基于时间路径的物流中心选址与优化研究
2019-12-04张雨逢锦荣于洋
张雨 逢锦荣 于洋

摘要:为提升快递物流企业服务效率和服务质量,优化大数据环境下企业管理模式,基于传统聚类选址算法和最小支撑树法,通过分析快递物流服务过程,提出配送时间路径概念。以时间路径优化为研究对象,对聚类算法和最小支撑树法进行改进,构建物流中心选址模型和物流配送区域划分模型。采用Python分别以时间路径和距离路径为参量的100物流点配送过程进行仿真验证。实验结果表明,基于时间路径的物流选址算法确保了物流中心位置的效率最高,达到了提高整体物流水平的目的。
关键词:物流中心选址;时间路径;实际距离;聚类
DOI:10.11907/ejdk.191091开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)010-0125-05
0引言
快递物流行业呈现蓬勃发展之势,物流配送中心的重要性和必要性日益凸显,成为现代物流环节中不可或缺的一部分。科学合理地选择物流中心位置有利于提高物流系统整体运行效率,简化物流系统运作模式,充分利用社会资源。因此,物流中心选址问题研究具有重要的理论与实际意义。
近邻传播(Affinity Propagation,AP)聚类分析算法作为物流领域常用的配送中心选址方法,与Bamnol-Wolf模型方法、多准则决策法、德尔菲法、数据包网络分析法等相比,算法简明、实时性好,能处理大规模数据,但在实际应用时未考虑交通路况,且物流中心选址的准确性取决于算法参数的值。针对物流中心选址问题研究有:Feng等提出OPTICS聚类算法,解决数据集的不同部分需要不同算法参数的问题,在算法理论上可获得任意密度的聚类。但该算法运行时间长、效率低;Wang等提出基于均值的距离度量聚类算法,但该算法缺乏鲁棒性,对噪声和异常值较敏感;甘月松等提出最小连接和最大连接聚类算法,通过选择适当的系数构造更复杂的聚类算法,但该算法过程中的决策不可回调、计算复杂;李捷承等提出通过设置不同权值调节各种因素以影响物流节点相关性,弥补了聚类算法直接应用于物流选址的不足,但该算法只考虑了空间距离对物流节点之间相关性影响。
以上研究考虑了算法本身优化,在解决物流中心选址问题上都以物流点之间的实际距离作为参考。本文以聚类分析算法为研究基础,以物流中心选址问题为研究对象,分析物流中心选址行为,考虑配送过程中的不确定因素影响,提出物流配送的时间路径概念,保证物流中心选址的合理性;基于遍历搜索法,通过时间最短的最小支撑树对各个物流节点进行配送区域划分。为验证提出的中心选址方法是否有效,采用Pathon进行物流中心选址仿真验证。
1物流配送模型
1.1物流配送行为分析
物流中心作为推动现代物流发展的重要基础设施和实现物流信息化的载体,其正确的选址在物流系统优化中起到关键作用。为准确规划物流中心选址,需要分析实际物流派送行为特点,并将其融合到物流中心选址规划中。
随着物流业的发展,建立物流配送中心迫在眉睫。基于物流派送行为描述物流中心选址过程如图1所示。
配送点记为M1,物流中心记为M2,用户记为M3,物流派送过程如下:
(1)集货过程:物流公司为满足特定客户的配送要求,把从几家甚至数十家供应商处预订的物品集中,并将物品分配到指定容器和场所,该过程称为集货过程。
(2)选址过程:在一个具有若干供应网点及若干需求网点的经济区域内,选一个地址设置物流中心的规划过程,此即为物流中心选址。
(3)配送过程:根据客户要求将货物送达至客户要求的地点称为配送过程。
1.2物流中心选址
从物流配送行为分析可知,选址阶段最为复杂,一旦物流中心的位置不合理会造成不可估计的损失。所以,物流中心的选址不是简单、基本层面的分析,而是需要系统、综合、全面分析。
1.2.1物流中心选址问题模型
由图1可知,物流配送中心选址问题实际为p-中值问题,即已知需求点或客户的位置坐标及配送需求量,在空间中或候选地址集中选择p个位置作为物流中心,可覆盖全部区域的配送需求且使所有需求点到其归属的配送重心距离和最小。
1.2.2物流中心选址流程
基于上述分析,选择合理的物流中心地址不仅可以有效节约物料、节省费用,而且还能有效促进消费者和生产者的协调与配合。因此,为保证物流中心位置的合理性,结合上述物流中心选址问题模型,提出物流中心選址算法流程如下:首先确定物流中心选址目标,其次制定物流中心选址原则,进行选址,直到选择出物流中心地址。通过物流中心评价指标对选择物流中心地址进行验证,最后确定合适的地址,如图2所示。
2基于改进的AP聚类算法应用
为提高AP聚类算法规划的物流中心位置合理性,结合上述物流中心选址行为分析理论,对传统规划物流中心位置的AP聚类算法进行改进。
2.1AP聚类算法理论
近邻传播算法由学者Frey&Due提出,可在短时间内处理较大规模数据集,且算法将每个数据点都作为潜在的数据中心,避免了主观意识对聚类结果的影响。算法将所有数据点都作为一个网络节点,在网络的边缘对实值信息进行传输,通过递归方式直到得到最优结果并出现聚类
2.2改进的AP聚类算法
基于传统AP聚类算法与物流中心选址行为对AP聚类算法进行改进,主要在基于时间路径建立物流中心选址模型和改进的物流配送区域划分模型方面进行改进。
2.2.1时间路径矩阵
在传统AP聚类算法中,一般以物流点之间的实际空间距离作为相似度评判标准进行聚类分析。由于城市物流本身存在很多影响因素,如城市交通高峰期、交通拥堵等,造成物流点间的实际空间距离无法代表实际运送时间,因此无法保证物流中心选址的准确性,同时也会降低整个物流系统配送的效率和用户服务体验。
为保证合理准确规划物流中心选址,基于城市交通约束提出物流点的时间路径理念,即以时间作为物流点之间的距离进行计算,提高物流中心选址的准确性和实际应用价值。用户物流点之间时间路径获取公式如下:
物流节点的时间距离矩阵获取方式如下:
通过收集N个物流节点位置和运输车辆速度信息,获得各个物流节点之间的距离,形成N x N的距离矩阵;与此同时获取到各个物流节点之间的运送时间,实际运送时间是通过累计计算两个物流节点之间的各次运送时间得到95%置信区间的最大值,以此作为其“时间距离”。以满足95%以上的任務完成度为目标,若获取不到就根据实际距离和实际情况进行估计、模拟,将所获得的时间信息存储到“时间距离”矩阵中。
2.2.3物流配送区域划分
物流配送过程中,当确定物流中心个数及相应位置后,需要通过遍历搜索方法确定各物流中心的配送区域以提高物流运输效率。本文将配送运输时间最短作为研究点,将其转化为最小支撑树条件,即将物流中心配送区域划分转变为物流配送网络优化问题。
3仿真验证
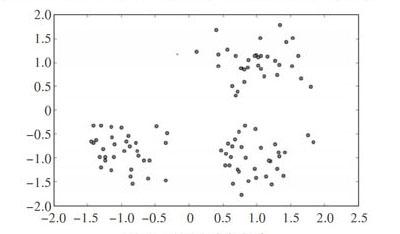
由于缺乏准确的物流点之间运送时间信息,因此本文实验数据集采用模拟数据进行实验验证。用Python在图上生成100个随机数据点作为物流点,根据每两点之间的距离按正太分布,随机生成100xl00组100个数据代表两个物流点之间的运送时间,将其作为基础试验数据集,每100个数据代表一个数据点到另一个数据点之间的100次物流运送时间。随机生成的测试离散点如图4所示。
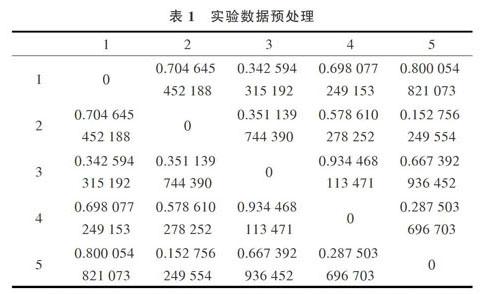
按正太分布计算每组数据,获得95%置信区间的最大值,将其作为该点到另一个数据点之间的运送时间,模拟现实生活中物流点完成95%以上的最低时间要求。将100xl00组数据全部处理,获得一个100xl00的矩阵,对数据进行处理获得相似度矩阵,以其中的5个数据点为例,处理结果如表1所示。
将数据处理阶段的两组相似度矩阵带人算法,调整算法内各个参数,根据以下流程得到物流中心选址位置:
(1)根据两个数据点之间的实际距离进行聚类,计算出两个数据点之间的欧式距离得到相似度矩阵,聚类中心为:
[1.023281031.10586516]、[0.84056362-0.99388229]、[-0.95558077-0.85930372]。
(2)根据实验数据处理阶段得到的时间相似度矩阵,带人聚类算法得到两个数据点之间关于时间的聚类结果,聚类中心为:
[1.016015480.9344856]、[0.96554162-1.2322174]、[-1.26947063-0.81126278]。
基于上述物流中心数据,通过最小支撑树法获得物流配送的最小支撑树。为清楚地展示实验过程,以20个数据点为例进行说明。
如图5所示,点1、点14、点18代表基于上述时间路径得出的物流中心位置,其余点代表客户位置点,各点之间的连接边上的权值为时间值。
采用最小支撑树法获得物流中心位置的最小支撑树,如图6所示。
基于上述最小支撑树和相应的物流信息,分别通过点1、14、18三个物流中心点进行广度优先的遍历搜索,获得各自所负责配送的客户点,结果如下:
(1)以点1进行遍历搜索的结果(规定其遍历层数为四层):2,3,4,6,8,5,7,9,10。
(2)以点14进行遍历搜索的结果(规定其遍历层数为三层):12,15,13,11。
(3)以点18进行遍历搜索的结果(规定其遍历层数为二层):16,19,17,20。
通过以上方法对100个数据点进行处理,基于实际距离和时间路径得到的处理结果分别如图7和图8所示(彩图见封三)。
从聚类结果可以看出,图7中除去部分噪声点,空间距离相近的数据点聚为一个类,即图中颜色相同的点;而从图8可以看出,部分原归为绿色的数据点,即图8中圆圈内标记的数据节点,由时间进行聚类后划为黄色的数据点,这是因为在实际物流中心选址应用中,两个物流点之间的实际距离较长,但两个物流点之间的运送时间却较短,造成部分原属于一个物流中心分配的物流点,经过以时间计算的方式后重新归属于另一个物流中心进行分配。
从以上结果分析可知,通过时间进行的聚类保证了物流中心分配到客户点的时间最优,确保了物流中心位置效率最高,从而达到优化整体物流水平目的。
4结语
本文以物流中心选址为研究对象,分析了基于物流点之间的运送时间进行选址的可行性,建立了基于时间路径的物流中心选址模型,并且通过最小支撑树法,由时间路径对选择的物流中心划分物流配送区域,通过仿真实例验证选址模型的有效性。
以时间路径替代实际距离进行聚类,避免了复杂环境下物流服务管理面对不确定性因素的处理难度,简化了管理控制过程的参量集合。采用最小支撑树法,通过时间赋权进行物流配送区域划分,提高了配送区域的合理性,提高了物流整体服务水平。后续将进一步研究时间路径数据如何采集以及大数据环境下的快递物流管理。
