基于手机经纬度数据的重要位置识别应用研究
2019-12-04王兴旺
王兴旺


摘要:在大数据背景下,为挖掘手机与基站交互而产生的经纬度数据的社会价值,在聚类算法的基础上,提出一种基于局部异常因子LOF的k-means空间聚类算法。试验结果表明,该算法在去除离群点后,提高了分类识别准确度,对大数据集和高维数据重要位置识别上有较理想的效果。
关键词:聚类;局部异常因子;经纬度数据;重要位置
中图分类号:TP311 文献标识码:A 文章编号:1007-9416(2019)08-0053-02
0 引言
随着移动通讯、无线定位、移动互联网技术的高速发展,在智能手机及各类APP应用日益普及的当下,手机用户日常生活轨迹网络化的程度越来越高,当人们使用手机浏览新闻资讯、接打电话、收发信息、聊天、游戏时,手机与基站之间时刻发生即时通讯,由此产生了大量的空间位置数据。
目前,对手机用户轨迹进行聚类的研究中,文献[1]提出对轨迹点进行空间密度聚类,该方法没有对轨迹的离群点进行预处理,只通过KNN算法对数据进行聚类,聚类的区分度不够高。文献[2]将轨迹点转化为线段序列,通过对线段序列进行聚类来挖掘热点路径,该方法适用于GPS数据,对手机采集的信令数据并不适用。文献[3]通过将数据序列化网格序列,基于网格进行聚类发现热点区域,但基于手机信息的数据量巨大,传统的聚类方法已经不能满足热区挖掘要求。文献[4]提出了基于DBSCAN的空间聚类算法,处理带有噪声的空间位置数据,多个区域间相差较大,导致聚类质量较差。基于此,本文结合LOF离群点检测算法,提出了基于LOF的k-means空间聚类算法。LOF算法适用于基于不同密度的数据集群,通过利用LOF算法去掉部分异常位置数据,再利用聚类算法,找到手机用户的几个常用的聚集地。经过实验论证,该算法在处理海量数据时有较好效果。
1 基于LOF+K-means的重要位置识别算法
1.1 LOF算法
LOF算法作为一种基于密度方法的异常检测算法,通过将数据样本点的可达密度与其邻居的平均可达密度之比作为离群因子,用以识别离群点。
1.1.1 定义
(1)可达距离。点o到p的第k可达距离定义为:
rdk(p,o)=max{k-distance(o),d(p,o)
(2)局部可达密度。点p的局部可达密度表示为:
lrdk(p)=1/
该值代表一个密度,密度越高,认为越可能属于同一簇,密度越低,越可能是离群点。
(3)局部离群因子。点p的局部离群因子表示为:
LOFk(p)==/lrdk(p)
表示点p的邻域点Nk(p)的局部可达密度与点p的局部可达密度之比的平均数。
1.1.2 异常点判断
如果局部离群因子越接近1,说明p的邻域点密度差不多,p可能和邻域同属一簇;如果这个比值越小于1,说明p的密度高于邻域点密度,p为密集点;如果这个比值越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
1.1.3 算法1 LOF算法
输入:数据样本空间及局部邻居数和异常比;(1)设定局部邻居数和异常比,使用LOF算法对数据样本空间进行异常点检测;(2)根据1中得到正常点和异常点;(3)从数据样本空间中删除异常点。
1.2 K-means算法
k-means算法是基于划分的聚类算法,将样本空间在特征空间下相似的样本进行分类组织的过程,形成若干个不相交的簇,使得组内距离尽可能小,而组间距离尽可能大。
k-means算法的实现准则是选取适当的准则函数,是一种发现这种内在结构的技术,由于不需要标注样本而被称为无监督学习。由于简洁和效率而成为所有聚类算法中最广泛使用的一种算法。给定一个样本空间和需要划分的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把样本归入到k个聚类中。
1.3 基于LOF+K-means的重要位置识别算法
在识别重要位置时,由于个体日常生活、工作中在空间位置移动时,多数情况下会在几个主要区域切换,有部分位置因为偶尔出现,而在数据上表现出一定的随机性,在识别特定手机用户重要位置时可以先将这些数据剔除,因此,本文考虑将局部异常因子算法结合k-means算法,达到识别出特定手机用户的重要位置。
根据模型输入数据的特征及业务特点,可以利用k-means聚类算法,挖掘出每个手机用户的三个簇(工作地、居住地、其他),再根据聚类中心与数据样本中距离最近的样本,标注为该手机用户的工作地、居住地、其他。
1.4 算法2基于LOF的K-means算法
输入:数据样本空间、局部邻居数和异常比、聚类数k;
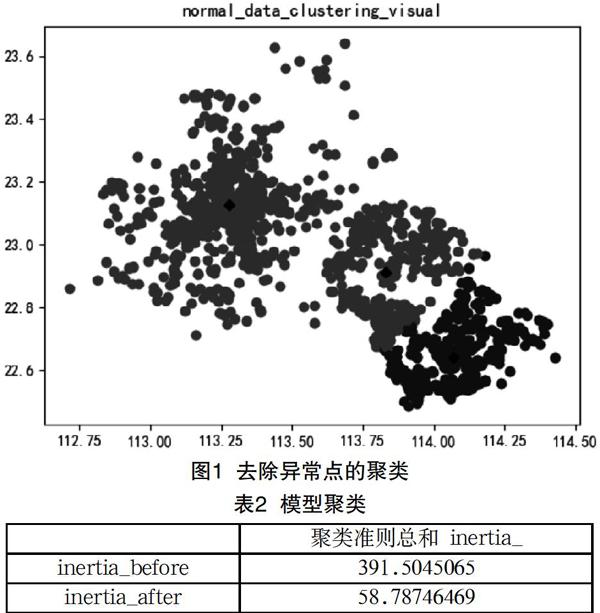
(1)根据LOF算法过滤异常点;(2)预先给定k=3,随机从样本中选取3个初始聚类中心;(3)计算所有样本到每个聚类中心的距离,并将所有样本划归到距离最近的距离中心;(4)在每个聚类中,根据所有样本的平均值,将其作为新的聚类中心;(5)循环2、3,直到迭代步达到预先设定的迭代步数,或前后两次聚类中心的变化小于预先设定的阈值;(6)根据两个聚类中心与样本距离最近,获得数据集中对应的重要位置。(7)结合发生时间,分类识别出职、住地。
2 实验结果及分析
2.1 数据准备
数据来源为某市接入的各类数据,包括行程服务、打车类/代驾类、地理位置信息等五个源数据集,并从各数据集中初步筛选相关字段元素,作为分析要素。
手机用戶的网络行为是多维度的,获取的样本越多,从这些信息中就越能逼近其现实状态,基于此,需要尽可能多的融合各类信息,融合形成如表1,用于建模输入。
