的方法使用概念的上下位关系和词向量的余弦距离识别名词性隐喻.该方法首先在大语料中训练各个概念的词向量,之后计算概念间的余弦相似度.若两个概念不属于上下位关系并且概念间的向量余弦相似度小于阈值,则这两个概念属于隐喻表达,否则为常规表达.余弦相似度阈值使用训练集训练得到.本文的方法与对比实验使用了相同的训练集和测试集.本文的方法与对比实验在测试集上的结果见表7.

Table 7 Comparison of experimental result of this paper with the method result of Su,et al.[44]表7 本文的实验结果与Su 等人[44]的方法结果比较
实验结果表明,本文的方法效果优于对比实验的方法.此外,本文的方法在识别出隐喻结果的同时,还能得到识别的角度和依据.例如,对于两个概念“person”和“machine”,我们的方法可以得到它们在整体部件上有很低的相似度,即人和机器的整体部件有很大的不同,这可以成为把它们识别为隐喻的依据.Su 等人[44]的方法得到“person”和“machine”的余弦相似度是-0.036,我们只能得到它们不相似的结论,却难以解释它们为什么不相似.由此可见,本文的方法具有可解释性的优势.表8 列举了部分隐喻的识别结果及识别的角度和依据.
为了进一步了解各个角度在隐喻识别工作上的不同之处,我们设置了如下3 个对比实验.对比实验只考虑了部分角度.各个对比实验的设置如下所示.
(1)仅使用语义类别和整体部件的角度计算.在语义类别不冲突的前提下,若整体部件差异性高于阈值,则判断为隐喻表达;否则为常规表达.
(2)仅使用语义类别和客观属性值的角度计算.在语义类别不冲突的前提下,若存在使相似性为0 的客观属性值,则判断为隐喻表达;否则为常规表达.
(3)仅使用语义类别和认知属性的角度计算.在语义类别不冲突的前提下,若存在显著差异属性,则判断为隐喻表达;否则为常规表达.
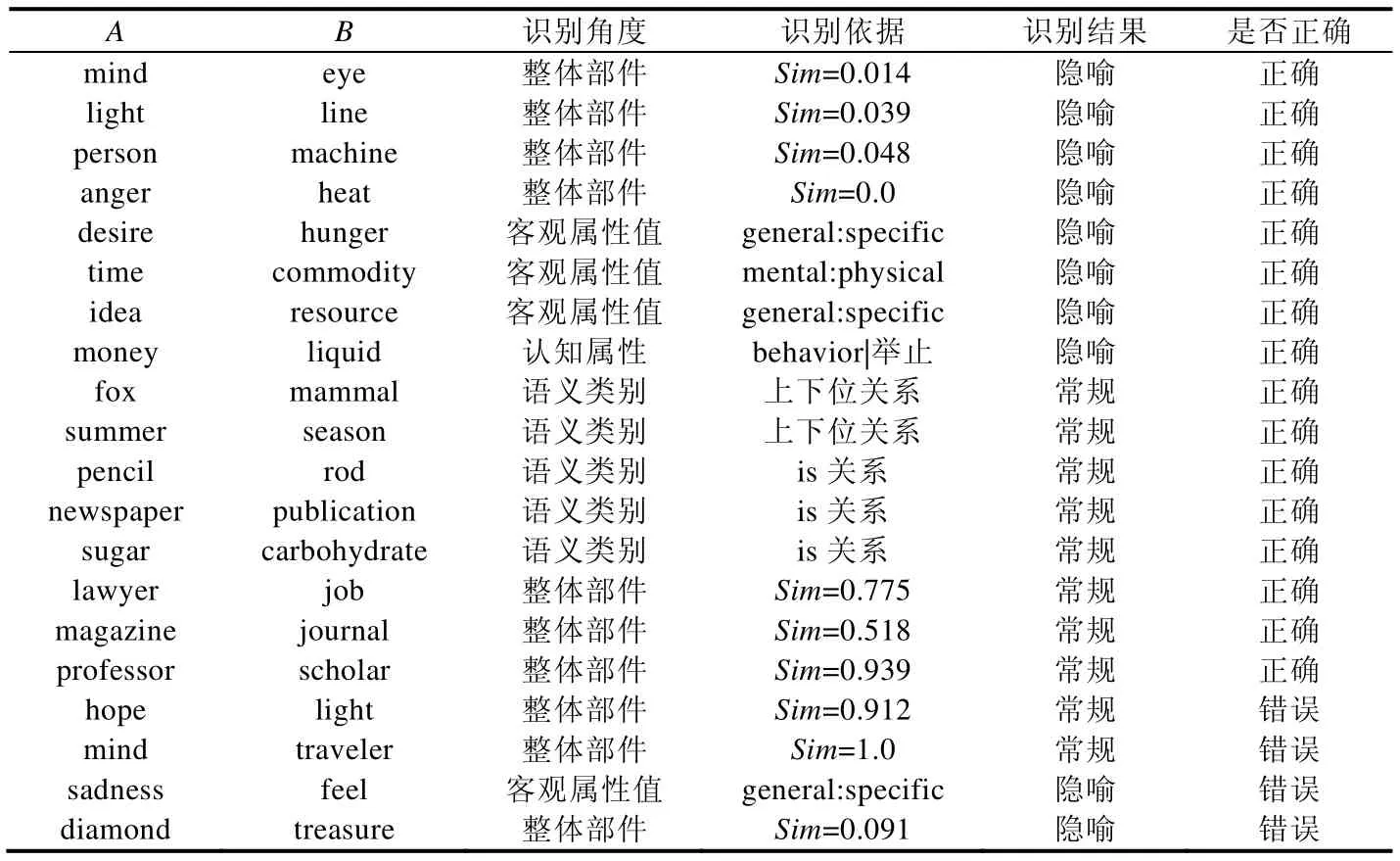
Table 8Results of metaphor identification表8 隐喻识别结果
表9 给出了本文方法和各角度方法的对比.通过对比可以发现,多角度的方法识别准确率高于部分角度的准确率.这说明多角度的隐喻识别方法对于提升识别效果是有效的.使用语义类别和整体部件的对比实验准确率最低,这是由于整体部件的差异性有时不能全面反映概念间的总体差异.此外,还有很多概念无法找到足够多的整体部件特征,这些概念需要其他角度的补充才能完善整个隐喻识别过程.使用客观属性值的对比实验比使用认知属性的对比实验效果要好,这是因为客观属性值的获取来自于权威的词典,它对概念特征的描述更客观,因此也更加准确.来源于互联网资源的认知属性值对概念特征的描述更具有主观性,因此会有更多的噪声.经过进一步的数据分析我们发现,本文方法在识别准确率上的提高大多体现在隐喻识别中各个角度的互补作用.例如,对于隐喻表达“desire force”,整体部件的方法无法找到足够多的部件支持它的判断,但客观属性值能够找到“general:specific”的反义关系作为补充,从而使其被正确地识别为隐喻表达.

Table 9 Comparison of the method result of this paper with part angles algorithms results表9 本文方法与部分角度的算法对比
本文方法的不足之处在于,对于抽象概念,我们提取出的认知属性值比较少.例如,“knowledge”只有6 个认知属性值,其中最显著的“honourable”的显著度只有0.8,而“discrimination”等一些不太常见的抽象概念更是找不到认知属性值,使判断结果不令人满意.未来我们可以通过采用知识图谱等方法改善认知属性值缺乏的问题.
4 结 语
我们实现了一种基于动态分类的隐喻识别方法.该方法从概念的语义类别、整体部件、客观属性值和认知属性这4 个角度对隐喻进行动态识别.在语义类别的角度,我们使用概念的上下位关系及“is 关系”判断隐喻;在整体部件角度,我们通过WordNet 获得概念的整体部件信息并计算其差异性;在客观属性值的角度,我们通过WordNet 的释义文本抽取出概念的客观属性值描述,并通过形容词的反义关系计算其差异性;在认知属性方面,我们通过知识库获取概念的认知属性,通过图模型计算形容词的相似度.此外,我们提出了隐藏属性补充算法,通过计算同一属性类别下的认知属性值相似度,判断认知属性角度的差异性.实验结果表明,本文方法具有可行性.此外,本方法还具有可解释性的优点.本文在隐喻研究的道路上朝新的角度迈出了试探性的一步,为隐喻计算和其他相关领域提供了新的思路.
本文算法仍有如下不足和改进空间.
(1)本文的特征抽取方法只限于WordNet,而该类资源受到手工构建的限制.如何从更广阔的资源中获取概念的特征,是一个重要的研究点.
(2)本文的方法只探讨了无数分类角度中常见的几类,还有许多可供使用的角度可以尝试.
(3)本文的方法只实现了名词性隐喻的识别,动词性隐喻、形容词性隐喻的识别也是今后需要进一步研究的方向.
