基于文本相似度算法的融合推荐系统的设计与实现
2019-12-10何宏廖巍唐林丰刘勋寒
何宏 廖巍 唐林丰 刘勋寒

摘 要:針对目前各类推荐系统存在推荐商品的用户满意度不理想和用户依赖程度比较低的问题,该文从用户的评分和行为两个角度,构建了将传统基于用户的协同过滤算法和文本相似度算法进行融合的改进算法模型,使推荐系统从用户角度进行推荐,并且实时更新,从而有效提高用户满意度和用户的依赖程度。
关键词:推荐系统 协同过滤 文本相似度 用户依赖程度
中图分类号:TP391.3 文献标识码:A 文章编号:1672-3791(2019)10(a)-0006-04
在这个信息过载的时代,推荐系统[1]在我们生活中已经随处可见了,比如电影推荐系统、图书推荐系统、广告推荐系统等。它已经成为大数据时代下不可或缺的一项重要技术,并且在未来扮演着重要角色。然而目前用户对推荐系统的依赖程度和推荐商品的满意度仍然比较低。其原因主要有以下两方个面:一方面是推荐系统对用户数据挖掘不够透彻,没有真正挖掘出用户潜在的价值需求;另一方面是推荐系统推荐给用户的物品没有质量保证,从而导致用户对推荐系统的信任降低。
协同过滤算法具有高效、准确等优势,但同时也存在数据稀疏、冷启动和扩展性差等问题[2],并且对用户的行为挖掘得不够透彻。数据稀疏是指用户计算的用户评分数据量不够,这样就很容易使计算结果不够准确,影响推荐系统的效果以及用户体验,并且没有被评价的商品很难得到推荐。该文提出的基于文本相似度算法的融合推荐系统是在使用基于用户的协同过滤算法预测用户对商品评分的基础上结合用户浏览记录和文本相似度算法给出推荐商品。首先预测评分高的商品才能进入候选商品集,这样一定程度保证了商品的质量以及用户的满意度,然后根据用户最近的浏览记录得知用户近期的购物需求。将两者结合起来提高用户对推荐商品的满意度,从而提高用户对推荐系统的依赖程度,提供个性化服务,并且能够一定程度上缓解数据稀疏、冷启动和扩展性差的问题,达到实时更新的推荐效果。
1 推荐算法描述
1.1 协同过滤算法
协同过滤算法是推荐系统领域的经典算法,简单高效是它最大的优势[3]。它是通过测量用户之间的距离作为相似性指标来计算用户的相似度。传统的基于物品的协同过滤算法在计算物品相似度时,热门商品与冷门商品相似度比较低,因此冷门商品的推广就比较困难[4],但并不能说明冷门商品就不好。该文首先采用的是基于用户的协同过滤算法,将用户评分以向量的形式作为输入,通过相似度算法就可以计算出各个用户之间的相似度,通过这种方法就算是冷门商品只要它的评价足够好也有可能出现在推荐队列当中。用户相似度度量方式采用皮尔森相关系数(Pearson Correlation Coefficient)。由于该文所涉及的数据维度不高,因此相似度计算方法的选择对实验结果的影响微乎其微,但考虑到欧式距离以及cosine相似度对变量取值范围比较敏感的原因,选择皮尔森相关系数来计算用户相似度。
如公式(1)所示,其中sim(a,b)为用户a与用户b的相似度;I为用户a与用户b共同评价的商品集合,i属于这个集合,Rai为用户a对商品i的评分;Ra为用户a对评价过的商品的平均评分。
如公式(2)所示,PAC为用户A对商品C的预测评分;RA为用户A对所有商品的平均评分;sim(A,B)为用户A与用户B之间的相似度,用户B属于用户A的邻近集合;RBC为用户B对商品C的评分;RB为用户B对所有评价过的商品的平均评分,下面给出算法描述。
1.2 文本相似度算法
TF-IDF是一种使用最为广泛的文本特征权重计算方法[5],TF-IDF就是词频(TF) 与逆文档频率(IDF)的乘积,它是文章关键词提取的常用方法。TF-IDF越大则这个词称为关键词的概率就越大[6]。
如公式(3)所示分子表示特征词g在文本中出现的次数,分母表示文本中所有特征词的总数。h为文本类别,g{1…k}。
如公式(4)所示,N为语料库中文本的总数;N(g)为包含特征词x的文本数,分母加1是为了防止分母为0。
比如将某一个商品信息文本做一个分词处理并且向量化(文本中各个词的出现频率统计)就可以得到每一个词在文本中TF值。将所有商品信息文本作为语料库,就可以得到这个商品中的每个词在所有文本中出现的频率,通过这个频率就可以计算得到逆文档频率IDF。假设一个词在所有文本出现的频率比较高,根据公式(4)那么它的IDF值就比较低。那么当一个词在某一个文档中出现的频率比较高,在所有文档中出现的频率比较低,那么这个词就很有可能是这个文档的关键词。因此根据公式(5),一个词的TF与IDF的乘积越大则越有可能是文档的关键字。该文则通过TF-IDF算法来生成文本TF-IDF矩阵,两个信息文本的TF-IDF矩阵相似度就是两个文本的相似度[7]。
1.3 融合推荐算法
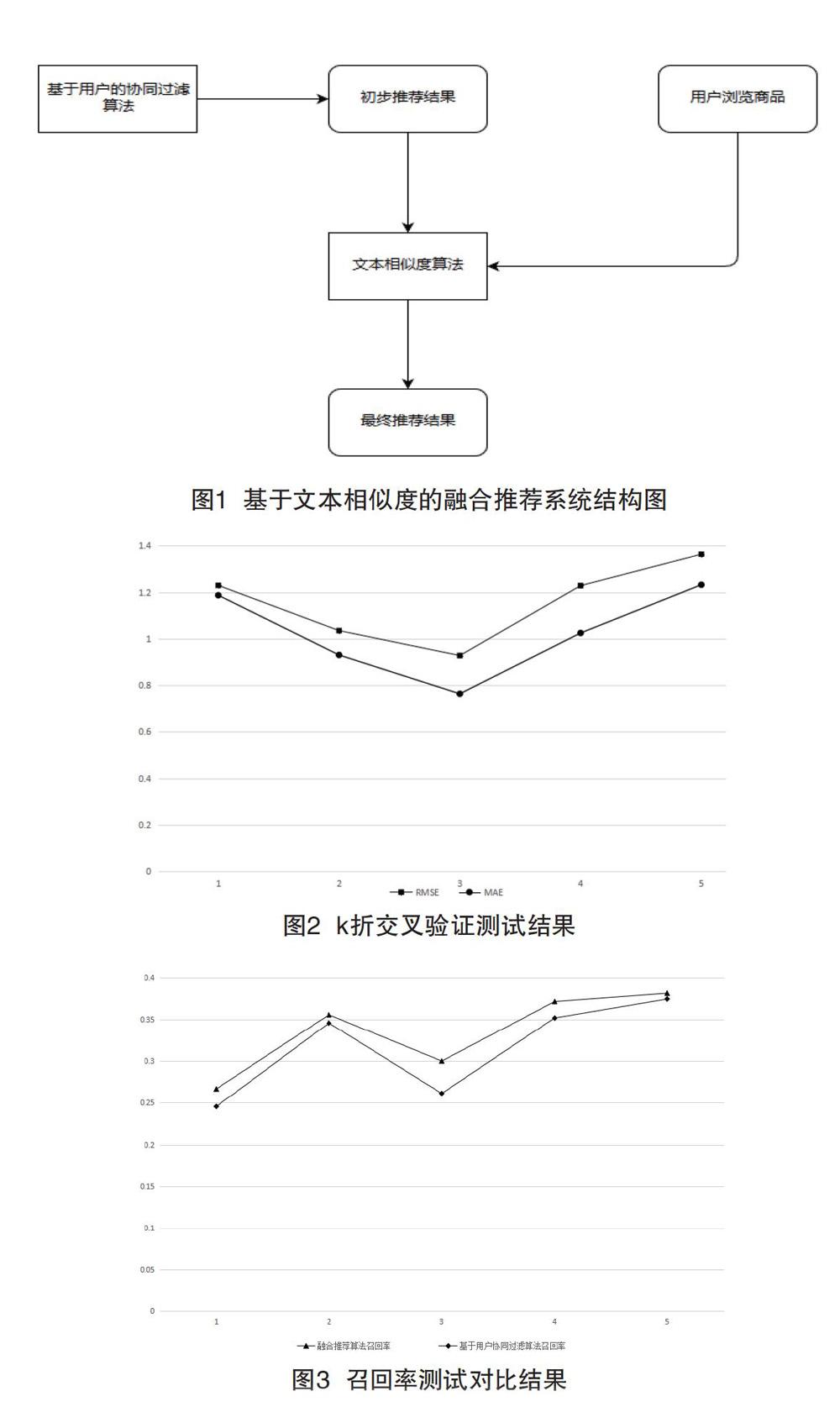
该文提出的融合推荐算法是将基于用户的协同过滤算法与文本相似度算法做一个融合。如图1所示首先利用基于用户的协同过滤算法得到一个初步的推荐结果,再从网页前端获取用户浏览记录,再利用文本相似度算法计算初步推荐列表中商品文本与用户浏览商品文本的相似度,将初步推荐列表中相似度高的商品作为最终推荐结果。基于本文相似度的融合推荐系统结构图如图1所示。
算法流程如下:
输入:用户-商品评分矩阵;
输出:推荐商品集合。
第一步,利用用户商品评分矩阵根据本文2.1协同过滤算法公式(1)和公式(2)得到初步推荐商品列表。
第二步,提取初步推荐列表中某一个商品的特征信息整合成一个信息文本。
第三步,将用户浏览商品特征信息整合成一个信息文本。
第四步,利用本文2.2提到的文本相似度算法计算两个文本的相似度。
第五步,将初步推荐商品ID以及其对应的文本相似度以键值对的形式保存到字典中,分别对应字典中的键和值。
第六步,重复第二到第五步直到初步推荐列表中的商品都已经计算完成,得到一个有关商品-文本相似度的字典集合L。
第七步,将集合L中的字典按值从大到小排序。
第八步,选排名前N个作为最终推荐结果。
2 实验数据以及实验结果
2.1 实验数据来源
该文所涉及的所有商品数据是用Scrapy爬虫框架从某电商网站爬取出来的7000多条数据。该文所使用的用户数据是通过小范围的测试所获取的真实数据,包括用户商品评分数据、用户本身的信息数据等。为了反映用户对已购买商品的满意程度,该项目采用5分制的评价制度。评分越高表明对于对商品的满意程度就越高。
2.2 数据处理
通常原始数据并不能直接用算法进行计算,需要通过对原始数据进行特征提取得到我们想要的数据格式然后输入到算法模型中。比如本文1.1提到的协同过滤算法所使用的用户-商品评分矩阵需要我们把几项数据整理到一起形成二维用户评分矩阵。P是一个j×n的用户-商品评分矩阵,u表示用户,i表示商品,j表示用户数量,n表示商品数量。Pj,n表示用户j对商品n的评分(见表1)。
除了协同过滤算法所用到的数据处理外,该文1.2提到的文本相似度算法也需要做特征提取,所提取的数据特征是对商品本身而言是比较重要和具有代表性的属性值。该文以手机为例,所提取的特征包括手机品牌、手机型号、手机内存、手机运行内存、手机摄像头参数、手机价格。
如表2、表3所示,将商品重要特征整合成信息文本过后就可以直接利用该文1.2提到的文本相似度算法直接计算两个商品信息文本的相似度,也就是这两个商品的相似度。
2.3 實验结果分析
选定一个合适的评价标准对系统性能的评估有积极的影响,由于该文的特殊性,定制了两个评估标准,一个是通过均方根误差(RMSE)和平均绝对误差(MAE)两种指标体现推荐系统预测评分的准确度。
如公式(6)(7)所示,n为参与用户个数,Pui为预测评分;tui为实际评分。
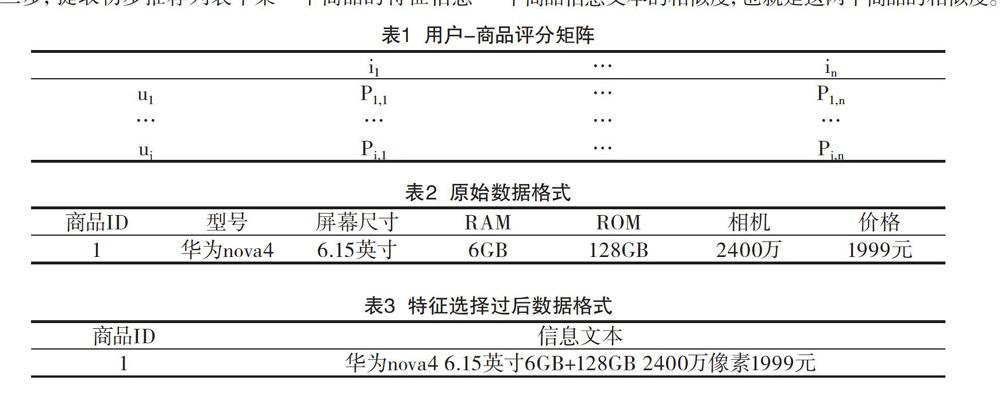
如图2所示,横纵坐标表示k折交叉验证中k的值,纵坐标则是RMSE和MAE的值。根据实验结果可知,当k=3时,推荐系统预测评分最准确。
另一个是召回率,它也是反映推荐系统性能的重要指标,R=TP/(TP+FN),反映了被正确判定的正例占总的正例的比重。
如图3所示,横坐标表示交叉验证k值,纵坐标表示召回率大小。通过实验测试结果对比可以发现,基于文本相似度的融合推荐系统的召回率与基于用户评分的推荐系统相比,最大提高了了0.05左右,并且在不同的k值下测试效果都保持稳定。这说明改进型推荐系统的准确率在基于用户评分的推荐系统上有了一定提升。
3 结语
该文将用户对商品的预测评分作为推荐系统的第一筛选指标,再将商品相似度作为第二指标,有效地提高用户对推荐商品的满意程度和依赖程度。搭建了基于Python3.7和Django的购物平台,使用Scrapy爬虫框架爬取国内某知名电商平台的真实商品数据,合理使用推荐算法达到了项目预期效果。
推荐系统仍有很大的进步空间,机器学习在推荐系统领域还有很大的潜力未被挖掘。比如推荐算法的改进,数据的多元化,推荐系统中的主动学习等都是推荐系统改进的方向。下一步在基于用户评分的商品推荐系统的基础上加入商品评价内容的情感分析并且将推荐系统与基于Seq2Seq的聊天机器人结合起来,研究基于自然语言处理的智能导购客服。
参考文献
[1] Ricci F,Rokach L,Shapira B,et al.Recommender Sys-tems Handbook[M].Boston:Springer,2011:1-35 .
[2] 刘向举,袁煦聪,刘鹏程.基于长尾理论的物品协同过滤Top-N推荐算法[J].齐齐哈尔大学学报:自然科学版,2019,35(2):1-4,9.
[3] 李梅珍.大数据环境下高校图书馆建立科研数据知识库智能推荐系统的思考[J].图书馆学刊,2019(3):102-105.
[4] 张子杰.基于数据挖掘技术的图书馆个性化快速推荐算法研究[J].计算机产品与流通,2019(6):119.
[5] 张俊飞.改进TF-IDF结合余弦定理计算中文语句相似度[J].现代计算机:专业版,2017(32):20-23,27.
[6] 王洁,王丽清.多特征关键词提取算法研究[J].计算机系统应用,2018,27(7):162-166.
[7] 王春柳,杨永辉,邓霏,等.文本相似度计算方法研究综述[J].情报科学,2019,37(3):158-168.
[8] 付建清.网络信息推荐系统存在的问题及发展方向[J].科技创新导报,2016,13(2):1-2.
